MARD: Mirror-Augmented Reasoning Distillation for Mechanism-Level Drug-Drug Interaction Prediction
Pith reviewed 2026-06-27 09:43 UTC · model grok-4.3
The pith
A 7B model trained with reasoning distillation predicts drug interaction mechanisms on unseen pairs more accurately than GPT-4o.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
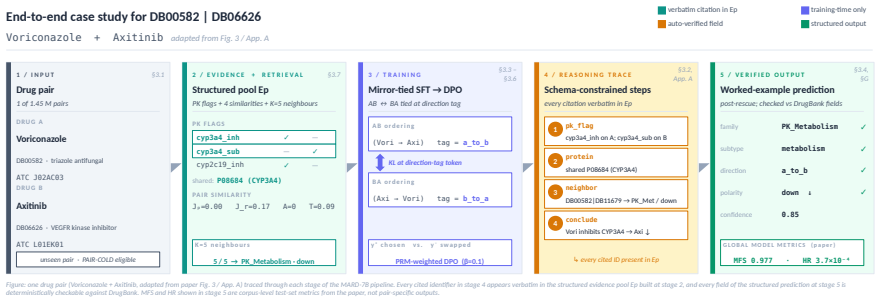
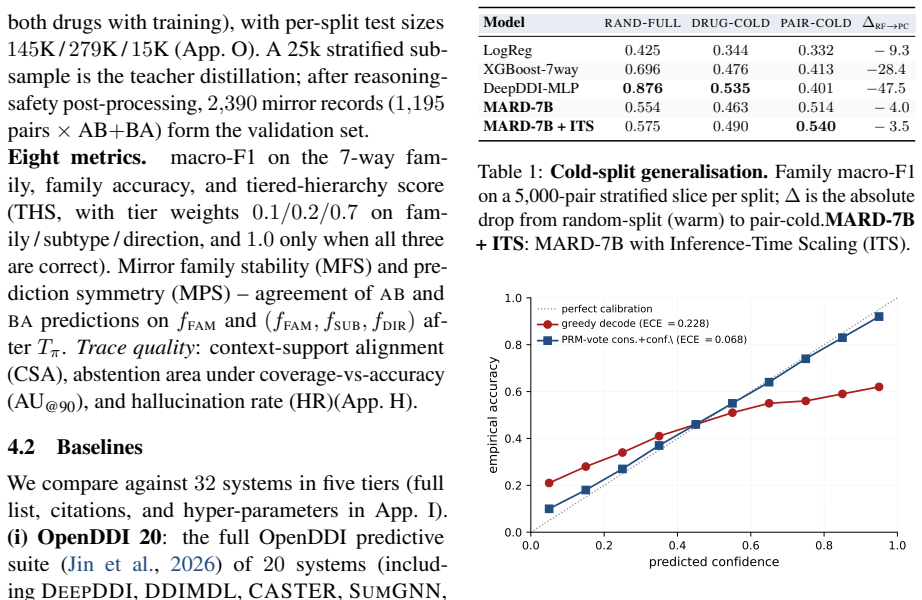
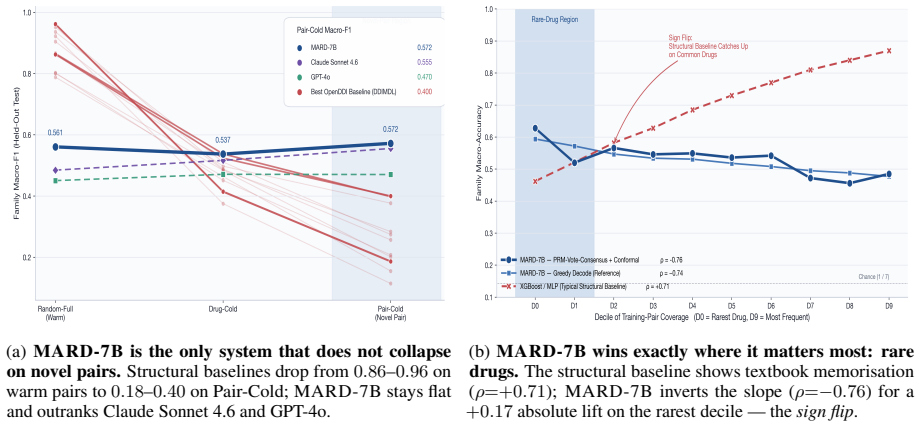
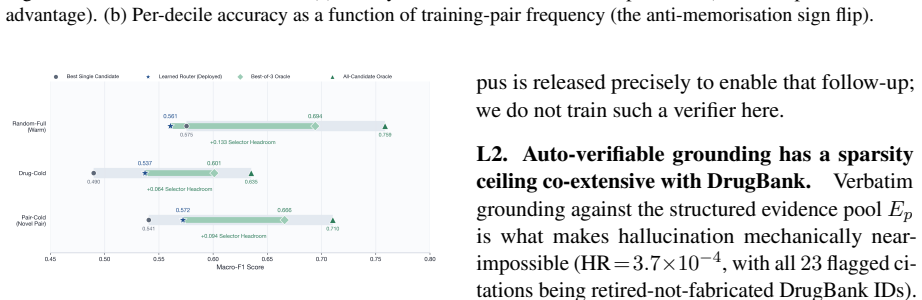
MARD-7B is the only system in a 32-system comparison whose accuracy survives drug-pair novelty, beating the best baseline by +13.9 pp and GPT-4o by +6.7 pp at ~1% of frontier API cost, achieved by combining single-token KL divergence on direction tags, per-loss PRM-weighted DPO with programmatic hard negatives, and leakage-safe mechanism-aware retrieval, with process-reward labels automatically verifiable against DrugBank fields.
What carries the argument
Mirror-Augmented Reasoning Distillation pipeline that ties model predictions to direction tags via KL divergence, weights DPO steps by verifiable process rewards, and adds a leakage-safe retrieval channel over the taxonomy.
If this is right
- Accuracy improves on rarely seen drugs, indicating the gains come from structured pharmacological reasoning rather than drug-frequency memorization.
- Process-reward step labels can be produced automatically from DrugBank-structured fields without human or LLM judges.
- The method supports auditable reasoning metrics that go beyond flat binary interaction classification.
- Performance holds under leakage-safe cold-split protocols designed to test novelty in drug pairs.
Where Pith is reading between the lines
- Specialized distillation on domain taxonomies may let smaller models handle precise biomedical reasoning tasks more reliably than general frontier models.
- The anti-memorization pattern could be tested on other structured prediction problems where new entities appear after training.
- If the retrieval channel proves essential, similar leakage-safe indexes might improve generalization in additional scientific domains with evolving entity sets.
Load-bearing premise
The leakage-safe cold-split protocols and the 7-family/147-subtype taxonomy together ensure that performance gains reflect genuine generalization to unseen drug pairs rather than residual data leakage or taxonomy-specific artifacts.
What would settle it
Running the same 32-system comparison on a random split that permits drug-pair overlap with training data, or on a later DrugBank release, and finding that MARD-7B no longer leads or that its accuracy on rarely seen drugs stops improving.
Figures
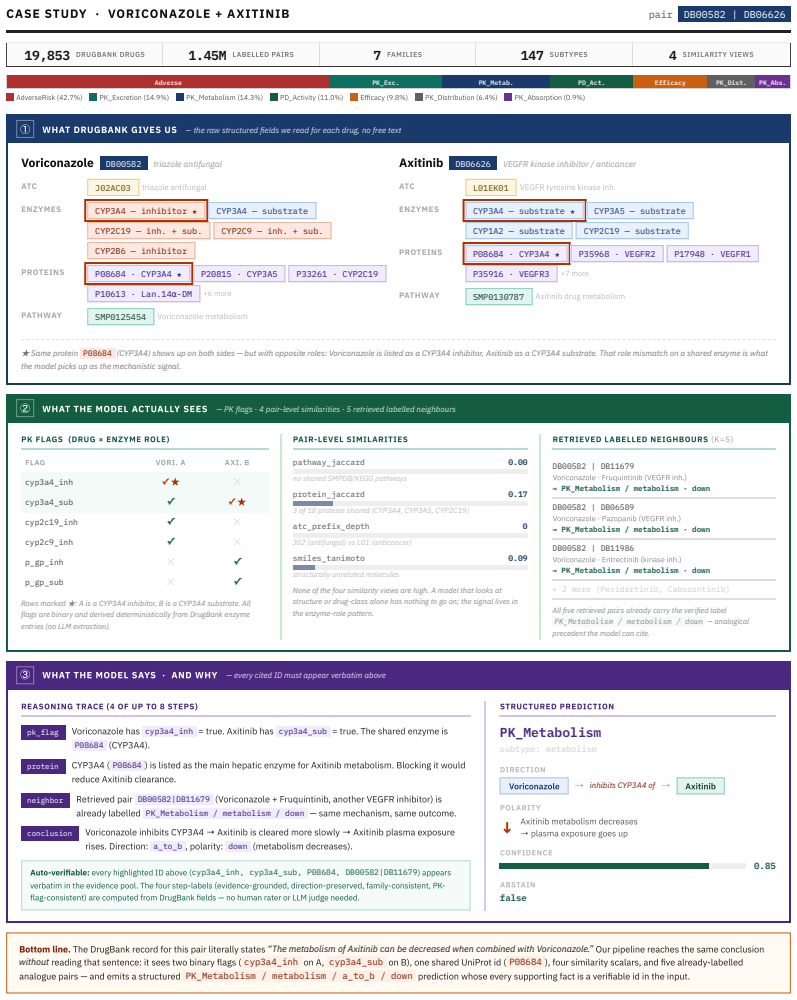
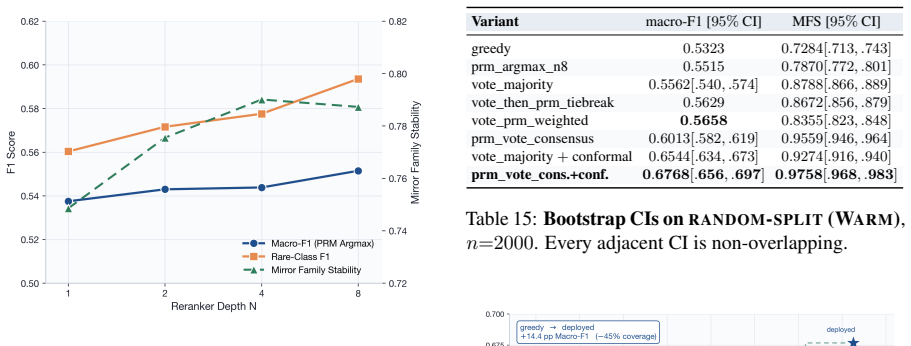
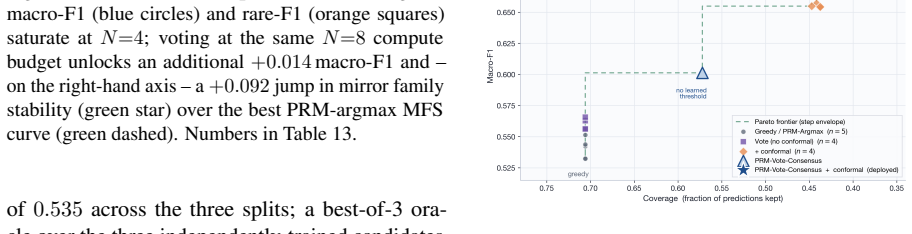

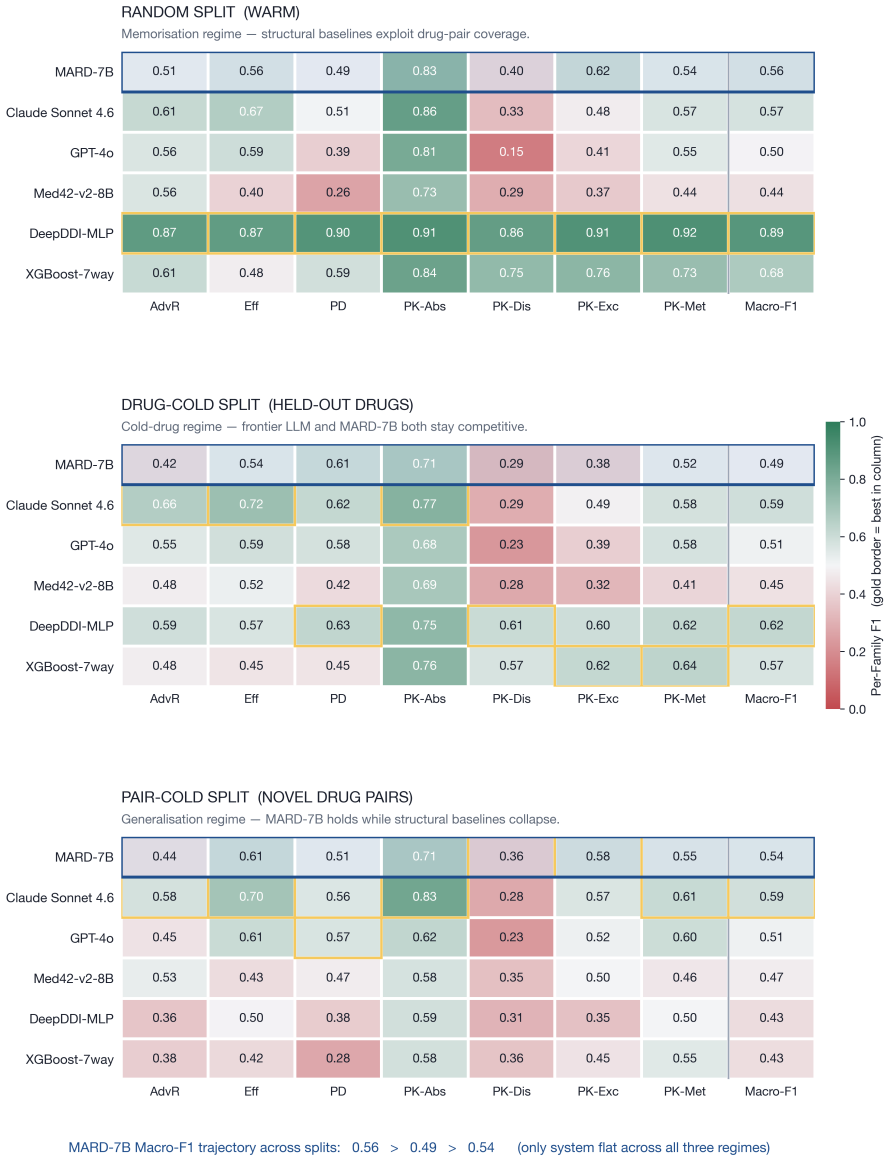
read the original abstract
Mechanism-level drug-drug interaction (DDI) prediction requires identifying which enzyme or pharmacodynamic axis is implicated, in which direction, and with which evidence -- not merely whether two drugs interact. We introduce a reproducible mechanism-level DDI labelling and evaluation protocol with a structured 7-family/147-subtype taxonomy, leakage-safe cold-split protocols, and auditable reasoning metrics for evaluating pharmacological prediction beyond flat interaction classification. We propose a pipeline that produces a 7B reasoning MARD (Mirror-Augmented Reasoning Distillation), combining three training innovations: a single-token KL divergence on direction tag that ties the model's prediction, per-loss PRM-weighted DPO with programmatic hard negatives, and a leakage-safe mechanism-aware retrieval channel. Process-reward step labels are automatically verifiable against DrugBank-structured fields, requiring no human or LLM judges. On the April-2026 DrugBank release, our MARD-7B is the only system in a 32-system comparison whose accuracy survives drug-pair novelty, beating the best baseline by +13.9 pp and GPT-4o by +6.7 pp at ~1% of frontier API cost. Further analysis reveals an anti-memorisation signature where accuracy improves on rarely seen drugs, suggesting that gain comes from structured pharmacological reasoning rather than drug-frequency memorisation. We release corpus, DDI-PRM, retrieval index, and training code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a reproducible mechanism-level DDI prediction protocol using a 7-family/147-subtype taxonomy, leakage-safe cold splits, and auditable reasoning metrics. It proposes MARD-7B, a 7B model trained via mirror-augmented reasoning distillation (single-token KL on direction tags, PRM-weighted DPO with programmatic hard negatives, and leakage-safe mechanism-aware retrieval). On the April-2026 DrugBank release, MARD-7B is claimed to be the sole system among 32 whose accuracy survives drug-pair novelty, outperforming the best baseline by +13.9 pp and GPT-4o by +6.7 pp at ~1% API cost, with an anti-memorization signature where accuracy rises on rarely seen drugs. Code, corpus, DDI-PRM, and retrieval index are released.
Significance. If the cold-split protocols and taxonomy truly eliminate leakage on drugs, pairs, and subtypes while the gains reflect structured pharmacological reasoning, the work would advance DDI prediction beyond flat classification toward mechanism-level, generalizable, and low-cost models. The automatic verifiability of process rewards against DrugBank fields and the release of training artifacts are strengths supporting reproducibility.
major comments (1)
- [Abstract and evaluation protocol section] Abstract and evaluation protocol section: the central claim that MARD-7B is the only system whose accuracy survives drug-pair novelty (with +13.9 pp gain) rests on the unverified assertion that the 7-family/147-subtype taxonomy plus cold-split protocols ensure zero shared drugs, zero shared pairs, zero shared mechanism subtypes, and a retrieval index built strictly on train-only data. No explicit audit, split statistics, or code snippet confirming these properties is provided, leaving open the possibility that performance exploits taxonomy-level patterns or retrieval leakage rather than genuine generalization.
Simulated Author's Rebuttal
Thank you for your constructive review. We agree that explicit verification of the leakage-safe properties is necessary to support the central claims and will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and evaluation protocol section] Abstract and evaluation protocol section: the central claim that MARD-7B is the only system whose accuracy survives drug-pair novelty (with +13.9 pp gain) rests on the unverified assertion that the 7-family/147-subtype taxonomy plus cold-split protocols ensure zero shared drugs, zero shared pairs, zero shared mechanism subtypes, and a retrieval index built strictly on train-only data. No explicit audit, split statistics, or code snippet confirming these properties is provided, leaving open the possibility that performance exploits taxonomy-level patterns or retrieval leakage rather than genuine generalization.
Authors: We agree this is a valid concern and that the current manuscript lacks the requested quantitative audit. In the revised version we will add a new subsection under Evaluation Protocol that reports: (i) exact counts of unique drugs, pairs, and mechanism subtypes in each split with explicit zero-overlap confirmation; (ii) a self-contained code snippet implementing the cold-split logic; and (iii) a statement plus index-construction log verifying that the retrieval index contains only training-set mechanisms. These additions will directly rule out taxonomy-level or retrieval leakage as alternative explanations for the reported gains. revision: yes
Circularity Check
No circularity: claims rest on external DrugBank labels and claimed leakage-safe splits without reduction to fitted inputs by construction
full rationale
The abstract describes a structured taxonomy, leakage-safe cold-split protocols, and programmatic hard negatives derived from DrugBank fields for DPO training, with process-reward labels verifiable against those fields. However, no equations or steps are shown that make the reported accuracy (or the +13.9 pp gain) equivalent to the training inputs by definition. The central generalization claim is presented as depending on the cold-split and taxonomy design rather than being forced by self-definition or self-citation. No load-bearing self-citation chain or ansatz smuggling is visible in the provided text. This is the normal case of a paper whose performance metric is externally benchmarked against held-out data.
Axiom & Free-Parameter Ledger
free parameters (1)
- DPO loss weights and PRM scaling factors
axioms (2)
- domain assumption DrugBank structured fields supply accurate, complete mechanism annotations that can serve as automatic process-reward labels without human verification
- ad hoc to paper The 7-family/147-subtype taxonomy partitions pharmacological mechanisms without overlap or omission that would bias the cold-split evaluation
Reference graph
Works this paper leans on
-
[2]
Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, and Owain Evans. 2024. https://arxiv.org/abs/2309.12288 The reversal curse: LLMs trained on `` A is B '' fail to learn `` B is A '' . In The Twelfth International Conference on Learning Representations
arXiv 2024
-
[3]
Tianqi Chen and Carlos Guestrin. 2016. https://arxiv.org/abs/1603.02754 Xgboost: A scalable tree boosting system . In KDD
Pith/arXiv arXiv 2016
-
[5]
Chi, Xuezhi Wang, and Denny Zhou
Xinyun Chen, Ryan A. Chi, Xuezhi Wang, and Denny Zhou. 2024. https://proceedings.mlr.press/v235/chen24i.html Premise order matters in reasoning with large language models . In Proceedings of the 41st International Conference on Machine Learning, volume 235, pages 6596--6620. PMLR
2024
-
[7]
Gabriele De Vito, Filomena Ferrucci, and Athanasios Angelakis. 2025. https://arxiv.org/abs/2502.06890 LLMs for drug-drug interaction prediction: A comprehensive comparison . arXiv preprint arXiv:2502.06890
Pith/arXiv arXiv 2025
-
[8]
Yifan Deng, Xinran Xu, Yang Qiu, Jingbo Xia, Wen Zhang, and Shichao Liu. 2020. https://academic.oup.com/bioinformatics/article/36/15/4316/5837109 A multimodal deep learning framework for predicting drug-drug interaction events . Bioinformatics
2020
-
[10]
Yao Fu, Hao Peng, Litu Ou, Ashish Sabharwal, and Tushar Khot. 2023. https://proceedings.mlr.press/v202/fu23d.html Specializing smaller language models towards multi-step reasoning . In Proceedings of the 40th International Conference on Machine Learning, volume 202, pages 10421--10430. PMLR
2023
-
[11]
Parsa Hejabi, Elnaz Rahmati, Alireza S. Ziabari, and Morteza Dehghani. 2025. https://arxiv.org/abs/2510.14242 Flip-flop consistency: Unsupervised training for robustness to prompt perturbations in LLMs . arXiv preprint arXiv:2510.14242
arXiv 2025
-
[12]
Yixin Hong, Pengyu Luo, Shuting Jin, and Xiangrong Liu. 2022. https://academic.oup.com/bioinformatics/article/38/24/5406/6769887 Lagat: Link-aware graph attention network for drug-drug interaction prediction . Bioinformatics
2022
-
[13]
Glass, and Jimeng Sun
Kexin Huang, Cao Xiao, Lucas M. Glass, and Jimeng Sun. 2020. https://ojs.aaai.org/index.php/AAAI/article/view/5412 Caster: Predicting drug interactions with chemical substructure representation . In AAAI
2020
-
[16]
Minoru Kanehisa and Susumu Goto. 2000. https://doi.org/10.1093/nar/28.1.27 KEGG : Kyoto Encyclopedia of Genes and Genomes . Nucleic Acids Research, 28(1):27--30
-
[17]
Sunyoung Kim, Hyeri Lee, Jaeyu Park, Jiseung Kang, Masoud Rahmati, Sang Youl Rhee, and Dong Keon Yon. 2024. https://doi.org/10.1016/j.archger.2024.105465 Global and regional prevalence of polypharmacy and related factors, 1997--2022: An umbrella review . Archives of Gerontology and Geriatrics, 122:105465
-
[18]
Craig Knox, Michael Wilson, Christopher M. Klinger, and 1 others. 2024. https://doi.org/10.1093/nar/gkad976 Drugbank 6.0: the drugbank knowledgebase for 2024 . Nucleic Acids Research, 52(D1):D1265--D1275
-
[21]
Zimeng Li, Shichao Zhu, Bin Shao, Xiangxiang Zeng, Tong Wang, and Tie-Yan Liu. 2023. https://academic.oup.com/bib/article/24/1/bbac597/6966537 Dsn-ddi: An accurate and generalizable drug-drug interaction prediction network . In Briefings in Bioinformatics
2023
-
[22]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. https://arxiv.org/abs/2305.20050 Let's verify step by step . In ICLR
Pith/arXiv arXiv 2023
-
[23]
Guanying Liu, Yifan Zhang, Xuan Liu, and Quanming Yao. 2025. https://arxiv.org/abs/2505.23034 Case-based reasoning enhances the predictive power of LLM s in drug-drug interaction . In arXiv:2505.23034
arXiv 2025
-
[25]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2024. https://arxiv.org/abs/2305.18290 Direct preference optimization: Your language model is secretly a reward model . In Advances in Neural Information Processing Systems (NeurIPS)
Pith/arXiv arXiv 2024
-
[26]
Yaniv Romano, Matteo Sesia, and Emmanuel Cand\` e s. 2020. https://proceedings.neurips.cc/paper_files/paper/2020/file/244edd7e85dc81602b7615cd705545f5-Paper.pdf Classification with valid and adaptive coverage . In NeurIPS
2020
-
[27]
Jae Yong Ryu, Hyun Uk Kim, and Sang Yup Lee. 2018. https://doi.org/10.1073/pnas.1803294115 Deep learning improves prediction of drug-drug and drug-food interactions . In Proceedings of the National Academy of Sciences, volume 115, pages E4304--E4311
-
[28]
Shuaijie She, Junxiao Liu, Yifeng Liu, Jiajun Chen, Xin Huang, and Shujian Huang. 2025. https://arxiv.org/abs/2503.21295 R-PRM : Reasoning-driven process reward modeling . In arXiv:2503.21295
arXiv 2025
-
[29]
Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, Perry Payne, Martin Seneviratne, Paul Gamble, Chris Kelly, Abubakr Babiker, Nathanael Sch\" a rli, Aakanksha Chowdhery, Philip Mansfield, Dina Demner-Fushman, and 13 others. 2023. https://doi.org/10.1038/s415...
-
[30]
Zhaoyue Sun, Jiazheng Li, Gabriele Pergola, and Yulan He. 2024. https://arxiv.org/abs/2409.05592 ExDDI : Explaining drug-drug interaction predictions with natural language . In AAAI
arXiv 2024
-
[31]
Yao Tian, Jiacai Yi, Ningning Wang, Chengkun Wu, Jinfu Peng, Shao Liu, Guoping Yang, and Dongsheng Cao. 2025. https://doi.org/10.1093/nar/gkae726 Ddinter 2.0: An enhanced drug interaction resource with expanded data coverage, new interaction types, and improved user interface . Nucleic Acids Research, 53(D1):D1356--D1362
-
[33]
Vladimir Vovk, Alex Gammerman, and Glenn Shafer. 2005. https://link.springer.com/book/10.1007/b106715 Algorithmic Learning in a Random World . Springer
-
[34]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. https://arxiv.org/abs/2203.11171 Self-consistency improves chain of thought reasoning in language models . In ICLR
Pith/arXiv arXiv 2023
-
[35]
Ziyan Wang, Zhankun Xiong, Feng Huang, Xuan Liu, and Wen Zhang. 2024. https://arxiv.org/abs/2407.00891 ZeroDDI : A zero-shot drug-drug interaction event prediction method with semantic enhanced learning and dual-modal uniform alignment . In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI)
arXiv 2024
-
[36]
Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang. 2024. https://aclanthology.org/2024.findings-acl.372/ Benchmarking retrieval-augmented generation for medicine . In ACL Findings
2024
-
[37]
Zhankun Xiong, Shichao Liu, Feng Huang, Ziyan Wang, Xuan Liu, Zhongfei Zhang, and Wen Zhang. 2023. https://doi.org/10.1609/aaai.v37i4.25665 Multi-relational contrastive learning graph neural network for drug-drug interaction event prediction . In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 5339--5347
-
[38]
Huimin Xu, Xin Mao, Feng-Lin Li, Xiaobao Wu, and 1 others. 2025. https://arxiv.org/abs/2502.14356 Full-step- DPO : Self-supervised preference optimization with step-wise rewards for mathematical reasoning . In arXiv:2502.14356
arXiv 2025
-
[39]
Glass, Jimeng Sun, and Cao Xiao
Yue Yu, Kexin Huang, Chao Zhang, Lucas M. Glass, Jimeng Sun, and Cao Xiao. 2021. https://doi.org/10.1093/bioinformatics/btab207 Sumgnn: Multi-typed drug interaction prediction via efficient knowledge graph summarization . In Bioinformatics
-
[40]
Jaehoon Yun, Jiwoong Sohn, Jungwoo Park, Hyunjae Kim, Xiangru Tang, Daniel Shao, Yong Hoe Koo, Minhyeok Ko, Qingyu Chen, Mark Gerstein, Michael Moor, and Jaewoo Kang. 2025. https://arxiv.org/abs/2506.11474 Med-prm: Medical reasoning models with stepwise, guideline-verified process rewards . Preprint, arXiv:2506.11474
arXiv 2025
-
[42]
AISTATS , year=
A General Theoretical Paradigm to Understand Learning from Human Preferences , author=. AISTATS , year=
-
[43]
Training Verifiers to Solve Math Word Problems , author=. arXiv:2110.14168 , year=
-
[44]
Solving Math Word Problems with Process- and Outcome-Based Feedback , author=. arXiv:2211.14275 , year=
-
[45]
ICLR , year=
Let's Verify Step by Step , author=. ICLR , year=
-
[46]
Common 7B Language Models Already Possess Strong Math Capabilities , author=. arXiv:2403.04706 , year=
-
[47]
S1: Simple Test-Time Scaling , author=. arXiv:2501.19393 , year=
-
[48]
Teaching Small Language Models to Reason , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=. 2023 , address=. doi:10.18653/v1/2023.acl-short.151 , url=
-
[49]
Proceedings of the 40th International Conference on Machine Learning , pages=
Specializing Smaller Language Models towards Multi-Step Reasoning , author=. Proceedings of the 40th International Conference on Machine Learning , pages=. 2023 , publisher=
2023
-
[50]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Skip-Thinking: Chunk-wise Chain-of-Thought Distillation Enable Smaller Language Models to Reason Better and Faster , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=. 2025 , address=. doi:10.18653/v1/2025.emnlp-main.610 , url=
-
[51]
Bioinformatics , year=
A multimodal deep learning framework for predicting drug-drug interaction events , author=. Bioinformatics , year=
-
[52]
AAAI , year=
CASTER: Predicting Drug Interactions with Chemical Substructure Representation , author=. AAAI , year=
-
[53]
Findings of EMNLP , year=
ExDDI: Explainable Drug-Drug Interaction Prediction with Retrieval-Augmented LLMs , author=. Findings of EMNLP , year=
-
[54]
IJCAI , year=
KGNN: Knowledge Graph Neural Network for Drug-Drug Interaction Prediction , author=. IJCAI , year=
-
[55]
IJCAI , year=
GoGNN: Graph of Graphs Neural Network for Predicting Structured Entity Interactions , author=. IJCAI , year=
-
[56]
Bioinformatics , year=
LaGAT: Link-aware Graph Attention Network for Drug-Drug Interaction Prediction , author=. Bioinformatics , year=
-
[57]
Bioinformatics , year=
MUFFIN: Multi-Scale Feature Fusion for Drug-Drug Interaction Prediction , author=. Bioinformatics , year=
-
[58]
WWW , year=
MIRACLE: Multi-View Graph Contrastive Representation Learning for Drug-Drug Interaction Prediction , author=. WWW , year=
-
[59]
Bioinformatics , year=
SumGNN: Multi-Typed Drug Interaction Prediction via Efficient Knowledge Graph Summarization , author=. Bioinformatics , year=
-
[60]
KDD , year=
TIGER: Transformer over Interaction Graphs for Drug-Drug Interaction , author=. KDD , year=
-
[61]
Briefings in Bioinformatics , year=
DSN-DDI: An Accurate and Generalizable Drug-Drug Interaction Prediction Network , author =. Briefings in Bioinformatics , year=
-
[62]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Multi-Relational Contrastive Learning Graph Neural Network for Drug-Drug Interaction Event Prediction , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2023 , doi =
2023
-
[63]
IEEE Trans.\ Neural Netw.\ Learn.\ Syst
MKG-FENN: A Multi-Knowledge-Graph Fingerprint Edge Neural Network for Drug-Drug Interaction , author=. IEEE Trans.\ Neural Netw.\ Learn.\ Syst. , year=
-
[64]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI) , year =
Wang, Ziyan and Xiong, Zhankun and Huang, Feng and Liu, Xuan and Zhang, Wen , title =. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI) , year =
-
[65]
arXiv preprint arXiv:2602.00539 , year =
Jin, Xinmo and Fan, Bowen and Li, Xunkai and Sun, Henan and others , title =. arXiv preprint arXiv:2602.00539 , year =
-
[66]
2025 , url=
De Vito, Gabriele and Ferrucci, Filomena and Angelakis, Athanasios , journal=. 2025 , url=
2025
-
[67]
Nature , volume=
Large Language Models Encode Clinical Knowledge , author=. Nature , volume=. 2023 , doi=
2023
-
[68]
and others , title =
Knox, Craig and Wilson, Michael and Klinger, Christopher M. and others , title =. Nucleic Acids Research , volume =. 2024 , doi =
2024
-
[69]
Nucleic Acids Research , volume=
DDInter 2.0: An enhanced drug interaction resource with expanded data coverage, new interaction types, and improved user interface , author=. Nucleic Acids Research , volume=. 2025 , doi=
2025
-
[70]
2025 , eprint=
Med-PRM: Medical Reasoning Models with Stepwise, Guideline-Verified Process Rewards , author=. 2025 , eprint=
2025
-
[71]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[72]
Qwen2.5 Technical Report , author=
-
[73]
DeepSeek-R1: Incentivizing Reasoning Capability via Reinforcement Learning , author=
-
[74]
KDD , year=
XGBoost: A Scalable Tree Boosting System , author=. KDD , year=
-
[75]
ACL Findings , year=
Benchmarking Retrieval-Augmented Generation for Medicine , author =. ACL Findings , year=
-
[76]
EMNLP , year=
Knowledge-Augmented Multimodal Clinical Rationale Generation for Disease Diagnosis with Small Language Models , author=. EMNLP , year=
-
[77]
The Reversal Curse:
Berglund, Lukas and Tong, Meg and Kaufmann, Max and Balesni, Mikita and Stickland, Asa Cooper and Korbak, Tomasz and Evans, Owain , booktitle=. The Reversal Curse:. 2024 , url=
2024
-
[78]
Proceedings of the 41st International Conference on Machine Learning , pages=
Premise Order Matters in Reasoning with Large Language Models , author=. Proceedings of the 41st International Conference on Machine Learning , pages=. 2024 , publisher=
2024
-
[79]
Findings of the Association for Computational Linguistics:
Striking a Balance: Alleviating Inconsistency in Pre-trained Models for Symmetric Classification Tasks , author=. Findings of the Association for Computational Linguistics:. 2022 , address=. doi:10.18653/v1/2022.findings-acl.148 , url=
-
[80]
and Dehghani, Morteza , journal=
Hejabi, Parsa and Rahmati, Elnaz and Ziabari, Alireza S. and Dehghani, Morteza , journal=. Flip-Flop Consistency: Unsupervised Training for Robustness to Prompt Perturbations in. 2025 , url=
2025
-
[81]
ICLR , year=
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval , author=. ICLR , year=
-
[82]
Hard Negative Sample-Augmented DPO Post-Training for Small Language Models , author=. arXiv:2407.13856 , year=
-
[83]
Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
Yuan, Weizhe and Pang, Richard Yuanzhe and Cho, Kyunghyun and others , title =. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[84]
NeurIPS , year=
Adversarial Negatives for Direct Preference Optimization , author=. NeurIPS , year=
-
[85]
Symmetric Direct Preference Optimization , author=. arXiv:2402.13228 , year=
-
[86]
MedBench: A Large-Scale Chinese Medical Benchmark , author=. arXiv:2403.01469 , year=
-
[87]
ACL , year=
Statistical Reward Models for Factual Generation , author=. ACL , year=
-
[88]
SLiC-HF: Sequence Likelihood Calibration with Human Feedback , author=. arXiv:2305.10425 , year=
-
[89]
ICLR , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. ICLR , year=
-
[90]
2005 , url =
Algorithmic Learning in a Random World , author=. 2005 , url =
2005
-
[91]
NeurIPS , year=
Classification with Valid and Adaptive Coverage , author=. NeurIPS , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.