LargeMonitor: Monitoring Online Task-Free Continual Learning via Large Pretrained Models
Pith reviewed 2026-06-27 17:07 UTC · model grok-4.3
The pith
Large pretrained models enable zero-shot drift detection and semantic diagnosis in task-free continual learning streams.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
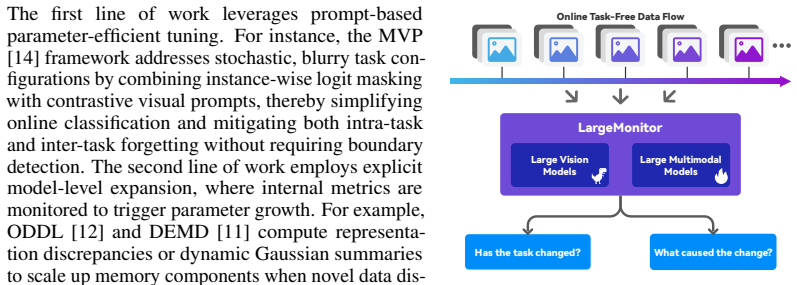
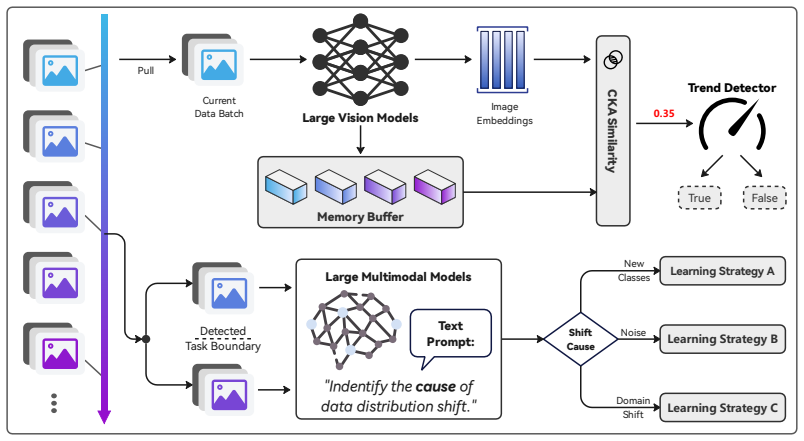
LargeMonitor introduces a decoupled detection module utilizing the frozen, stable representation space of large vision models to achieve robust, zero-shot drift detection without training-dependent interference or brittle threshold tuning. Upon a confirmed drift, the framework activates a context-aware diagnostic module driven by large multimodal models to interpret the precise semantic etiologies of the stream variation, such as novel class emergence versus environmental domain shift. This dual-stage capability empowers the continuous learner to dynamically deploy adaptive and shift-specific optimization strategies.
What carries the argument
Decoupled two-stage monitoring that uses frozen large vision model representations for drift detection and large multimodal models for semantic diagnosis of the shift cause.
If this is right
- Existing online TFCL algorithms receive consistent performance gains when the monitoring framework is added.
- Shift-specific optimization strategies can replace a single fixed adaptation rule.
- Drift detection operates independently of the learner's training dynamics.
- Precise diagnosis distinguishes novel class emergence from domain shift in complex data streams.
Where Pith is reading between the lines
- The same frozen-detector plus diagnostic structure could be tested on non-vision modalities if suitable large models are available.
- Semantic labels from the diagnostic stage might support more interpretable explanations of why a continual learner's accuracy changes over time.
- Because detection requires no task-specific training, the monitor could be swapped across different base learners without retraining.
Load-bearing premise
The frozen representation space of large vision models remains stable and sufficient for zero-shot drift detection across fundamentally distinct streaming variations without requiring any training-dependent interference or brittle threshold tuning.
What would settle it
A controlled streaming experiment in which the large vision model embeddings produce indistinguishable similarity scores for a novel-class introduction and an environmental domain shift.
Figures
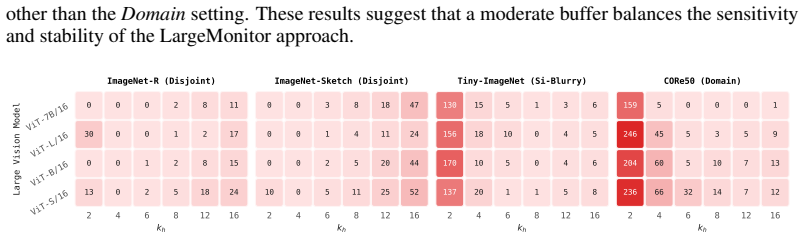
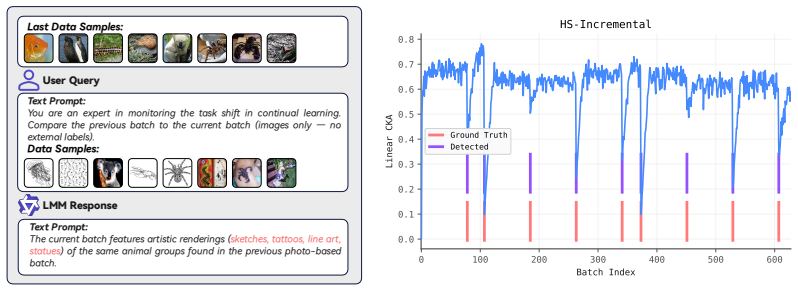
read the original abstract
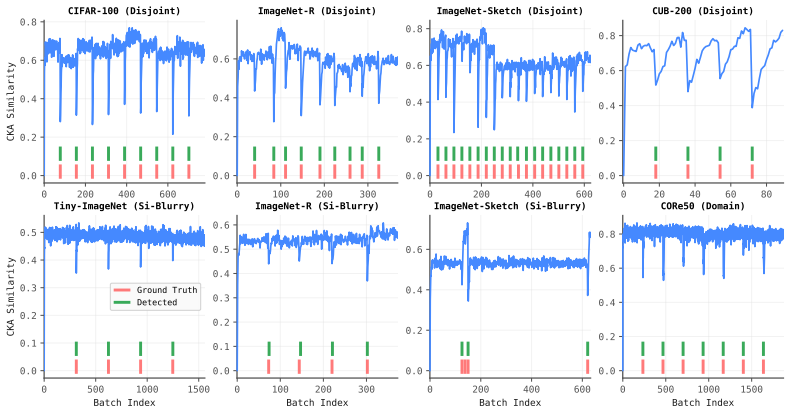
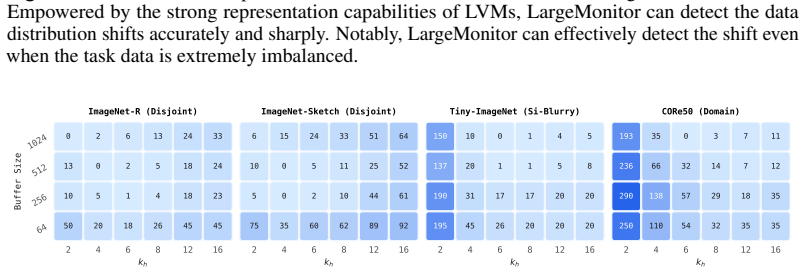
Online task-free continual learning (TFCL) requires intelligent agents to sequentially accumulate knowledge from an unbounded, non-stationary data stream under strict single-pass constraints and without any explicit task identifiers. Existing online TFCL paradigms primarily rely on parameter-efficient prompt tuning or dynamic structure expansion driven by training-coupled optimization dynamics, such as empirical loss fluctuations or evolving latent distances. As a result, these training-coupled solvers remain agnostic to the structural origins of distribution drift, mechanically enforcing a fixed strategy across fundamentally distinct streaming variations. To address this gap, we propose LargeMonitor, a framework that leverages large pretrained foundation models to autonomously orchestrate task-free continuous adaptation. Specifically, LargeMonitor introduces a decoupled detection module utilizing the frozen, stable representation space of large vision models (LVMs) to achieve robust, zero-shot drift detection without training-dependent interference or brittle threshold tuning. Upon a confirmed drift, the framework activates a context-aware diagnostic module driven by large multimodal models (LMMs) to interpret the precise semantic etiologies of the stream variation (e.g., novel class emergence vs. environmental domain shift). This dual-stage capability empowers the continuous learner to dynamically deploy adaptive and shift-specific optimization strategies. Extensive experiments across multiple TFCL settings and benchmarks demonstrate that LargeMonitor achieves precise, robust detection and diagnosis of complex data streams while consistently improving the performance of existing online TFCL algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LargeMonitor, a framework for online task-free continual learning that decouples drift detection from the learner by using the frozen representation space of large vision models for zero-shot detection of distribution shifts, followed by large multimodal models to diagnose the semantic cause of the shift (e.g., novel class vs. domain change), thereby enabling shift-specific adaptation strategies that improve the performance of existing TFCL methods.
Significance. If the central claims on robust zero-shot detection hold, the work could be significant for continual learning by demonstrating that pretrained foundation models can provide training-decoupled monitoring that distinguishes structural origins of drift and supports adaptive optimization, moving beyond loss- or distance-driven heuristics.
major comments (2)
- [Abstract / §3] The detection module (described in the abstract and presumably §3): the claim of robust, parameter-free zero-shot drift detection without brittle threshold tuning is load-bearing for the performance gains, yet the manuscript provides no explicit metric, decision rule, or reference-set construction; without these details it is impossible to verify whether the procedure is truly free of implicit parameters or normalization choices that would undermine the decoupling advantage.
- [§4 / Tables] Experimental section (presumably §4 and tables): the headline claim of 'consistently improving the performance of existing online TFCL algorithms' requires ablations that isolate the contribution of the detection/diagnosis modules versus the base learner; absent such controls, it remains unclear whether gains stem from the proposed monitoring or from other implementation choices.
minor comments (1)
- Notation for the drift types and diagnostic outputs should be formalized with explicit definitions to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / §3] The detection module (described in the abstract and presumably §3): the claim of robust, parameter-free zero-shot drift detection without brittle threshold tuning is load-bearing for the performance gains, yet the manuscript provides no explicit metric, decision rule, or reference-set construction; without these details it is impossible to verify whether the procedure is truly free of implicit parameters or normalization choices that would undermine the decoupling advantage.
Authors: We agree that explicit details on the detection module are necessary to support the claims of robust, parameter-free zero-shot detection. The manuscript currently provides only a high-level description of using frozen LVM representations. In the revision we will expand §3 with the precise metric, decision rule, and reference-set construction to allow verification that no brittle thresholds or implicit normalizations are involved. revision: yes
-
Referee: [§4 / Tables] Experimental section (presumably §4 and tables): the headline claim of 'consistently improving the performance of existing online TFCL algorithms' requires ablations that isolate the contribution of the detection/diagnosis modules versus the base learner; absent such controls, it remains unclear whether gains stem from the proposed monitoring or from other implementation choices.
Authors: We acknowledge that dedicated ablations are required to isolate the contribution of the detection and diagnosis modules. The current experiments report overall performance gains when LargeMonitor is integrated with existing TFCL methods but do not include controls that separate the monitoring components from the base learner. We will add these ablations to the revised experimental section. revision: yes
Circularity Check
No circularity: framework claims rest on empirical decoupling, not self-defined derivations or fits
full rationale
The provided abstract and description contain no equations, parameter fits, predictions of derived quantities, or load-bearing self-citations. The core proposal is a decoupled detection/diagnosis module using frozen LVM/LMM representations for zero-shot drift handling; this is presented as an architectural choice whose performance is validated externally on benchmarks rather than reduced to its own inputs by construction. No self-definitional loops, fitted-input predictions, or ansatz smuggling appear. The reader's circularity score of 2.0 aligns with this assessment.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5362–5383, 2024
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5362–5383, 2024
2024
-
[2]
Learning without forgetting.IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(12):2935–2947, 2017
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(12):2935–2947, 2017
2017
-
[3]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017
2001
-
[4]
Human-guided continual learning for personalized decision-making of autonomous driving.IEEE Transactions on Intelligent Transportation Systems, 26(4):5435–5447, 2025
Haohan Yang, Yanxin Zhou, Jingda Wu, Haochen Liu, Lie Yang, and Chen Lv. Human-guided continual learning for personalized decision-making of autonomous driving.IEEE Transactions on Intelligent Transportation Systems, 26(4):5435–5447, 2025
2025
-
[5]
Jiarun Zhu, Yijun Hong, Xiaoquan Sun, Zetian Xu, Mingqi Yuan, Zhiyong Wang, Wenjun Zeng, and Jiayu Chen. Can vla models learn from real-world data continually without forgetting? arXiv preprint arXiv:2605.26820, 2026
Pith/arXiv arXiv 2026
-
[6]
Interactive continual learning architecture for long-term personalization of home service robots
Ali Ayub, Chrystopher L Nehaniv, and Kerstin Dautenhahn. Interactive continual learning architecture for long-term personalization of home service robots. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 11289–11296. IEEE, 2024
2024
-
[7]
Continual prototype evolution: Learning online from non-stationary data streams
Matthias De Lange and Tinne Tuytelaars. Continual prototype evolution: Learning online from non-stationary data streams. InProceedings of the IEEE/CVF international conference on computer vision, pages 8250–8259, 2021
2021
-
[8]
Remind your neural network to prevent catastrophic forgetting
Tyler L Hayes, Kushal Kafle, Robik Shrestha, Manoj Acharya, and Christopher Kanan. Remind your neural network to prevent catastrophic forgetting. InEuropean conference on computer vision, pages 466–483. Springer, 2020
2020
-
[9]
A neural dirichlet process mixture model for task-free continual learning
Soochan Lee, Junsoo Ha, Dongsu Zhang, and Gunhee Kim. A neural dirichlet process mixture model for task-free continual learning. InInternational Conference on Learning Representations, 2020
2020
-
[10]
Online task-free continual generative and discriminative learning via dynamic cluster memory
Fei Ye and Adrian G Bors. Online task-free continual generative and discriminative learning via dynamic cluster memory. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26202–26212, 2024
2024
-
[11]
Online task-free continual learning via dynamic expansionable mem- ory distribution
Fei Ye and Adrian G Bors. Online task-free continual learning via dynamic expansionable mem- ory distribution. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 20512–20522, 2025. 10
2025
-
[12]
Online task-free continual learning via discrepancy mechanism
Fei Ye and Adrian G Bors. Online task-free continual learning via discrepancy mechanism. Knowledge-Based Systems, 322:113688, 2025
2025
-
[13]
Online-lora: Task-free online continual learning via low rank adaptation
Xiwen Wei, Guihong Li, and Radu Marculescu. Online-lora: Task-free online continual learning via low rank adaptation. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 6634–6645. IEEE, 2025
2025
-
[14]
Online class incremental learning on stochastic blurry task boundary via mask and visual prompt tuning
Jun-Yeong Moon, Keon-Hee Park, Jung Uk Kim, and Gyeong-Moon Park. Online class incremental learning on stochastic blurry task boundary via mask and visual prompt tuning. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11731–11741, 2023
2023
-
[15]
Reconciling meta-learning and continual learning with online mixtures of tasks.Advances in neural information processing systems, 32, 2019
Ghassen Jerfel, Erin Grant, Tom Griffiths, and Katherine A Heller. Reconciling meta-learning and continual learning with online mixtures of tasks.Advances in neural information processing systems, 32, 2019
2019
-
[16]
Varigrow: Variational architecture growing for task-agnostic continual learning based on bayesian novelty
Randy Ardywibowo, Zepeng Huo, Zhangyang Wang, Bobak J Mortazavi, Shuai Huang, and Xiaoning Qian. Varigrow: Variational architecture growing for task-agnostic continual learning based on bayesian novelty. InInternational Conference on Machine Learning, pages 865–877. PMLR, 2022
2022
-
[17]
Large-scale multi-modal pre-trained models: A comprehensive survey.Machine Intelligence Research, 20(4):447–482, 2023
Xiao Wang, Guangyao Chen, Guangwu Qian, Pengcheng Gao, Xiao-Yong Wei, Yaowei Wang, Yonghong Tian, and Wen Gao. Large-scale multi-modal pre-trained models: A comprehensive survey.Machine Intelligence Research, 20(4):447–482, 2023
2023
-
[18]
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, et al. Sora: A review on background, technology, limitations, and opportunities of large vision models.arXiv preprint arXiv:2402.17177, 2024
Pith/arXiv arXiv 2024
-
[19]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[20]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[21]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
2021
-
[22]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
Pith/arXiv arXiv 2025
-
[23]
Task-free continual learning
Rahaf Aljundi, Klaas Kelchtermans, and Tinne Tuytelaars. Task-free continual learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11254–11263, 2019
2019
-
[24]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational conference on machine learning, pages 3519–3529. PMlR, 2019
2019
-
[25]
Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[26]
Learning multiple layers of features from tiny images
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical report, University of Toronto, Toronto, ON, Canada, 2009
2009
-
[27]
Tiny imagenet visual recognition challenge.CS 231N, 7(7):3, 2015
Yann Le, Xuan Yang, et al. Tiny imagenet visual recognition challenge.CS 231N, 7(7):3, 2015. 11
2015
-
[28]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. InProceedings of the IEEE/CVF international conference on computer vision, pages 8340–8349, 2021
2021
-
[29]
Learning robust global repre- sentations by penalizing local predictive power.Advances in neural information processing systems, 32, 2019
Haohan Wang, Songwei Ge, Zachary Lipton, and Eric P Xing. Learning robust global repre- sentations by penalizing local predictive power.Advances in neural information processing systems, 32, 2019
2019
-
[30]
Caltech-ucsd birds 200
Peter Welinder, Steve Branson, Takeshi Mita, Catherine Wah, Florian Schroff, Serge Belongie, and Pietro Perona. Caltech-ucsd birds 200. Technical report, California Institute of Technology, Pasadena, CA, USA, 2010
2010
-
[31]
Core50: a new dataset and benchmark for continuous object recognition
Vincenzo Lomonaco and Davide Maltoni. Core50: a new dataset and benchmark for continuous object recognition. InConference on Robot Learning, pages 17–26. PMLR, 2017
2017
-
[32]
Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Pith/arXiv arXiv 2023
-
[33]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
Pith/arXiv arXiv 2023
-
[34]
Learning to prompt for continual learning
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, and Tomas Pfister. Learning to prompt for continual learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 139–149, 2022
2022
-
[35]
Expe- rience replay for continual learning.Advances in neural information processing systems, 32, 2019
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy Lillicrap, and Gregory Wayne. Expe- rience replay for continual learning.Advances in neural information processing systems, 32, 2019
2019
-
[36]
Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526, 2017
2017
-
[37]
Rainbow memory: Continual learning with a memory of diverse samples
Jihwan Bang, Heesu Kim, YoungJoon Yoo, Jung-Woo Ha, and Jonghyun Choi. Rainbow memory: Continual learning with a memory of diverse samples. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8218–8227, 2021
2021
-
[38]
Online continual learning on class incremental blurry task configuration with anytime inference
Hyunseo Koh, Dahyun Kim, Jung-Woo Ha, and Jonghyun Choi. Online continual learning on class incremental blurry task configuration with anytime inference. InInternational Conference on Learning Representations, 2022. 12
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.