Attention-Discounted Adaptive Sampler for Masked Diffusion Language Models
Pith reviewed 2026-06-27 13:29 UTC · model grok-4.3
The pith
A training-free reranker that discounts attention-coupled predictions improves parallel decoding quality in masked diffusion language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
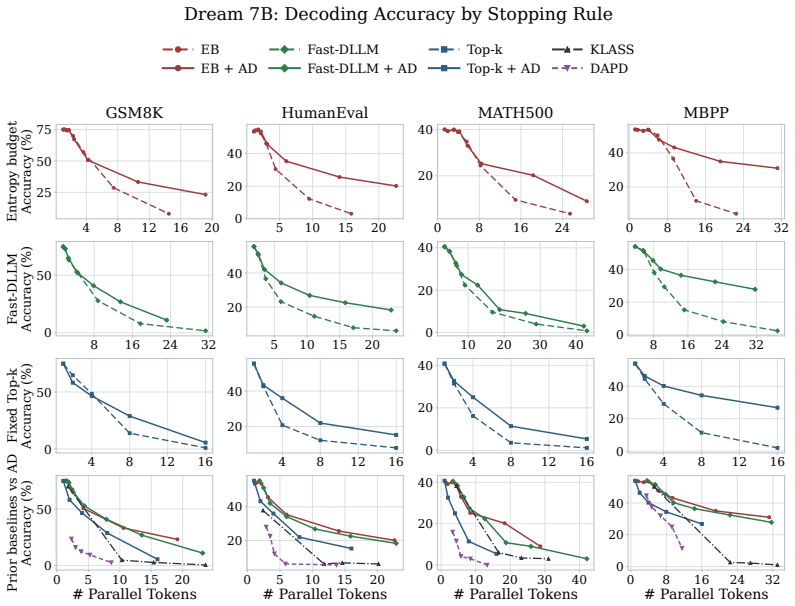
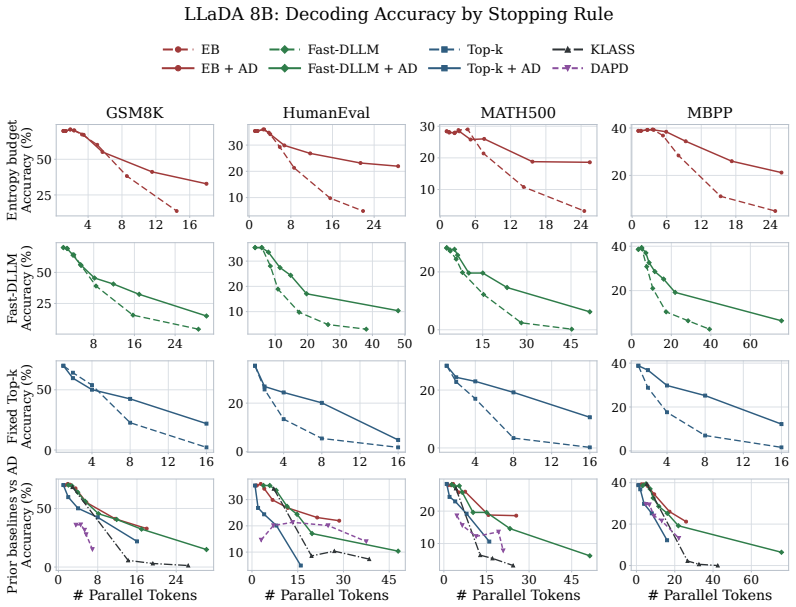
ADAS modifies only the subset construction step in parallel masked diffusion decoding by greedily discounting candidates that attend strongly to already selected positions with uncertain predictions, treating attention as a soft marginal penalty rather than a hard constraint. This yields average improvements of 9.11 and 10.46 percentage points on low-NFE performance for LLaDA-8B-Base and Dream-7B-Base across GSM8K, MATH500, HumanEval, and MBPP when plugged into Top-k, Fast-dLLM, and EB-Sampler.
What carries the argument
ADAS (Attention-Discounted Adaptive Sampler), a greedy reranking rule that applies continuous attention-based discounts to candidates attending to uncertain selected positions, serving as a soft penalty on prediction coupling.
If this is right
- ADAS can be plugged into multiple existing samplers like Top-k, Fast-dLLM, and EB-Sampler without changing their stopping rules.
- Performance gains are observed specifically at low numbers of function evaluations (NFE) on mathematical reasoning and code generation tasks.
- The method adds only 3.1% per-forward runtime overhead while delivering the reported accuracy improvements.
- Soft attention penalties avoid the need for graph-based hard constraints used in other approaches.
Where Pith is reading between the lines
- Attention patterns in the base model may encode task-relevant dependencies that token-wise confidence scores miss, suggesting broader use of internal model signals for sampling decisions.
- The approach could extend to other diffusion-based or autoregressive models where parallel generation risks coupling errors.
- Without task-specific calibration, the discount rule might need adjustment for domains with different attention behaviors, such as long-context or multimodal tasks.
Load-bearing premise
The attention scores produced by the base model already provide a reliable measure of how much one position's prediction depends on another's without needing any extra tuning or validation.
What would settle it
Running the same experiments on a new masked diffusion model or benchmark where ADAS either matches or underperforms the base samplers at low NFE would falsify the claim of consistent improvement.
Figures


read the original abstract
Masked diffusion language models can reduce inference steps by revealing multiple tokens per denoising iteration, but this parallelism is fragile: positions that are individually confident may be unsafe to commit together when their predictions are coupled. Existing training-free samplers such as Top-\(k\), Fast-dLLM, and EB-Sampler mainly control how many tokens to reveal, while often ranking candidates by token-wise scores that ignore interactions within the selected set. We propose ADAS, a training-free reranking rule for parallel masked diffusion decoding. ADAS leaves the base sampler's stopping rule unchanged and modifies only subset construction: it greedily discounts a candidate when it attends strongly to already selected positions whose predictions remain uncertain. Unlike graph-constrained methods that turn attention into hard compatibility constraints, ADAS keeps attention continuous and uses it as a soft marginal penalty. Across LLaDA-8B-Base and Dream-7B-Base on GSM8K, MATH500, HumanEval, and MBPP, plugging ADAS into Top-\(k\), Fast-dLLM, and EB-Sampler improves low-NFE performance at matched denoiser evaluations by \(9.11\) and \(10.46\) percentage points on average, respectively, with \(3.1\%\) per-forward runtime overhead. These results show that soft attention-discounted reranking is a simple and modular way to improve quality in highly parallel decoding for masked diffusion language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ADAS, a training-free reranking rule for parallel masked diffusion decoding in language models. It modifies subset construction by greedily applying a continuous soft penalty based on attention scores to candidates that attend strongly to already-selected uncertain positions, while leaving the base sampler's stopping rule unchanged. The central claim is that integrating ADAS into Top-k, Fast-dLLM, and EB-Sampler yields average gains of 9.11 and 10.46 percentage points on GSM8K, MATH500, HumanEval, and MBPP for LLaDA-8B-Base and Dream-7B-Base at low NFE, with 3.1% per-forward runtime overhead.
Significance. If the empirical results prove robust, this provides a simple modular enhancement to existing training-free samplers for masked diffusion LMs by addressing prediction coupling via soft attention penalties rather than hard constraints. The low overhead and plug-in nature could make it practically useful for efficient parallel inference, and the concrete multi-model, multi-task gains are a strength if they generalize.
major comments (2)
- [Results] Results section: the headline gains of 9.11 and 10.46 percentage points are reported as averages without error bars, variance across runs, or statistical significance tests, which is load-bearing for establishing that the improvements reliably exceed noise in stochastic sampling.
- [§3] §3 (ADAS definition): the method applies raw attention scores directly as a soft marginal penalty with no reported ablation on the discount functional form, scaling, threshold, or cross-task/model validation of the coupling assumption; this is load-bearing because the observed lift depends on the rule being generally reliable rather than benchmark-specific.
minor comments (2)
- [Abstract] Abstract and method: the exact mathematical form of the discount (e.g., how attention is normalized or combined with token scores) is not stated, requiring readers to consult the full equations for reproducibility.
- [Experiments] Table captions or experimental setup: missing details on the precise NFE values used for the 'low-NFE' comparisons and whether denoiser evaluations are exactly matched across conditions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that will strengthen the empirical support.
read point-by-point responses
-
Referee: [Results] Results section: the headline gains of 9.11 and 10.46 percentage points are reported as averages without error bars, variance across runs, or statistical significance tests, which is load-bearing for establishing that the improvements reliably exceed noise in stochastic sampling.
Authors: We agree that reporting variability is essential for stochastic samplers. In the revised manuscript we will rerun all experiments across multiple random seeds, report means with standard deviations, and add paired statistical significance tests to confirm the gains are reliable. revision: yes
-
Referee: [§3] §3 (ADAS definition): the method applies raw attention scores directly as a soft marginal penalty with no reported ablation on the discount functional form, scaling, threshold, or cross-task/model validation of the coupling assumption; this is load-bearing because the observed lift depends on the rule being generally reliable rather than benchmark-specific.
Authors: We acknowledge the value of further validation. We will add an ablation study on the discount functional form, scaling, and thresholds, plus cross-task and cross-model checks of the coupling assumption, to be placed in the appendix or a dedicated subsection. revision: yes
Circularity Check
No circularity; empirical gains on external benchmarks with no self-referential reductions
full rationale
The paper introduces ADAS as a training-free heuristic that applies raw attention scores from the base denoiser as a continuous soft penalty during subset construction for parallel decoding. All reported results consist of measured accuracy lifts on public benchmarks (GSM8K, MATH500, HumanEval, MBPP) when ADAS is plugged into existing samplers, with no equations, fitted parameters, or derivations that reduce the claimed improvements to the method's own inputs by construction. No self-citations are invoked as load-bearing premises, and the discount rule is presented as an ansatz rather than derived from a uniqueness theorem or prior self-work. The evaluation remains externally falsifiable against standard baselines.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
James Martens , title =. CoRR , volume =. 2014 , url =. 1412.1193 , timestamp =
arXiv 2014
-
[2]
Dependency-Aware Parallel Decoding via Attention for Diffusion
Kim, Bumjun and Jeon, Dongjae and Jeon, Moongyu and No, Albert , year =. Dependency-Aware Parallel Decoding via Attention for Diffusion. 2603.12996 , archiveprefix =
-
[3]
2026 , eprint=
Where-to-Unmask: Ground-Truth-Guided Unmasking Order Learning for Masked Diffusion Language Models , author=. 2026 , eprint=
2026
-
[4]
2025 , eprint=
Plan for Speed: Dilated Scheduling for Masked Diffusion Language Models , author=. 2025 , eprint=
2025
-
[5]
2025 , eprint=
Accelerating Diffusion LLMs via Adaptive Parallel Decoding , author=. 2025 , eprint=
2025
-
[6]
2025 , eprint =
Path Planning for Masked Diffusion Model Sampling , author =. 2025 , eprint =
2025
-
[7]
2024 , eprint=
Simple and Effective Masked Diffusion Language Models , author=. 2024 , eprint=
2024
-
[8]
2025 , eprint=
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding , author=. 2025 , eprint=
2025
-
[9]
2025 , eprint=
Accelerated Sampling from Masked Diffusion Models via Entropy Bounded Unmasking , author=. 2025 , eprint=
2025
-
[10]
2026 , eprint=
KLASS: KL-Guided Fast Inference in Masked Diffusion Models , author=. 2026 , eprint=
2026
-
[11]
2025 , eprint =
Learning to Parallel: Accelerating Diffusion Large Language Models via Learnable Parallel Decoding , author =. 2025 , eprint =
2025
-
[12]
2025 , eprint=
Lookahead Unmasking Elicits Accurate Decoding in Diffusion Language Models , author=. 2025 , eprint=
2025
-
[13]
2025 , eprint =
Improving Discrete Diffusion Unmasking Policies Beyond Explicit Reference Policies , author =. 2025 , eprint =
2025
-
[14]
2025 , eprint =
Learning Unmasking Policies for Diffusion Language Models , author =. 2025 , eprint =
2025
-
[15]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[16]
2021 , eprint=
Program Synthesis with Large Language Models , author=. 2021 , eprint=
2021
-
[17]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[18]
2021 , eprint=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. 2021 , eprint=
2021
-
[19]
2025 , eprint=
Dream 7B: Diffusion Large Language Models , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint=
Large Language Diffusion Models , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.