PriFT: Prior-Support Guided Supervised Fine-Tuning
Pith reviewed 2026-06-27 16:56 UTC · model grok-4.3
The pith
Reweighting SFT tokens from the frozen pretrained model outperforms online-model reweighting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
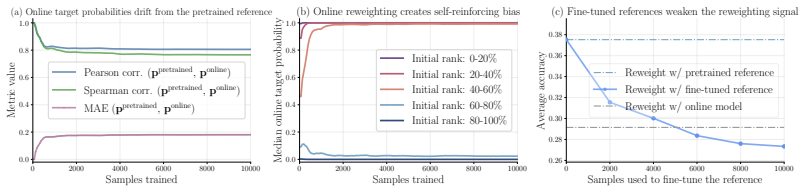
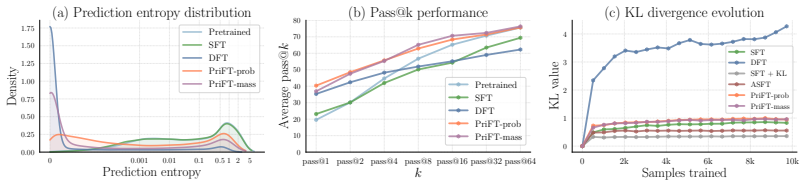
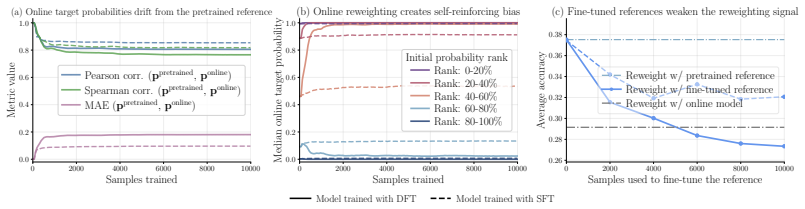
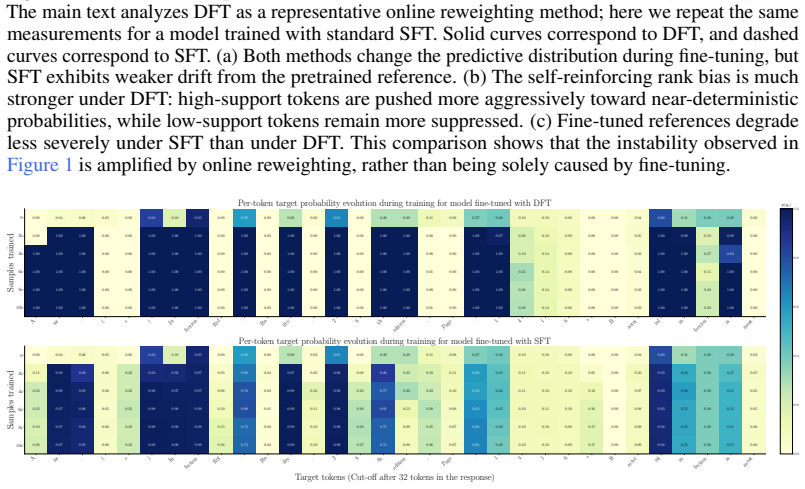
PriFT derives token weights from a frozen pretrained reference to obtain a stable reweighting signal unaffected by fine-tuning. This signal estimates prior support: the extent to which each target token is supported by the pretrained distribution. Across multiple existing token-reweighting rules, replacing the reweighting signal from the online model to pretrained model consistently improves performance. Two instantiations are introduced: PriFT-prob uses pretrained token probability, while PriFT-mass selects tokens by cumulative probability mass under the pretrained distribution.
What carries the argument
Prior-support signal computed from the frozen pretrained model's output distribution over target tokens.
If this is right
- SFT reaches state-of-the-art results among supervised baselines on mathematical reasoning, code generation, and medical question answering.
- The same performance lift occurs when any of several existing token-reweighting rules is supplied with pretrained rather than online probabilities.
- Checkpoints produced by PriFT serve as stronger initializations for subsequent reinforcement learning stages.
Where Pith is reading between the lines
- The result suggests that preserving alignment with the base model's knowledge distribution can matter more than adapting weights dynamically to the fine-tuning trajectory.
- The same prior-support idea could be tested in preference optimization or other post-training objectives that also suffer from distribution drift.
- Gains may arise mainly from down-weighting tokens the base model would rarely generate, thereby reducing overfitting to low-support demonstrations.
Load-bearing premise
Token probabilities from the frozen pretrained model remain a reliable and stable guide for which demonstration tokens deserve higher weight throughout fine-tuning.
What would settle it
A controlled experiment on the same benchmarks in which switching the reweighting source back to the online model produces equal or higher final accuracy than using the pretrained source.
Figures

read the original abstract
Supervised fine-tuning (SFT) is an efficient approach for downstream task adaptation and often serves as the initialization stage for reinforcement learning (RL), but it can show weaker generalization than RL. A key limitation is its off-policy objective: SFT fits fixed demonstrations token by token, including targets poorly aligned with the model's pretrained distribution, which can lead to overfitting. A recent line of work addresses this issue by assigning larger training weights to tokens better aligned with the current model's predictive distribution, with the intuition that fitting these tokens are less distortive to the model's pretrained knowledge and representations. However, computing the token weights from the model that is currently fine-tuned entangles token weights with the optimization trajectory, inducing a self-reinforcing dynamics as the distribution rapidly departs from the pretrained model. To address this, we propose PriFT (Prior-support guided Fine-Tuning), which derives token weights from a frozen pretrained reference to obtain a stable reweighting signal unaffected by fine-tuning. This signal estimates prior support: the extent to which each target token is supported by the pretrained distribution. Across multiple existing token-reweighting rules, replacing the reweighting signal from the online model to pretrained model consistently improves performance. We introduce two instantiations: PriFT-prob uses pretrained token probability, while PriFT-mass selects tokens by cumulative probability mass under the pretrained distribution. Extensive experiments on mathematical reasoning, code generation, and medical question answering show that PriFT achieves state-of-the-art results among SFT baselines and provides a better initialization for subsequent RL training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PriFT, which modifies token-reweighting approaches to SFT by deriving weights from a frozen pretrained reference model rather than the online model being fine-tuned. This is intended to provide a stable estimate of prior support for target tokens and avoid self-reinforcing dynamics. The authors report that the change yields consistent gains across multiple reweighting rules on mathematical reasoning, code generation, and medical QA, reaching SOTA among SFT baselines and supplying a stronger initialization for subsequent RL.
Significance. If the empirical claims hold, the work supplies a low-overhead, broadly applicable fix to an identified entanglement problem in reweighted SFT. The use of an external frozen model as the source of the reweighting signal is a direct and falsifiable remedy; the reported consistency across reweighting rules and domains would make the result practically useful for improving SFT initialization quality.
minor comments (3)
- The abstract states that PriFT 'achieves state-of-the-art results among SFT baselines,' but the manuscript should include an explicit table or section listing the exact prior SFT baselines, their reported scores, and the evaluation protocol (e.g., exact match, pass@k) used for each domain.
- The two instantiations (PriFT-prob and PriFT-mass) are introduced without equations; adding the precise definitions of the token-weight functions (e.g., how cumulative mass is thresholded) would clarify reproducibility.
- The claim that the pretrained signal 'avoids self-reinforcing dynamics' would be strengthened by a short ablation showing the divergence (e.g., KL or token-weight correlation) between online-model weights and pretrained weights over training steps.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of PriFT and the recommendation of minor revision. The report provides no specific major comments to address.
Circularity Check
No significant circularity identified
full rationale
The core construction replaces the token-reweighting signal with values computed from a fixed, external frozen pretrained reference model. This choice is independent of quantities fitted during the current SFT run and does not reduce any claimed prediction or uniqueness result to a self-fit or self-citation chain. No equations equate the proposed prior-support weights to quantities derived from the online model, and the reported gains are presented as empirical outcomes across reweighting rules and domains rather than as algebraic identities. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token weights from the frozen pretrained distribution estimate prior support and avoid entanglement with the fine-tuning trajectory
Reference graph
Works this paper leans on
-
[1]
Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
-
[2]
Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
-
[3]
Xiwen Chen, Jingjing Wang, Wenhui Zhu, Peijie Qiu, Xuanzhao Dong, Hejian Sang, Zhipeng Wang, Alborz Geramifard, and Feng Luo. Soda: Semi on-policy black-box distillation for large language models.arXiv preprint arXiv:2604.03873,
-
[4]
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161,
-
[5]
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
-
[6]
Muxi Diao, Lele Yang, Wuxuan Gong, Yutong Zhang, Zhonghao Yan, Yufei Han, Kongming Liang, Weiran Xu, and Zhanyu Ma. Entropy-adaptive fine-tuning: Resolving confident conflicts to mitigate forgetting.arXiv preprint arXiv:2601.02151,
-
[7]
Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300,
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300,
Pith/arXiv arXiv 2009
-
[8]
Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
-
[9]
Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
-
[10]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186,
-
[11]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974,
-
[12]
11 Jongwoo Ko, Sungnyun Kim, Tianyi Chen, and Se-Young Yun. Distillm: Towards streamlined distillation for large language models.arXiv preprint arXiv:2402.03898,
-
[13]
Distillm-2: A contrastive approach boosts the distillation of llms.arXiv preprint arXiv:2503.07067,
Jongwoo Ko, Tianyi Chen, Sungnyun Kim, Tianyu Ding, Luming Liang, Ilya Zharkov, and Se- Young Yun. Distillm-2: A contrastive approach boosts the distillation of llms.arXiv preprint arXiv:2503.07067,
-
[14]
Ananya Kumar, Aditi Raghunathan, Robbie Jones, Tengyu Ma, and Percy Liang. Fine-tuning can distort pretrained features and underperform out-of-distribution.arXiv preprint arXiv:2202.10054,
-
[15]
Llm post-training: A deep dive into reasoning large language models.arXiv preprint arXiv:2502.21321,
Komal Kumar, Tajamul Ashraf, Omkar Thawakar, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, Phillip HS Torr, Fahad Shahbaz Khan, and Salman Khan. Llm post-training: A deep dive into reasoning large language models.arXiv preprint arXiv:2502.21321,
-
[16]
Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124,
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124,
-
[17]
Tao Liu, Taiqiang Wu, Runming Yang, Shaoning Sun, Junjie Wang, and Yujiu Yang. Profit: Leveraging high-value signals in sft via probability-guided token selection.arXiv preprint arXiv:2601.09195,
-
[18]
Chongli Qin and Jost Tobias Springenberg. Supervised fine tuning on curated data is reinforcement learning (and can be improved).arXiv preprint arXiv:2507.12856,
-
[19]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300,
-
[20]
Rl’s razor: Why online reinforcement learning forgets less.arXiv preprint arXiv:2509.04259,
Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal. Rl’s razor: Why online reinforcement learning forgets less.arXiv preprint arXiv:2509.04259,
-
[21]
Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897,
12 Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897,
-
[22]
Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
-
[23]
Wenda Xu, Rujun Han, Zifeng Wang, Long T Le, Dhruv Madeka, Lei Li, William Yang Wang, Rishabh Agarwal, Chen-Yu Lee, and Tomas Pfister. Speculative knowledge distillation: Bridging the teacher-student gap through interleaved sampling.arXiv preprint arXiv:2410.11325,
-
[24]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[25]
Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
-
[26]
Wenhao Yu, Shaohang Wei, Jiahong Liu, Yifan Li, Minda Hu, Aiwei Liu, Hao Zhang, and Irwin King. Probability-entropy calibration: An elastic indicator for adaptive fine-tuning.arXiv preprint arXiv:2602.01745,
-
[27]
Dylan Zhang, Yufeng Xu, Haojin Wang, Qingzhi Chen, and Hao Peng. Good sft optimizes for sft, better sft prepares for reinforcement learning.arXiv preprint arXiv:2602.01058, 2026a. Miaosen Zhang, Yishan Liu, Shuxia Lin, Xu Yang, Qi Dai, Chong Luo, Weihao Jiang, Peng Hou, Anxiang Zeng, Xin Geng, et al. Towards on-policy sft: Distribution discriminant theory...
-
[28]
13 A Related Work Token-reweighted supervised fine-tuning.Recent work improves SFT by reweighting or selecting target tokens according to model-derived signals, rather than treating all tokens in a response equally. DFT and TALR use target-token probability to assign larger weights to high-confidence tokens [Wu et al., 2026, Lin et al., 2026], while ProFi...
2026
-
[29]
argue that on-policy RL forgets less precisely because it trains on rollouts the model itself produces. These findings motivate token-reweighting methods that try to make SFT behave more like on-policy training [Qin and Springenberg, 2025, Wu et al., 2026, Zhang et al., 2026b, Zhu et al., 2026]. SFT objectives as initialization for RLA complementary line ...
2025
-
[30]
We adopt this perspective as an auxiliary evaluation of token-reweighted SFT
propose GEM, a method to better preserve the sampling diversity during supervised fine-tuning stage, which can potentially improve exploration to improve performance limits with reinforcement learning. We adopt this perspective as an auxiliary evaluation of token-reweighted SFT. Our results show that PriFT improves over vanilla SFT and DFT both before RL ...
2026
-
[31]
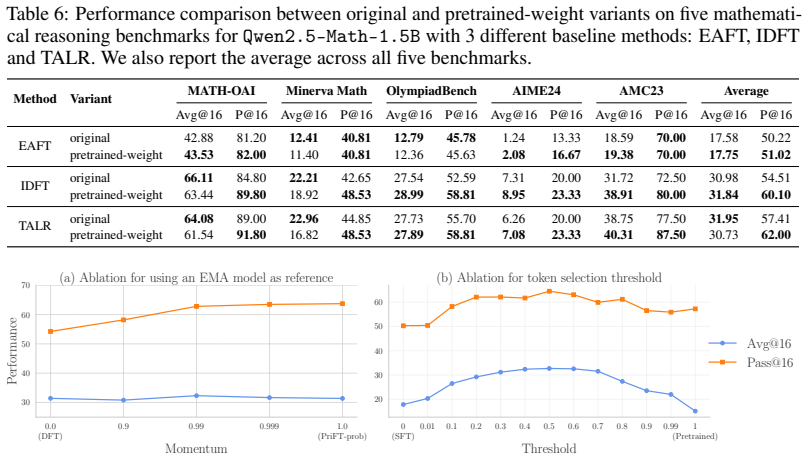
Unless otherwise specified, experiments are conducted on Qwen2.5-Math-1.5B. Replacing the pretrained reference with an EMA model.We test whether the frozen pretrained reference in PriFT-prob can be replaced by an exponential moving average (EMA) of the online model: θ(k) ema ←ρθ (k−1) ema + (1−ρ)θ (k) on . Here, ρ= 0 recovers DFT, where token weights are ...
arXiv 2026
-
[32]
in general. We fine-tune LLaMA-2-7B [Touvron et al., 2023] on 100k examples from MedMCQA [Pal et al., 2022] for 1 epoch. We evaluate on MedQA [Jin et al., 2021], MMLU-medical [Hendrycks et al., 2020], and the MedMCQA test set. The model is trained for one epoch with a maximum sequence length of 512, a global batch size of 64, and a learning rate of 2×10 −...
arXiv 2023
-
[33]
Overall, PriFT continues to provide strong performance across model families and scales
Due to computational constraints, we include the most representative baseline from the main experiments rather than exhaustively evaluating all token-reweighted methods on every additional backbone. Overall, PriFT continues to provide strong performance across model families and scales. On Qwen2.5-Math-1.5B, PriFT-mass achieves the best average performanc...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.