The Illusion of Multi-Agent Advantage
Pith reviewed 2026-06-27 06:43 UTC · model grok-4.3
The pith
Automatically generated multi-agent systems underperform chain-of-thought self-consistency despite up to 10x higher cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
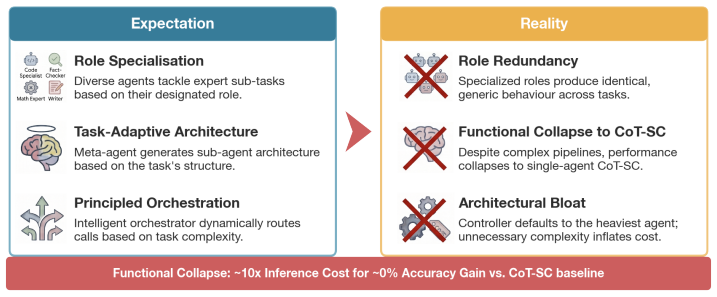
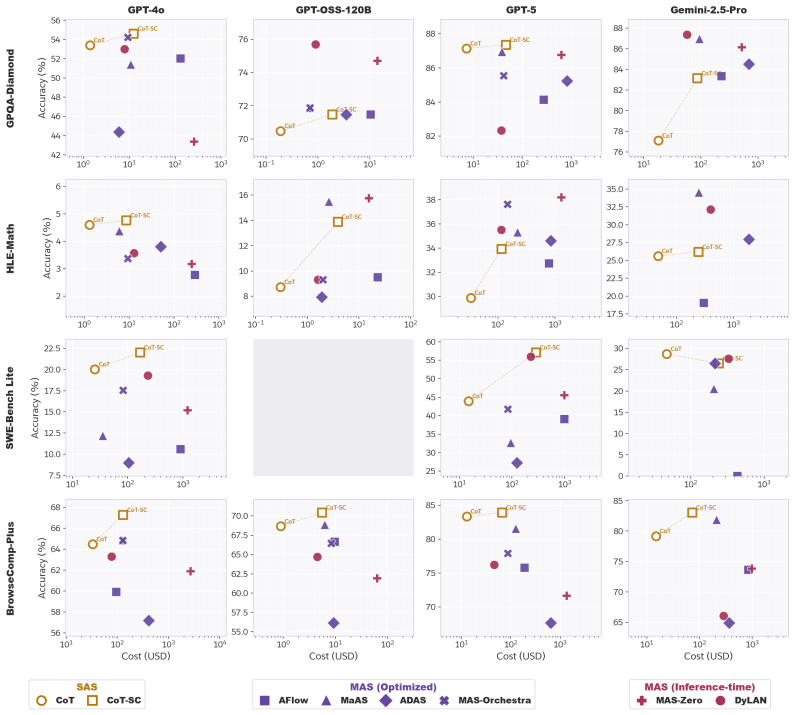
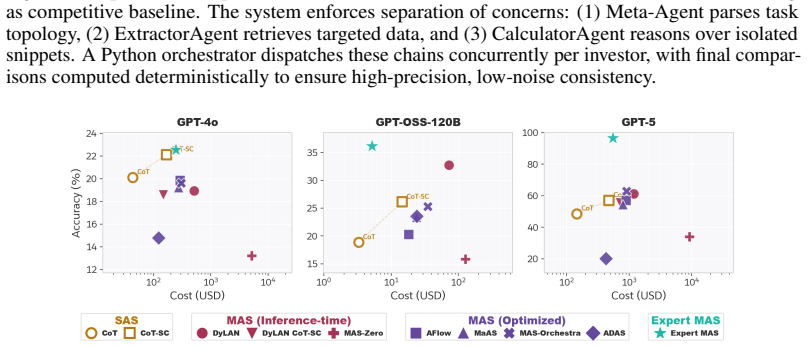
Automatic MAS consistently underperform CoT-SC despite being up to 10x more expensive. On a diagnostic synthetic dataset featuring explicit task decomposition, context separation and parallelization potential, expert-architected MAS outperform automatically generated architectures in both raw performance and cost-efficiency. Systematic deconstruction of the generated MAS architectures reveals that current automated design paradigms produce architectural bloat that prioritizes superficial complexity which does not translate into functional utility, exposing a fundamental misalignment with multi-agent principles.
What carries the argument
Diagnostic synthetic dataset with explicit task decomposition, context separation, and parallelization potential, used to isolate MAS advantages from baseline task structure.
If this is right
- Evaluation frameworks must incorporate marginal utility of added computational cost when assessing MAS.
- Expert-architected MAS can deliver better performance and efficiency than automatic versions on tasks with clear decomposition needs.
- Automated MAS design methods currently produce unnecessary layers that do not improve outcomes.
- Single-agent methods with self-consistency remain competitive or superior for many reasoning workflows.
Where Pith is reading between the lines
- Development effort on complex MAS may yield higher returns if redirected toward strengthening single-agent baselines.
- Selective addition of individual MAS components to simpler systems could be tested as a lower-cost alternative.
- Default preference for MAS in system design should be replaced by cost-benefit checks on concrete tasks.
- Future benchmarks should require explicit cost reporting to expose cases where added agents add no value.
Load-bearing premise
The synthetic dataset and chosen benchmarks properly isolate MAS advantages of decomposition and parallelization so that underperformance can be attributed to architecture rather than task mismatch.
What would settle it
An automatically generated MAS that matches or exceeds CoT-SC accuracy on the synthetic dataset while using equal or lower total compute.
Figures





read the original abstract
Prevailing wisdom posits that Multi-Agent Systems (MAS) are superior to Single-Agent Systems (SAS), citing advantages like context protection, parallel processing and distributed decision-making. However, empirical support for this claim relies primarily on comparisons with SAS baselines using benchmarks that prioritize isolated reasoning tasks, which do not adequately assess these advantages. Focusing on automatically generated MAS that are designed for enhanced generalizability over manually-designed counterparts, we perform a rigorous, systematic evaluation against SAS, specifically Chain-of-Thought with Self-Consistency (CoT-SC). Across traditional reasoning datasets and tasks with interactive multi-step workflows (e.g., BrowseComp-Plus), we demonstrate that automatic MAS consistently underperform CoT-SC despite being up to 10x more expensive. To isolate these failures from limitations inherent to task structure, we introduce a diagnostic synthetic dataset tailored for MAS featuring explicit task decomposition, context separation and parallelization potential. We show that expert-architected MAS consistently outperforms automatically generated architectures in both raw performance and cost-efficiency on this dataset, demonstrating that existing evaluation frameworks mask critical architectural gaps and inefficiencies of complex MAS by failing to account for the marginal utility of increased computational cost. Critically, systematic deconstruction of the generated MAS architectures reveals that current automated design paradigms produce architectural bloat that prioritizes superficial complexity which does not translate into functional utility, exposing a fundamental misalignment with multi-agent principles.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that automatically generated multi-agent systems (MAS) consistently underperform the single-agent baseline Chain-of-Thought with Self-Consistency (CoT-SC) on traditional reasoning datasets and interactive tasks such as BrowseComp-Plus, despite up to 10x higher cost. It introduces a diagnostic synthetic dataset explicitly tailored to MAS advantages (task decomposition, context separation, parallelization) on which expert-designed MAS outperform auto-generated ones, attributing the gaps to architectural bloat and superficial complexity in current automated design methods that fails to deliver functional utility.
Significance. If the central empirical claims hold after addressing the noted issues, the work would challenge prevailing assumptions about MAS superiority and highlight the need for evaluation frameworks that incorporate marginal cost-utility analysis. The introduction of a targeted diagnostic dataset and the cost-performance comparisons represent constructive contributions toward more rigorous MAS assessment.
major comments (3)
- [diagnostic synthetic dataset (abstract and methods)] The diagnostic synthetic dataset (described in the abstract) is constructed to feature 'explicit task decomposition, context separation and parallelization potential.' This tailoring risks embedding structures that expert architects can directly exploit while automated generation methods cannot discover or utilize, confounding the attribution of performance gaps to 'architectural bloat' rather than dataset construction favoring manual designs. This is load-bearing for the claim that existing frameworks mask critical architectural gaps.
- [abstract and results] The abstract reports that automatic MAS 'consistently underperform CoT-SC' and that expert MAS outperform auto-generated ones, but provides no error bars, exact dataset sizes, statistical tests, or full baseline implementation details. Without these, the reliability of the underperformance and cost-efficiency claims cannot be assessed, weakening the central empirical argument.
- [results (deconstruction analysis)] The post-hoc systematic deconstruction of generated MAS architectures (results section) to identify 'architectural bloat' and 'superficial complexity' risks selection effects, as the choice of which components to analyze could influence the conclusion that automated paradigms are misaligned with multi-agent principles.
minor comments (1)
- [methods] Clarify the exact sizes and construction details of all datasets (including the synthetic one) and provide full descriptions of the automated MAS generation process and baselines to enable reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commitments to revisions where appropriate.
read point-by-point responses
-
Referee: [diagnostic synthetic dataset (abstract and methods)] The diagnostic synthetic dataset (described in the abstract) is constructed to feature 'explicit task decomposition, context separation and parallelization potential.' This tailoring risks embedding structures that expert architects can directly exploit while automated generation methods cannot discover or utilize, confounding the attribution of performance gaps to 'architectural bloat' rather than dataset construction favoring manual designs. This is load-bearing for the claim that existing frameworks mask critical architectural gaps.
Authors: The diagnostic dataset was intentionally constructed to instantiate the specific MAS advantages (decomposition, context separation, parallelization) that standard benchmarks rarely isolate. This design allows direct comparison of whether automated methods can discover and exploit these structures versus expert architects. The performance gap and subsequent architectural deconstruction support the attribution to bloat in auto-generated systems rather than dataset bias; expert MAS succeed precisely because they utilize the embedded features that auto methods overlook. We will expand the methods section with explicit construction criteria and validation steps to make this rationale transparent. revision: partial
-
Referee: [abstract and results] The abstract reports that automatic MAS 'consistently underperform CoT-SC' and that expert MAS outperform auto-generated ones, but provides no error bars, exact dataset sizes, statistical tests, or full baseline implementation details. Without these, the reliability of the underperformance and cost-efficiency claims cannot be assessed, weakening the central empirical argument.
Authors: We agree that the presentation of results would be strengthened by additional statistical details. In the revised manuscript we will add error bars (standard deviations across repeated runs), exact dataset sizes for all benchmarks including the diagnostic set, statistical tests (e.g., paired t-tests with p-values), and expanded baseline implementation details in both the main text and appendix. revision: yes
-
Referee: [results (deconstruction analysis)] The post-hoc systematic deconstruction of generated MAS architectures (results section) to identify 'architectural bloat' and 'superficial complexity' risks selection effects, as the choice of which components to analyze could influence the conclusion that automated paradigms are misaligned with multi-agent principles.
Authors: The deconstruction was performed systematically on every generated architecture using a fixed taxonomy of component types (agent roles, inter-agent communication, decision aggregation, etc.) defined prior to analysis. Components were flagged as bloat only when ablation experiments showed no performance gain relative to added cost. We will include the full taxonomy, decision rules, and per-architecture examples in the revised methods section to eliminate any ambiguity about selection criteria. revision: partial
Circularity Check
No circularity: purely empirical head-to-head evaluation
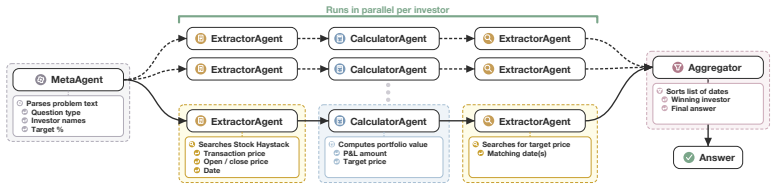
full rationale
The paper advances its central claim through direct empirical comparisons of automatic MAS vs. CoT-SC on standard benchmarks and vs. expert MAS on a new synthetic dataset. No equations, fitted parameters, or derivations are present that could reduce to inputs by construction. The synthetic dataset is introduced as an explicit methodological tool to isolate MAS advantages, but its construction does not define the performance gap or force the outcome; results are measured against external baselines (CoT-SC and expert designs). No self-citation chains or uniqueness theorems are invoked to justify the architecture or conclusions. The analysis is self-contained against external benchmarks and does not rely on any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
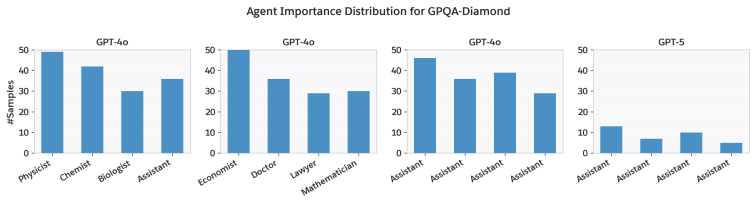
axioms (2)
- domain assumption Traditional reasoning datasets and BrowseComp-Plus adequately test MAS advantages such as context protection and parallel processing.
- domain assumption The synthetic dataset features explicit task decomposition, context separation, and parallelization potential that should favor well-designed MAS.
invented entities (1)
-
diagnostic synthetic dataset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
How we built our multi-agent research system
Anthropic. How we built our multi-agent research system. https://www.anthropic.com/ engineering/built-multi-agent-research-system, June 2025
2025
-
[2]
Building multi-agent systems: When and how to use them
Anthropic. Building multi-agent systems: When and how to use them. hhttps://claude. com/blog/building-multi-agent-systems-when-and-how-to-use-them , January 2026
2026
-
[3]
Claude code agent teams
Anthropic. Claude code agent teams. https://code.claude.com/docs/en/agent-teams, 2026
2026
-
[4]
yfinance: Yahoo! finance market data downloader
Ran Aroussi. yfinance: Yahoo! finance market data downloader. https://github.com/ ranaroussi/yfinance, 2024
2024
-
[5]
Pan, Shuyi Yang, Lakshya A
Mert Cemri, Melissa Z. Pan, Shuyi Yang, Lakshya A. Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. Why do multi-agent llm systems fail?, 2025
2025
-
[6]
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Cheng Qian, Chi-Min Chan, Yujia Qin, Ya-Ting Lu, Ruobing Xie, Zhiyuan Liu, Maosong Sun, and Jie Zhou. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors in agents.ArXiv, abs/2308.10848, 2023
Pith/arXiv arXiv 2023
-
[7]
Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, Sahel Sharifymoghaddam, Yanxi Li, Haoran Hong, Xinyu Shi, Xuye Liu, Nandan Thakur, Crystina Zhang, Luyu Gao, Wenhu Chen, and Jimmy Lin. Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent.arXiv p...
arXiv 2025
-
[8]
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[9]
Foerster, Yannis Assael, Nando de Freitas, and Shimon Whiteson
Jakob N. Foerster, Yannis Assael, Nando de Freitas, and Shimon Whiteson. Learning to communicate with deep multi-agent reinforcement learning.ArXiv, abs/1605.06676, 2016
Pith/arXiv arXiv 2016
-
[10]
Single-agent or multi-agent systems? why not both?ArXiv, abs/2505.18286, 2025
Mingyan Gao, Yanzi Li, Banruo Liu, Yifan Yu, Phillip Wang, Ching-Yu Lin, and Fan Lai. Single-agent or multi-agent systems? why not both?ArXiv, abs/2505.18286, 2025
arXiv 2025
-
[11]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
Pith/arXiv arXiv 2021
-
[12]
Pablo Hernandez-Leal, Bilal Kartal, and Matthew E. Taylor. A survey and critique of multiagent deep reinforcement learning.Autonomous Agents and Multi-Agent Systems, 33:750 – 797, 2018
2018
-
[13]
Automated design of agentic systems.arXiv preprint arXiv:2408.08435, 2024
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems.arXiv preprint arXiv:2408.08435, 2024
Pith/arXiv arXiv 2024
-
[14]
Automated design of agentic systems
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[15]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. Swe-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. 10
2024
-
[16]
Ai agents that matter.arXiv preprint arXiv:2407.01502, 2024
Sayash Kapoor, Benedikt Stroebl, Zachary S Siegel, Nitya Nadgir, and Arvind Narayanan. Ai agents that matter.arXiv preprint arXiv:2407.01502, 2024
arXiv 2024
-
[17]
A survey of frontiers in llm reasoning: Inference scaling, learning to reason, and agentic systems.TMLR, 2025
Zixuan Ke, Fangkai Jiao, Yifei Ming, Xuan-Phi Nguyen, Austin Xu, Do Xuan Long, Minzhi Li, Chengwei Qin, Peifeng Wang, Silvio Savarese, Caiming Xiong, and Shafiq Joty. A survey of frontiers in llm reasoning: Inference scaling, learning to reason, and agentic systems.TMLR, 2025
2025
-
[18]
Mas-orchestra: Understanding and improving multi-agent reasoning through holistic orchestration and controlled benchmarks
Zixuan Ke, Yifei Ming, Austin Xu, Ryan Chin, Xuan-Phi Nguyen, Prathyusha Jwalapuram, Jiayu Wang, Semih Yavuz, Caiming Xiong, and Shafiq Joty. Mas-orchestra: Understanding and improving multi-agent reasoning through holistic orchestration and controlled benchmarks. ICML, 2026
2026
-
[19]
MAS- ZERO: Designing multi-agent systems with zero supervision.SEA@NeurIPS, 2025
Zixuan Ke, Austin Xu, Yifei Ming, Xuan-Phi Nguyen, Caiming Xiong, and Shafiq Joty. MAS- ZERO: Designing multi-agent systems with zero supervision.SEA@NeurIPS, 2025
2025
-
[20]
Yu Han Kim, Ken Gu, Chanwoo Park, Chunjong Park, Samuel Schmidgall, A. Ali Heydari, Yao Yan, Zhihan Zhang, Yuchen Zhuang, Yun Liu, Mark Malhotra, Paul Pu Liang, Hae Won Park, Yuzhe Yang, Xuhai Xu, Yi qing Du, Shwetak N. Patel, Tim Althoff, Daniel McDuff, and Xin Liu. Towards a science of scaling agent systems.ArXiv, abs/2512.08296, 2025
Pith/arXiv arXiv 2025
-
[21]
More agents is all you need
Junyou Li, Qin Zhang, Yangbin Yu, Qiang Fu, and Deheng Ye. More agents is all you need. Transactions on Machine Learning Research, 2024
2024
-
[23]
Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. A dynamic llm-powered agent network for task-oriented agent collaboration.arXiv preprint arXiv:2310.02170, 2024
Pith/arXiv arXiv 2024
-
[24]
Self-refine: Iterative refinement with self-feedback.Advances in Neural Information Processing Systems, 36, 2024
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[25]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. InThirty-seventh Conference on Neural Informati...
2023
-
[26]
Mirofish: A simple and universal swarm intelligence engine
MiroFish. Mirofish: A simple and universal swarm intelligence engine. https://github. com/666ghj/MiroFish, 2026
2026
-
[27]
Openclaw agents: A multi-agent configuration kit for openclaw
OpenClaw Agents. Openclaw agents: A multi-agent configuration kit for openclaw. https: //github.com/shenhao-stu/openclaw-agents, 2026
2026
-
[28]
Humanity’s last exam.arXiv preprint arXiv:2501.14249, 2025
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, et al. Humanity’s last exam.arXiv preprint arXiv:2501.14249, 2025
Pith/arXiv arXiv 2025
-
[29]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof qa benchmark, 2023
2023
-
[30]
Toolorchestra: Elevating intelligence via efficient model and tool orchestration, 2025
Hongjin Su, Shizhe Diao, Ximing Lu, Mingjie Liu, Jiacheng Xu, Xin Dong, Yonggan Fu, Peter Belcak, Hanrong Ye, Hongxu Yin, Yi Dong, Evelina Bakhturina, Tao Yu, Yejin Choi, Jan Kautz, and Pavlo Molchanov. Toolorchestra: Elevating intelligence via efficient model and tool orchestration, 2025
2025
-
[31]
Single-agent llms outperform multi-agent systems on multi-hop reasoning under equal thinking token budgets, 2026
Dat Tran and Douwe Kiela. Single-agent llms outperform multi-agent systems on multi-hop reasoning under equal thinking token budgets, 2026
2026
-
[32]
Mas-prove: Understanding the process verification of multi-agent systems.ICML, 2026
Vishal Venkataramani, Haizhou Shi, Zixuan Ke, Austin Xu, Xiaoxiao He, Yingbo Zhou, Semih Yavuz, Hao Wang, and Shafiq Joty. Mas-prove: Understanding the process verification of multi-agent systems.ICML, 2026. 11
2026
-
[33]
Mixture-of-agents enhances large language model capabilities.ArXiv, abs/2406.04692, 2024
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of-agents enhances large language model capabilities.ArXiv, abs/2406.04692, 2024
Pith/arXiv arXiv 2024
-
[34]
Weixun Wang, Jianye Hao, Yixi Wang, and Matthew E. Taylor. Achieving cooperation through deep multiagent reinforcement learning in sequential prisoner’s dilemmas.Proceedings of the First International Conference on Distributed Artificial Intelligence, 2019
2019
-
[35]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[36]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[37]
Andrea Wynn, Harsh Satija, and Gillian K Hadfield. Talk isn’t always cheap: Understanding failure modes in multi-agent debate.ArXiv, abs/2509.05396, 2025
arXiv 2025
-
[38]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Yuhao Zhou, Weiran Wang, Changhao Jiang, Yicheng Zou, Xiangyang Liu, Zhangyue Yin, Shihan Dou, Rongxiang Weng, Wensen Cheng, Qi Zhang, Wenjuan Qin, Yongyan Zheng, Xipeng Qiu, Xuanjing Huang, a...
Pith/arXiv arXiv 2023
-
[39]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[40]
Multi-agent architecture search via agentic supernet.arXiv preprint arXiv:2502.04180, 2025
Guibin Zhang, Luyang Niu, Junfeng Fang, Kun Wang, Lei Bai, and Xiang Wang. Multi-agent architecture search via agentic supernet.arXiv preprint arXiv:2502.04180, 2025
arXiv 2025
-
[41]
Multi-agent architecture search via agentic supernet, 2025
Guibin Zhang, Luyang Niu, Junfeng Fang, Kun Wang, Lei Bai, and Xiang Wang. Multi-agent architecture search via agentic supernet, 2025
2025
-
[42]
AFlow: Automating agentic workflow generation, 2025
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xiong-Hui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. AFlow: Automating agentic workflow generation, 2025
2025
-
[43]
Yao Zhang, Xiaogeng Liu, and Chaowei Xiao. Metaagent: Automatically constructing multi- agent systems based on finite state machines.ArXiv, abs/2507.22606, 2025
arXiv 2025
-
[44]
Han Zhou, Xingchen Wan, Xingchen Wan, Ruoxi Sun, Hamid Palangi, Shariq Iqbal, Ivan Vuli’c, Anna Korhonen, and Sercan Ö. Arik. Multi-agent design: Optimizing agents with better prompts and topologies.ArXiv, abs/2502.02533, 2025
arXiv 2025
-
[45]
Assistant
Yuxuan Zhu, Tengjun Jin, Yada Pruksachatkun, Andy K Zhang, Shu Liu, Sasha Cui, Sayash Kapoor, Shayne Longpre, Kevin Meng, Rebecca Weiss, Fazl Barez, Rahul Gupta, Jwala Dhamala, Jacob Merizian, Mario Giulianelli, Harry Coppock, Cozmin Ududec, Antony Keller- mann, Jasjeet S Sekhon, Jacob Steinhardt, Sarah Schwettmann, Arvind Narayanan, Matei Zaharia, Ion St...
2025
-
[46]
Stock Data Sampling.For each sample, we randomly select a target transaction type (buy/sell), price type (open/close), and a target profit/loss percentage. The number of investors (parallelizable threads), the breadth B (total number of stocks traded), and the depth D (number of transactions per investor) of the dataset are varied to give us a range of co...
-
[47]
Needle-in-a-Haystack
Haystack construction.Each instance follows a "Needle-in-a-Haystack" architecture. The Haystackconsists of 30-day OHLCV histories of B sampled stocks formatted as price tables, interleaved with additional distractor stocks to increase retrieval difficulty
-
[48]
Each investor receives D completed buy–sell pairs drawn from distinct stocks, plus one open position (the target stock) shared across all investors
Needle construction.TheNeedleconsists of specific investor transaction histories em- bedded within the context. Each investor receives D completed buy–sell pairs drawn from distinct stocks, plus one open position (the target stock) shared across all investors. The open position determines the dates on which the profit target can be achieved. 14 Figure 8: ...
1996
-
[49]
Answer computation.The reference answer and chain-of-thought are computed determin- istically from the sampled prices and transactions
-
[50]
Samples with no valid qualifying dates are retried with a new seed
Quality filtering.To limit null answers, the open transaction date is sampled from the first or last 25% of the time window. Samples with no valid qualifying dates are retried with a new seed. 16 Table 5: Role configurations and corresponding system prompts for each dataset in DyLAN. Dataset Role Name System Prompt ALLAssistant You are a super-intelligent...
-
[51]
This agent produces a structured JSON schema that drives the downstream orchestration, but performs no numerical reasoning itself
The Meta-Agent:A specialized agent that acts as a structural parser, responsible for extracting the problem’s topology (investor names, profit targets, and aggregation criteria). This agent produces a structured JSON schema that drives the downstream orchestration, but performs no numerical reasoning itself
-
[52]
It is prompted to locate specific transaction dates and prices as needed, effectively acting as a high-precision filter
The ExtractorAgent:A reusable retrieval unit tasked with targeted information extraction from the 50k+ token haystack. It is prompted to locate specific transaction dates and prices as needed, effectively acting as a high-precision filter
-
[53]
optimized
The CalculatorAgent:A numerical reasoning unit that computes realized P&L and derives target price thresholds. By providing this agent only with the relevant extracted snippets, we ensure its reasoning window remains uncluttered by distractor tickers. Deterministic Orchestration and ParallelismA significant departure from automated MAS is our use of aPyth...
-
[54]
Extreme Primacy:GPT-4o exhibits a severe bias toward the initial block (index 0, vanilla CoT), selecting it in over 45% of instances, while CoT-SC (index 1) remains a distant secondary choice
-
[55]
Broadened Initial Bias:GPT-5 demonstrates a slightly more distributed but still front-loaded preference, favoring the first four fundamental reasoning blocks (indices 0–3) while largely ignoring subsequent iterations
-
[56]
expensive witnesses
Blocks corresponding to later search rounds (indices 4–8) are rarely selected by either model, accounting for less than 15% of total selections combined. Consequently, the complex MAS architecture suffers from structural redundancy: subsequent worker agents function as "expensive witnesses", incurring full inference costs while exerting zero causal influe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.