Real-Time Source-Free Object Detection
Pith reviewed 2026-07-01 05:53 UTC · model grok-4.3
The pith
Dual-head detectors with selective pseudo-label fusion and multi-scale feature diversification enable faster, more compact source-free object detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
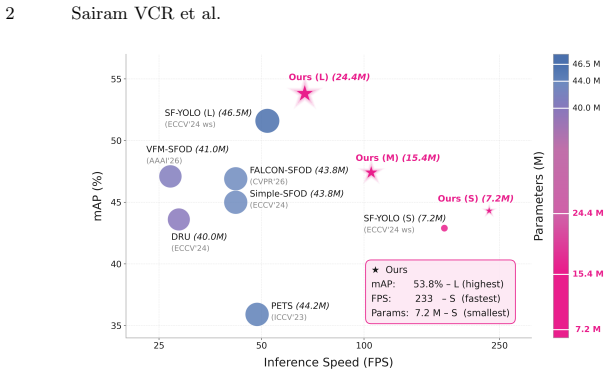
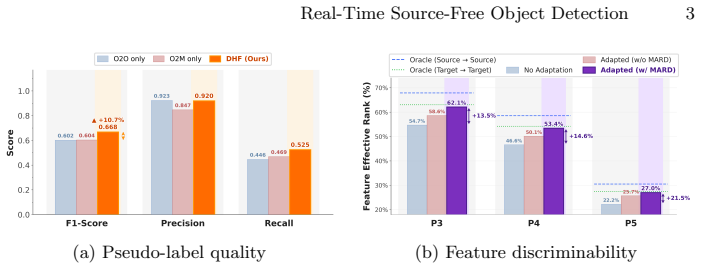
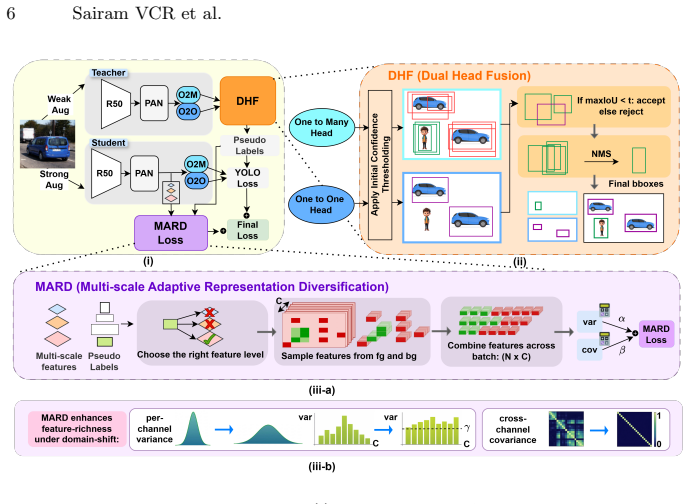
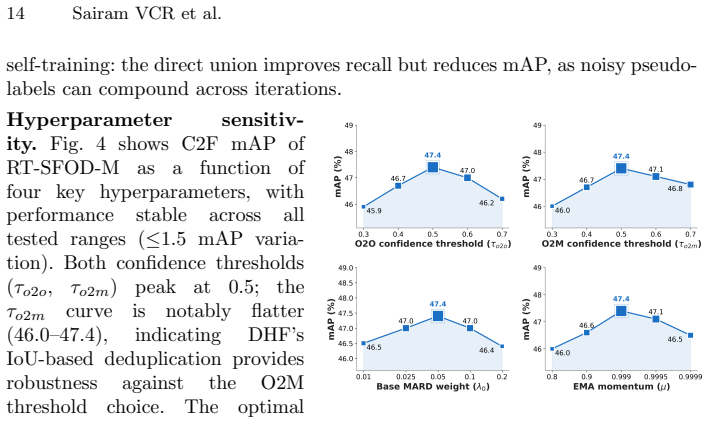
Directly applying vanilla mean-teacher to dual-head detectors yields suboptimal adaptation because single-head or naive combination pseudo-labels are imprecise under domain shift and because multi-scale feature maps lose discriminability. DHF selectively admits one-to-one and one-to-many head predictions to preserve precision while recovering missed objects. MARD enforces detection-aware variance and covariance constraints on multi-scale feature maps to restore discriminability. Both modules are training-only and leave inference unchanged, producing 1.4 to 3.5 percent mAP gains, 1.3 times higher throughput, and about two times fewer parameters than prior state-of-the-art SFOD methods.
What carries the argument
DHF (Dual-Head Pseudo-Label Fusion) that selectively admits O2O and O2M predictions from the two heads, together with MARD (Multi-scale Adaptive Representation Diversification) loss that applies variance and covariance constraints on multi-scale feature maps.
If this is right
- Yields 1.4 to 3.5 percent mAP gains across domain-shift benchmarks.
- Achieves 1.3 times higher throughput than prior SFOD methods.
- Uses roughly two times fewer parameters while maintaining or improving accuracy.
- Generalizes to additional YOLO- and DETR-based dual-head detectors.
Where Pith is reading between the lines
- The training-only nature of the modules suggests they can be combined with other adaptation techniques without changing deployed model size or latency.
- The same fusion and diversification ideas could be tested on other self-supervised detection pipelines that already produce multiple output heads.
- Edge deployment in autonomous driving or surveillance may become more practical once the accuracy-speed-size frontier moves as described.
Load-bearing premise
The two observed problems—suboptimal pseudo-labels from single-head or naive combination and collapsed multi-scale feature discriminability—are the main reasons vanilla mean-teacher fails on dual-head detectors, and that DHF and MARD fix them without creating new adaptation problems.
What would settle it
An ablation that replaces DHF with either single-head or direct combination pseudo-labeling and removes MARD, then measures whether mAP on a domain-shift benchmark drops back to the level of vanilla mean-teacher.
Figures
read the original abstract
Real-world detectors for autonomous driving, surveillance, and robotics must handle domain-shifts under strict latency and memory constraints, yet existing source-free object detection (SFOD) methods rely on heavyweight architectures that prioritize accuracy alone. We show this trade-off is unnecessary: building on YOLOv10, an NMS-free dual-head detector, we achieve state-of-the-art adaptation accuracy while being faster and more compact. We observe that directly applying vanilla mean-teacher self-training to dual-head detectors leads to suboptimal adaptation performance due to two key factors. First, simple pseudo-label generation strategies, such as using a single head or directly combining high-confidence predictions from both heads, yield suboptimal supervision under domain-shift. We propose DHF (Dual-Head Pseudo-Label Fusion) which selectively admits one-to-one (O2O) and one-to-many (O2M) head predictions, preserving precision and recovering missed objects. Second, we observe domain-shift collapses multi-scale feature discriminability. We propose the use of our MARD (Multi-scale Adaptive Representation Diversification) loss which mitigates this by enforcing detection-aware variance and covariance constraints on multi-scale feature maps. Both modules are training-time only, leaving inference unchanged. Across domain-shift benchmarks, our method, RT-SFOD yields 1.4 to 3.5\% mAP gains, 1.3$\times$ higher throughput, with $\sim$2$\times$ fewer parameters than prior state-of-the-art SFOD methods, thus advancing the Pareto frontier of the speed-accuracy-model size trade-off. We report main results with YOLOv10, and demonstrate generalizability with additional YOLO- and DETR-based dual-head detectors. Code is available here: https://github.com/Sairam13001/RT-SFOD/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RT-SFOD, a source-free object detection method built on the YOLOv10 dual-head detector. It identifies two limitations of vanilla mean-teacher self-training under domain shift—suboptimal pseudo-label generation from single-head or naive fusion strategies, and collapsed multi-scale feature discriminability—and proposes DHF (Dual-Head Pseudo-Label Fusion) to selectively combine O2O and O2M predictions plus the MARD loss to enforce detection-aware variance and covariance constraints on multi-scale features. Both modules are training-only. The central empirical claim is 1.4–3.5% mAP improvement, 1.3× higher throughput, and ~2× fewer parameters versus prior SFOD methods on domain-shift benchmarks, with generalization shown on additional YOLO and DETR dual-head detectors and code released.
Significance. If the reported gains are robust, the work meaningfully advances the speed-accuracy-model-size Pareto frontier for practical SFOD, which is relevant for latency-sensitive applications. The explicit code release supports reproducibility, a clear strength.
major comments (2)
- [Abstract, §4] Abstract and §4 (results): The attribution of the 1.4–3.5% mAP gains specifically to DHF and MARD rests on the premise that these modules correct the two identified factors without side effects, yet no controlled ablation is described that replaces the pseudo-label strategy or removes MARD while holding the remainder of the mean-teacher pipeline fixed to show the performance delta disappears.
- [§3.1–3.2] §3.1–3.2: The observations that single-head/naive fusion yields suboptimal supervision and that domain shift collapses multi-scale discriminability are presented as primary causes, but the manuscript provides no quantitative isolation (e.g., teacher-student consistency metrics or feature variance statistics before/after each module) demonstrating these are the dominant failure modes rather than other adaptation pathologies.
minor comments (2)
- [Tables 1–3, §4] Table captions and experimental setup paragraphs should explicitly list the exact baselines, number of runs, and whether error bars reflect standard deviation across seeds.
- [§3.1] Notation for O2O and O2M in the DHF description could be clarified with a short equation or diagram to avoid ambiguity in how predictions are selectively admitted.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will incorporate additional experiments to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (results): The attribution of the 1.4–3.5% mAP gains specifically to DHF and MARD rests on the premise that these modules correct the two identified factors without side effects, yet no controlled ablation is described that replaces the pseudo-label strategy or removes MARD while holding the remainder of the mean-teacher pipeline fixed to show the performance delta disappears.
Authors: We agree that the manuscript would benefit from a more tightly controlled ablation that holds the mean-teacher self-training pipeline fixed while varying only the pseudo-label generation strategy (e.g., single-head vs. naive fusion vs. DHF) or ablating MARD. The current results demonstrate gains relative to prior SFOD methods and include component-level studies, but do not isolate the contributions in exactly the manner described. In the revised manuscript we will add these controlled experiments and report the resulting performance deltas. revision: yes
-
Referee: [§3.1–3.2] §3.1–3.2: The observations that single-head/naive fusion yields suboptimal supervision and that domain shift collapses multi-scale discriminability are presented as primary causes, but the manuscript provides no quantitative isolation (e.g., teacher-student consistency metrics or feature variance statistics before/after each module) demonstrating these are the dominant failure modes rather than other adaptation pathologies.
Authors: The observations were derived from our development-stage analysis of dual-head detectors under domain shift. To provide the requested quantitative isolation, we will include additional metrics in the revision, such as teacher-student prediction consistency scores and multi-scale feature variance/covariance statistics computed before and after each module, to more rigorously demonstrate that these are the dominant issues addressed by DHF and MARD. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks
full rationale
The paper motivates DHF and MARD from observed issues with vanilla mean-teacher on dual-head detectors, then validates via mAP, throughput, and parameter comparisons on domain-shift benchmarks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All load-bearing claims reduce to experimental results rather than definitions or internal fits, making the work self-contained against external data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Annual Review of Control, Robotics, and Autonomous Systems9(2025)
Aljalbout, E., Xing, J., Romero, A., Akinola, I., Garrett, C.R., Heiden, E., Gupta, A., Hermans, T., Narang, Y., Fox, D., et al.: The reality gap in robotics: Chal- lenges, solutions, and best practices. Annual Review of Control, Robotics, and Autonomous Systems9(2025)
2025
-
[2]
In: Proceedings of the IEEE/CVF International Conference on Computer Vi- sion
Ashraf, T., Bashir, J.: Titan: Query-token based domain adaptive adversarial learn- ing. In: Proceedings of the IEEE/CVF International Conference on Computer Vi- sion. pp. 250–262 (2025)
2025
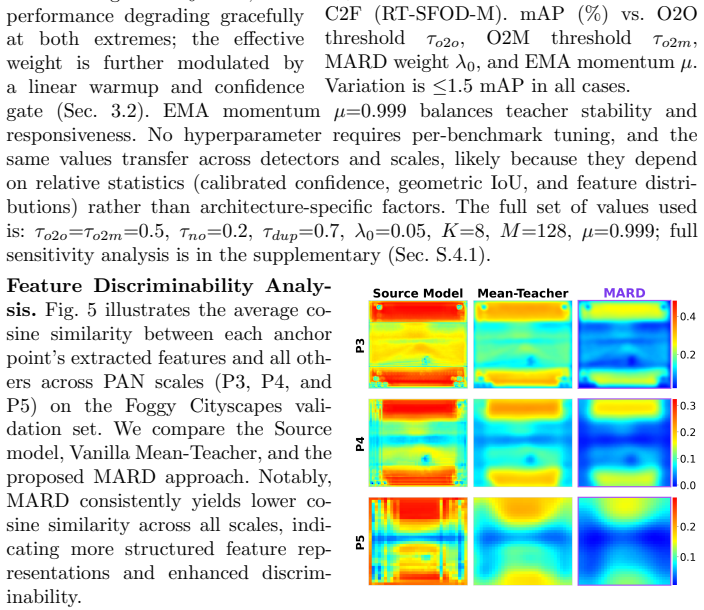
-
[3]
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
Bardes, A., Ponce, J., LeCun, Y.: Vicreg: Variance-invariance-covariance regular- ization for self-supervised learning. arXiv preprint arXiv:2105.04906 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, C., Zheng, Z., Ding, X., Huang, Y., Dou, Q.: Harmonizing transferability and discriminability for adapting object detectors. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8869–8878 (2020)
2020
-
[5]
IEEE Transac- tions on Image Processing34, 982–994 (2025)
Chen, L., Han, J., Wang, Y.: Datr: Unsupervised domain adaptive detection trans- former with dataset-level adaptation and prototypical alignment. IEEE Transac- tions on Image Processing34, 982–994 (2025)
2025
-
[6]
arXiv preprint arXiv:2406.03459 (2024) 4, 10
Chen, Q., Su, X., Zhang, X., Wang, J., Chen, J., Shen, Y., Han, C., Chen, Z., Xu, W., Li, F., et al.: Lw-detr: A transformer replacement to yolo for real-time detection. arXiv preprint arXiv:2406.03459 (2024)
-
[7]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Chen, Y., Li, W., Sakaridis, C., Dai, D., Van Gool, L.: Domain adaptive faster r-cnn for object detection in the wild. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3339–3348 (2018)
2018
-
[8]
Proceedings of the AAAI Conference on Artificial Intelligence 37(1), 452–460 (Jun 2023)
Chu, Q., Li, S., Chen, G., Li, K., Li, X.: Adversarial alignment for source free object detection. Proceedings of the AAAI Conference on Artificial Intelligence 37(1), 452–460 (Jun 2023)
2023
-
[9]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3213–3223 (2016)
2016
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Deng, J., Li, W., Chen, Y., Duan, L.: Unbiased mean teacher for cross-domain ob- ject detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4091–4101 (June 2021)
2021
-
[11]
The international journal of robotics research32(11), 1231–1237 (2013)
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The kitti dataset. The international journal of robotics research32(11), 1231–1237 (2013)
2013
-
[12]
In: European Conference on Computer Vision
Hao, Y., Forest, F., Fink, O.: Simplifying source-free domain adaptation for object detection: Effective self-training strategies and performance insights. In: European Conference on Computer Vision. pp. 196–213. Springer (2024)
2024
-
[13]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., An- dreetto, M., Adam, H.: Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Neurocomputing661, 131957 (2026)
Huo, Y., Wu, T., Shen, Y., Li, X., Tao, Z., Yang, D.: Qrt-detr: Post-training quan- tization for real-time detection transformer. Neurocomputing661, 131957 (2026)
2026
-
[15]
com/ultralytics/ultralytics
Jocher, G., Chaurasia, A., Qiu, J.: Ultralytics yolov8 (2023),https://github. com/ultralytics/ultralytics
2023
-
[16]
Johnson-Roberson, M., Barto, C., Mehta, R., Sridhar, S.N., Rosaen, K., Vasudevan, R.: Driving in the matrix: Can virtual worlds replace human-generated annotations for real world tasks? arXiv preprint arXiv:1610.01983 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kennerley, M., Wang, J.G., Veeravalli, B., Tan, R.T.: Cat: Exploiting inter-class dynamics for domain adaptive object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16541–16550 (2024) Real-Time Source-Free Object Detection 17
2024
-
[18]
YOLOv11: An Overview of the Key Architectural Enhancements
Khanam, R., Hussain, M.: Yolov11: An overview of the key architectural enhance- ments. arXiv preprint arXiv:2410.17725 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
In: European Conference on Computer Vision
Khanh, T.L.B., Nguyen, H.H., Pham, L.H., Tran, D.N.N., Jeon, J.W.: Dynamic retraining-updating mean teacher for source-free object detection. In: European Conference on Computer Vision. pp. 328–344. Springer (2024)
2024
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, H., Zhang, R., Yao, H., Zhang, X., Hao, Y., Song, X., Peng, S., Zhao, Y., Zhao, C., Wu, Y., et al.: Seen-da: Semantic entropy guided domain-aware attention for domain adaptive object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 25465–25475 (2025)
2025
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Li, S., Ye, M., Zhu, X., Zhou, L., Xiong, L.: Source-free object detection by learn- ing to overlook domain style. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8014–8023 (June 2022)
2022
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence35, 8474–8481 (05 2021)
Li, X., Chen, W., Xie, D., Yang, S., Yuan, P., Pu, S., Zhuang, Y.: A free lunch for unsupervised domain adaptive object detection without source data. Proceedings of the AAAI Conference on Artificial Intelligence35, 8474–8481 (05 2021)
2021
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, Y.J., Dai, X., Ma, C.Y., Liu, Y.C., Chen, K., Wu, B., He, Z., Kitani, K., Vajda, P.: Cross-domain adaptive teacher for object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7581–7590 (2022)
2022
-
[24]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision (2023)
Liu, Q., Lin, L., Shen, Z., Yang, Z.: Periodically exchange teacher-student for source-free object detection. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision (2023)
2023
-
[25]
In: International Conference on Learning Representations (2022)
Liu, S., Li, F., Zhang, H., Yang, X., Qi, X., Su, H., Zhu, J., Zhang, L.: DAB-DETR: Dynamic anchor boxes are better queries for DETR. In: International Conference on Learning Representations (2022)
2022
-
[26]
In: Proceedings of the European Conference on Computer Vision (ECCV)
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S.E., Fu, C.Y., Berg, A.C.: Ssd: Single shot multibox detector. In: Proceedings of the European Conference on Computer Vision (ECCV). Lecture Notes in Computer Science, vol. 9905, pp. 21–37. Springer (2016)
2016
-
[27]
arXiv preprint arXiv:2406.05800 (2024)
Ma, C., Wang, N., Zhao, Z., Chen, Q.A., Shen, C.: Slowperception: Physical-world latency attack against visual perception in autonomous driving. arXiv preprint arXiv:2406.05800 (2024)
-
[28]
Journal of Applied Informatics and Computing9, 3810–3820 (12 2025)
Naufaldihanif, R., Kurniawan, D., Tania, K.: Performance analysis of yolo, faster r-cnn, and detr for automated personal protective equipment detection. Journal of Applied Informatics and Computing9, 3810–3820 (12 2025)
2025
-
[29]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Noori, M., Hakim, G.A.V., Osowiechi, D., Shakeri, F., Bahri, A., Yazdanpanah, M., Dastani, S., Ben Ayed, I., Desrosiers, C.: Histopath-c: Towards realistic do- main shifts for histopathology vision-language adaptation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 4890–4900 (2026)
2026
-
[30]
RangiLyu: Nanodet-plus: Super fast and high accuracy lightweight anchor-free object detection model. (2021)
2021
-
[31]
IEEE transactions on pattern analysis and machine intelligence39(6), 1137–1149 (2016)
Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object de- tection with region proposal networks. IEEE transactions on pattern analysis and machine intelligence39(6), 1137–1149 (2016)
2016
-
[32]
Robinson, I., Robicheaux, P., Popov, M., Ramanan, D., Peri, N.: Rf-detr: Neural architecture search for real-time detection transformers (2025)
2025
-
[33]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Safdari, R., Nikouei Mahani, M.A., Koohi-Moghadam, M., Bae, K.T.: Mixstyleflow: Domain generalization in medical image segmentation using normalizing flows. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 376–385. Springer (2025) 18 Sairam VCR et al
2025
-
[34]
International Journal of Computer Vision126, 973–992 (2018)
Sakaridis, C., Dai, D., Van Gool, L.: Semantic foggy scene understanding with synthetic data. International Journal of Computer Vision126, 973–992 (2018)
2018
-
[35]
arXiv preprint arXiv:2402.04466 (2024)
Sinha, S., Dwivedi, S., Azizian, M.: Towards deterministic end-to-end latency for medical ai systems in nvidia holoscan. arXiv preprint arXiv:2402.04466 (2024)
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sun, T., Segu, M., Postels, J., Wang, Y., Van Gool, L., Schiele, B., Tombari, F., Yu, F.: Shift: a synthetic driving dataset for continuous multi-task domain adaptation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21371–21382 (2022)
2022
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Tan, M., Pang, R., Le, Q.V.: Efficientdet: Scalable and efficient object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 10781–10790 (2020)
2020
-
[38]
Advances in neural information processing systems30(2017)
Tarvainen, A., Valpola, H.: Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Advances in neural information processing systems30(2017)
2017
-
[39]
urlhttps://github.com/ultralytics/yolov5 (Dec 2020), accessed: [Insert date here]
Ultralytics: Ultralytics yolov5. urlhttps://github.com/ultralytics/yolov5 (Dec 2020), accessed: [Insert date here]
2020
-
[40]
Ultralytics: YOLO26 (2025),https://github.com/ultralytics/ultralytics
2025
-
[41]
In: European Conference on Computer Vision
Varailhon, S., Aminbeidokhti, M., Pedersoli, M., Granger, E.: Source-free domain adaptation for yolo object detection. In: European Conference on Computer Vision. pp. 218–235. Springer (2024)
2024
-
[42]
arXiv preprint arXiv:2512.17514 (2025)
VCR, S., Lalla, R., Dayal, A., Kulkarni, T., Lalla, A., Balasubramanian, V.N., Khan, M.H.: Foundation model priors enhance object focus in feature space for source-free object detection. arXiv preprint arXiv:2512.17514 (2025)
-
[43]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2023)
Vibashan, V., Oza, P., Patel, V.M.: Instance relation graph guided source-free domain adaptive object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2023)
2023
-
[44]
Advances in neural information processing systems 37, 107984–108011 (2024)
Wang, A., Chen, H., Liu, L., Chen, K., Lin, Z., Han, J., et al.: Yolov10: Real-time end-to-end object detection. Advances in neural information processing systems 37, 107984–108011 (2024)
2024
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Wang, C.Y., Bochkovskiy, A., Liao, H.Y.M.: YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[46]
In: WACV
Wang, S., Xia, C., Lv, F., Shi, Y.: Rt-detrv3: Real-time end-to-end object detection with hierarchical dense positive supervision. In: WACV. pp. 1628–1636 (2025)
2025
-
[47]
In: Pro- ceedings of the 29th ACM International Conference on Multimedia
Wang, W., Cao, Y., Zhang, J., He, F., Zha, Z.J., Wen, Y., Tao, D.: Exploring sequence feature alignment for domain adaptive detection transformers. In: Pro- ceedings of the 29th ACM International Conference on Multimedia. p. 1730–1738. MM ’21, Association for Computing Machinery, New York, NY, USA (2021)
2021
-
[48]
Weng, W., Yuan, C.: Mean teacher detr with masked feature alignment: a robust domain adaptive detection transformer framework. In: Proceedings of the Thirty- Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Inte...
2024
-
[49]
In: Proceedings of the IEEE/CVF interna- tional conference on computer vision
Wu, A., Liu, R., Han, Y., Zhu, L., Yang, Y.: Vector-decomposed disentanglement for domain-invariant object detection. In: Proceedings of the IEEE/CVF interna- tional conference on computer vision. pp. 9342–9351 (2021)
2021
-
[50]
Advances in Neural Information Processing Systems35, 4203–4217 (2022) Real-Time Source-Free Object Detection 1
Yang, J., Li, C., Dai, X., Gao, J.: Focal modulation networks. Advances in Neural Information Processing Systems35, 4203–4217 (2022) Real-Time Source-Free Object Detection 1
2022
-
[51]
arXiv preprint arXiv:2511.07301 (2025)
Yao, H., Zhao, S., Li, P., Cui, Y., Lu, S., Guo, W., Lu, Y., Xu, Y., Xiong, H.: Beyond boundaries: Leveraging vision foundation models for source-free object detection. arXiv preprint arXiv:2511.07301 (2025)
-
[52]
IEEE Transactions on Image Processing34, 5948–5963 (2025)
Yao, H., Zhao, S., Lu, S., Chen, H., Li, Y., Liu, G., Xing, T., Yan, C., Tao, J., Ding, G.: Source-free object detection with detection transformer. IEEE Transactions on Image Processing34, 5948–5963 (2025)
2025
-
[53]
In: European Conference on Computer Vision
Yoon, I., Kwon, H., Kim, J., Park, J., Jang, H., Sohn, K.: Enhancing source-free domain adaptive object detection with low-confidence pseudo label distillation. In: European Conference on Computer Vision. pp. 337–353. Springer (2024)
2024
-
[54]
arXiv preprint arXiv:1805.046872(5), 6 (2018)
Yu, F., Xian, W., Chen, Y., Liu, F., Liao, M., Madhavan, V., Darrell, T., et al.: Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv preprint arXiv:1805.046872(5), 6 (2018)
-
[55]
In: ECCV (2024)
Yu, J., Liu, J., Wei, X., Zhou, H., Nakata, Y., Gudovskiy, D., Okuno, T., Li, J., Keutzer, K., Zhang, S.: Mttrans: Cross-domain object detection with mean-teacher transformer. In: ECCV (2024)
2024
-
[56]
detr: Instructive multi-route training for detection transformers
Zhang, C.B., Zhong, Y., Han, K.: Mr. detr: Instructive multi-route training for detection transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9933–9943 (June 2025)
2025
-
[57]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Zhang, J., Huang, J., Luo, Z., Zhang, G., Zhang, X., Lu, S.: Da-detr: Domain adap- tive detection transformer with information fusion. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 23787–23798 (2021)
2023
-
[58]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhao, C., Sun, Y., Wang, W., Chen, Q., Ding, E., Yang, Y., Wang, J.: Ms-detr: Efficient detr training with mixed supervision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 17027– 17036 (June 2024)
2024
-
[59]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhao, Y., Lv, W., Xu, S., Wei, J., Wang, G., Dang, Q., Liu, Y., Chen, J.: Detrs beat yolos on real-time object detection. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 16965–16974 (2024)
2024
-
[60]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhao, Z., Wei, S., Chen, Q., Li, D., Yang, Y., Peng, Y., Liu, Y.: Masked retraining teacher-student framework for domain adaptive object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19039–19049 (2023)
2023
-
[61]
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., Dai, J.: Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159 (2020) Supplementary for Real-Time Source-Free Object Detection Sairam VCR1, Varun Gopal1, Poornima Jain 1, Vineeth N Balasubramanian 1,2, and Muhammad Haris Khan 3 1IIT Hyderabad, India 2Microsoft R...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[62]
is a large-scale driving dataset with 100,000 images collected under diverse environmental and weather conditions. S.4.3 Details of Data Augmentation Strategies To facilitate robust self-training in our Source-Free Object Detection (SFOD) framework, we employ a Teacher-Student distillation mechanism with asymmet- Real-Time Source-Free Object Detection 7 r...
-
[63]
However, AdaBN does not eliminate pseudo-label noise or the non-stationarity introduced by augmentation and thresholding
shows that Adaptive Batch Normalization (AdaBN) provides a better start- ing point on the target domain and makes fixed pseudo-label training competitive with EMA-based methods. However, AdaBN does not eliminate pseudo-label noise or the non-stationarity introduced by augmentation and thresholding. Figure S.7 studies the effect of teacher update frequency...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.