Agentic-Ideation: Sample Efficient Agentic Trajectories Synthesis for Scientific Ideation Agents
Pith reviewed 2026-07-01 05:47 UTC · model grok-4.3
The pith
Oracle-guided synthesis lets agentic LLMs for scientific ideation beat workflow baselines by 11.91 percent while using over 10 times fewer samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
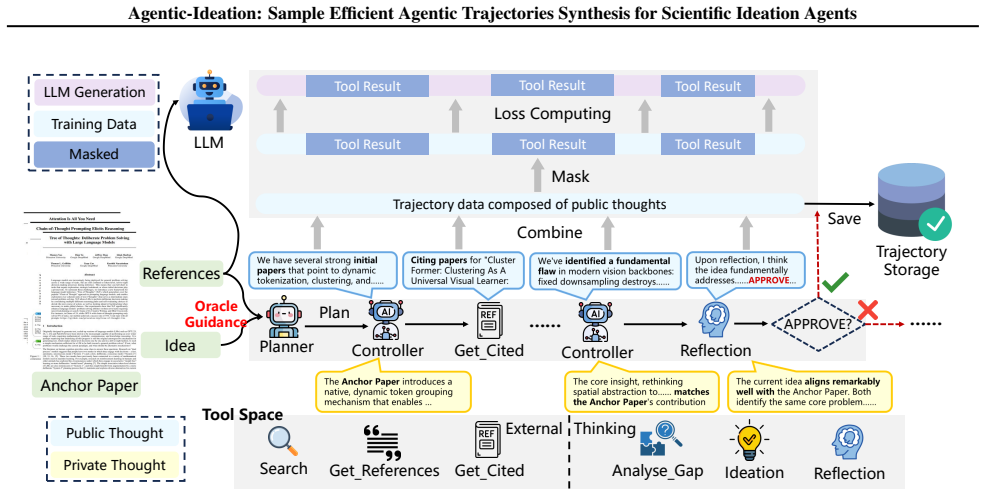
By defining a tool space of three external and three cognitive tools and then applying oracle-guided data synthesis, the method reconstructs logical reasoning trajectories from a reference idea; training an agentic LLM on these trajectories with masked tool feedback produces a model that outperforms the strongest workflow-based baseline by 11.91 percent in overall quality and achieves more than 10 times better sample efficiency for high-quality data.
What carries the argument
Oracle-Guided Data Synthesis, which uses a reference idea to direct a multi-agent system in reconstructing decision and tool-use sequences instead of undirected search.
If this is right
- The trained agent can reason flexibly across literature and actions without being locked into a fixed workflow.
- Masking tool execution results during training forces the model to internalize decision-making rather than rely on external signals.
- The same synthesis pipeline can be applied to other domains that need autonomous tool use and long reasoning chains.
- Data synthesis cost drops enough that larger sets of high-quality trajectories become feasible to collect.
Where Pith is reading between the lines
- The method may extend to domains outside science where reference solutions exist for training but not for deployment.
- Removing the oracle entirely during synthesis and testing would reveal how much the performance gain depends on guided data creation.
- Combining the trained agent with live experimental tools could close the loop from idea generation to validation.
Load-bearing premise
Trajectories built while an oracle reference idea is available will still produce useful decision logic once that reference is removed at inference time.
What would settle it
Run the trained agent on new ideation tasks that supply no reference idea at all and measure whether overall quality falls below the reported 11.91 percent gain over the workflow baseline.
Figures



read the original abstract
Ideation plays a pivotal role in scientific discovery. Recent LLM, especially AI Scientist systems, show promising potential for automated ideation. However, existing approaches predominantly rely on pre-defined agentic workflows. This constraint severely limits the flexibility required to navigate the vast search space of scientific literature and the complex action space of research reasoning. Recently, training Agentic LLMs has emerged as a promising direction, offering flexible reasoning frameworks and the capability for autonomous tool utilization. However, there remains a non-trivial challenge: applying previous agentic data synthesis methods to scientific ideation suffers from prohibitively high data synthesis cost. To bridge this gap, we propose Agentic-Ideation, a novel framework comprising an automated trajectory synthesis pipeline and a specialized agentic LLM trained for scientific ideation. Specifically, we first define a comprehensive tool space incorporating three external tools and three cognitive tools. Then we introduce an Oracle-Guided Data Synthesis strategy. By leveraging a reference idea as oracle guidance, this approach steers the multi-agent system to efficiently reconstruct the logical reasoning and tool invocation paths, transforming aimless trial-and-error into directed trajectory generation. Finally, we train the agent on these synthesized trajectories, employing a masking strategy on tool execution results. This ensures the model focuses on decision-making logic without interference from external feedback. Experimental results demonstrate that our method outperforms the SOTA workflow-based baseline by \textbf{11.91\%} in overall quality. Furthermore, our approach improves the sample efficiency of high-quality data synthesis by \textbf{over 10$\times$}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Agentic-Ideation, a framework for scientific ideation agents consisting of a tool space (three external + three cognitive tools), an Oracle-Guided Data Synthesis pipeline that uses a reference idea to steer multi-agent trajectory reconstruction, and training of an agentic LLM with masking applied only to tool execution results. It claims this yields trajectories that enable an agent outperforming a SOTA workflow-based baseline by 11.91% in overall quality while improving sample efficiency of high-quality data synthesis by over 10×.
Significance. If the empirical results and generalization hold, the work would address a practical bottleneck in scaling agentic LLMs for open-ended scientific reasoning by converting high-cost trial-and-error synthesis into directed generation, potentially enabling more flexible, autonomous ideation systems beyond fixed workflows.
major comments (2)
- [Abstract] Abstract / Experimental results: the 11.91% quality improvement and 10× sample-efficiency claims are stated without any description of the concrete metric(s) used for 'overall quality', the precise implementation and hyper-parameters of the SOTA workflow baseline, the number of evaluated trajectories or ideas, statistical significance tests, or controls for prompt sensitivity and oracle leakage.
- [Method] Oracle-Guided Data Synthesis strategy (described in the method): the pipeline explicitly conditions trajectory reconstruction on a reference idea (oracle) to convert trial-and-error into directed generation, yet the subsequent training (masking only on tool results) contains no ablation, hold-out evaluation, or analysis showing that the learned decision logic remains effective when the oracle is absent at inference time—the setting required for real scientific ideation tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for improving clarity and rigor in our presentation of results and methods. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract / Experimental results: the 11.91% quality improvement and 10× sample-efficiency claims are stated without any description of the concrete metric(s) used for 'overall quality', the precise implementation and hyper-parameters of the SOTA workflow baseline, the number of evaluated trajectories or ideas, statistical significance tests, or controls for prompt sensitivity and oracle leakage.
Authors: We agree that the abstract would benefit from explicit details on these elements to allow readers to better assess the claims. In the revision, we will expand the abstract to define the overall quality metric (a composite human evaluation score across novelty, feasibility, and scientific impact), specify the SOTA baseline implementation and hyperparameters, report the evaluation scale (number of trajectories and ideas), include results of statistical significance tests, and describe the controls applied for prompt sensitivity and oracle leakage. Corresponding clarifications will also be added to the experimental section. revision: yes
-
Referee: [Method] Oracle-Guided Data Synthesis strategy (described in the method): the pipeline explicitly conditions trajectory reconstruction on a reference idea (oracle) to convert trial-and-error into directed generation, yet the subsequent training (masking only on tool results) contains no ablation, hold-out evaluation, or analysis showing that the learned decision logic remains effective when the oracle is absent at inference time—the setting required for real scientific ideation tasks.
Authors: The masking of tool execution results during training is specifically intended to encourage the model to internalize decision-making logic independent of external signals, supporting generalization to oracle-free inference. That said, we acknowledge the value of explicit validation for this claim. We will add an ablation study in the revised manuscript that evaluates the trained agent on held-out ideation tasks both with and without oracle guidance at inference time, along with analysis of decision quality in the oracle-absent setting. revision: yes
Circularity Check
No circularity; empirical method with no derivation chain
full rationale
The paper describes an empirical pipeline (tool space definition, Oracle-Guided Data Synthesis using reference ideas, masking during training) and reports performance gains (11.91% quality, 10× efficiency) against a SOTA baseline. No equations, derivations, or first-principles results appear. None of the six enumerated circularity patterns apply: no self-definitional relations, no fitted inputs relabeled as predictions, no load-bearing self-citations, and no uniqueness theorems or ansatzes. The oracle-to-inference generalization is an empirical assumption, not a circular reduction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agents can be steered by an oracle reference idea to produce useful reasoning trajectories
- domain assumption Masking tool execution results during training isolates decision-making logic from external feedback
invented entities (1)
-
Oracle-Guided Data Synthesis strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fireact: Toward language agent fine-tuning.arXiv preprint arXiv:2310.05915,
URL https://api.semanticscholar. org/CorpusID:211054583. Chen, B., Shu, C., Shareghi, E., Collier, N., Narasimhan, K., and Yao, S. Fireact: Toward language agent fine-tuning.ArXiv, abs/2310.05915, 2023. URL https: //api.semanticscholar.org/CorpusID: 263829338. Chen, M., Li, T., Sun, H., Zhou, Y ., Zhu, C., Wang, H., Pan, J. Z., Zhang, W., zeng Chen, H., Y...
-
[2]
URL https://api.semanticscholar. org/CorpusID:277313597. Fang, R., Cai, S., Li, B., Wu, J., Li, G., Yin, W., Wang, X., Wang, X., Su, L., Zhang, Z., Wu, S., Tao, Z., Jiang, Y ., Xie, P., Huang, F., and Zhou, J. Towards general agentic intelligence via environment scaling.ArXiv, abs/2509.13311,
-
[3]
WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent
URL https://api.semanticscholar. org/CorpusID:281325844. Geng, X., Xia, P., Zhang, Z., Wang, X., Wang, Q., Ding, R., Wang, C., Wu, J., Zhao, Y ., Li, K., Jiang, Y ., Xie, P., Huang, F., and Zhou, J. Webwatcher: Breaking new frontier of vision- language deep research agent.ArXiv, abs/2508.05748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URL https://api.semanticscholar. org/CorpusID:280561766. Gottweis, J., Weng, W.-H., Daryin, A., Tu, T., Palepu, A., Sirkovic, P., Myaskovsky, A., Weissenberger, F., Rong, K., Tanno, R., et al. Towards an ai co-scientist.arXiv preprint arXiv:2502.18864, 2025. Hu, S., Lu, C., and Clune, J. Automated de- sign of agentic systems.ArXiv, abs/2408.08435,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
URL https://api.semanticscholar. org/CorpusID:271892234. Jin, B., Zeng, H., Yue, Z., Wang, D., Zamani, H., and Han, J. Search-r1: Training llms to reason and leverage search engines with reinforcement learn- ing.ArXiv, abs/2503.09516, 2025. URL https: //api.semanticscholar.org/CorpusID: 276937772. Li, K., Zhang, Z., Yin, H., Ye, R., Zhao, Y ., Zhang, L., ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
URL https://api.semanticscholar. org/CorpusID:278658695. 9 Agentic-Ideation: Sample Efficient Agentic Trajectories Synthesis for Scientific Ideation Agents Pu, Y ., Lin, T., and Chen, H. Piflow: Principle-aware sci- entific discovery with multi-agent collaboration.arXiv preprint arXiv:2505.15047, 2025. Romera-Paredes, B., Barekatain, M., Novikov, A., Balo...
-
[7]
URL https://api.semanticscholar. org/CorpusID:266223700. Schmidgall, S. and Moor, M. Agentrxiv: Towards collaborative autonomous research.arXiv preprint arXiv:2503.18102, 2025. Schmidgall, S., Su, Y ., Wang, Z., Sun, X., Wu, J., Yu, X., Liu, J., Liu, Z., and Barsoum, E. Agent laboratory: Using llm agents as research assistants.arXiv preprint arXiv:2501.04...
-
[8]
org/CorpusID:273228108
URL https://api.semanticscholar. org/CorpusID:273228108. Su, H., Chen, R., Tang, S., Yin, Z., Zheng, X., Li, J., Qi, B., Wu, Q., Li, H., Ouyang, W., Torr, P., Zhou, B., and Dong, N. Many heads are bet- ter than one: Improved scientific idea generation by a llm-based multi-agent system. InAnnual Meet- ing of the Association for Computational Linguistics,
-
[9]
Ai-researcher: Autonomous scientific innovation.arXiv preprint arXiv:2505.18705, 2025
URL https://api.semanticscholar. org/CorpusID:273346445. Tang, J., Xia, L., Li, Z., and Huang, C. Ai-researcher: Autonomous scientific innovation.arXiv preprint arXiv:2505.18705, 2025. Tao, Z., Wu, J., Yin, W., Zhang, J., Li, B., Shen, H., Li, K., Zhang, L., Wang, X., Jiang, Y ., Xie, P., Huang, F., and Zhou, J. Web- shaper: Agentically data synthesizing ...
-
[10]
URL https://api.semanticscholar. org/CorpusID:280271252. Wang, Q., Downey, D., Ji, H., and Hope, T. Sci- mon: Scientific inspiration machines optimized for novelty. InAnnual Meeting of the Association for Computational Linguistics, 2023. URL https: //api.semanticscholar.org/CorpusID: 258841365. Wang, W., Gu, L., Zhang, L., Luo, Y ., Dai, Y ., Shen, C., Xi...
-
[11]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
URL https://api.semanticscholar. org/CorpusID:278959248. Yamada, Y ., Lange, R. T., Lu, C., Hu, S., Lu, C., Foerster, J., Clune, J., and Ha, D. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search. arXiv preprint arXiv:2504.08066, 2025. Yan, X., Feng, S., Yuan, J., Xia, R., Wang, B., Bai, L., and Zhang, B. Surveyforge...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
URL https://api.semanticscholar. org/CorpusID:278602855. Yu, H., Hong, Z., Cheng, Z., Zhu, K., Xuan, K., Yao, J., Feng, T., and You, J. Researchtown: Simulator of human research community.arXiv preprint arXiv:2412.17767, 2024. Zhang, L., Wang, M., and Chen, B. Scientific judgment drifts over time in ai ideation.ArXiv, abs/2511.04964, 2025a. URL https://ap...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.