TypedCSIP: Typed Counterfactual Pretraining for Chinese Legislative Conflict Classification
Pith reviewed 2026-06-29 22:04 UTC · model grok-4.3
The pith
TypedCSIP pretrains on expert revisions of law pairs to improve conflict-type classification by 0.9-1.3 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
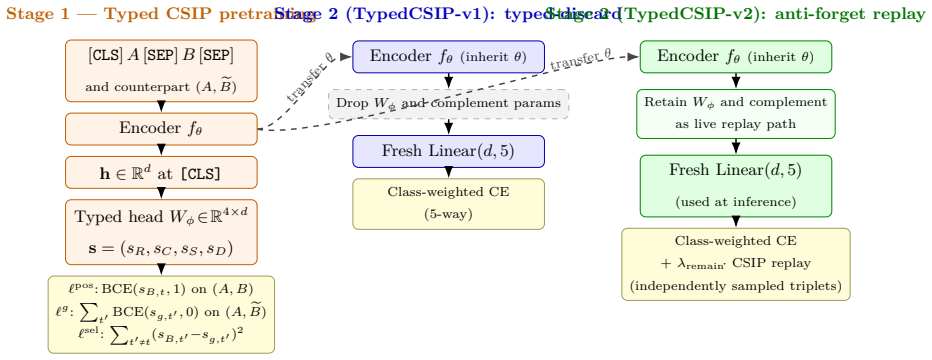
TypedCSIP pretrains a shared encoder with a typed Counterfactual Selective Intervention Pretraining objective on (superior, subordinate, expert-revised) triplets, requiring the typed factor head to classify the expert revision as carrying no conflict evidence; the encoder is then transferred to a five-way classification head that reads only the original pair at test time.
What carries the argument
The typed Counterfactual Selective Intervention Pretraining objective that treats expert minimal revisions as clean no-conflict counterfactuals for doctrine-type classification.
If this is right
- The pretraining signal raises macro-F1 on unmodified test pairs by at least 0.9 pp on chinese-roberta-wwm-ext and 1.3 pp on SAILER.
- Gains remain positive on the 244 Unseen-gB records.
- The Stage-2 encoder specializes for conflict classification and does not improve superior-law retrieval.
- Both cells pass the locked statistical rule requiring mean difference at least 0.8 pp with both seed-bootstrap and Student-t bounds above zero.
Where Pith is reading between the lines
- The same revision-based signal might be tested on other legal corpora where minimal expert edits are available.
- If the revisions are not fully minimal or doctrine-neutral, the pretraining objective could introduce label noise.
- A direct comparison of typed versus untyped counterfactual heads would isolate the contribution of the doctrine-type supervision.
Load-bearing premise
Expert-written minimal revisions can be treated as clean counterfactuals that carry no conflict evidence and that this signal transfers to improve classification on unmodified pairs.
What would settle it
A mean per-seed macro-F1 difference below 0.8 pp or a 95% lower bound below zero on either backbone, under the pre-registered 18-seed protocol, would falsify the performance claim.
Figures
read the original abstract
TypedCSIP is a typed counterfactual pretraining method for the conflict-classification task of the LCR-CN benchmark (Zhao et al., 2026): given a (superior, subordinate) provision pair, predict whether the pair conflicts and which of four legal-doctrine types (Responsibility, Condition, Sanction, Definition) describes the inconsistency. We exploit LCR-CN's expert-written minimal revisions as training-time counterfactual supervision; at test time the classifier reads only the original pair. Stage 1 pretrains a shared encoder with a typed Counterfactual Selective Intervention Pretraining objective on (superior, subordinate, expert-revised) triplets, treating the expert revision as a counterfactual that the typed factor head must classify as carrying no conflict evidence. Stage 2 transfers the encoder to a five-way classification head. The confirmatory test was registered on the Open Science Framework before observing v6 measurements: 18 seeds, locked rule requiring mean per-seed difference at least 0.8 pp with both seed-bootstrap and Student-t 95% lower bounds above zero. On the 696-record test split, the v2 variant improves macro-F1 over the strongest single-model baseline by +0.916 pp on chinese-roberta-wwm-ext and +1.288 pp on the SAILER cross-backbone replication; both cells pass the rule. A cold-start stratified result on the 244 Unseen-gB records keeps the gain positive on both backbones. A cross-task diagnostic shows the Stage-2 encoder is classification-specialized and does not transfer to LCR-CN's superior-law retrieval task, so we scope the contribution to conflict classification. We release code, 72 pre-registered prediction files, matched-seed and MLM-control auxiliaries, and the OSF pre-registration record.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. TypedCSIP is a two-stage typed counterfactual pretraining method for the conflict-classification task on the LCR-CN benchmark. Stage 1 pretrains a shared encoder on (superior, subordinate, expert-revised) triplets using a typed Counterfactual Selective Intervention Pretraining objective that treats expert revisions as no-conflict counterfactuals; Stage 2 transfers the encoder to a five-way classification head. On the 696-record test split the v2 variant reports macro-F1 gains of +0.916 pp (chinese-roberta-wwm-ext) and +1.288 pp (SAILER replication) that pass a pre-registered rule (mean per-seed difference ≥0.8 pp with both seed-bootstrap and Student-t 95% lower bounds >0); gains remain positive on the 244-record Unseen-gB cold-start subset. A cross-task diagnostic shows the encoder is specialized to conflict classification and does not improve superior-law retrieval.
Significance. If the result holds, the work supplies a scoped, statistically controlled improvement to legislative conflict classification that exploits expert counterfactuals without claiming cross-task transfer. Strengths include the locked pre-registration, multi-seed protocol with explicit thresholds, replication across two backbones, cold-start evaluation, matched-seed MLM controls, and public release of code plus 72 pre-registered prediction files; these elements provide independent support for the narrow claim.
minor comments (3)
- Abstract: references to the 'v2 variant' and 'v6 measurements' are undefined; a short methods paragraph or footnote should state what these versions denote and how they differ from the registered protocol.
- The typed factor head and its loss formulation are described at a high level; adding a short pseudocode block or diagram in §3 would improve reproducibility without lengthening the paper.
- Table or figure captions for the main results should explicitly restate the pre-registered decision rule and the two backbone identifiers for quick reference.
Simulated Author's Rebuttal
We thank the referee for the detailed summary of our work, the positive assessment of its significance, and the recommendation for minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper's central claim is an empirical macro-F1 improvement on a locked 696-record test split, obtained by pretraining on expert minimal revisions from the external LCR-CN benchmark and transferring to a classification head. No equation or derivation reduces the reported gain to a quantity defined by parameters fitted on the test data itself. The method relies on an externally annotated benchmark and pre-registered statistical thresholds rather than self-definitional or self-citation load-bearing steps. Matched-seed MLM controls and cross-task diagnostics provide independent support outside the fitted values.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert-written minimal revisions act as counterfactuals that carry no conflict evidence for the typed factor head.
Reference graph
Works this paper leans on
-
[1]
A simple framework for contrastive learning of visual representations, in: International Conference on Machine Learning (ICML)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G., 2020. A simple framework for contrastive learning of visual representations, in: International Conference on Machine Learning (ICML). Projection head discarded after pretraining
2020
-
[2]
Cui, Y., Che, W., Liu, T., Qin, B., Wang, S., Hu, G., 2020. Revisiting pre-trained models for Chinese natural language processing, in: Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 657–668.arXiv:2004.13922. chinese RoBERTa-WWM-ext (primary backbone in our exper- iments)
-
[3]
Deng, C., Mao, K., Dou, Z., 2024. Learning interpretable legal case retrieval via knowledge-guided case reformulation, in: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Pro- cessing, pp. 1253–1265. URL:https://aclanthology.org/2024.emnlp-main.73/. knowledge-guided legal case retrieval (KELLER); Chinese legal IR
2024
-
[4]
Efron, B., 1979. Bootstrap methods: Another look at the jackknife. The Annals of Statistics 7, 1–26. doi:10.1214/aos/1176344552
-
[5]
SimCSE: Simple Contrastive Learning of Sentence Embeddings
Gao, T., Yao, X., Chen, D., 2021. SimCSE: Simple contrastive learning of sentence embeddings, in: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 6894–6910.arXiv:2104.08821
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [6]
-
[7]
Clash-of-Leges: A bilingual dataset for conflict detection and explanation in statutory law
Italiani, P., Moro, G., Ragazzi, L., 2026. Clash-of-Leges: A bilingual dataset for conflict detection and explanation in statutory law. Expert Systems with Applications 300, 130182. doi:10.1016/j.eswa. 2025.130182. closest international prior work; binary conflict detection between legal articles, Italian Constitutional Court
-
[8]
Retrieval contrastive learning for aspect-level sentiment classifica- tion
Jian, Z., Li, J., Wu, Q., Yao, J., 2024. Retrieval contrastive learning for aspect-level sentiment classifica- tion. Information Processing & Management 61. doi:10.1016/j.ipm.2023.103539. iP&M contrastive method precedent; ABSA SOTA
-
[9]
Learning the difference that makes a difference with counterfactually-augmented data, in: International Conference on Learning Representations (ICLR)
Kaushik, D., Hovy, E., Lipton, Z.C., 2020. Learning the difference that makes a difference with counterfactually-augmented data, in: International Conference on Learning Representations (ICLR). URL:https://openreview.net/forum?id=Sklgs0NFvr. foundational counterfactually- augmented data (CAD) paper: human minimal revisions flip the gold label
2020
-
[10]
Dharshan Kumaran, Demis Hassabis, and James L
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A.A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., Hassabis, D., Clopath, C., Kumaran, D., Hadsell, R., 2017. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sci- ences 114, 3521–3526. doi:10.1073/pnas.1611835114
-
[11]
Statistical significance tests for machine translation evaluation, in: Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp
Koehn, P., 2004. Statistical significance tests for machine translation evaluation, in: Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 388–395
2004
-
[12]
Li, H., Ai, Q., Chen, J., Dong, Q., Wu, Y., Liu, Y., Chen, C., Tian, Q., 2023. SAILER: Structure- aware pre-trained language model for legal case retrieval, in: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 1035–1044. doi:10.1145/ 3539618.3591761. chinese legal BERT-encoder; we use as ...
-
[13]
Triplecontrastivelearningrepresentationboostingforsupervisedmulticlass tasks
Li, X., Liu, Z., Liu, S., 2025. Triplecontrastivelearningrepresentationboostingforsupervisedmulticlass tasks. Information Processing & Management 62, 104011. doi:10.1016/j.ipm.2024.104011. iP&M label-aware supervised contrastive multiclass precedent
-
[14]
Li, Y., Xu, C., Long, G., Shen, T., Tao, C., Jiang, J., 2024. CCPrefix: Counterfactual contrastive prefix- tuning for many-class classification, in: Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 2977–2988. URL:https: //aclanthology.org/2024.eacl-long.181/, doi:10.18...
-
[15]
Li, Z., Hoiem, D., 2018. Learning without forgetting. IEEE Transactions on Pattern Analysis and Machine Intelligence 40, 2935–2947. doi:10.1109/TPAMI.2017.2773081. 30
-
[16]
Ma, Y., Shao, Y., Wu, Y., Liu, Y., Zhang, R., Zhang, M., Ma, S., 2021. LeCaRD: A legal case retrieval dataset for Chinese law system, in: Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 2342–2348. doi:10.1145/3404835.3463250
-
[17]
The preregistration revolution
Nosek, B.A., Ebersole, C.R., DeHaven, A.C., Mellor, D.T., 2018. The preregistration revolution. Proceedings of the National Academy of Sciences 115, 2600–2606. doi:10.1073/pnas.1708274114
-
[18]
Qiu, X., Wang, Y., Guo, X., Zeng, Z., Yue, Y., Feng, Y., Miao, C., 2024a. PairCFR: Enhancing model training on paired counterfactually augmented data through contrastive learning, in: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). URL:https: //aclanthology.org/2024.acl-long.646/. paired CAD + contrastive los...
2024
-
[19]
Qiu, Z., Duan, X., Cai, Z., 2024b. Evaluating grammatical well-formedness in large language models: A comparative study with human judgments, in: Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics (CMCL). URL:https://aclanthology.org/2024.cmcl-1.16/, doi:10. 18653/v1/2024.cmcl-1.16. oSF pre-registration of three NLP experiment...
2024
-
[20]
Roschewitz, M., De Sousa Ribeiro, F., Xia, T., Khara, G., Glocker, B., 2024. Counterfactual contrastive learning: Robust representations via causal image synthesis, in: Data Engineering in Medical Imaging (DEMI) Workshop at MICCAI.arXiv:2403.09605. counterfactual-as-positive contrastive; medical imaging not legal
-
[21]
Simmons, J.P., Nelson, L.D., Simonsohn, U., 2011. False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychological Science 22, 1359–1366. doi:10.1177/0956797611417632
-
[22]
Increasing transparency through a multiverse analysis
Steegen, S., Tuerlinckx, F., Gelman, A., Vanpaemel, W., 2016. Increasing transparency through a multiverse analysis. Perspectives on Psychological Science 11, 702–712
2016
-
[23]
Legal judgment prediction via graph boosting with con- straints
Tong, S., Yuan, J., Zhang, P., Li, L., 2024. Legal judgment prediction via graph boosting with con- straints. Information Processing & Management 61, 103663. doi:10.1016/j.ipm.2024.103663. iP&M Chinese LJP precedent; multi-task with constraints
-
[24]
Lawformer: A pre-trained language model for Chinese legal long documents
Xiao, C., Hu, X., Liu, Z., Tu, C., Sun, M., 2021. Lawformer: A pre-trained language model for Chinese legal long documents. AI Open Chinese legal long-document encoder, RoFormer-based
2021
-
[25]
CAIL2018: A Large-Scale Legal Dataset for Judgment Prediction
Xiao, C., Zhong, H., Guo, Z., Tu, C., Liu, Z., Sun, M., Feng, Y., Han, X., Hu, Z., Wang, H., Xu, J., 2018. CAIL2018: Alarge-scalelegaldatasetforjudgmentprediction. arXivpreprintarXiv:1807.02478.cAIL benchmark for Chinese LJP — broadly used foundation for LJP method papers. 31
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[26]
Zhao, Q., Gao, T., Guo, N., 2023. LA-MGFM: A legal judgment prediction method via sememe- enhanced graph neural networks and multi-graph fusion mechanism. Information Processing & Man- agement 60, 103455. doi:10.1016/j.ipm.2023.103455. iP&M legal NLP precedent; Chinese CAIL multi-task
-
[27]
Zhao, S., Xu, Y., Chen, Z., Qiao, F., Chen, H., Li, X., Lin, S., Ji, Z., Li, Y., Wang, W.,
-
[28]
Scientific Data URL:https://www.nature.com/articles/s41597-026-07195-2, doi:10.1038/ s41597-026-07195-2
Bridging the gap in Chinese legal conflict review: A dataset, benchmark tasks, and frame- work. Scientific Data URL:https://www.nature.com/articles/s41597-026-07195-2, doi:10.1038/ s41597-026-07195-2. lCR-CN dataset, 6995 annotated provisions, 5-class conflict taxonomy
-
[29]
Enhancing pre-trained language models with Chinese character mor- phological knowledge
Zheng, Z., Wu, X., Liu, X., 2025. Enhancing pre-trained language models with Chinese character mor- phological knowledge. Information Processing & Management 62. doi:10.1016/j.ipm.2024.103945. iP&M 2-stage Chinese contrastive pretraining precedent (methodology twin). 32
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.