Heterogeneous Information-Bottleneck Coordination Graphs for Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-20 13:02 UTC · model grok-4.3
The pith
HIBCG learns sparse coordination graphs with closed-form criteria for both edge existence and per-agent message capacity using a group-aligned block-diagonal prior in the graph information bottleneck.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
With the graph information bottleneck serving as the underlying tool, HIBCG constructs a group-aligned block-diagonal prior that provides a closed-form criterion for edge retention and then controls per-agent feature bandwidth on the resulting topology, with proofs that the prior strictly tightens the variational bound, the objective decomposes per group block, and capacity allocation follows a water-filling principle.
What carries the argument
The group-aligned block-diagonal prior inside the graph information bottleneck, which supplies the closed-form edge-retention criterion and permits the objective to decompose for differential per-group control.
If this is right
- The variational bound on topology learning is strictly tightened by the group-aligned prior.
- The overall objective decomposes per group block, allowing independent control of edge density in different groups.
- Message capacity is allocated across agents according to a water-filling principle that keeps only task-relevant information.
- Both the decision of which edges exist and how much capacity each carries receive explicit theoretical justification rather than heuristic selection.
Where Pith is reading between the lines
- The block-diagonal construction could be tested by measuring whether learned graphs become sparser yet more effective when the task naturally contains group structure.
- If groups must be discovered rather than given, joint inference of partitions alongside the graph might preserve the closed-form benefits while broadening applicability.
- The water-filling capacity rule suggests that agents with more intra-group connections would receive proportionally different bandwidth, which could be verified by inspecting per-agent compression rates in trained models.
Load-bearing premise
That agents can be partitioned into groups such that a block-diagonal prior on the coordination graph produces a closed-form, task-relevant criterion for edge retention and remains compatible with the graph information bottleneck objective.
What would settle it
In a multi-agent environment with known group partitions, the graphs learned by HIBCG either violate the expected block-diagonal structure or yield no improvement in task reward and total communication volume compared with heuristic sparse-graph baselines.
Figures





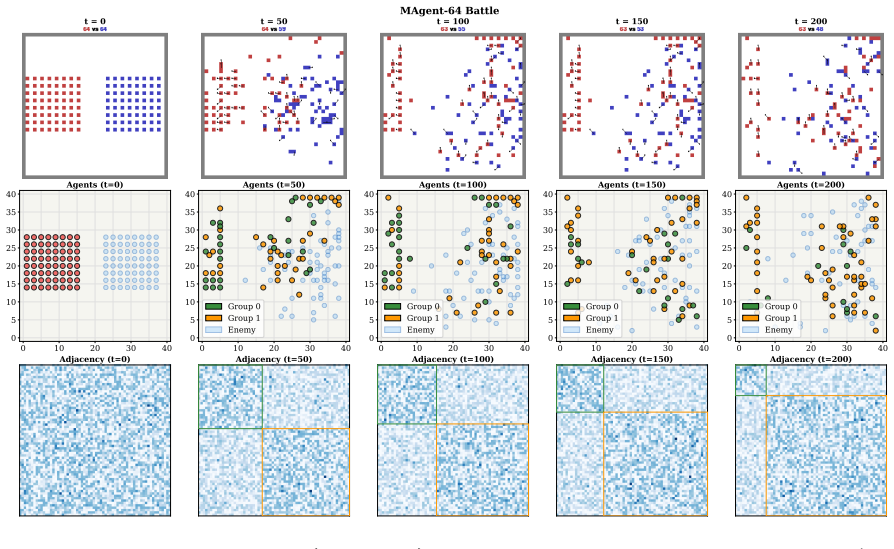


read the original abstract
Coordination graphs are a central abstraction in cooperative multi-agent reinforcement learning (MARL), yet existing sparse-graph learners lack a theoretically grounded mechanism to decide which edges should exist and how much information each edge should carry. Current methods rely on heuristic criteria that offer no formal guarantee on the learned topology, and no principled way to allocate different communication capacities to structurally different agent relationships. To address this, we propose Heterogeneous Information-Bottleneck Coordination Graphs (HIBCG), which learns a group-aware sparse graph in which both edge existence and message capacity are theoretically justified. With the graph information bottleneck (GIB) serving as the underlying tool, HIBCG first constructs a group-aligned block-diagonal prior that provides a closed-form criterion for edge retention -- determining which edges should exist and at what density per group block -- and then controls per-agent feature bandwidth on the resulting topology, compressing messages to retain only task-relevant content. We prove that the group-aligned prior strictly tightens the variational bound on topology learning, that the objective decomposes per group block, enabling differential edge control, and that capacity allocation follows a water-filling principle.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Heterogeneous Information-Bottleneck Coordination Graphs (HIBCG) for cooperative multi-agent reinforcement learning. Building on the graph information bottleneck (GIB) framework, it introduces a group-aligned block-diagonal prior over the coordination graph that supplies a closed-form criterion for edge retention and per-group density. The method then compresses per-agent messages while allocating heterogeneous capacities according to a water-filling rule. The authors claim three theoretical results: the block-diagonal prior strictly tightens the GIB variational bound, the objective decomposes across group blocks, and capacity allocation follows the water-filling principle.
Significance. If the claimed proofs hold and the group-partition assumption can be satisfied without external domain knowledge, the work would supply the first information-theoretically justified mechanism for jointly learning sparse topology and heterogeneous message capacities in MARL. This could improve both sample efficiency and interpretability relative to heuristic sparsity methods, while extending GIB techniques to structured multi-agent settings.
major comments (2)
- [§3.2] §3.2 (Group-Aligned Prior Construction): The derivation of the closed-form edge-retention criterion rests on a static partition of agents into groups that produces a block-diagonal prior. The manuscript does not specify how this partition is obtained in general environments; if it is supplied by the user or by an unstated preprocessing step rather than derived from the GIB objective, the claimed strict tightening of the variational bound and the per-block decomposition become conditional on an external assumption that is not guaranteed when coordination structures are overlapping or dynamic.
- [Theorem 1] Theorem 1 (Variational Bound Tightening): The proof that the group-aligned prior strictly improves the GIB bound should explicitly quantify the approximation error introduced when inter-group edges that carry task-relevant information are pruned by the block-diagonal structure. Without this quantification, it is unclear whether the tightening holds in environments where optimal coordination crosses the assumed group boundaries.
minor comments (2)
- [§3.1] Notation for the block-diagonal prior matrix (Eq. 7) is introduced without an explicit definition of the group indicator matrix; adding a short paragraph or diagram would improve readability.
- [§5] The experimental section reports performance gains but does not include an ablation that isolates the contribution of the water-filling allocation versus uniform capacity; such a control would strengthen the empirical support for the heterogeneous-capacity claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments on our manuscript. We address each of the major comments below, providing clarifications and indicating the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Group-Aligned Prior Construction): The derivation of the closed-form edge-retention criterion rests on a static partition of agents into groups that produces a block-diagonal prior. The manuscript does not specify how this partition is obtained in general environments; if it is supplied by the user or by an unstated preprocessing step rather than derived from the GIB objective, the claimed strict tightening of the variational bound and the per-block decomposition become conditional on an external assumption that is not guaranteed when coordination structures are overlapping or dynamic.
Authors: We appreciate the referee pointing out the need for clarity on the group partition. The manuscript assumes that the partition into groups is provided as input, either from domain knowledge or as a preprocessing step based on agent similarities, which is a standard assumption in structured MARL settings. This allows the block-diagonal prior to be constructed and yields the closed-form criterion and decomposition. To address this comment, we will revise the manuscript to explicitly describe possible ways to obtain the partition (e.g., via clustering on agent state representations) and discuss the implications when the partition does not perfectly align with the optimal coordination structure. We will also emphasize that the theoretical results hold under this modeling assumption. revision: yes
-
Referee: [Theorem 1] Theorem 1 (Variational Bound Tightening): The proof that the group-aligned prior strictly improves the GIB bound should explicitly quantify the approximation error introduced when inter-group edges that carry task-relevant information are pruned by the block-diagonal structure. Without this quantification, it is unclear whether the tightening holds in environments where optimal coordination crosses the assumed group boundaries.
Authors: Theorem 1 proves that the group-aligned block-diagonal prior leads to a strictly tighter variational bound than the standard GIB by reducing the feasible set of graphs, which decreases the upper bound on the relevant mutual information. This tightening is strict in the sense that the bound is lower (tighter) for any fixed partition. However, we agree that in cases where important coordination occurs across groups, pruning those edges introduces an approximation. Providing a general quantification of this error without environment-specific assumptions is not feasible within the current framework, as it would require bounding the information loss from excluded edges. In the revision, we will include a discussion of this limitation following the proof of Theorem 1, noting the trade-off and suggesting that the method is most suitable when groups can be chosen to capture the primary coordination patterns. revision: partial
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper applies the established graph information bottleneck (GIB) objective to MARL coordination graphs and introduces a group-aligned block-diagonal prior as a modeling choice that enables closed-form edge retention and per-block decomposition. The claimed tightening of the variational bound and objective decomposition follow directly from substituting the block-diagonal structure into the GIB variational form, which is a standard algebraic step rather than a redefinition of the inputs. Capacity allocation is identified with the water-filling solution from rate-distortion theory, an external mathematical result applied after the topology is fixed. No equation reduces a claimed prediction or proof to a fitted parameter or self-citation by construction, and the group partition is treated as an assumption compatible with the objective rather than derived from it. The central results therefore retain independent content beyond the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agents in the target MARL tasks admit a grouping that permits construction of a group-aligned block-diagonal prior providing a closed-form edge-retention criterion.
Reference graph
Works this paper leans on
-
[1]
Learning multiagent communication with backpropagation,
S. Sukhbaatar, R. Ferguset al., “Learning multiagent communication with backpropagation,” inAd- vances in Neural Information Processing Systems (NeurIPS), vol. 29, 2016
work page 2016
-
[2]
Learning attentional communication for multi-agent cooperation,
J. Jiang and Z. Lu, “Learning attentional communication for multi-agent cooperation,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018
work page 2018
-
[4]
A survey of multi-agent deep reinforcement learning with communication,
C. Guo, H. Li, D. Qiu, H. Li, Y. Zhang, P. Liet al., “A survey of multi-agent deep reinforcement learning with communication,”Autonomous Agents and Multi-Agent Systems, vol. 38, no. 1, p. 13, 2024
work page 2024
-
[5]
Learning to communicate with deep multi-agent reinforcement learning,
J. Foerster, I. A. Assael, N. de Freitas, and S. Whiteson, “Learning to communicate with deep multi-agent reinforcement learning,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 29, 2016
work page 2016
-
[6]
Partially observable multi-agent rl with (quasi-)efficiency: The blessing of in- formation sharing,
X. Liu and K. Bai, “Partially observable multi-agent rl with (quasi-)efficiency: The blessing of in- formation sharing,” inInternational Conference on Machine Learning (ICML). PMLR, 2023, pp. 22 106–22 130
work page 2023
-
[7]
Bayesian ego-graph inference for networked multi-agent reinforcement learning,
W. Duan, J. Lu, and J. Xuan, “Bayesian ego-graph inference for networked multi-agent reinforcement learning,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NIPS 2025), 2025
work page 2025
-
[8]
Context-aware sparse deep coordination graphs,
T. Yang, J. Wang, L. Wu, and C. Zhang, “Context-aware sparse deep coordination graphs,” inInter- national Conference on Learning Representations (ICLR), 2022
work page 2022
-
[9]
Self-organized polynomial-time co- ordination graphs,
Q. Yang, W. Dong, Z. Ren, J. Wang, T. Wang, and C. Zhang, “Self-organized polynomial-time co- ordination graphs,” inInternational Conference on Machine Learning (ICML), vol. 162, 2022, pp. 24 963–24 979. 40
work page 2022
-
[10]
Group-aware coordination graph for multi-agent reinforcement learning,
W. Duan, J. Lu, and J. Xuan, “Group-aware coordination graph for multi-agent reinforcement learning,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI), 2024, pp. 3926–3934
work page 2024
-
[11]
Networked agents in the dark: Team value learning under partial observability,
G. S. Varela, A. Sardinha, and F. S. Melo, “Networked agents in the dark: Team value learning under partial observability,” inProceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems, AAMAS 2025, Detroit, MI, USA, May 19-23, 2025. International Foundation for Autonomous Agents and Multiagent Systems / ACM, 2025, pp. 2087–2095
work page 2025
-
[12]
Deep implicit coordination graphs for multi-agent reinforcement learning,
S. Li, J. K. Gupta, P. Morales, R. E. Allen, and M. J. Kochenderfer, “Deep implicit coordination graphs for multi-agent reinforcement learning,” inProceedings of the 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2021, pp. 764–772
work page 2021
-
[13]
Multi-agent game abstraction via graph attention neural network,
Y. Liu, W. Wang, Y. Hu, J. Hao, X. Chen, and Y. Gao, “Multi-agent game abstraction via graph attention neural network,” inAAAI Conference on Artificial Intelligence, 2020, pp. 7211–7218
work page 2020
-
[14]
Dynamic deep factor graph for multi-agent reinforcement learning,
Y. Shi, S. Duan, C. Xu, R. Wang, F. Ye, and C. Yuen, “Dynamic deep factor graph for multi-agent reinforcement learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 3, pp. 3417–3431, 2026
work page 2026
-
[15]
Semi-supervised classification with graph convolutional networks,
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” in5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017
work page 2017
-
[16]
Learning from the dark: Boosting graph convolutional neural networks with diverse negative samples,
W. Duan, J. Xuan, M. Qiao, and J. Lu, “Learning from the dark: Boosting graph convolutional neural networks with diverse negative samples,” inThirty-Sixth AAAI Conference on Artificial Intelligence (AAAI 2022), Virtual Event. AAAI Press, 2022, pp. 6550–6558
work page 2022
-
[17]
Layer-diverse negative sampling for graph neural networks,
W. Duan, J. Lu, Y. G. Wang, and J. Xuan, “Layer-diverse negative sampling for graph neural networks,” Transactions on Machine Learning Research, 2024
work page 2024
-
[18]
W. Duan, J. Xuan, M. Qiao, and J. Lu, “Graph convolutional neural networks with diverse negative samples via decomposed determinant point processes,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 12, pp. 18 160–18 171, 2024
work page 2024
-
[19]
Mecon: A gnn-based graph classification framework for MEV activity detection,
Z. Yao, F. Huang, Y. Li, W. Duan, P. Qian, N. Yang, and W. Susilo, “Mecon: A gnn-based graph classification framework for MEV activity detection,”Expert Syst. Appl., vol. 269, p. 126486, 2025
work page 2025
-
[20]
Graph convolutional reinforcement learning,
J. Jiang, C. Dun, T. Huang, and Z. Lu, “Graph convolutional reinforcement learning,” inInternational Conference on Learning Representations (ICLR), 2020
work page 2020
-
[21]
Nervenet: Learning structured policy with graph neural networks,
T. Wang, R. Liao, J. Ba, and S. Fidler, “Nervenet: Learning structured policy with graph neural networks,” inInternational Conference on Learning Representations (ICLR), 2018
work page 2018
-
[22]
W. B¨ ohmer, V. Kurin, and S. Whiteson, “Deep coordination graphs,” inInternational Conference on Machine Learning (ICML), vol. 119. PMLR, 2020, pp. 980–991
work page 2020
-
[23]
Tarmac: Targeted multi- agent communication,
A. Das, T. Gervet, J. Romoff, D. Batra, D. Parikh, M. Rabbat, and J. Pineau, “Tarmac: Targeted multi- agent communication,” inInternational Conference on Machine Learning (ICML). PMLR, 2019, pp. 1538–1546
work page 2019
-
[24]
Multi-agent graph-attention communication and teaming,
Y. Niu, R. R. Paleja, and M. C. Gombolay, “Multi-agent graph-attention communication and teaming,” inProceedings of the 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2021, pp. 964–973
work page 2021
-
[25]
Inferring latent temporal sparse coordination graph for multiagent reinforcement learning,
W. Duan, J. Lu, and J. Xuan, “Inferring latent temporal sparse coordination graph for multiagent reinforcement learning,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 8, pp. 14 358–14 370, 2025. 41
work page 2025
-
[26]
Learning multi-agent communication from graph modeling perspective,
S. He, H. Ni, J. Wang, L. Wu, and C. Zhang, “Learning multi-agent communication from graph modeling perspective,” inInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[27]
B. Lin and C. Lee, “HGAP: boosting permutation invariant and permutation equivariant in multi-agent reinforcement learning via graph attention network,” inForty-first International Conference on Machine Learning, (ICML 2024), Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024
work page 2024
-
[28]
J. Weil, Z. Bao, O. Abboud, and T. Meuser, “Towards generalizability of multi-agent reinforcement learning in graphs with recurrent message passing,” inProceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, (AAMAS 2024), Auckland, New Zealand, May 6-10, 2024, 2024, pp. 1919–1927
work page 2024
-
[29]
Hierarchical cooperative multi-agent reinforcement learning with skill discovery,
J. Yang, I. Borovikov, and H. Zha, “Hierarchical cooperative multi-agent reinforcement learning with skill discovery,” inProceedings of the 19th International Conference on Autonomous Agents and Multi- agent Systems (AAMAS), 2020, pp. 1566–1574
work page 2020
-
[30]
Exponential topology-enabled scalable communication in multi- agent reinforcement learning,
X. Li, X. Wang, C. Bai, and J. Zhang, “Exponential topology-enabled scalable communication in multi- agent reinforcement learning,” inInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[31]
Roma: Multi-agent reinforcement learning with emergent roles,
T. Wang, H. Dong, V. Lesser, and C. Zhang, “Roma: Multi-agent reinforcement learning with emergent roles,” inInternational Conference on Machine Learning (ICML), 2020, pp. 9876–9886
work page 2020
-
[32]
VAST: Value function factorization with variable agent sub-teams,
T. Phan, F. Ritz, L. Belzner, P. Altmann, T. Gabor, and C. Linnhoff-Popien, “VAST: Value function factorization with variable agent sub-teams,” inAdvances in Neural Information Processing Systems (NeurIPS), 2021, pp. 24 018–24 032
work page 2021
-
[33]
REFIL: Randomized extrapolation for multi-agent reinforcement learning,
S. Iqbal, C. A. S. de Witt, B. Peng, W. B¨ ohmer, S. Whiteson, and F. Sha, “REFIL: Randomized extrapolation for multi-agent reinforcement learning,” inInternational Conference on Machine Learning (ICML), 2021, pp. 4555–4566
work page 2021
-
[34]
Self-organized group for cooperative multi-agent reinforcement learning,
Y. Pan, J. Chen, B. Huang, D. Wang, and H. Deng, “Self-organized group for cooperative multi-agent reinforcement learning,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[35]
Group-oriented multi-agent reinforcement learning,
Z. Li, P. Liu, J. Chen, and C. Zhang, “Group-oriented multi-agent reinforcement learning,” inInterna- tional Conference on Machine Learning (ICML), 2023
work page 2023
-
[36]
Learning to schedule communication in multi-agent reinforcement learning,
D. Kim, S. Moon, D. Hostallero, W. J. Kang, T. Lee, K. Son, and Y. Yi, “Learning to schedule communication in multi-agent reinforcement learning,” in7th International Conference on Learning Representations, ICLR 2019, 2019
work page 2019
-
[37]
Learning agent communication under limited band- width by message pruning,
H. Mao, Z. Zhang, Z. Xiao, Z. Gong, and Y. Ni, “Learning agent communication under limited band- width by message pruning,” inThe Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Int...
work page 2020
-
[38]
Asynchronous cooperative multi-agent rein- forcement learning with limited communication,
S. Dolan, S. Nayak, J. J. Aloor, and H. Balakrishnan, “Asynchronous cooperative multi-agent rein- forcement learning with limited communication,” inProceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems, (AAMAS 2025), Detroit, MI, USA, May 19-23, 2025. International Foundation for Autonomous Agents and Multiagent Syst...
work page 2025
-
[39]
Learning nearly decomposable value functions via com- munication minimization,
T. Wang, J. Wang, C. Zheng, and C. Zhang, “Learning nearly decomposable value functions via com- munication minimization,” inInternational Conference on Learning Representations (ICLR), 2020
work page 2020
-
[40]
Multi-agent shared information aggregation for cooperative multi-agent rein- forcement learning,
T. Wang and C. Zhang, “Multi-agent shared information aggregation for cooperative multi-agent rein- forcement learning,” inInternational Conference on Machine Learning (ICML), 2023
work page 2023
-
[41]
Robust multi-agent communication with graph information bottleneck optimization,
S. Ding, W. Du, L. Ding, J. Zhang, L. Guo, and B. An, “Robust multi-agent communication with graph information bottleneck optimization,”IEEE Transactions on Pattern Analysis and Machine In- telligence, vol. 46, no. 5, pp. 3096–3107, 2024. 42
work page 2024
-
[42]
The information bottleneck method,
N. Tishby, F. C. Pereira, and W. Bialek, “The information bottleneck method,”Proceedings of the 37th Annual Allerton Conference on Communication, Control, and Computing, pp. 368–377, 1999
work page 1999
-
[43]
T. Wu, H. Ren, P. Li, and J. Leskovec, “Graph information bottleneck,”Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 20 437–20 448, 2020
work page 2020
-
[44]
Deep variational information bottleneck,
A. A. Alemi, I. Fischer, J. V. Dillon, and K. Murphy, “Deep variational information bottleneck,” in International Conference on Learning Representations (ICLR), 2017
work page 2017
-
[45]
Generalization in reinforcement learning with selective noise injection and information bottleneck,
M. Igl, K. Ciosek, Y. Li, S. Tschiatschek, C. Zhang, S. Devlin, and K. Hofmann, “Generalization in reinforcement learning with selective noise injection and information bottleneck,” inAdvances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Cana...
work page 2019
-
[46]
Bandwidth-constrained variational message encoding for multi-agent co- ordination,
W. Duan, J. Lu, and J. Xuan, “Bandwidth-constrained variational message encoding for multi-agent co- ordination,” inProceedings of the 25th International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2026
work page 2026
-
[47]
Z. Liu, L. Wan, S. Sun, X. Sui, X. Chen, X. Lan, and N. Zheng, “Enhancing value decomposition with target transformation in cooperative multi-agent reinforcement learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–17, 2026
work page 2026
-
[48]
Efficient exploration for multi-agent diversity with agent identity,
T. Li and K. Zhu, “Efficient exploration for multi-agent diversity with agent identity,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, vol. 48, no. 5, pp. 5460–5473, 2026
work page 2026
-
[49]
Randomized exploration in cooperative multi-agent rein- forcement learning,
H. Hsu, W. Wang, M. Pajic, and P. Xu, “Randomized exploration in cooperative multi-agent rein- forcement learning,” inAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems (NeurIPS 2024), Vancouver, BC, Canada, December 10 - 15, 2024
work page 2024
-
[50]
Trust region policy optimisa- tion in multi-agent reinforcement learning,
J. G. Kuba, R. Chen, M. Wen, Y. Wen, F. Sun, J. Wang, and Y. Yang, “Trust region policy optimisa- tion in multi-agent reinforcement learning,” inInternational Conference on Learning Representations (ICLR), 2022
work page 2022
-
[51]
Resilient contrastive pre-training under non-stationary drift,
X. Yang, J. Lu, E. Yu, and W. Duan, “Resilient contrastive pre-training under non-stationary drift,”
-
[52]
Available: https://arxiv.org/abs/2502.07620
[Online]. Available: https://arxiv.org/abs/2502.07620
-
[53]
X. Yang, J. Lu, and E. Yu, “Walking the tightrope: Autonomous disentangling beneficial and detrimental drifts in non-stationary custom-tuning,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id= 1BAiQmAFsx
work page 2025
-
[54]
Adapting multi-modal large language model to concept drift from pre-training onwards,
——, “Adapting multi-modal large language model to concept drift from pre-training onwards,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=b20VK2GnSs
work page 2025
-
[55]
Drift-aware collaborative assistance mixture of experts for heterogeneous multistream learning,
E. Yu, J. Lu, K. Wang, X. Yang, and G. Zhang, “Drift-aware collaborative assistance mixture of experts for heterogeneous multistream learning,”arXiv preprint arXiv:2508.01598, 2025
-
[56]
F. A. Oliehoek and C. Amato,A Concise Introduction to Decentralized POMDPs, ser. Springer Briefs in Intelligent Systems. Springer, 2016
work page 2016
-
[57]
QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning,
T. Rashid, M. Samvelyan, C. S. de Witt, G. Farquhar, J. N. Foerster, and S. Whiteson, “QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning,” inProceedings of the 35th International Conference on Machine Learning (ICML 2018), Stockholmsm¨ assan, Stockholm, Sweden, vol. 80, 2018, pp. 4292–4301
work page 2018
-
[58]
T. M. Cover and J. A. Thomas,Elements of Information Theory, 2nd ed. Wiley-Interscience, 2006. 43
work page 2006
-
[59]
The starcraft multi-agent challenge,
M. Samvelyan, T. Rashid, C. Schr¨ oder de Witt, G. Farquhar, N. Nardelli, T. G. J. Rudner, C.-M. Hung, P. H. S. Torr, J. Foerster, and S. Whiteson, “The starcraft multi-agent challenge,” inProceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), 2019, pp. 2186–2188
work page 2019
-
[60]
Smacv2: An improved benchmark for cooperative multi-agent reinforcement learning,
B. Ellis, J. Cook, S. Moalla, M. Samvelyan, M. Sun, A. Mahajan, J. N. Foerster, and S. Whiteson, “Smacv2: An improved benchmark for cooperative multi-agent reinforcement learning,” inThe 36th Annual Conference on Neural Information Processing Systems (NeurIPS 2023), New Orleans, LA, USA, December 10 - 16, 2023
work page 2023
-
[61]
Magent: A many-agent re- inforcement learning platform for artificial collective intelligence,
L. Zheng, J. Yang, H. Cai, M. Zhou, W. Zhang, J. Wang, and Y. Yu, “Magent: A many-agent re- inforcement learning platform for artificial collective intelligence,” inAAAI Conference on Artificial Intelligence, 2018, pp. 8222–8223. 44
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.