On the Nonlinearity of Learning Rate Scaling for LLM Training
Pith reviewed 2026-06-30 08:12 UTC · model grok-4.3
The pith
The optimal learning rate develops upward curvature at larger scales, leading to inaccurate extrapolation from smaller models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
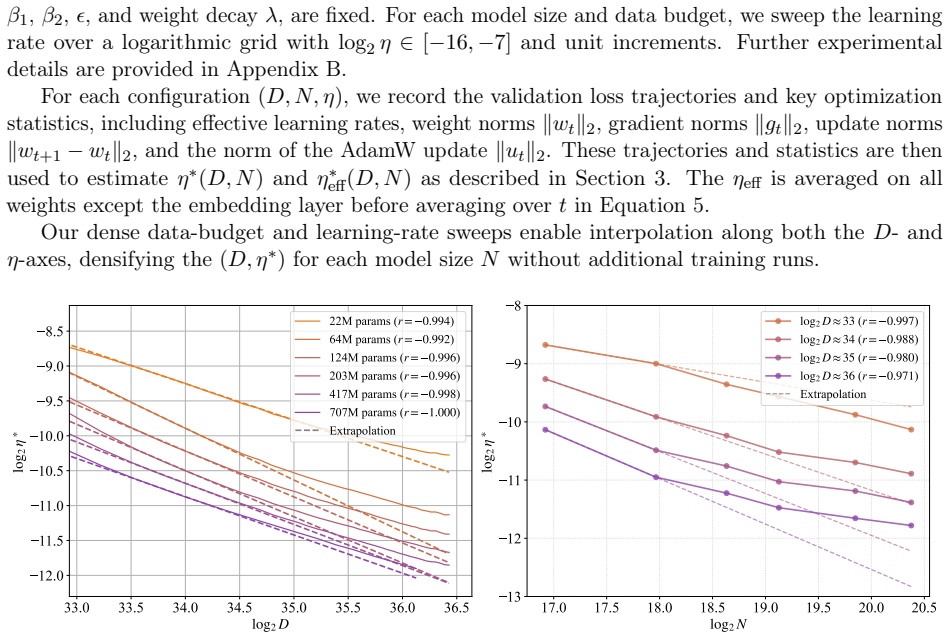
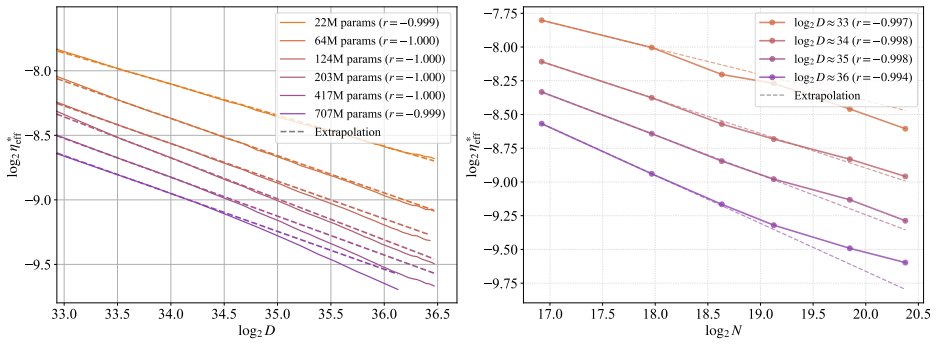
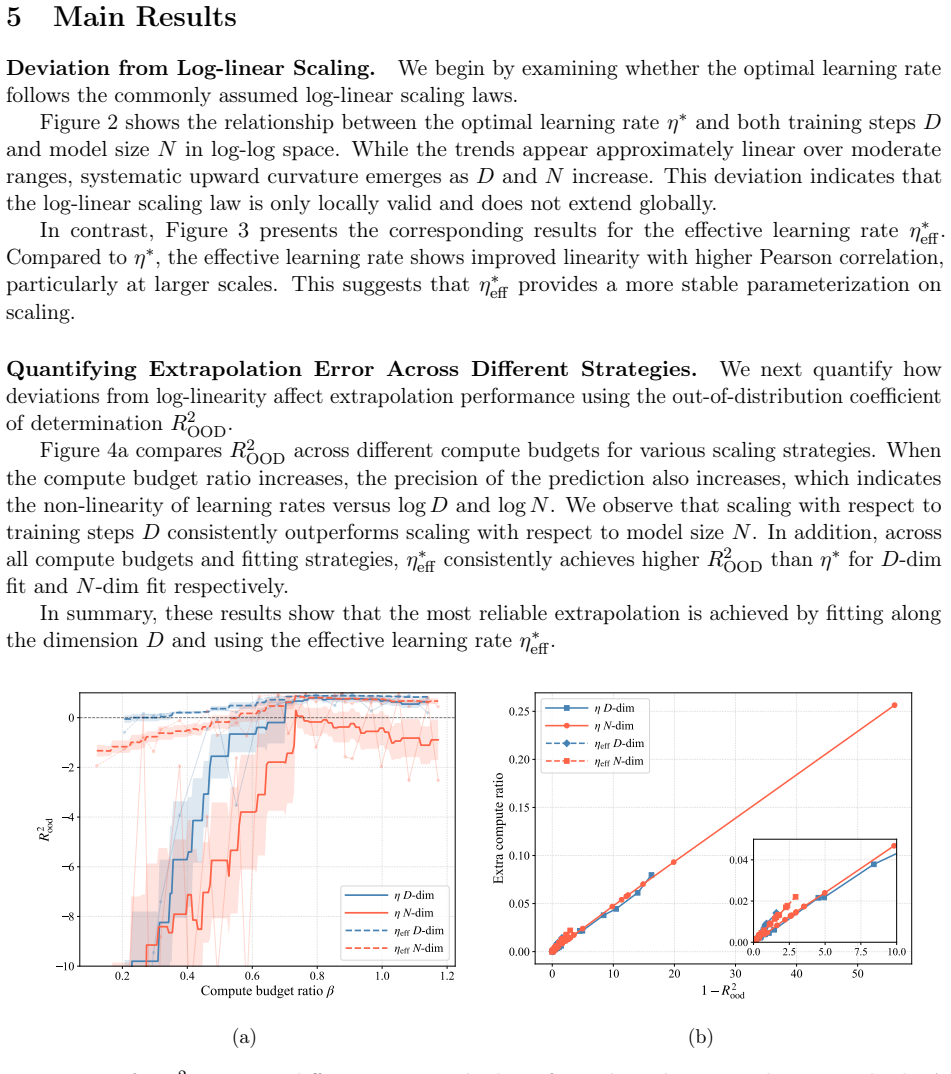
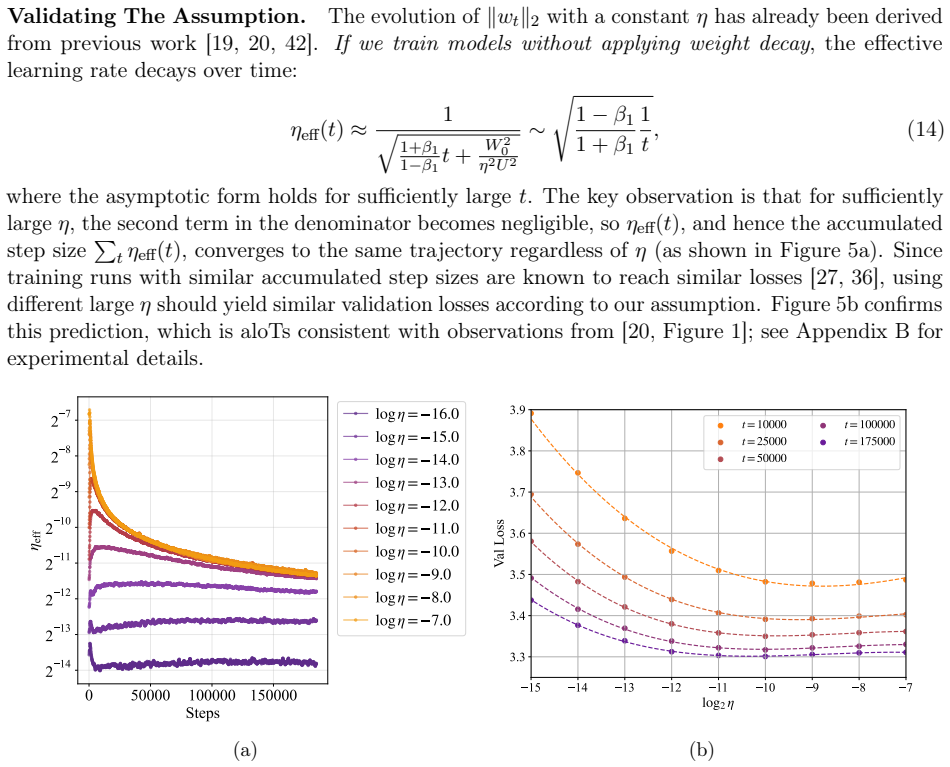
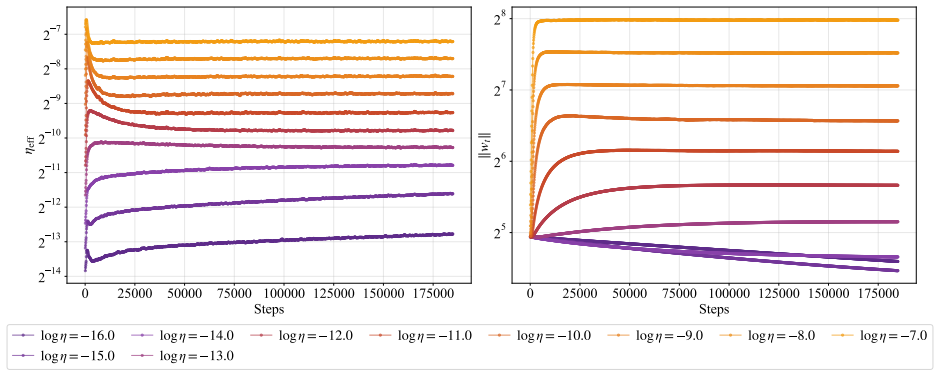
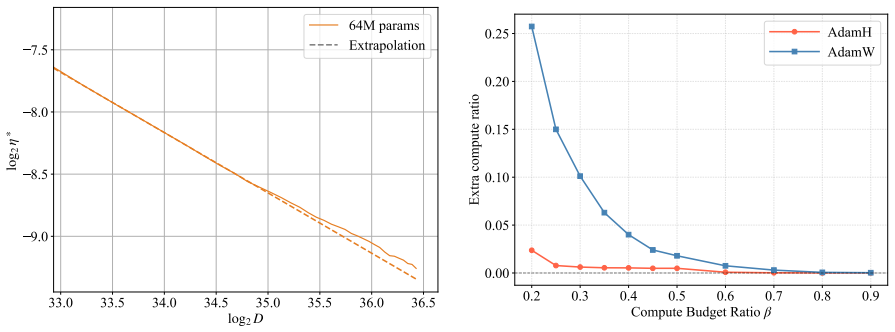
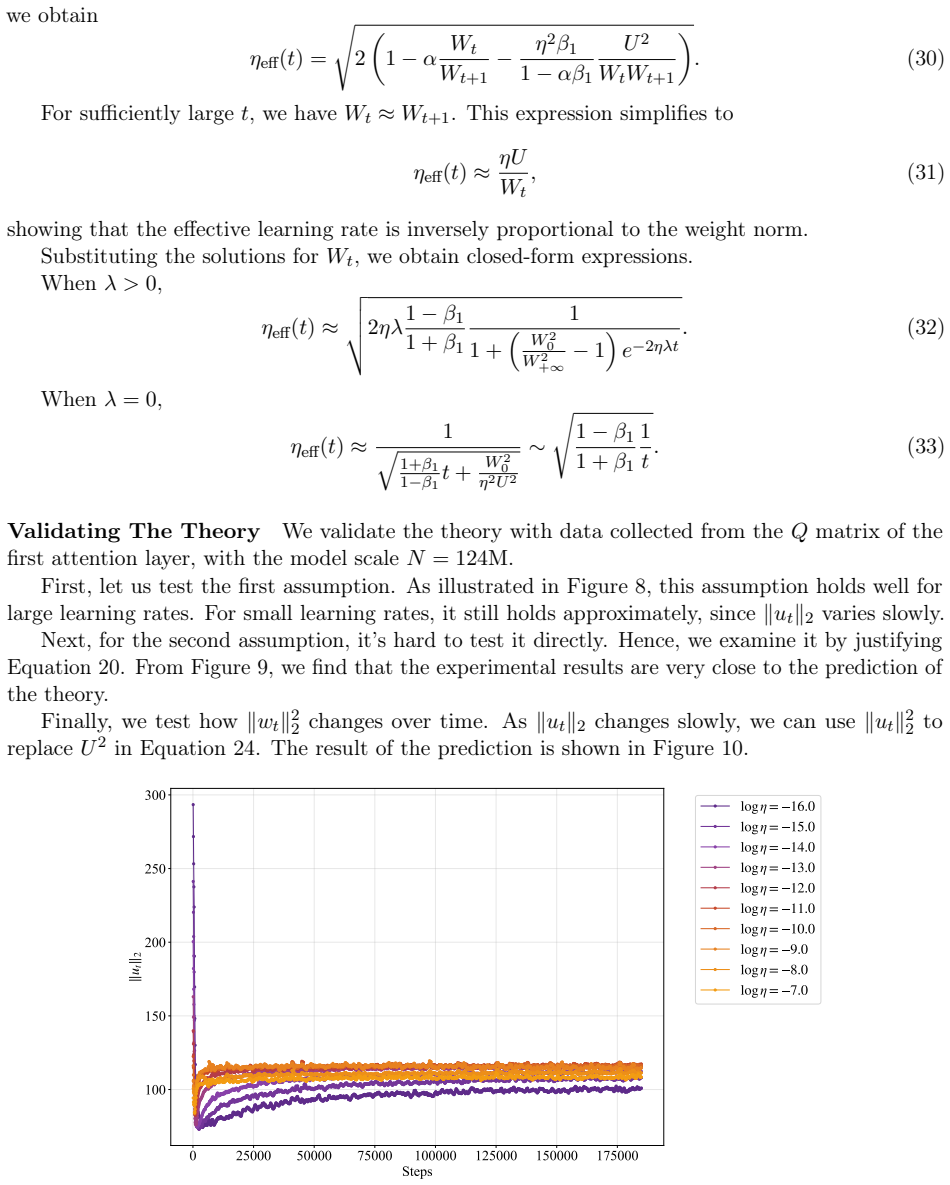
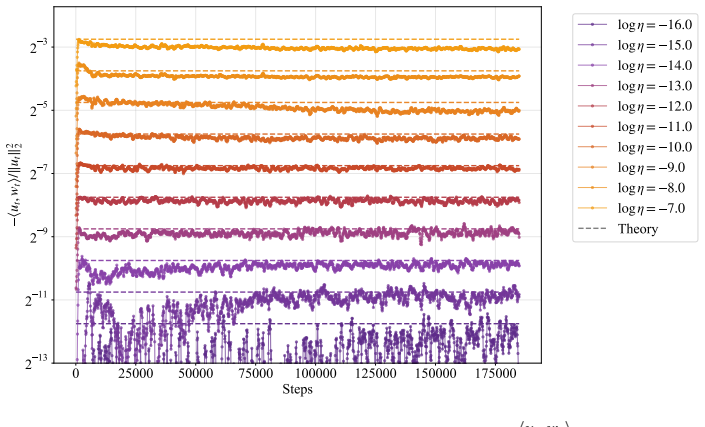
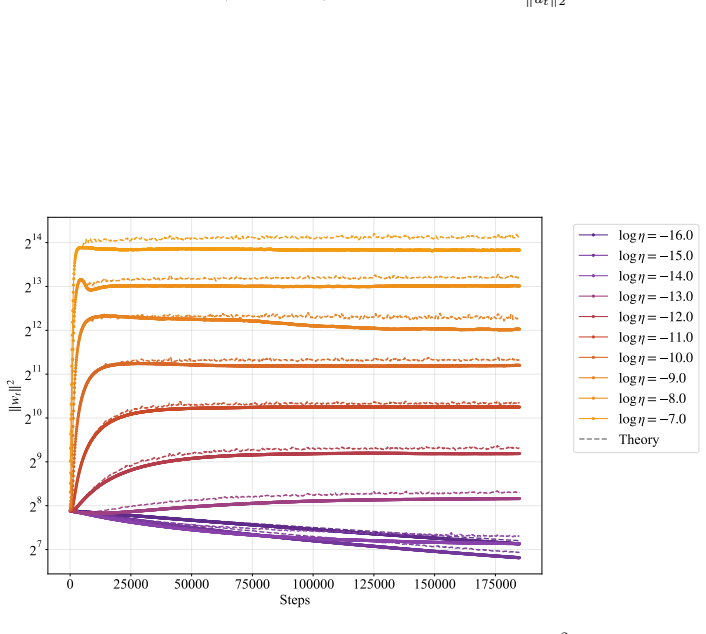
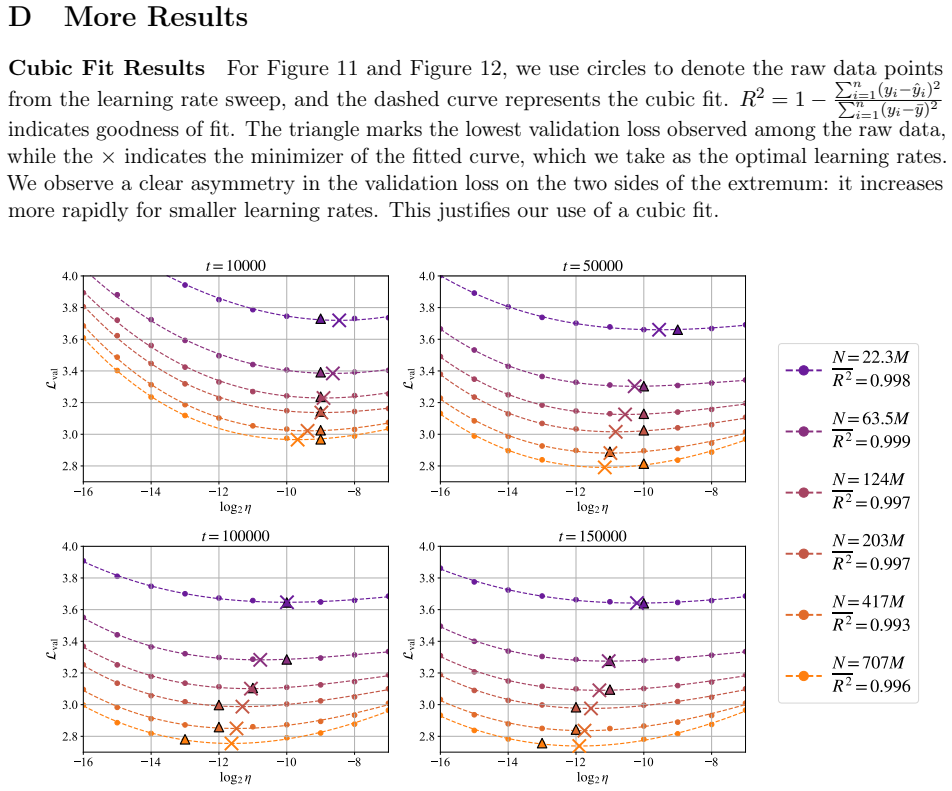
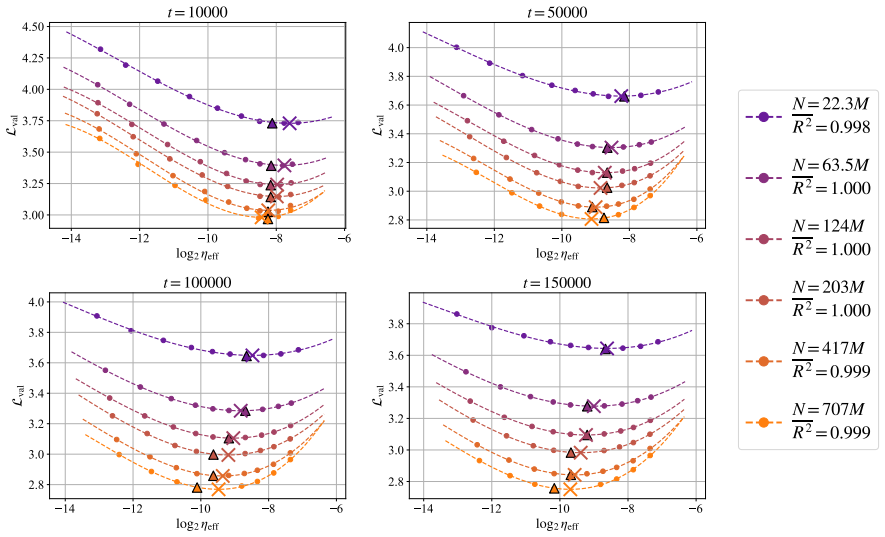
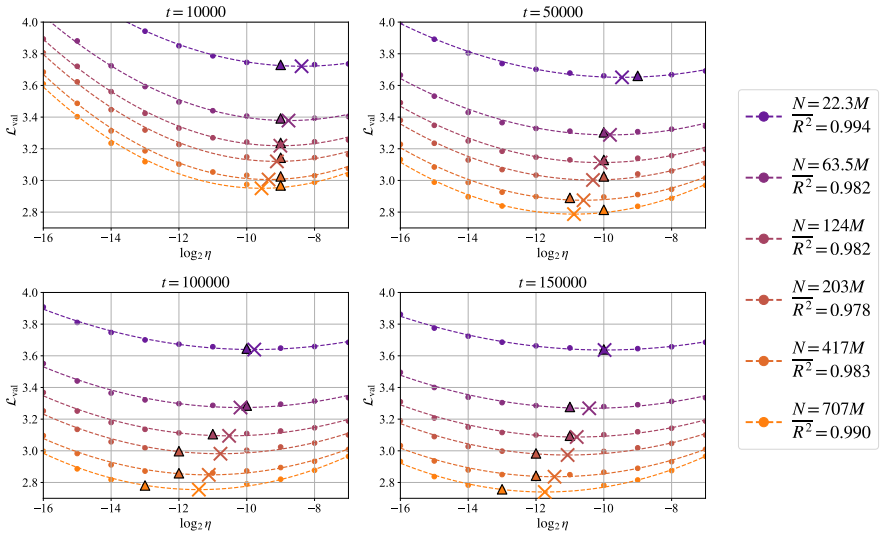
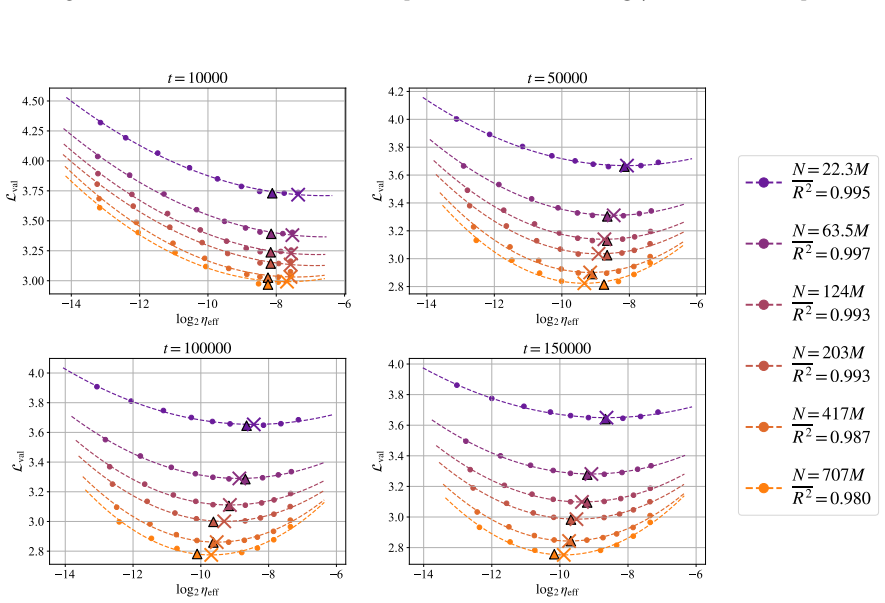
In training runs from 22M to 707M parameters on 5B to 100B tokens, the optimal learning rate exhibits upward curvature at larger scales. This curvature largely disappears when learning rates are replaced by effective learning rate and when data D extrapolation is used instead of model size N extrapolation. Weight-norm converges to equilibrium slower when optimal learning is small, requiring a larger step size to reduce the transient phase, as further supported by AdamH experiments.
What carries the argument
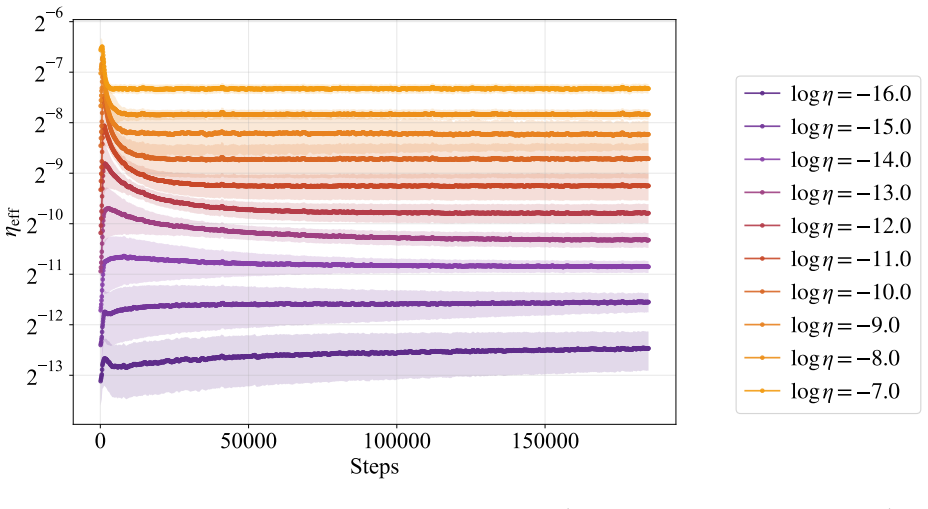
Effective learning rate as the step size in normalized weight space, which removes the curvature in scaling.
If this is right
- Log-linear extrapolation of optimal learning rates from small models will underestimate values at large scales.
- Using effective learning rate allows accurate predictions without curvature.
- Extrapolating on data scale D produces more linear behavior than on model size N.
- Direct control of effective learning rate via optimizers like AdamH stabilizes the scaling process.
Where Pith is reading between the lines
- If weight-norm dynamics dominate, then interventions that accelerate weight-norm convergence could eliminate the need for adjusted step sizes.
- Previous scaling laws for other hyperparameters may also require checks for similar nonlinearities at large scales.
- The results suggest that training very large models may need scale-dependent adjustments beyond simple power laws.
Load-bearing premise
Slower weight-norm convergence at small optimal learning rates is the main reason a larger step size is needed to shorten the transient phase.
What would settle it
Training a model larger than 707M parameters and measuring whether upward curvature remains after switching to effective learning rate and data-based extrapolation.
Figures

read the original abstract
Learning-rate transfer can reduce the cost of training large language models: instead of sweeping learning rates at target scale, practitioners extrapolate from smaller runs. Existing approaches often assume that the optimal learning rate follows a log-linear scaling law in data scale and model size. We carefully examine and evaluate this scaling law. In our empirical study of GPT-2--style models from 22M to 707M parameters trained on 5B to 100B tokens, the optimal learning rate develops upward curvature at larger scales, leading to inaccurate extrapolation. We find that this curvature largely disappears when learning rates are replaced by effective learning rate (the step size in normalized weight space), and when data $D$ extrapolation is used instead of model size $N$ extrapolation. Next, we explain nonlinearity in scaling: weight-norm converges to equilibrium slower when optimal learning is small, requiring a larger step size to reduce the transient phase. Experiments with AdamH, which directly controls the effective learning rate, further support this explanation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical study of optimal learning-rate scaling for GPT-2-style models (22M–707M parameters, 5B–100B tokens). It finds upward curvature in optimal LR versus model size N that produces inaccurate extrapolation from small-scale runs; this curvature largely vanishes when LR is replaced by effective learning rate (step size in normalized weight space) or when extrapolation is performed over data scale D rather than N. The authors attribute the nonlinearity to slower weight-norm equilibration at small optimal LRs and supply supporting evidence from AdamH experiments that directly control effective LR.
Significance. If the central empirical observations hold under more rigorous statistical controls, the work would improve practical hyperparameter transfer for large LLMs by showing that log-linear N-scaling assumptions are insufficient and that effective-LR and D-extrapolation yield more reliable predictions. The controlled sweep across both N and D together with the AdamH validation experiments constitute a concrete methodological contribution that moves beyond purely phenomenological scaling laws.
major comments (2)
- [Abstract] Abstract: the mechanistic explanation that 'weight-norm converges to equilibrium slower when optimal learning is small, requiring a larger step size to reduce the transient phase' is offered without quantitative evidence that the magnitude of the observed curvature is accounted for by the transient duration, nor does it rule out alternative scale-dependent effects such as changes in gradient noise, Hessian conditioning, or Adam momentum statistics.
- [Abstract] Abstract: the description of the controlled sweep supplies no information on statistical significance of the reported curvature, error bars on optimal-LR estimates, data-filtering rules, or whether the AdamH runs isolate the proposed weight-norm mechanism from other scale-dependent factors.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the mechanistic explanation that 'weight-norm converges to equilibrium slower when optimal learning is small, requiring a larger step size to reduce the transient phase' is offered without quantitative evidence that the magnitude of the observed curvature is accounted for by the transient duration, nor does it rule out alternative scale-dependent effects such as changes in gradient noise, Hessian conditioning, or Adam momentum statistics.
Authors: The abstract condenses the proposed mechanism, with the AdamH experiments in the main text providing direct support by demonstrating that the observed nonlinearity in optimal LR largely disappears when effective learning rate is held constant. We agree that the manuscript does not include an explicit quantitative decomposition showing that transient duration fully accounts for the curvature magnitude, nor does it exhaustively rule out alternatives such as scale-dependent changes in gradient noise or Hessian properties. In revision we will expand the discussion section to include additional analysis of these factors using the existing experimental data and to clarify the scope of the AdamH evidence. revision: partial
-
Referee: [Abstract] Abstract: the description of the controlled sweep supplies no information on statistical significance of the reported curvature, error bars on optimal-LR estimates, data-filtering rules, or whether the AdamH runs isolate the proposed weight-norm mechanism from other scale-dependent factors.
Authors: The referee correctly notes that the abstract omits these methodological details. The full manuscript describes the N and D sweeps and AdamH controls, but does not report error bars on the optimal-LR points, formal statistical tests for curvature, explicit data-filtering criteria, or a dedicated isolation argument for the weight-norm mechanism. We will revise both the abstract and the methods/experiments sections to supply error bars where feasible, state the data-selection rules, report any significance assessments, and add text clarifying how the AdamH design isolates effective LR from other factors. revision: yes
Circularity Check
Empirical scaling observations with independent experimental checks; no reduction to fitted inputs or self-citations
full rationale
The paper reports direct measurements of optimal learning rates across model sizes and data scales in GPT-2-style models, documents upward curvature in N-extrapolation, and shows the curvature vanishes under effective learning rate (normalized step size) or D-extrapolation. The mechanistic account of weight-norm transients is presented as an explanation supported by separate AdamH experiments rather than a closed derivation; no equations or claims reduce the reported curvature or its disappearance to quantities defined by the fit itself, and no load-bearing self-citations or ansatzes imported from prior author work are invoked to force the result. The central findings remain independent empirical observations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Optimal learning rate follows a log-linear scaling law in model size and data volume
Reference graph
Works this paper leans on
-
[1]
Tune my adam, please!arXiv preprint arXiv:2508.19733, 2025
Athanasiadis, T., Adriaensen, S., Müller, S., and Hutter, F. Tune my adam, please!arXiv preprint arXiv:2508.19733, 2025
-
[2]
Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Power lines: Scaling laws for weight decay and batch size in llm pre-training
Bergsma, S., Dey, N., Gosal, G., Gray, G., Soboleva, D., and Hestness, J. Power lines: Scaling laws for weight decay and batch size in llm pre-training. InAdvances in Neural Information Processing Systems, 2025
2025
-
[4]
Scaling optimal lr across token horizons
Bjorck, J., Benhaim, A., Chaudhary, V., Wei, F., and Song, X. Scaling optimal lr across token horizons. InInternational Conference on Learning Representations, 2025
2025
-
[5]
Y., Deiseroth, B., Cruz-Salinas, A
Blake, C., Eichenberg, C., Dean, J., Balles, L., Prince, L. Y., Deiseroth, B., Cruz-Salinas, A. F., Luschi, C., Weinbach, S., and Orr, D. u-µ p: The unit-scaled maximal update parametrization. InInternational Conference on Learning Representations, 2025
2025
-
[6]
Depthwise hyperparameter transfer in residual networks: Dynamics and scaling limit
Bordelon, B., Noci, L., Li, M., Hanin, B., and Pehlevan, C. Depthwise hyperparameter transfer in residual networks: Dynamics and scaling limit. InInternational Conference on Learning Representations, 2024
2024
-
[7]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
DeepSeek-AI, Bi, X., Chen, D., Chen, G., Chen, S., Dai, D., Deng, C., Ding, H., Dong, K., Du, Q., Fu, Z., Gao, H., Gao, K., Gao, W., Ge, R., Guan, K., Guo, D., Guo, J., Hao, G., Hao, Z., He, Y., Hu, W., Huang, P., Li, E., Li, G., Li, J., Li, Y., Li, Y. K., Liang, W., Lin, F., Liu, A. X., Liu, B., Liu, W., Liu, X., Liu, X., Liu, Y., Lu, H., Lu, S., Luo, F....
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
C., Noci, L., Li, M., Bordelon, B., Bergsma, S., Pehlevan, C., Hanin, B., and Hestness, J
Dey, N., Zhang, B. C., Noci, L., Li, M., Bordelon, B., Bergsma, S., Pehlevan, C., Hanin, B., and Hestness, J. Don’t be lazy: Completep enables compute-efficient deep transformers.arXiv preprint arXiv:2505.01618, 2025
-
[9]
E., Xiao, L., Wortsman, M., Alemi, A
Everett, K. E., Xiao, L., Wortsman, M., Alemi, A. A., Novak, R., Liu, P. J., Gur, I., Sohl- Dickstein, J., Kaelbling, L. P., Lee, J., et al. Scaling exponents across parameterizations and optimizers. InInternational Conference on Machine Learning, pp. 12666–12700. PMLR, 2024
2024
-
[10]
Robust layerwise scaling rules by proper weight decay tuning.arXiv preprint arXiv:2510.15262, 2025
Fan, Z., Liu, Y., Zhao, Q., Yuan, A., and Gu, Q. Robust layerwise scaling rules by proper weight decay tuning.arXiv preprint arXiv:2510.15262, 2025
-
[11]
Nemotron-flash: Towards latency-optimal hybrid small language models
Fu, Y., Dong, X., Diao, S., Ye, H., Byeon, W., Karnati, Y., Liebenwein, L., Khadkevich, M., Keller, A., Kautz, J., et al. Nemotron-flash: Towards latency-optimal hybrid small language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[12]
Norm matters: efficient and accurate normalization schemes in deep networks.Advances in Neural Information Processing Systems, 31, 2018
Hoffer, E., Banner, R., Golan, I., and Soudry, D. Norm matters: efficient and accurate normalization schemes in deep networks.Advances in Neural Information Processing Systems, 31, 2018. 12
2018
-
[13]
Minicpm: Unveiling the potential of small language models with scalable training strategies
Hu, S., Tu, Y., Han, X., Cui, G., He, C., Zhao, W., Long, X., Zheng, Z., Fang, Y., Huang, Y., et al. Minicpm: Unveiling the potential of small language models with scalable training strategies. InFirst Conference on Language Modeling, 2024
2024
-
[14]
H., and Leyton-Brown, K
Hutter, F., Hoos, H. H., and Leyton-Brown, K. Sequential model-based optimization for general algorithm configuration. InInternational conference on learning and intelligent optimization, pp. 507–523. Springer, 2011
2011
-
[15]
and Szegedy, C
Ioffe, S. and Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. InInternational conference on machine learning, pp. 448–456. pmlr, 2015
2015
-
[16]
Three Factors Influencing Minima in SGD
Jastrzębski, S., Kenton, Z., Arpit, D., Ballas, N., Fischer, A., Bengio, Y., and Storkey, A. Three factors influencing minima in sgd.arXiv preprint arXiv:1711.04623, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[18]
nanoGPT.https://github.com/karpathy/nanoGPT, 2022
Karpathy, A. nanoGPT.https://github.com/karpathy/nanoGPT, 2022. GitHub repository
2022
-
[19]
Rotational equilibrium: How weight decay balances learning across neural networks
Kosson, A., Messmer, B., and Jaggi, M. Rotational equilibrium: How weight decay balances learning across neural networks. InInternational Conference on Machine Learning, pp. 25333– 25369. PMLR, 2024
2024
-
[20]
Kosson, A., Welborn, J., Liu, Y., Jaggi, M., and Chen, X. Weight decay may matter more than mup for learning rate transfer in practice.arXiv preprint arXiv:2510.19093, 2025
-
[21]
Li, B., Wen, J., Zhou, Z., Zhu, J., and Chen, J. Efficient hyperparameter tuning via trajectory invariance principle.arXiv preprint arXiv:2509.25049, 2025
-
[22]
Li, H., Zheng, W., Wang, Q., Zhang, H., Wang, Z., Xuyang, S., Fan, Y., Ding, Z., Wang, H., Ding, N., Zhou, S., Zhang, X., and Jiang, D. Predictable scale: Part i, step law – optimal hyperparameter scaling law in large language model pretraining.arXiv preprint arXiv:2503.04715, 2025
-
[23]
Reconciling modern deep learning with traditional optimization analyses: The intrinsic learning rate.Advances in Neural Information Processing Systems, 33: 14544–14555, 2020
Li, Z., Lyu, K., and Arora, S. Reconciling modern deep learning with traditional optimization analyses: The intrinsic learning rate.Advances in Neural Information Processing Systems, 33: 14544–14555, 2020
2020
-
[24]
Muon is Scalable for LLM Training
Liu, J., Su, J., Yao, X., Jiang, Z., Lai, G., Du, Y., Qin, Y., Xu, W., Lu, E., Yan, J., et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
and Hutter, F
Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[26]
ngpt: Normalized transformer with representation learning on the hypersphere
Loshchilov, I., Hsieh, C.-P., Sun, S., and Ginsburg, B. ngpt: Normalized transformer with representation learning on the hypersphere. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[27]
A multi-power law for loss curve prediction across learning rate schedules
Luo, K., Wen, H., Hu, S., Sun, Z., Liu, Z., Sun, M., Lyu, K., and Chen, W. A multi-power law for loss curve prediction across learning rate schedules. InInternational Conference on Learning Representations, 2025. 13
2025
-
[28]
On the sdes and scaling rules for adaptive gradient algorithms.Advances in Neural Information Processing Systems, 35:7697–7711, 2022
Malladi, S., Lyu, K., Panigrahi, A., and Arora, S. On the sdes and scaling rules for adaptive gradient algorithms.Advances in Neural Information Processing Systems, 35:7697–7711, 2022
2022
-
[29]
G., and Goldblum, M
Marek, M., Lotfi, S., Somasundaram, A., Wilson, A. G., and Goldblum, M. Small batch size training for language models: When vanilla sgd works, and why gradient accumulation is wasteful. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[30]
McCandlish, S., Kaplan, J., Amodei, D., and Team, O. D. An empirical model of large-batch training.arXiv preprint arXiv:1812.06162, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Completed hyperparameter transfer across modules, width, depth, batch and duration
Mlodozeniec, B., Ablin, P., Béthune, L., Busbridge, D., Klein, M., Ramapuram, J., and Cuturi, M. Completed hyperparameter transfer across modules, width, depth, batch and duration. arXiv preprint arXiv:2512.22382, 2025
-
[32]
The fineweb datasets: Decanting the web for the finest text data at scale.Advances in Neural Information Processing Systems, 37:30811–30849, 2024
Penedo, G., Kydlíček, H., Lozhkov, A., Mitchell, M., Raffel, C., Von Werra, L., Wolf, T., et al. The fineweb datasets: Decanting the web for the finest text data at scale.Advances in Neural Information Processing Systems, 37:30811–30849, 2024
2024
-
[33]
Resolving discrepancies in compute-optimal scaling of language models.arXiv:2406.19146, 2024
Porian, T., Wortsman, M., Jitsev, J., Schmidt, L., and Carmon, Y. Resolving discrepancies in compute-optimal scaling of language models.arXiv:2406.19146, 2024
-
[34]
Language models are un- supervised multitask learners
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. Language models are un- supervised multitask learners. Technical report, OpenAI, 2019. URLhttps://cdn.openai.com/ better-language-models/language_models_are_unsupervised_multitask_learners.pdf
2019
-
[35]
Snoek, J., Larochelle, H., and Adams, R. P. Practical bayesian optimization of machine learning algorithms.Advances in neural information processing systems, 25, 2012
2012
-
[36]
Scaling law with learning rate annealing.arXiv preprint arXiv:2408.11029, 2024
Tissue, H., Wang, V., and Wang, L. Scaling law with learning rate annealing.arXiv preprint arXiv:2408.11029, 2024
-
[37]
L2 Regularization versus Batch and Weight Normalization
Van Laarhoven, T. L2 regularization versus batch and weight normalization.arXiv preprint arXiv:1706.05350, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
N., Kaiser, L
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. u., and Polosukhin, I. Attention is all you need. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R. (eds.),Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URLhttps://procee...
2017
-
[39]
The sharpness disparity principle in transformers for accelerating language model pre-training
Wang, J., Wang, M., Zhou, Z., Yan, J., Wu, L., et al. The sharpness disparity principle in transformers for accelerating language model pre-training. InInternational Conference on Machine Learning, pp. 64859–64879. PMLR, 2025
2025
-
[40]
Wang, S., Chen, Z., Li, B., He, K., Zhang, M., and Wang, J. Scaling laws across model architectures: A comparative analysis of dense and MoE models in large language mod- els. In Al-Onaizan, Y., Bansal, M., and Chen, Y.-N. (eds.),Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 5583–5595. Associ- ation for Comput...
-
[41]
and Aitchison, L
Wang, X. and Aitchison, L. How to set adamw’s weight decay as you scale model and dataset size. InInternational Conference on Machine Learning, 2025. 14
2025
-
[42]
Fantastic pretraining optimizers and where to find them 2.1: Hyperball optimization, 12 2025
Wen, K., Dang, X., Lyu, K., Ma, T., and Liang, P. Fantastic pretraining optimizers and where to find them 2.1: Hyperball optimization, 12 2025. URLhttps://tinyurl.com/muonh
2025
-
[43]
K., Ren, Q., Wang, Y., Zhao, W
Xie, T., Luo, H., Tang, H., Hu, Y., Liu, J. K., Ren, Q., Wang, Y., Zhao, W. X., Yan, R., Su, B., et al. Controlled llm training on spectral sphere.arXiv preprint arXiv:2601.08393, 2026
-
[44]
and Hu, E
Yang, G. and Hu, E. J. Tensor programs IV: feature learning in infinite-width neural networks. In Meila, M. and Zhang, T. (eds.),Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, Proceedings of Machine Learning Re- search, pp. 11727–11737. PMLR, 2021. URLhttp://proceedings.mlr.press/v139/yang21c. html
2021
-
[45]
Tuning large neural networks via zero-shot hyperparameter transfer.Advances in Neural Information Processing Systems, 34:17084–17097, 2021
Yang, G., Hu, E., Babuschkin, I., Sidor, S., Liu, X., Farhi, D., Ryder, N., Pachocki, J., Chen, W., and Gao, J. Tuning large neural networks via zero-shot hyperparameter transfer.Advances in Neural Information Processing Systems, 34:17084–17097, 2021
2021
-
[46]
Zhang, H., Morwani, D., Vyas, N., Wu, J., Zou, D., Ghai, U., Foster, D., and Kakade, S. M. How does critical batch size scale in pre-training? InInternational Conference on Learning Representations, 2025
2025
-
[47]
Configuration-to-performance scaling law with neural ansatz
Zhang, H., Wen, K., and Ma, T. Configuration-to-performance scaling law with neural ansatz. arXiv preprint arXiv:2602.10300, 2026
-
[48]
How to set the learning rate for large-scale pre-training?arXiv preprint arXiv:2601.05049, 2026
Zhou, Y., Xing, S., Huang, J., Qiu, X., and Guo, Q. How to set the learning rate for large-scale pre-training?arXiv preprint arXiv:2601.05049, 2026. 15 Appendix A Additional Related Works on Hyperparameter Tuning and Trans- fer Beyond learning rate, recent work has also investigated tuning and transfer strategies for other hyperparameters. From a theoreti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.