TabPFN-MT: A Natively Multitask In-Context Learner for Tabular Data
Pith reviewed 2026-05-21 07:36 UTC · model grok-4.3
The pith
TabPFN-MT performs multitask in-context learning on tabular data by training on a multi-target synthetic prior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
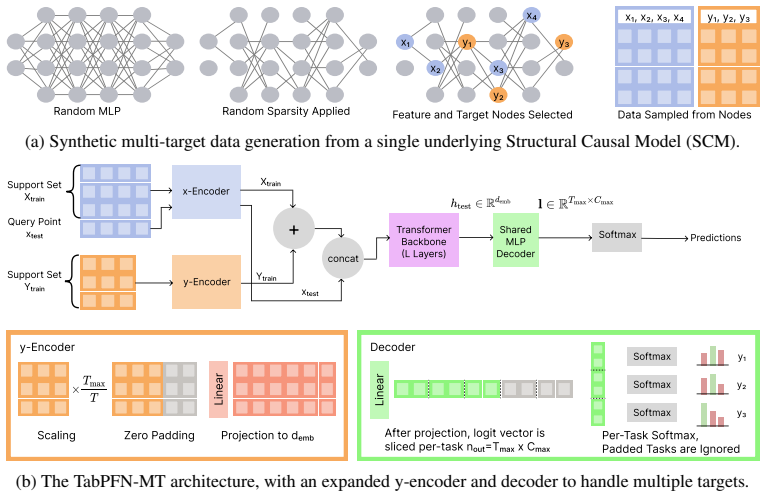
TabPFN-MT is trained on an expanded multi-target synthetic prior to capture inter-task dependencies in context. This model uses an expanded y-encoder and a shared decoder head to enable multitask in-context learning and simultaneous inference. Within this regime of averaging fewer than 1,000 samples, extensive evaluations across 344 datasets demonstrate that TabPFN-MT establishes a new state-of-the-art for deep tabular multitask learning and remains highly competitive with the latest state-of-the-art single-task ensembles while reducing the inference cost for T tasks from O(T) to O(1) forward passes.
What carries the argument
Expanded y-encoder and shared decoder head operating on a multi-target synthetic prior, allowing joint modeling of multiple targets in a single in-context forward pass.
Load-bearing premise
The expanded multi-target synthetic prior successfully captures the inter-task dependencies that exist in real-world tabular data.
What would settle it
Running TabPFN-MT and single-task baselines on a collection of real multitask tabular datasets where task correlations are measured independently, and checking whether the multitask model shows larger gains on high-correlation datasets.
Figures






read the original abstract
Prior-Data Fitted networks (PFNs) have been very successful in tabular contexts, handling prediction tasks in context. However, they are designed for single-task inference, meaning that predicting several target values within a context requires repeated forward calls and precludes inter-task information sharing. We propose TabPFN-MT, which is trained on an expanded multi-target synthetic prior to capture inter-task dependencies in context. This model uses an expanded $y$-encoder and a shared decoder head to enable multitask in-context learning and simultaneous inference. The model is uniquely specialized for small-to-medium datasets by relying on in-context learning rather than traditional gradient-based training. Within this regime (averaging fewer than 1,000 samples), extensive evaluations across 344 datasets demonstrate that TabPFN-MT establishes a new state-of-the-art for deep tabular multitask learning. Furthermore, despite the inherent compute asymmetry of joint optimization, our model remains highly competitive with the latest state-of-the-art single-task ensembles. Notably, on multitask datasets it achieves an overall Accuracy rank of 4.89, the highest average rank among all models tested. Crucially, TabPFN-MT delivers this highly competitive performance while reducing the inference cost for $T$ tasks from $O(T)$ to $O(1)$ forward passes, offering a massive computational efficiency improvement for multi-target tabular applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TabPFN-MT as a multitask extension of Prior-Data Fitted Networks (PFNs) for tabular data. It trains the model on an expanded multi-target synthetic prior, using an expanded y-encoder and shared decoder head to support native in-context multitask learning and simultaneous inference across targets in O(1) forward passes rather than O(T). Evaluations across 344 small-to-medium datasets (average <1000 samples) claim a new state-of-the-art for deep tabular multitask learning, with an overall accuracy rank of 4.89 on the multitask subset, while remaining competitive with single-task ensembles despite the compute asymmetry of joint optimization.
Significance. If the results hold under rigorous verification, the work would offer a meaningful contribution to efficient multitask tabular modeling in low-data regimes by eliminating per-task gradient training and reducing inference cost. The in-context approach and claimed ability to exploit inter-task structure could be practically useful for multi-target applications, provided the performance gains are shown to arise from the multitask prior rather than architecture alone.
major comments (2)
- [Abstract] Abstract: The headline claim that TabPFN-MT 'establishes a new state-of-the-art for deep tabular multitask learning' and achieves rank 4.89 rests on the untested assumption that the expanded multi-target synthetic prior successfully induces the model to exploit real inter-task dependencies. No diagnostic is reported (e.g., comparison of synthetic vs. empirical target correlations, label co-occurrence statistics, or conditional distributions on the 344 evaluation collections), so it remains possible that observed gains derive entirely from the architectural changes (expanded y-encoder + shared decoder head) rather than from prior-data fitting of multitask structure.
- [Abstract] Abstract and evaluation description: The reported SOTA results and rank of 4.89 supply no information on baseline implementations, statistical testing, dataset selection criteria, or error bars. Without these details the reliability of the cross-model comparison cannot be assessed and the central empirical claim cannot be verified.
minor comments (1)
- [Method] Provide a clear, self-contained definition of the multi-target synthetic prior (including how targets are jointly sampled) and contrast it explicitly with the single-task prior from prior TabPFN work.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and describe the revisions we intend to incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that TabPFN-MT 'establishes a new state-of-the-art for deep tabular multitask learning' and achieves rank 4.89 rests on the untested assumption that the expanded multi-target synthetic prior successfully induces the model to exploit real inter-task dependencies. No diagnostic is reported (e.g., comparison of synthetic vs. empirical target correlations, label co-occurrence statistics, or conditional distributions on the 344 evaluation collections), so it remains possible that observed gains derive entirely from the architectural changes (expanded y-encoder + shared decoder head) rather than from prior-data fitting of multitask structure.
Authors: We agree that direct diagnostics would strengthen the claim that performance gains arise from the multitask prior rather than architecture alone. The synthetic prior is explicitly constructed with correlated multi-target samples to induce inter-task structure, and the observed improvements on multitask datasets are consistent with this design. To address the concern rigorously, we will add an appendix containing (i) a comparison of pairwise target correlations between the synthetic prior and the 344 evaluation collections and (ii) an ablation isolating the multitask prior from the expanded y-encoder and shared decoder. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: The reported SOTA results and rank of 4.89 supply no information on baseline implementations, statistical testing, dataset selection criteria, or error bars. Without these details the reliability of the cross-model comparison cannot be assessed and the central empirical claim cannot be verified.
Authors: All requested details are already present in the manuscript: baseline implementations and hyper-parameters are described in Section 4.1, dataset selection criteria (small-to-medium tabular datasets with average size <1000 samples) appear in Section 4.2, and statistical testing with error bars and rank aggregation are reported in Section 4.3 and the supplementary material. The rank 4.89 is the mean rank over the multitask subset. For improved accessibility we will add a concise summary of the evaluation protocol and a pointer to these sections directly in the abstract. revision: partial
Circularity Check
No circularity: results are direct empirical measurements on held-out data
full rationale
The paper's central claims consist of measured performance ranks (e.g., Accuracy rank of 4.89) and efficiency gains obtained by running the trained model on 344 external tabular datasets. These quantities are not algebraically reduced to any fitted parameter, synthetic prior statistic, or self-referential definition inside the training loop. The multi-target synthetic prior is an input to training; the reported SOTA numbers are outputs of separate evaluation and do not collapse back to that prior by construction. No equations, uniqueness theorems, or self-citations are invoked to force the headline result. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Training on an expanded multi-target synthetic prior captures inter-task dependencies present in real tabular data
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose TabPFN-MT, which is trained on an expanded multi-target synthetic prior to capture inter-task dependencies in context. This model uses an expanded y-encoder and a shared decoder head to enable multitask in-context learning and simultaneous inference.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Datasets are generated by sampling a random directed acyclic graph (DAG) representing an SCM, propagating noise variables through non-linear deterministic functions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Accurate predictions on small data with a tab- ular foundation model.Nature, 637(8045):319–326, 2025
Hollmann, Noah and Müller, Samuel and Purucker, Lennart and Krishnakumar, Arjun and Körfer, Max and Hoo, Shi Bin and Schirrmeister, Robin Tibor and Hutter, Frank , month = jan, year =. Accurate predictions on small data with a tabular foundation model , volume =. Nature , publisher =. doi:10.1038/s41586-024-08328-6 , abstract =
-
[2]
Hollmann, Noah and Müller, Samuel and Eggensperger, Katharina and Hutter, Frank , year =. The
-
[3]
Chen, Tianqi and Guestrin, Carlos , year =. Proceedings of the 22nd. doi:10.1145/2939672.2939785 , abstract =
-
[4]
Gorishniy, Yury and Rubachev, Ivan and Khrulkov, Valentin and Babenko, Artem , year =. Revisiting. Advances in
-
[5]
Somepalli, Gowthami and Goldblum, Micah and Schwarzschild, Avi and Bruss, C. Bayan and Goldstein, Tom , month = jun, year =. doi:10.48550/arXiv.2106.01342 , abstract =
-
[6]
Prokhorenkova, Liudmila and Gusev, Gleb and Vorobev, Aleksandr and Dorogush, Anna Veronika and Gulin, Andrey , year =. Advances in
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , author =. 2024 , note =. doi:10.1609/aaai.v38i8.28749 , abstract =
-
[8]
Ma, Jiaqi and Zhao, Zhe and Yi, Xinyang and Chen, Jilin and Hong, Lichan and Chi, Ed H. , year =. Modeling. Proceedings of the 24th. doi:10.1145/3219819.3220007 , abstract =
-
[9]
Tang, Hongyan and Liu, Junning and Zhao, Ming and Gong, Xudong , year =. Progressive. Proceedings of the 14th. doi:10.1145/3383313.3412236 , abstract =
-
[10]
Müller, Samuel and Hollmann, Noah and Arango, Sebastian Pineda and Grabocka, Josif and Hutter, Frank , year =. Transformers. International
-
[11]
Feuer, Benjamin and Schirrmeister, Robin Tibor and Cherepanova, Valeriia and Hegde, Chinmay and Hutter, Frank and Goldblum, Micah and Cohen, Niv and White, Colin , editor =. Advances in. 2024 , pages =
work page 2024
-
[12]
Ye, Han-Jia and Liu, Si-Yang and Chao, Wei-Lun , month = feb, year =. A. doi:10.48550/arXiv.2502.17361 , abstract =
-
[13]
doi:10.48550/arXiv.2502.06684 , abstract =
Arbel, Michael and Salinas, David and Hutter, Frank , month = feb, year =. doi:10.48550/arXiv.2502.06684 , abstract =
-
[14]
Rundel, David and Kobialka, Julius and von Crailsheim, Constantin and Feurer, Matthias and Nagler, Thomas and Rügamer, David , editor =. Interpretable. Explainable. 2024 , keywords =. doi:10.1007/978-3-031-63797-1_23 , abstract =
-
[15]
Tokenize features, enhancing tables: the
Liu, Quangao and Yang, Wei and Liang, Chen and Pang, Longlong and Zou, Zhuozhang , month = jun, year =. Tokenize features, enhancing tables: the. doi:10.48550/arXiv.2406.06891 , abstract =
-
[16]
Rubachev, Ivan and Kartashev, Nikolay and Gorishniy, Yury and Babenko, Artem , month = oct, year =. International
-
[17]
Helli, Kai and Schnurr, David and Hollmann, Noah and Müller, Samuel and Hutter, Frank , month = nov, year =. Drift-. Advances in
-
[18]
Ke, Guolin and Meng, Qi and Finley, Thomas and Wang, Taifeng and Chen, Wei and Ma, Weidong and Ye, Qiwei and Liu, Tie-Yan , year =. Advances in
-
[19]
Why do tree-based models still outperform deep learning on typical tabular data? , url =
Grinsztajn, Leo and Oyallon, Edouard and Varoquaux, Gael , month = jun, year =. Why do tree-based models still outperform deep learning on typical tabular data? , url =. Thirty-sixth
-
[20]
Xiong, Zheyang and Cai, Ziyang and Cooper, John and Ge, Albert and Papageorgiou, Vasilis and Sifakis, Zack and Giannou, Angeliki and Lin, Ziqian and Yang, Liu and Agarwal, Saurabh and Chrysos, Grigorios and Oymak, Samet and Lee, Kangwook and Papailiopoulos, Dimitris , month = jun, year =. Everything. Forty-second
-
[21]
When do neural nets outperform boosted trees on tabular data? , abstract =
McElfresh, Duncan and Khandagale, Sujay and Valverde, Jonathan and C., Vishak Prasad and Ramakrishnan, Ganesh and Goldblum, Micah and White, Colin , month = dec, year =. When do neural nets outperform boosted trees on tabular data? , abstract =. Proceedings of the 37th
-
[22]
Zeng, Yuchen and Dinh, Tuan and Kang, Wonjun and Mueller, Andreas C. , month = jun, year =. Forty-second
-
[23]
TabNet: Attentive Interpretable Tabular Learning.,
Proceedings of the AAAI Conference on Artificial Intelligence , author =. 2021 , pages =. doi:10.1609/aaai.v35i8.16826 , number =
-
[24]
and Golestan, Keyvan and Yu, Guangwei and Caterini, Anthony L
Ma, Junwei and Thomas, Valentin and Hosseinzadeh, Rasa and Labach, Alex and Cresswell, Jesse C. and Golestan, Keyvan and Yu, Guangwei and Caterini, Anthony L. and Volkovs, Maksims , month = oct, year =. The
-
[25]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J. , month = sep, year =. Exploring the. doi:10.48550/arXiv.1910.10683 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1910.10683 1910
-
[26]
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[27]
Proceedings of the AAAI Conference on Artificial Intelligence , author =. 2024 , keywords =. doi:10.1609/aaai.v38i10.28988 , abstract =
-
[28]
The Twelfth International Conference on Learning Representations , url =
Gorishniy, Yury and Rubachev, Ivan and Kartashev, Nikolay and Shlenskii, Daniil and Kotelnikov, Akim and Babenko, Artem , month = oct, year =. The Twelfth International Conference on Learning Representations , url =
-
[29]
Holzmüller, David and Grinsztajn, Leo and Steinwart, Ingo , month = nov, year =. Better by default:. The Thirty-eighth Annual Conference on Neural Information Processing Systems , url =
- [30]
-
[31]
John Kim, Parviz Moin, and Robert Moser
Cipolla, Roberto and Gal, Yarin and Kendall, Alex , month = jun, year =. Multi-task. 2018. doi:10.1109/CVPR.2018.00781 , abstract =
-
[32]
Chen, Zhao and Badrinarayanan, Vijay and Lee, Chen-Yu and Rabinovich, Andrew , month = jul, year =. Proceedings of the 35th
- [33]
-
[34]
Sinodinos, Dimitrios and Nikpour, Bahareh and Wei, Jack Yi and Sinha, Sushant and Ma, Xiaoping and Rehman, Kashif and Yue, Stephen and Armanfard, Narges , month = mar, year =. Multitask-. doi:10.48550/arXiv.2603.22738 , abstract =
- [35]
-
[36]
Li, Pengcheng and Li, Runze and Da, Qing and Zeng, An-Xiang and Zhang, Lijun , month = oct, year =. Improving. Proceedings of the 29th. doi:10.1145/3340531.3412713 , abstract =
-
[37]
Xi, Dongbo and Chen, Zhen and Yan, Peng and Zhang, Yinger and Zhu, Yongchun and Zhuang, Fuzhen and Chen, Yu , month = aug, year =. Modeling the. Proceedings of the 27th. doi:10.1145/3447548.3467071 , abstract =
-
[38]
Deep Learning , author=
-
[39]
TabTransformer: Tabular Data Modeling Using Contextual Embeddings
Huang, Xin and Khetan, Ashish and Cvitkovic, Milan and Karnin, Zohar , month = dec, year =. doi:10.48550/arXiv.2012.06678 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2012.06678 2012
-
[40]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Grinsztajn, Léo and Flöge, Klemens and Key, Oscar and Birkel, Felix and Jund, Philipp and Roof, Brendan and Jäger, Benjamin and Safaric, Dominik and Alessi, Simone and Hayler, Adrian and Manium, Mihir and Yu, Rosen and Jablonski, Felix and Hoo, Shi Bin and Garg, Anurag and Robertson, Jake and Bühler, Magnus and Moroshan, Vladyslav and Purucker, Lennart an...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.08667
-
[41]
Gadetsky, Artyom and Atanov, Andrei and Jiang, Yulun and Gao, Zhitong and Mighan, Ghazal Hosseini and Zamir, Amir and Brbic, Maria , month = apr, year =. Large (. doi:10.48550/arXiv.2504.02349 , abstract =
-
[42]
Machine Learning 45(1), 5–32 (Oct 2001)
Random. Machine Learning , author =. 2001 , keywords =. doi:10.1023/A:1010933404324 , abstract =
-
[43]
A. Machine Learning , author =. 2001 , keywords =. doi:10.1023/A:1010920819831 , abstract =
-
[44]
Statistical. J. Mach. Learn. Res. , author =. 2006 , pages =
work page 2006
-
[45]
2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Attentive Single-Tasking of Multiple Tasks , author=. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
work page 2019
-
[46]
Tabular data:. Information Fusion , author =. 2022 , keywords =. doi:10.1016/j.inffus.2021.11.011 , abstract =
-
[47]
Sinodinos, Dimitrios and Wei, Jack Yi and Armanfard, Narges , year =. Proceedings of the
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.