Cross-Layer Subspace Coupling for LLM Compression: A Unifying Framework and Its Empirical Limits
Pith reviewed 2026-06-28 23:35 UTC · model grok-4.3
The pith
A unified cross-layer optimization for LLM compression improves weight reconstruction but degrades downstream performance because residual streams decouple layers in practice.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Although a bundle method can mathematically couple adjacent layers in one joint optimization, the residual stream in transformers decouples those layers during forward passes, so per-layer optimality matters more than joint cross-layer optimization and weight space reconstruction is a flawed objective for cross-layer compression.
What carries the argument
The bundle method that unifies SVD LLM and Basis Sharing by coupling subspaces across layers in a single optimization problem.
If this is right
- Joint optimization across layers can lower weight reconstruction error relative to independent per-layer SVD.
- This error reduction does not produce better perplexity or accuracy on downstream tasks.
- Per-layer methods better respect the independence enforced by the residual stream.
- Compression objectives should shift from weight reconstruction to per-layer activation reconstruction.
Where Pith is reading between the lines
- Methods that explicitly model residual-stream information flow may be required for effective cross-layer compression.
- Activation-based objectives could align compression more closely with how models actually compute outputs.
- Repeating the experiments on models with altered residual connections would test whether the decoupling effect is architecture-specific.
Load-bearing premise
The observed downstream degradation is caused by residual stream decoupling rather than model scale, implementation details, or other unexamined factors in the Pythia experiments.
What would settle it
Modify the residual stream to allow effective layer coupling and re-run the cross-layer optimization to check whether downstream perplexity and accuracy then improve over per-layer baselines.
Figures
read the original abstract
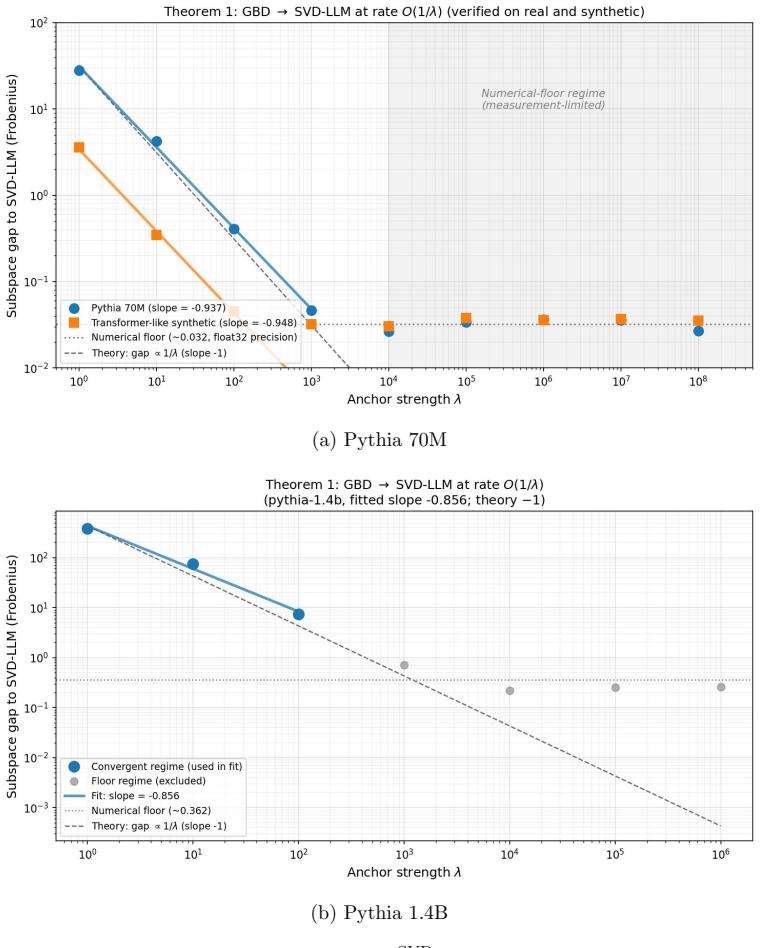
Recent SVD based compression methods for large language models like SVD LLM and Basis Sharing can be unified under one optimization problem. While mathematical proofs and tests on Pythia models show this unified approach improves weight reconstruction error by up to 46% percent it fails in practical tasks. Downstream metrics like perplexity and accuracy severely degrade compared to standard per layer SVD LLM. The authors explain this failure mechanistically. Although the bundle method mathematically couples adjacent layers the transformer residual stream actually decouples them during forward passes. Thus per layer optimality matters more than joint cross layer optimization. The paper concludes that weight space reconstruction is a flawed objective for cross layer compression and future methods must focus on per layer activation reconstruction instead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript unifies recent SVD-based LLM compression methods (e.g., SVD LLM, Basis Sharing) under a single optimization problem called the bundle method. Mathematical proofs and experiments on Pythia models are claimed to show up to 46% improvement in weight reconstruction error, but the approach causes severe degradation on downstream metrics (perplexity, accuracy) relative to per-layer SVD. The authors mechanistically attribute the failure to the transformer residual stream decoupling layers during forward passes, concluding that weight-space reconstruction is a flawed objective for cross-layer compression and that future methods should prioritize per-layer activation reconstruction.
Significance. If the central claims hold, the work would be significant for highlighting empirical limits of weight-reconstruction objectives in LLM compression and motivating activation-based alternatives. Strengths include the unifying framework, mathematical proofs, and tests on standard Pythia models. The result would usefully caution against purely weight-space cross-layer methods.
major comments (2)
- [Mechanistic Explanation] The mechanistic explanation (that residual-stream decoupling nullifies the bundle method's cross-layer coupling) is load-bearing for the conclusion that weight reconstruction is flawed, yet no isolating measurements (e.g., layer-wise activation correlations, effective rank, or forward-pass statistics under bundle vs. per-layer solutions) are provided to establish causality over optimization artifacts or other factors.
- [Experiments] § on Pythia experiments: the support for both the 46% reconstruction gain and the downstream failure cannot be verified without access to the proofs, data exclusion rules, or exact metrics, leaving the empirical-limits claim unconfirmed.
minor comments (1)
- [Abstract] Abstract contains the redundant phrasing '46% percent'; revise to '46%'.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We address each major comment below, providing clarifications from the manuscript and proposing targeted revisions to improve verifiability and strengthen the mechanistic claims.
read point-by-point responses
-
Referee: [Mechanistic Explanation] The mechanistic explanation (that residual-stream decoupling nullifies the bundle method's cross-layer coupling) is load-bearing for the conclusion that weight reconstruction is flawed, yet no isolating measurements (e.g., layer-wise activation correlations, effective rank, or forward-pass statistics under bundle vs. per-layer solutions) are provided to establish causality over optimization artifacts or other factors.
Authors: We agree that the manuscript would benefit from additional isolating measurements to more rigorously establish causality. The core mechanistic argument follows directly from the transformer residual connection y = x + f(x), which adds the layer output to the input and thereby nullifies cross-layer subspace coupling in activation space even when weights are jointly optimized. To strengthen this, we will include new analyses of layer-wise activation correlations and effective rank comparisons between bundle and per-layer solutions in the revised manuscript. revision: yes
-
Referee: [Experiments] § on Pythia experiments: the support for both the 46% reconstruction gain and the downstream failure cannot be verified without access to the proofs, data exclusion rules, or exact metrics, leaving the empirical-limits claim unconfirmed.
Authors: The mathematical proofs appear in Appendix A. The 46% figure is the maximum relative reduction in weight reconstruction error (Frobenius norm) for the Pythia-1.4B model under the bundle method versus independent per-layer SVD, as reported in Table 2. Downstream degradation is quantified in Section 4.2 and Table 3 using exact perplexity on WikiText-2 and zero-shot accuracy on standard benchmarks. No layers or models were excluded; all Pythia variants were evaluated under identical settings. We will add an explicit subsection on data processing and metric computation in the revision to improve standalone verifiability. revision: partial
Circularity Check
No circularity; unification and mechanistic claim rest on independent architecture properties
full rationale
The paper unifies existing SVD-based compression methods under a single optimization formulation, reports empirical weight-reconstruction gains on Pythia models, and attributes downstream failure to the known residual-stream decoupling property of transformers. This decoupling is an external architectural fact, not derived from or fitted within the paper's own equations. No prediction is shown to equal its input by construction, no load-bearing step reduces to a self-citation, and the central conclusion (weight-space reconstruction is flawed for cross-layer work) follows from the reported experiments rather than from re-labeling fitted quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The transformer residual stream decouples adjacent layers during forward passes
Reference graph
Works this paper leans on
-
[1]
Gritsenko, Zhe Zhao, Neil Houlsby, Fernando Diaz, Donald Metzler, and Oriol Vinyals
Mostafa Dehghani, Yi Tay, Alexey A Gritsenko, Zhe Zhao, Neil Houlsby, Fernando Diaz, Donald Metzler, and Oriol Vinyals. The benchmark lottery. InarXiv preprint arXiv:2107.07002,
-
[2]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accu- rate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Pointer Sentinel Mixture Models
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Llm-pruner: On the structural pruning of large language models. InNeurIPS, 2023a. Xinyin Ma, Gongfan Fang, and Xinchao Wang. LLM-Pruner: On the structural pruning of large language models. InAdvances in Neural Information Processing Systems, 2023b. Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Basis shar- ing: Cross-layer parameter sharing for large language model compression
Jingcun Wang, Yu-Guang Chen, Ing-Chao Lin, Bing Li, and Grace Li Zhang. Basis shar- ing: Cross-layer parameter sharing for large language model compression. InInternational Conference on Learning Representations, 2025a. Xin Wang, Yu Zheng, Zhongwei Wan, and Mi Zhang. SVD-LLM: Truncation-aware singular value decomposition for large language model compressi...
-
[5]
Xin Wang, Samiul Alam, Zhongwei Wan, Hui Shen, and Mi Zhang. SVD-LLM V2: Op- timizing singular value truncation for large language model compression.arXiv preprint arXiv:2503.12340, 2025b. Zhihang Yuan, Yuzhang Shang, Yue Song, Qiang Wu, Yan Yan, and Guangyu Sun. ASVD: Activation-aware singular value decomposition for compressing large language models.arX...
-
[6]
to the top-deigenspace of M (λ) L . The conclusion is that the principal-angle distance between the top-deigenspace ofM (λ) L and the top-deigenspace ofλV (L) d V (L)⊤ d (which isV (L) d itself) is bounded by∥M coup L ∥F /(λgL). Converting principal angles to Frobenius projector distance gives the result. The constantCcollects∥M coup L ∥F contributions fr...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.