Breaking Failure Cascades: Step-Aware Reinforcement Learning for Medical Multimodal Reasoning
Pith reviewed 2026-07-01 05:59 UTC · model grok-4.3
The pith
Step-aware RL with exponential early penalties breaks failure cascades in medical multimodal reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
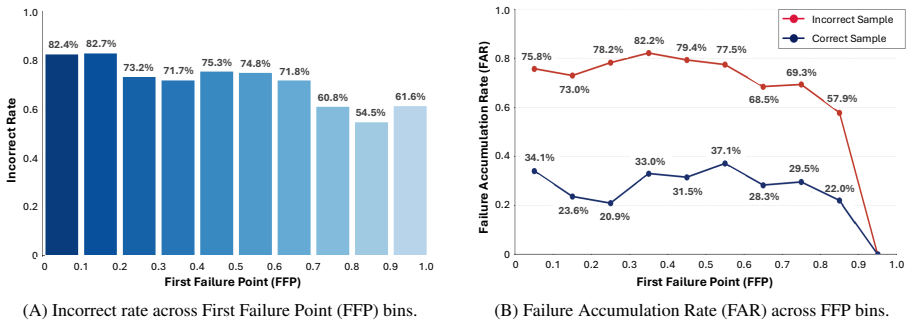
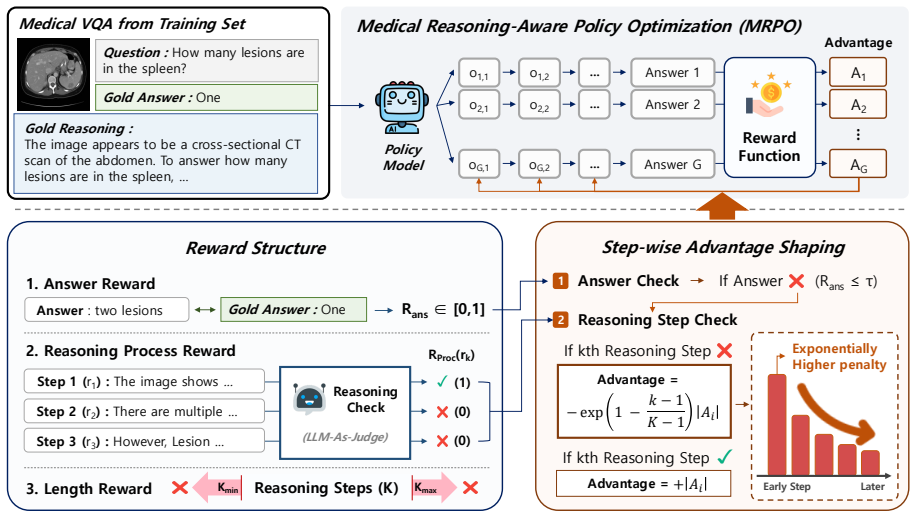
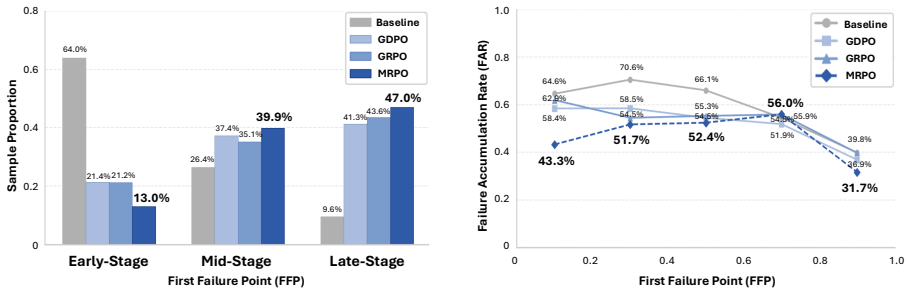
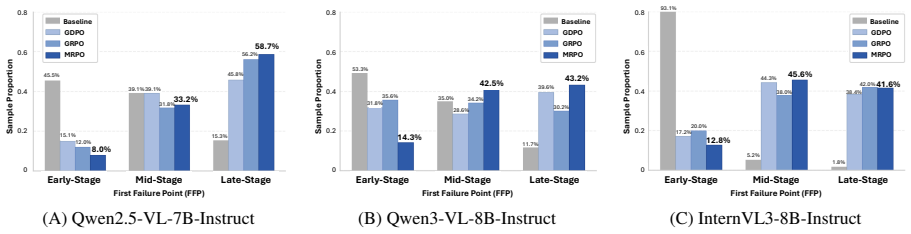
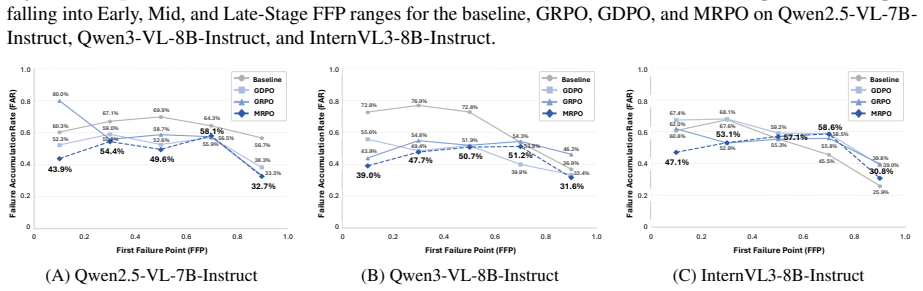
Cascading errors from early-stage reasoning failures are a leading cause of incorrect predictions in medical visual question answering benchmarks. MRPO is an RL algorithm that incorporates step-wise process rewards, assigning exponentially larger penalties to tokens in earlier invalid reasoning steps when the final answer is incorrect. This breaks failure cascades without compromising successful paths. Across three multimodal LLM backbones, MRPO outperforms standard GRPO and a recent RL baseline, and on Qwen3-VL-8B-Instruct surpasses HuatuoGPT-Vision-34B by 2.79 points while reducing early-stage reasoning failures from 64.0% to 13.0%.
What carries the argument
Medical Reasoning-aware Policy Optimization (MRPO), which uses step-wise process rewards with exponentially increasing penalties for earlier invalid steps to mitigate cascading errors.
If this is right
- MRPO consistently outperforms standard GRPO and a recent RL baseline across three multimodal LLM backbones.
- On Qwen3-VL-8B-Instruct, MRPO surpasses substantially larger medical MLLMs such as HuatuoGPT-Vision-34B by 2.79 points.
- MRPO reduces early-stage reasoning failures from 64.0% to 13.0%.
- Targeted mitigation of cascading failures improves both reasoning quality and final answer accuracy.
Where Pith is reading between the lines
- The exponential penalty structure could generalize to other sequential decision tasks where early mistakes compound.
- Combining MRPO with outcome rewards in a hybrid system might further optimize both process and result.
- Analysis of failure modes in non-medical domains could reveal if cascading errors are similarly dominant.
Load-bearing premise
Early-stage reasoning failures are the primary driver of incorrect final predictions and can be selectively penalized without disrupting correct reasoning sequences.
What would settle it
If applying MRPO on the medical VQA benchmarks does not lower the early-stage failure rate below 50% or fails to improve accuracy over baselines, the effectiveness of the exponential penalty mechanism would be called into question.
Figures









read the original abstract
Recent multimodal large language models have shown great promise in clinical image reasoning, but existing post-training pipelines remain predominantly outcome-centric, relying on final answer correctness or sequence-level preferences. This suffers from sparse credit assignment, making it difficult to optimize the reasoning process essential for clinical applications. Our analysis reveals that cascading errors from early-stage reasoning failures are a leading cause of incorrect predictions in medical visual question answering (VQA) benchmarks. Motivated by this, we propose Medical Reasoning-aware Policy Optimization (MRPO), an RL algorithm that incorporates step-wise process rewards. When the final answer is incorrect, MRPO assigns exponentially larger penalties to tokens in earlier invalid reasoning steps, breaking failure cascades without compromising successful paths. Across three multimodal LLM backbones, MRPO consistently outperforms standard GRPO and a recent RL baseline, and on Qwen3-VL-8B-Instruct even surpasses substantially larger medical MLLMs such as HuatuoGPT-Vision-34B by 2.79 points. Moreover, MRPO reduces early-stage reasoning failures from 64.0% to 13.0%, showing that targeted mitigation of cascading failures improves both reasoning quality and final answer accuracy. Our code is available at https://github.com/dmis-lab/MRPO
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that cascading errors from early-stage reasoning failures are a leading cause of incorrect predictions in medical VQA benchmarks. Motivated by this analysis, it proposes Medical Reasoning-aware Policy Optimization (MRPO), an RL algorithm that incorporates step-wise process rewards and assigns exponentially larger penalties to tokens in earlier invalid reasoning steps when the final answer is incorrect. Across three multimodal LLM backbones, MRPO outperforms standard GRPO and a recent RL baseline; on Qwen3-VL-8B-Instruct it surpasses larger medical MLLMs such as HuatuoGPT-Vision-34B by 2.79 points, while reducing early-stage reasoning failures from 64.0% to 13.0%. Code is released at https://github.com/dmis-lab/MRPO.
Significance. If the empirical results and the underlying analysis hold, the work is significant because it targets sparse credit assignment in outcome-centric RL for multimodal medical reasoning, offering a concrete mechanism to mitigate cascading failures. The consistent gains across backbones, outperformance of larger models, and substantial failure-rate reduction indicate potential for more reliable clinical image reasoning; open-sourcing the code further strengthens the contribution by enabling reproducibility.
major comments (2)
- [§2] §2 (analysis of cascading errors): the claim that early-stage failures are a 'leading cause' of incorrect predictions is load-bearing for the motivation of MRPO, yet the manuscript provides no quantitative breakdown (e.g., fraction of errors attributable to early vs. late steps, or statistical tests across the benchmark) beyond the headline 64% figure; without this, the premise that exponential penalties will selectively break cascades remains under-supported.
- [§3] §3 (MRPO formulation): the exponential penalty schedule is presented as breaking cascades 'without compromising successful paths,' but the manuscript does not report an ablation on the base of the exponential or on the step-identification heuristic; if these choices are sensitive, the reported gains may not generalize beyond the specific implementation.
minor comments (3)
- The abstract refers to 'a recent RL baseline' without naming it or citing the source; this should be clarified in the main text and abstract for reproducibility.
- Table or figure reporting the 2.79-point gain and the 64%→13% reduction should include confidence intervals or statistical significance tests to strengthen the cross-model claims.
- [§3] Notation for the step-wise reward (e.g., how invalid steps are detected and how the exponential factor is applied to tokens) should be introduced with an explicit equation early in §3.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation of minor revision. We provide point-by-point responses to the major comments and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§2] §2 (analysis of cascading errors): the claim that early-stage failures are a 'leading cause' of incorrect predictions is load-bearing for the motivation of MRPO, yet the manuscript provides no quantitative breakdown (e.g., fraction of errors attributable to early vs. late steps, or statistical tests across the benchmark) beyond the headline 64% figure; without this, the premise that exponential penalties will selectively break cascades remains under-supported.
Authors: We appreciate the referee's observation. Our analysis in Section 2 traces the origin of errors by identifying the earliest invalid reasoning step in each incorrect prediction, resulting in the reported 64% figure for early-stage failures. To provide the requested quantitative breakdown, we will expand Section 2 in the revised manuscript with a histogram or table detailing the distribution of first-error steps across the entire benchmark, the proportion of errors starting in early versus late stages, and any applicable statistical tests (e.g., comparing error rates). This additional evidence will more firmly establish early failures as a leading cause and justify the design of the exponential penalties in MRPO. revision: yes
-
Referee: [§3] §3 (MRPO formulation): the exponential penalty schedule is presented as breaking cascades 'without compromising successful paths,' but the manuscript does not report an ablation on the base of the exponential or on the step-identification heuristic; if these choices are sensitive, the reported gains may not generalize beyond the specific implementation.
Authors: Thank you for this suggestion. The exponential penalty is applied with base e to achieve a smooth but rapidly increasing penalty for earlier steps, and the step heuristic is based on the process reward signals. While we did not include ablations in the initial submission, we will add them to the appendix of the revised manuscript. Specifically, we will report results for different bases (2, e, 10) and an alternative heuristic using fixed token intervals for step identification. These ablations will confirm that the improvements in reducing early failures and overall accuracy are robust to these choices and not overly sensitive to the specific implementation. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central contribution is an empirical RL algorithm (MRPO) motivated by an internal analysis of cascading errors in medical VQA, with reported gains across backbones and reduced early failures. No equations, derivations, or self-citations are presented that reduce any claimed prediction or result to its own inputs by construction. The step-wise exponential penalties are introduced as a new training procedure rather than a fitted parameter or self-definitional renaming, and the performance claims rest on experimental outcomes rather than mathematical identities or load-bearing self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Med-r1: Reinforcement learning for general- izable medical reasoning in vision-language models. Preprint, arXiv:2503.13939. J. Richard Landis and Gary G. Koch. 1977. The mea- surement of observer agreement for categorical data. Biometrics, 33(1):159–174. Jason J. Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. 2018. A dataset of clini- cally ...
-
[2]
Quilt-llava: Visual instruction tuning by extracting localized narratives from open-source histopathology videos.Preprint, arXiv:2312.04746. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. 2024. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open langua...
-
[3]
Gtpo and grpo-s: Token and sequence- level reward shaping with policy entropy.Preprint, arXiv:2508.04349. LASA Team, Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, Yu Sun, Junao Shen, Chaojun Wang, Jie Tan, Deli Zhao, Tingyang Xu, Hao Zhang, and Yu Rong. 2025a. Lings...
-
[4]
Med-refl: Medical reasoning enhancement via self-corrected fine-grained reflection.Preprint, arXiv:2506.13793. Jaehoon Yun, Jiwoong Sohn, Jungwoo Park, Hyunjae Kim, Xiangru Tang, Yanjun Shao, Yonghoe Koo, Minhyeok Ko, Qingyu Chen, Mark Gerstein, Michael Moor, and Jaewoo Kang. 2025. Med-prm: Medical reasoning models with stepwise, guideline-verified proces...
-
[5]
Weihai Zhi, Jiayan Guo, and Shangyang Li
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems. Weihai Zhi, Jiayan Guo, and Shangyang Li. 2025. Medgr2: Breaking the data barrier for medical rea- soning via generative reward learning.Preprint, arXiv:2508.20549. Shuang Zhou, Wenya Xie, Jiaxi Li, Zaifu Zhan, Mei- jia Song, Han Yang, Cheyenna Espi...
-
[6]
Our imple- mentation builds on VLM-R1 (Shen et al., 2025), an open-source GRPO framework for VLMs
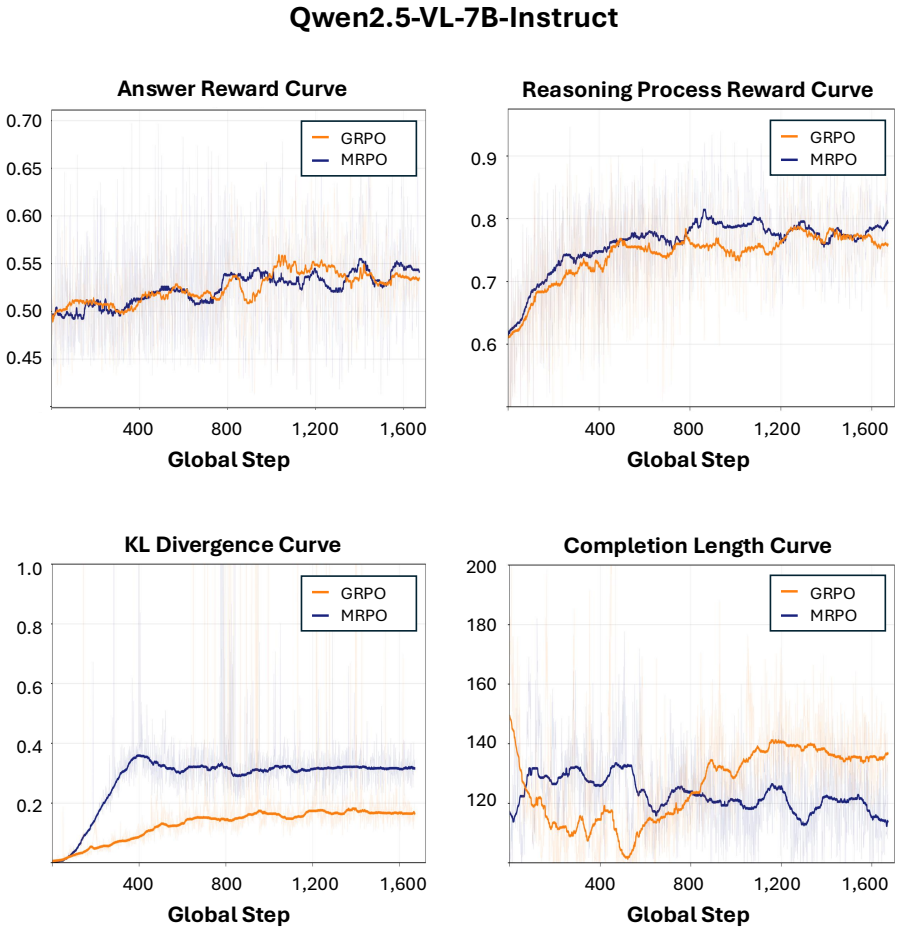
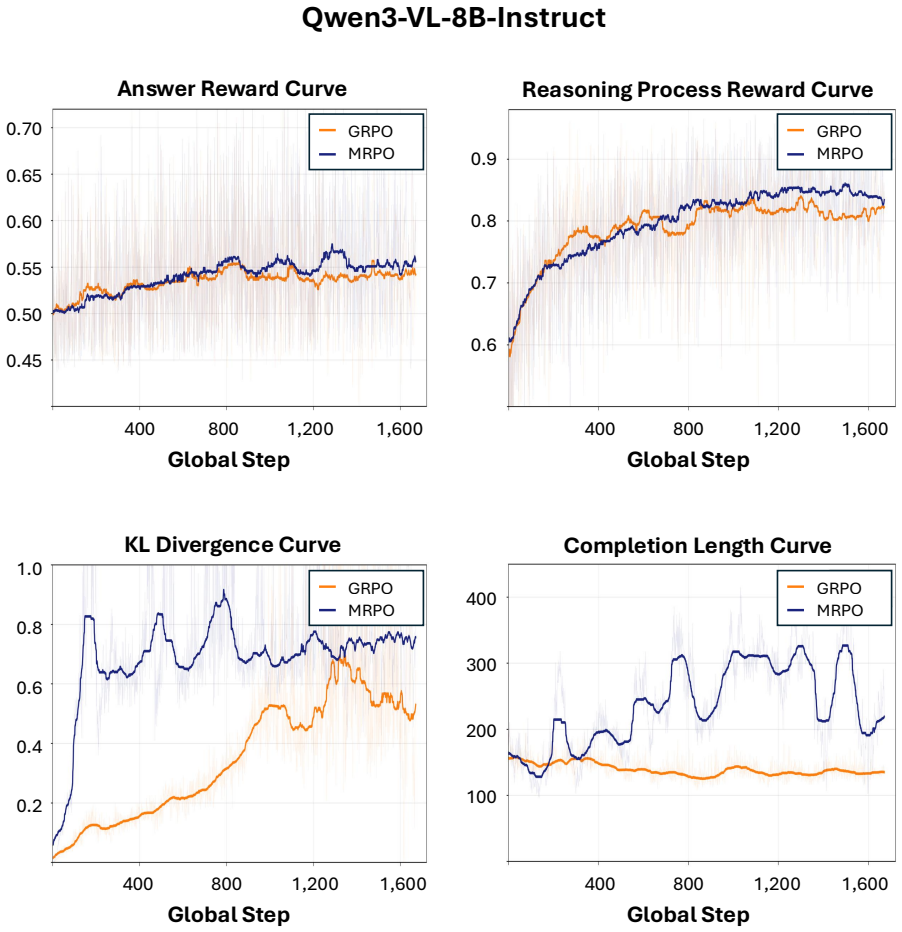
to improve training efficiency. Our imple- mentation builds on VLM-R1 (Shen et al., 2025), an open-source GRPO framework for VLMs. We train MRPO on three backbones, Qwen2.5- VL-7B-Instruct, Qwen3-VL-8B-Instruct, and InternVL3-8B-Instruct. To quantify MRPO’s effec- tiveness and compare it against other methods, all RL methods including MRPO, GRPO, and GDPO...
2025
-
[7]
with rank 8, alpha 32, and dropout 0.05, with a learning rate of2×10 −5 for 3 epochs. C.3 Training Cost and Efficiency We compare of training time, token usage, and total cost across RL methods on Qwen2.5-VL-7B- Instruct in Table 6. MRPO, GRPO, and GDPO all issue only a single API call per rollout to jointly evaluate all reasoning sentences. With 13K sam-...
-
[8]
Step2 It has a deep reddish-brown color, a lobulated shape, and a granular, nodular cut surface
GRPO Step1 The image is a gross pathology specimen on a blue background with a scale bar, not a microscopic or radiological image. Step2 It has a deep reddish-brown color, a lobulated shape, and a granular, nodular cut surface. Step3 The large size and heterogeneous parenchyma point to a solid visceral organ. MRPO anchors on the actual evidence from the s...
-
[9]
MRPO Figure 13:Case 1: Cascade correction.GRPO’s incorrect premise in the first step cascades into a wrong organ identification, while MRPO anchors on the correct visual evidence and reaches the right answer. 32 What is the mr weighting in this image?Question Gold Answer Qualitative Case Study: Case 2) Early Recovery Gold Reasoning The image provided is a...
-
[10]
Step2 The dark regions in and around the liver look like fluid, suggesting a fluid- sensitive T2 sequence
GRPO Step1 The image is an axial abdominal MRI showing the liver. Step2 The dark regions in and around the liver look like fluid, suggesting a fluid- sensitive T2 sequence. Step3 This fluid reading would point toward T2-weighting. MRPO misreads the dark regions around the liver as fluid, drifting toward a T2 interpretation. At step 4, it re-examines the i...
-
[11]
MRPO Step2 Most abdominal MRI scans are T2-weighted by default, so this is most likely T2-weighted. Figure 14:Case 2: Early recovery.GRPO defaults to a T2 assumption without inspecting the image and MRPO misreads dark regions as fluid; GRPO locks in the error, while MRPO re-anchors on the T1-characteristic bright subcutaneous fat and recovers the correct ...
-
[12]
lobulated,
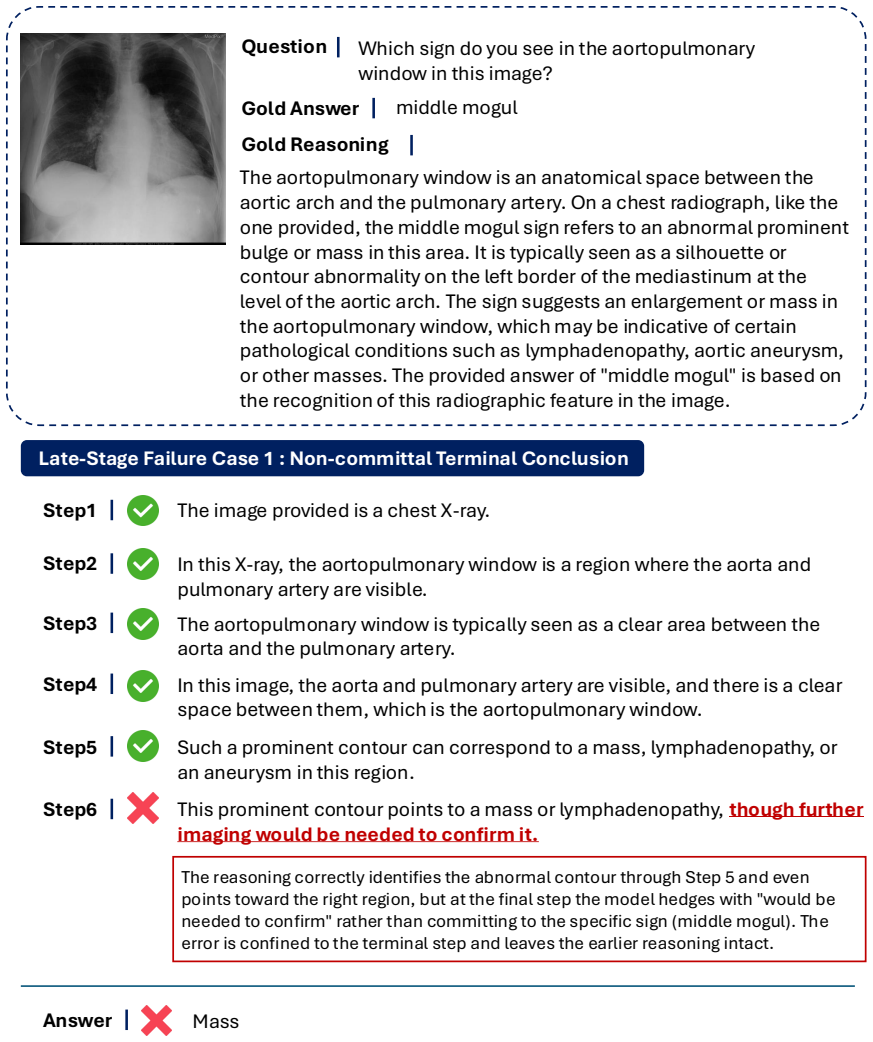
GRPO Step1 The image is an axial CT slice of the abdomen. Step2 The spleen is visible on the left side of the body, behind the stomach. Step3 Its outline appears as a smooth, curved soft-tissue structure following the contour of the abdominal wall. Late-stage failure (Terminal Label/Term Mismatch) : After correctly identifying the spleen and its smooth, c...
-
[13]
lobulated
MRPO Figure 15:Case 3: MRPO loss.MRPO correctly identifies and describes the spleen but labels its shape as “lobulated” at the final step, a terminal term mismatch that leaves the preceding reasoning intact. 34 0.45 0.50 0.55 0.60 0.65 0.70 400 800 1,200 1,600 Global Step Answer Reward Curve 0.6 0.7 0.8 0.9 400 800 1,200 1,600 Global Step Reasoning Proces...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.