Active Learning for Cascaded Object Detection: Balancing Coverage and Uncertainty in Table Extraction Pipelines
Pith reviewed 2026-07-02 14:24 UTC · model grok-4.3
The pith
Pipeline-aware active learning strategies outperform standard methods for cascaded table extraction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
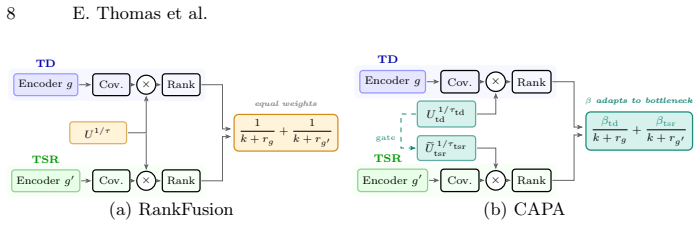
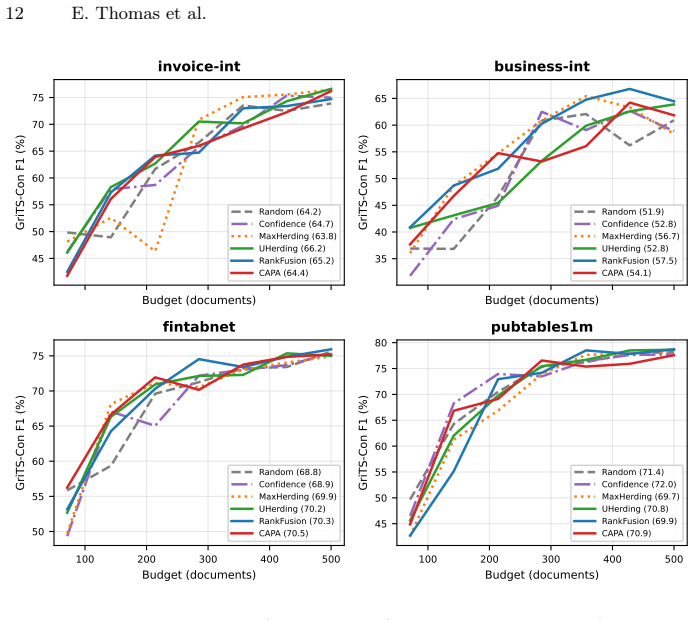
The first adaptation of Uncertainty Herding to cascaded object detection pipelines is presented, with two pipeline-aware extensions that exploit the TD-to-TSR dependency. RankFusion adds dual-manifold coverage over both detection and structure representation spaces, while CAPA further incorporates stage-dependent gating and per-task uncertainty calibration. Experiments across two public and two private datasets show that UHerding generalizes well to table extraction and outperforms each baseline, while among the pipeline-aware variants CAPA is the most consistent and outperforms standard UHerding on three out of four datasets.
What carries the argument
Pipeline-aware extensions to Uncertainty Herding (RankFusion with dual-manifold coverage and CAPA with stage-dependent gating) that exploit the TD-to-TSR dependency for sampling in cascaded table extraction.
If this is right
- UHerding generalizes well to table extraction, outperforming each baseline.
- RankFusion achieves higher expected gains but at the cost of greater variance.
- CAPA emerges as the most consistent strategy, outperforming standard UHerding on three out of four datasets.
- The methods remain effective across annotation budgets from 71 to 500 documents on both public and private datasets.
Where Pith is reading between the lines
- The stage-dependent approach may transfer to other cascaded vision pipelines where an early localization step informs a later recognition step.
- CAPA's consistency could make it suitable for production document systems that prioritize stable performance across varying document collections.
- Explicit checks for how detection-stage errors influence structure-stage sampling could identify further refinements to the gating mechanism.
Load-bearing premise
Exploiting the TD-to-TSR dependency via dual-manifold coverage and stage-dependent gating does not introduce new error propagation or selection biases that negate the reported gains.
What would settle it
A controlled test on a dataset with high table detection error rates in which CAPA no longer outperforms standard UHerding or produces lower end-to-end table extraction accuracy.
Figures

read the original abstract
Table extraction from business documents relies on a cascaded pipeline where Table Detection (TD) first localizes tables and Table Structure Recognition (TSR) then recovers their internal layout. Building task-specific training sets for this pipeline is costly, particularly for TSR which requires fine-grained structural annotations. Active learning (AL) can reduce this annotation burden, yet most AL strategies are designed for single-model tasks and do not account for inter-stage dependencies in cascaded architectures. In this work, we present the first adaptation of Uncertainty Herding (UHerding), a hybrid coverage-uncertainty sampling method originally proposed for image classification, to cascaded object detection pipelines. We propose two pipeline-aware extensions that exploit the TD-to-TSR dependency: RankFusion adds dual-manifold coverage over both detection and structure representation spaces, while CAPA further incorporates stage-dependent gating and per-task uncertainty calibration. Extensive experiments across two public (PubTables-1M and FinTabNet) and two private table extraction datasets, with various annotation budgets (from 71 to 500 documents) show that UHerding generalizes well to table extraction, outperforming each baseline. Among pipeline-aware variants, RankFusion achieves higher expected gains but at the cost of greater variance, while CAPA emerges as the most consistent strategy, outperforming standard UHerding on three out of four datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper adapts Uncertainty Herding (UHerding) to cascaded table extraction pipelines consisting of Table Detection (TD) followed by Table Structure Recognition (TSR). It introduces two pipeline-aware extensions—RankFusion (dual-manifold coverage) and CAPA (stage-dependent gating plus per-task uncertainty calibration)—that exploit the TD-to-TSR dependency. Experiments on two public and two private datasets across annotation budgets of 71–500 documents show that UHerding generalizes well, while CAPA is the most consistent pipeline-aware variant, outperforming standard UHerding on three of four datasets.
Significance. If the empirical results hold under proper statistical controls, the work supplies the first explicit treatment of inter-stage dependencies in active learning for cascaded object-detection pipelines. This is practically relevant for document-analysis tasks where TSR annotation is far more expensive than TD annotation. The hybrid coverage-uncertainty framing and the concrete extensions (RankFusion, CAPA) are reusable beyond tables.
major comments (2)
- [Abstract] Abstract: the headline claim that 'CAPA emerges as the most consistent strategy, outperforming standard UHerding on three out of four datasets' is presented without error bars, results across random seeds, or any statistical test. Because the text already notes greater variance for RankFusion, the absence of these controls makes the 'most consistent' ranking unverifiable and load-bearing for the central empirical conclusion.
- [Abstract] Abstract / Methods (implied): the premise that stage-dependent gating and dual-manifold coverage 'exploit the TD-to-TSR dependency' without introducing new selection bias is not accompanied by any ablation or sensitivity analysis on TD localization errors propagating into TSR-stage sampling and uncertainty estimates. This is the exact mechanism the skeptic note flags and is required to substantiate the pipeline-aware advantage.
minor comments (1)
- [Abstract] The abstract states results 'across two public (PubTables-1M and FinTabNet) and two private table extraction datasets' but does not name the private datasets or give their characteristics; this should be supplied for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which help strengthen the presentation of our empirical results. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that 'CAPA emerges as the most consistent strategy, outperforming standard UHerding on three out of four datasets' is presented without error bars, results across random seeds, or any statistical test. Because the text already notes greater variance for RankFusion, the absence of these controls makes the 'most consistent' ranking unverifiable and load-bearing for the central empirical conclusion.
Authors: We acknowledge the need for statistical rigor in supporting the claim. The manuscript will be revised to include results from multiple random seeds with error bars and appropriate statistical tests (such as Wilcoxon signed-rank tests) to verify the consistency of CAPA's performance across datasets. revision: yes
-
Referee: [Abstract] Abstract / Methods (implied): the premise that stage-dependent gating and dual-manifold coverage 'exploit the TD-to-TSR dependency' without introducing new selection bias is not accompanied by any ablation or sensitivity analysis on TD localization errors propagating into TSR-stage sampling and uncertainty estimates. This is the exact mechanism the skeptic note flags and is required to substantiate the pipeline-aware advantage.
Authors: Our experiments utilize real datasets where TD predictions contain localization errors that propagate to TSR, and the performance improvements demonstrate the effectiveness of the pipeline-aware methods in this realistic setting. To directly address concerns about selection bias, we will add an ablation study in the revised manuscript that simulates controlled TD error rates and analyzes their effect on TSR sampling and overall gains. revision: yes
Circularity Check
No circularity: empirical comparison of AL extensions on table extraction pipelines
full rationale
The manuscript adapts an existing method (UHerding) and introduces two algorithmic extensions (RankFusion, CAPA) that are evaluated through experiments on four datasets under varying annotation budgets. Central claims rest on measured performance differences versus baselines rather than any derivation, equation, or fitted quantity that reduces to its own inputs. No self-citation chains, self-definitional constructions, or renamings of known results appear as load-bearing steps. The work is self-contained as an empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the International Conference on Learning Representations (ICLR) (2020), https: //openreview.net/forum?id=ryghZJBKPS
Ash, J.T., Zhang, C., Krishnamurthy, A., Langford, J., Agarwal, A.: Deep batch active learning by diverse, uncertain gradient lower bounds. In: Proceedings of the International Conference on Learning Representations (ICLR) (2020), https: //openreview.net/forum?id=ryghZJBKPS
2020
-
[2]
In: European Conference on Computer Vision (2024), https://api.semanticscholar.org/CorpusID:271244923
Bae, W., Noh, J., Sutherland, D.J.: Generalized coverage for more robust low- budget active learning. In: European Conference on Computer Vision (2024), https://api.semanticscholar.org/CorpusID:271244923
2024
-
[3]
In: ICLR (2025)
Bae, W., Sutherland, D.J., Oliveira, G.L.: Uncertainty herding: One active learning method for all label budgets. In: ICLR (2025)
2025
-
[4]
International Journal on Docu- ment Analysis and Recognition27, 317–334 (2024)
Banerjee, A., Biswas, S., Lladós, J., Pal, U.: SemiDocSeg: Harnessing semi- supervised learning for document layout analysis. International Journal on Docu- ment Analysis and Recognition27, 317–334 (2024)
2024
-
[5]
In: International Conference on Learning Representations (ICLR) (2024)
Blecher, L., Cucurull, G., Scialom, T., Stojnic, R.: Nougat: Neural optical un- derstanding for academic documents. In: International Conference on Learning Representations (ICLR) (2024)
2024
-
[6]
In: European Conference on Computer Vision (ECCV)
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European Conference on Computer Vision (ECCV). pp. 213–229 (2020)
2020
-
[7]
In: IEEE/CVF International Conference on Computer Vision (ICCV)
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: IEEE/CVF International Conference on Computer Vision (ICCV). pp. 9650–9660 (2021)
2021
-
[8]
In: Proceedings of the 37th International Conference on Machine Learning (ICML)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: Proceedings of the 37th International Conference on Machine Learning (ICML). vol. 119, pp. 1597–1607. PMLR (2020)
2020
-
[9]
In: Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval
Cormack, G.V., Clarke, C.L.A., Büttcher, S.: Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In: Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 758–759. ACM (2009)
2009
-
[10]
In: international conference on machine learning
Gal, Y., Ghahramani, Z.: Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In: international conference on machine learning. pp. 1050–1059. PMLR (2016)
2016
-
[11]
In: International conference on machine learning
Gal, Y., Islam, R., Ghahramani, Z.: Deep bayesian active learning with image data. In: International conference on machine learning. pp. 1183–1192. PMLR (2017)
2017
-
[12]
2019 International Conference on Document Analysis and Recognition (ICDAR) pp
Gao, L., Huang, Y., Déjean, H., Meunier, J.L., Yan, Q., Fang, Y., Kleber, F., Lang, E.M.: Icdar 2019 competition on table detection and recognition (ctdar). 2019 International Conference on Document Analysis and Recognition (ICDAR) pp. 1510–1515 (2019), https://api.semanticscholar.org/CorpusID:211026773
2019
-
[13]
In: Inter- national Conference on Document Analysis and Recognition
Gautam, S., Purohit, N., Harit, G.: Table detection with active learning. In: Inter- national Conference on Document Analysis and Recognition. pp. 130–146. Springer (2025)
2025
-
[14]
2013 12th International Conference on Document Analysis and Recognition pp
Göbel, M.C., Hassan, T., Oro, E., Orsi, G.: Icdar 2013 table competition. 2013 12th International Conference on Document Analysis and Recognition pp. 1449–1453 (2013), https://api.semanticscholar.org/CorpusID:206777311 16 E. Thomas et al
2013
-
[15]
In: Proceedings of the 34th International Conference on Machine Learning (ICML)
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On calibration of modern neural networks. In: Proceedings of the 34th International Conference on Machine Learning (ICML). vol. 70, pp. 1321–1330. PMLR (2017)
2017
-
[16]
In: International Conference on Machine Learning (ICML)
Hacohen, G., Dekel, A., Weinshall, D.: Active learning on a budget: Opposite strategies suit high and low budgets. In: International Conference on Machine Learning (ICML). vol. 162, pp. 8175–8195. PMLR (2022)
2022
-
[17]
In: Document Analysis and Recognition (ICDAR)
Hou, Q., Wang, J.: TABLET: Table structure recognition using encoder-only transformers. In: Document Analysis and Recognition (ICDAR). pp. 253–278 (2026)
2026
-
[18]
ACM Computing Surveys56, 1 – 41 (2022), https://api.semanticscholar.org/CorpusID:253553399
Kasem, M.M., Abdallah, A., Berendeyev, A., Elkady, E., Abdalla, M., Mahmoud, M., Hamada, M., Nurseitov, D.B., Taj-Eddin, I.: Deep learning for table detection and structure recognition: A survey. ACM Computing Surveys56, 1 – 41 (2022), https://api.semanticscholar.org/CorpusID:253553399
2022
-
[19]
In: International Joint Conference on Artificial Intelligence (IJCAI) (2024)
Khang, M., Hong, T.: TFLOP: Table structure recognition framework with layout pointer mechanism. In: International Joint Conference on Artificial Intelligence (IJCAI) (2024)
2024
-
[20]
In: European Conference on Computer Vision (ECCV) (2022)
Kim, G., Hong, T., Yim, M., Nam, J., Park, J., Yim, J., Hwang, W., Yun, S., Han, D., Park, S.: Ocr-free document understanding transformer. In: European Conference on Computer Vision (ECCV) (2022)
2022
-
[21]
In: Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (1994), https://api.semanticscholar.org/CorpusID:915058
Lewis, D.D., Gale, W.A.: A sequential algorithm for training text classifiers. In: Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (1994), https://api.semanticscholar.org/CorpusID:915058
1994
-
[22]
In: Proceedings of the 30th ACM International Conference on Multimedia
Li, J., Xu, Y., Lv, T., Cui, L., Zhang, C., Wei, F.: DiT: Self-supervised pre-training for document image transformer. In: Proceedings of the 30th ACM International Conference on Multimedia. pp. 4003–4011. ACM (2022)
2022
-
[23]
Pattern Recognition157, 110816 (2025)
Long, R., Xing, H., Yang, Z., Zheng, Q., Yu, Z., Huang, F., Yao, C.: LORE++: Logical location regression network for table structure recognition with pre-training. Pattern Recognition157, 110816 (2025)
2025
-
[24]
In: Advances in Neural Information Processing Systems (NeurIPS)
Lüth, C.T., Bungert, T.J., Klein, L., Jaeger, P.F.: Navigating the pitfalls of ac- tive learning evaluation: A systematic framework for meaningful assessment. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 36 (2023)
2023
-
[25]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Machnio, J., Nielsen, M., Ghazi, M.M.: To label or not to label: Palm-a predictive model for evaluating sample efficiency in active learning models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4039–4048 (2025)
2025
-
[26]
In: IEEE/CVF International Conference on Computer Vision (ICCV) (2025)
Nassar, A., Omenetti, M., Lysak, M., Livathinos, N., Auer, C., Morin, L., de Lima, R.T., Kim, Y., Gurbuz, A.S., Dolfi, M., Staar, P.W.J.: SmolDocling: An ultra- compact vision-language model for end-to-end multi-modal document conversion. In: IEEE/CVF International Conference on Computer Vision (ICCV) (2025)
2025
-
[27]
In: International Conference on Learning Representations (ICLR) (2025)
Peng, Y., Li, H., Wu, P., Zhang, Y., Sun, X., Wu, F.: D-FINE: Redefine regression task in DETRs as fine-grained distribution refinement. In: International Conference on Learning Representations (ICLR) (2025)
2025
-
[28]
ACM Computing Surveys (CSUR)54, 1 – 40 (2020), https://api.semanticscholar.org/CorpusID:221397441
Ren, P., Xiao, Y., Chang, X., Huang, P.Y.B., Li, Z., Chen, X., Wang, X.: A survey of deep active learning. ACM Computing Surveys (CSUR)54, 1 – 40 (2020), https://api.semanticscholar.org/CorpusID:221397441
2020
-
[29]
In: AAAI
Roth, D., Small, K.: Active learning for pipeline models. In: AAAI. pp. 683–688 (2008)
2008
-
[30]
Schreiber, S., Agne, S., Wolf, I., Dengel, A.R., Ahmed, S.: Deepdesrt: Deep learning for detection and structure recognition of tables in document images. 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR) 01, 1162–1167 (2017), https://api.semanticscholar.org/CorpusID:10191334 Active Learning for Cascaded Object Detection 17
2017
-
[31]
Social Choice and Welfare 36(2), 267–303 (2011)
Schulze, M.: A new monotonic, clone-independent, reversal symmetric, and Condorcet-consistent single-winner election method. Social Choice and Welfare 36(2), 267–303 (2011)
2011
-
[32]
In: International Conference on Learning Representations (ICLR) (2018)
Sener, O., Savarese, S.: Active learning for convolutional neural networks: A core-set approach. In: International Conference on Learning Representations (ICLR) (2018)
2018
-
[33]
org/CorpusID:324600
Settles, B.: Active learning literature survey (2009), https://api.semanticscholar. org/CorpusID:324600
2009
-
[34]
In: Docu- ment Analysis and Recognition (ICDAR) (2024)
Shehzadi, T., Sarode, S., Stricker, D., Afzal, M.Z.: Towards end-to-end semi- supervised table detection with semantic aligned matching transformer. In: Docu- ment Analysis and Recognition (ICDAR) (2024)
2024
-
[35]
In: Proceedings of the Fifth Workshop on Natural Language Processing and Computational Social Science (NLP+CSS)
Shen, Z., Li, W., Zhao, J., Yu, Y., Dell, M.: OLALA: Object-level active learning for efficient document layout annotation. In: Proceedings of the Fifth Workshop on Natural Language Processing and Computational Social Science (NLP+CSS). pp. 170–182. Abu Dhabi, UAE (2022), https://aclanthology.org/2022.nlpcss-1.19/
2022
-
[36]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Smock, B., Pesala, R., Abraham, R.: PubTables-1M: Towards comprehensive table extraction from unstructured documents. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4634–4642 (2022)
2022
-
[37]
In: Document Analysis and Recognition (ICDAR)
Smock, B., Pesala, R., Abraham, R.: GriTS: Grid table similarity metric for table structure recognition. In: Document Analysis and Recognition (ICDAR). p. 535–549 (2023)
2023
-
[38]
In: Document Analysis and Recognition – ICDAR 2023
Subramanian, V., Poudel, S., Chaudhuri, P., Ramakrishnan, G.: TACTFUL: A framework for targeted active learning for document analysis. In: Document Analysis and Recognition – ICDAR 2023. vol. 13824, pp. 259–273. Springer (2023). https: //doi.org/10.1007/978-3-031-41734-4_16
-
[39]
In: Winter Conference on Applications of Computer Vision (WACV) (2025)
Thomas, E., Coustaty, M., Joseph, A., Deloin, G., Carel, E., D’Andecy, V.P., Ogier, J.M.: RAPTOR: Refined approach for product table object recognition. In: Winter Conference on Applications of Computer Vision (WACV) (2025)
2025
-
[40]
In: International Conference on Document Analysis and Recognition (IC- DAR) (2025)
Thomas, E., Coustaty, M., Joseph, A., Deloin, G., Carel, E., D’Andecy, V.P., Ogier, J.M.: QUEST: Quality-aware semi-supervised table extraction for business documents. In: International Conference on Document Analysis and Recognition (ICDAR) (2025). https://doi.org/10.1007/978-3-032-04630-7_16
-
[41]
In: European Conference on Computer Vision (ECCV) (2024)
Wang, C.Y., Yeh, I.H., Liao, H.Y.M.: YOLOv9: Learning what you want to learn using programmable gradient information. In: European Conference on Computer Vision (ECCV) (2024)
2024
-
[42]
doi: https://doi.org/10.1016/j.eswa
Xiao, B., Simsek, M., Kantarci, B., Alkheir, A.A.: Rethinking detection based table structure recognition for visually rich document images. Expert Systems with Applications269, 126461 (2025). https://doi.org/https://doi.org/10.1016/j.eswa. 2025.126461
-
[43]
Advances in Neural Information Processing Systems35, 22354–22367 (2022)
Yehuda, O., Dekel, A., Hacohen, G., Weinshall, D.: Active learning through a covering lens. Advances in Neural Information Processing Systems35, 22354–22367 (2022)
2022
-
[44]
In: Findings of the Association for Computational Linguistics: EMNLP
Zhang, Z., Liu, S., Hu, P., Ma, J., Du, J., Zhang, J., Hu, Y.: UniTabNet: Bridging vision and language models for enhanced table structure recognition. In: Findings of the Association for Computational Linguistics: EMNLP. p. 6131–6143 (2024)
2024
-
[45]
2021 IEEE Winter Conference on Applications of Computer Vision (WACV) pp
Zheng, X., Burdick, D., Popa, L., Wang, N.X.R.: Global table extractor (gte): A framework for joint table identification and cell structure recognition using visual context. 2021 IEEE Winter Conference on Applications of Computer Vision (WACV) pp. 697–706 (2020), https://api.semanticscholar.org/CorpusID:218487305
2021
-
[46]
In: European Conference on Computer Vision (ECCV)
Zhong, X., ShafieiBavani, E., Jimeno Yepes, A.: Image-based table recognition: Data, model, and evaluation. In: European Conference on Computer Vision (ECCV). pp. 564–580 (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.