Leveraging LLM-Based Agentic Systems to Generate Quantum Applications for Test Optimization
Pith reviewed 2026-07-02 08:25 UTC · model grok-4.3
The pith
QPipe uses an LLM multi-agent system to convert natural language requirements into executable quantum applications for test optimization with high success rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
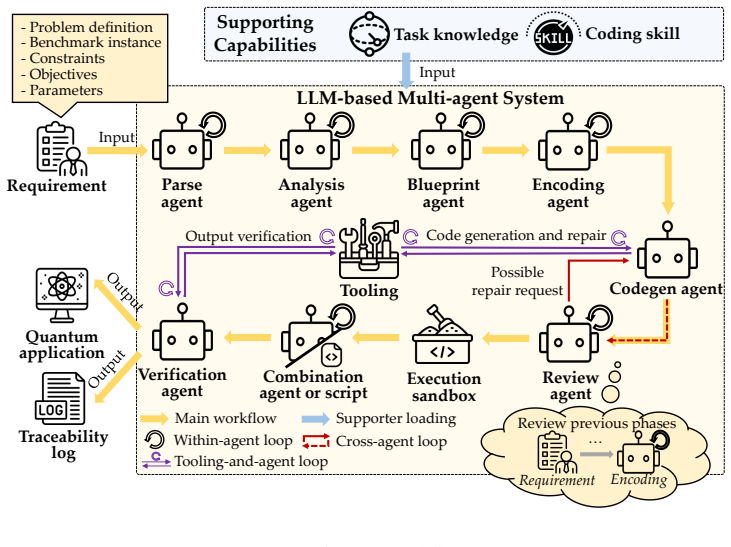
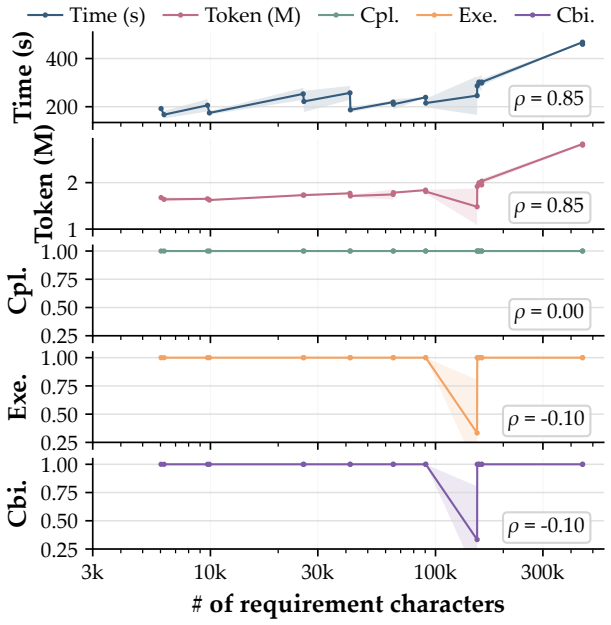
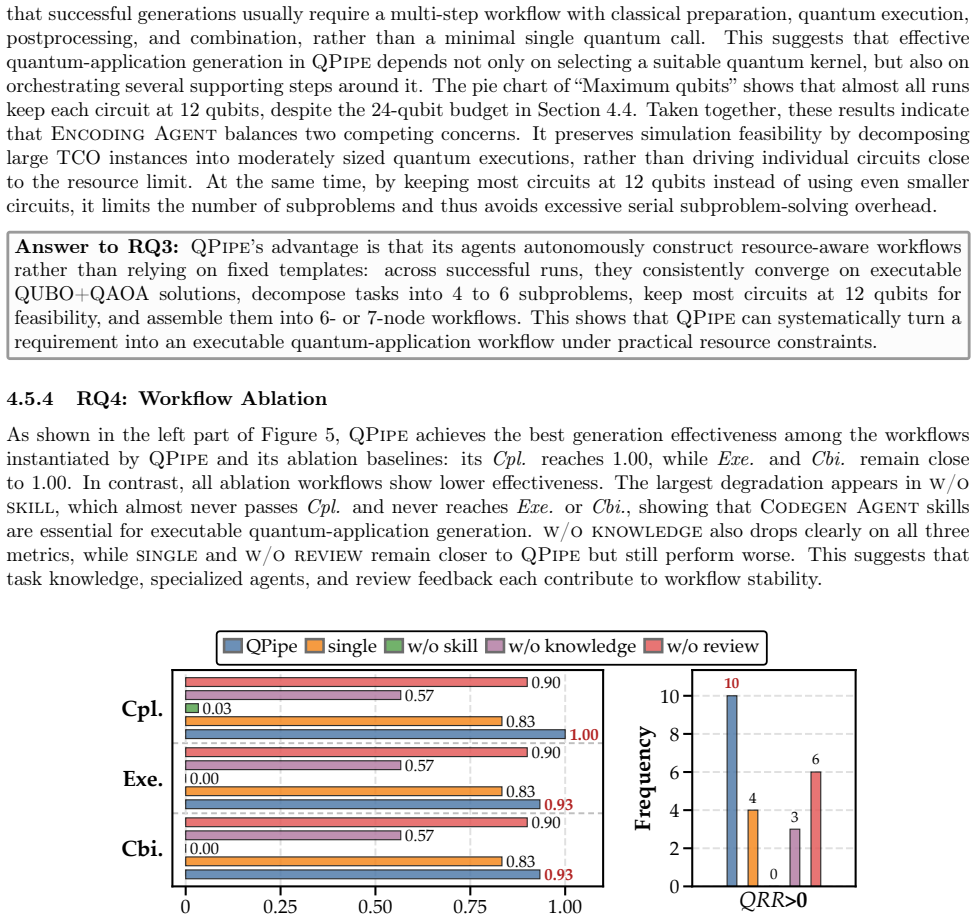
QPipe autonomously transforms natural-language requirements into traceable quantum-application workflows via specialized agents for requirement parsing, formulation, code generation, review, execution, and verification. Across 20 NL requirements linked to real-world test-optimization benchmarks, it achieves 100% code compilation and 96.7% application execution and result combination rates. The generated quantum applications outperform an offline genetic algorithm baseline in most cases, at average costs of 260.1 seconds and 1.89 million tokens per requirement. Ablation studies indicate that the system's performance depends on code-generation skills, task knowledge, review feedback, and multi
What carries the argument
QPipe, an LLM-based multi-agent architecture with agents specialized in requirement parsing, quantum formulation, code generation, review, execution, and verification.
If this is right
- QPipe completes quantum-application generation with 100% code compilation and 96.7% execution success across the 20 requirements.
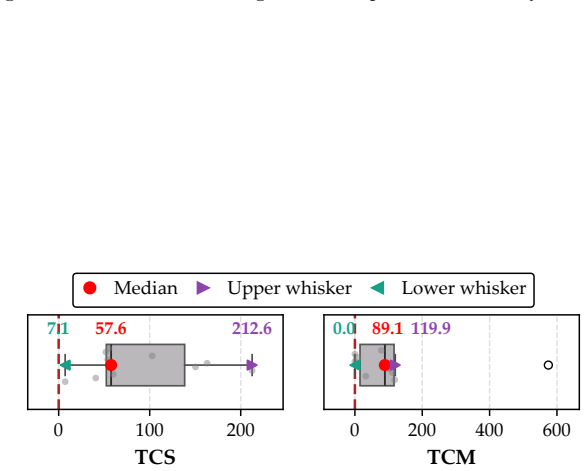
- The generated solutions outperform the offline genetic algorithm baseline in most cases.
- The advantage of QPipe depends on retaining code-generation skills, task knowledge, review feedback, and multi-agent decomposition.
- Average generation requires 260.1 seconds and 1.89M tokens per requirement.
Where Pith is reading between the lines
- The method might generalize to other software engineering tasks involving optimization if the benchmark requirements are similar to real-world ones.
- Performance could vary with different quantum hardware back-ends not tested in the current evaluation.
- Token and time costs might be reduced through improved agent coordination or model choices.
- This opens the possibility of fully automated pipelines for quantum-assisted software testing in industrial settings.
Load-bearing premise
The 20 chosen natural language requirements from existing benchmarks represent the full range of real-world test optimization tasks and the agents produce correct outputs without any human intervention across different quantum hardware.
What would settle it
Running QPipe on a fresh collection of natural language requirements from additional test-optimization benchmarks and observing execution success below 90 percent or baseline outperformance in fewer than half the cases would challenge the reported results.
Figures
read the original abstract
Quantum computing is increasingly explored for software engineering (SE) optimization, but translating natural-language (NL) task-level requirements into executable quantum applications still demands substantial quantum and programming expertise. We present QPipe, a large language model (LLM)-based multi-agent architecture that autonomously turns NL requirements into traceable quantum-application workflows through specialized agents for requirement parsing, formulation, code generation, review, execution, and verification. We evaluate QPipe on 20 NL requirements, each associated with a real-world benchmark and a test-optimization problem. QPipe successfully completes the key stages of quantum-application generation across requirements, achieving average rates of 100% for code compilation and 96.7% for application execution and final-result combination, with average generation costs of 260.1 seconds and 1.89M tokens per requirement. Among the generated quantum applications that execute successfully, the returned solutions outperform the offline genetic algorithm baseline in most cases. Ablation results further show that QPipe's advantage depends on retaining code-generation skills, task knowledge, review feedback, and multi-agent decomposition. These results indicate that agentic coordination can support generation of executable quantum applications for tackling test optimization problems from real-world benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QPipe, an LLM-based multi-agent architecture with specialized agents for parsing, formulation, code generation, review, execution, and verification that autonomously converts natural-language requirements into executable quantum applications for test-optimization problems. It reports evaluation on 20 NL requirements drawn from real-world benchmarks, claiming 100% average code-compilation success, 96.7% average execution and result-combination success, average costs of 260.1 seconds and 1.89M tokens per requirement, and outperformance versus an offline genetic-algorithm baseline in most successful cases, with ablations attributing gains to code-generation skills, task knowledge, review feedback, and multi-agent decomposition.
Significance. If the reported success rates and baseline comparisons hold under broader conditions, the work would demonstrate a practical route to reducing quantum and programming expertise barriers for SE optimization tasks, with potential impact on automated quantum-application pipelines; the ablation results on component contributions add internal validity to the agentic design.
major comments (3)
- [Evaluation] Evaluation (20 NL requirements): the reported aggregate success rates (100% compilation, 96.7% execution) lack per-instance error bars, variance measures, or breakdown of the four failure cases, making it impossible to assess stability or identify systematic weaknesses in the pipeline.
- [Evaluation] Evaluation (baseline comparison): no description is given of how the offline genetic-algorithm baseline was configured (population size, generations, mutation rates, or termination criteria), preventing reproduction or assessment of whether the reported outperformance is robust.
- [Evaluation] Evaluation (generalizability): all 20 requirements are drawn from existing benchmarks; the manuscript provides no experiments on novel NL inputs, different quantum hardware back-ends, or real-world test-optimization tasks outside the benchmark set, leaving the claim that QPipe supports generation "for tackling test optimization problems from real-world benchmarks" without external-validity evidence.
minor comments (2)
- [Abstract] The abstract states "outperform the offline genetic algorithm baseline in most cases" but does not quantify how many of the successful executions were compared or report the magnitude of improvement.
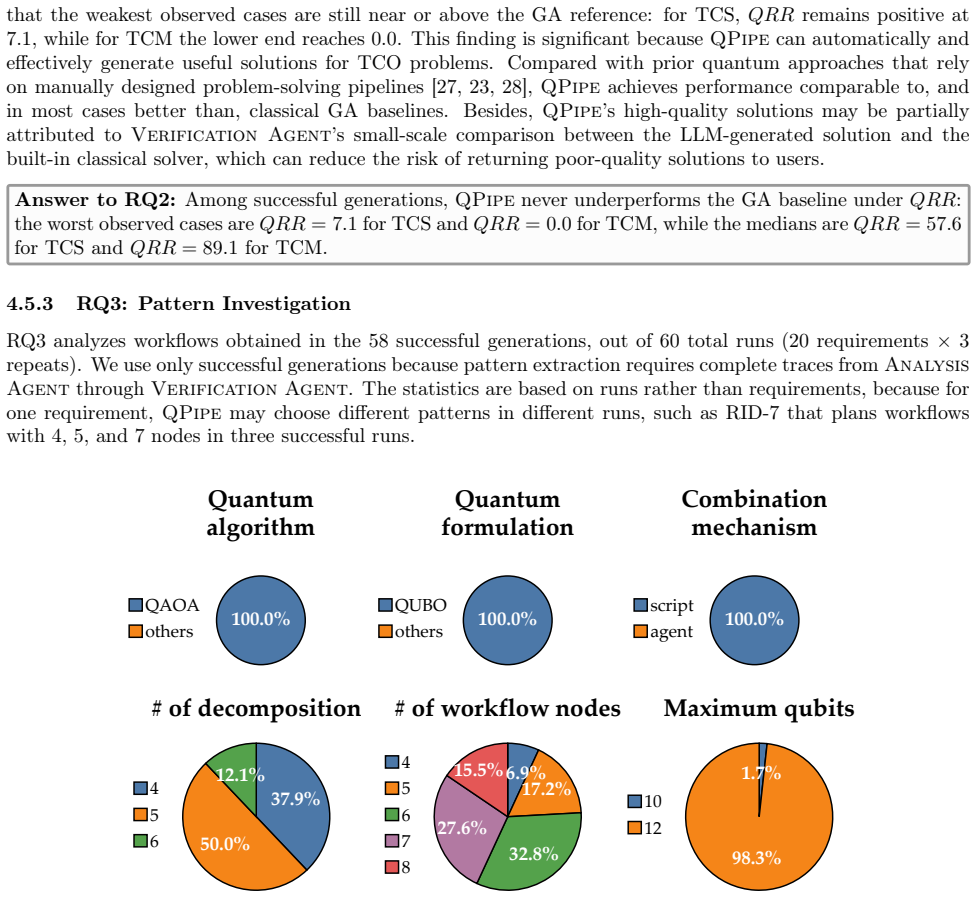
- [Ablation study] Ablation results are summarized at a high level; a table listing per-component success-rate drops would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the evaluation section of our manuscript. We address each major comment below and outline the revisions we will incorporate.
read point-by-point responses
-
Referee: [Evaluation] Evaluation (20 NL requirements): the reported aggregate success rates (100% compilation, 96.7% execution) lack per-instance error bars, variance measures, or breakdown of the four failure cases, making it impossible to assess stability or identify systematic weaknesses in the pipeline.
Authors: We agree that per-instance details would improve transparency and allow better assessment of stability. In the revised version, we will add a table presenting compilation and execution outcomes for each of the 20 requirements individually, along with standard deviation measures for the aggregate success rates and costs. This will also include a brief analysis of the four failure cases to identify any systematic patterns. revision: yes
-
Referee: [Evaluation] Evaluation (baseline comparison): no description is given of how the offline genetic-algorithm baseline was configured (population size, generations, mutation rates, or termination criteria), preventing reproduction or assessment of whether the reported outperformance is robust.
Authors: We acknowledge the omission of the genetic algorithm configuration details. The revised manuscript will include a complete description of the baseline setup, specifying population size, number of generations, mutation and crossover rates, selection method, and termination criteria, to support reproducibility and allow readers to evaluate the robustness of the outperformance claims. revision: yes
-
Referee: [Evaluation] Evaluation (generalizability): all 20 requirements are drawn from existing benchmarks; the manuscript provides no experiments on novel NL inputs, different quantum hardware back-ends, or real-world test-optimization tasks outside the benchmark set, leaving the claim that QPipe supports generation "for tackling test optimization problems from real-world benchmarks" without external-validity evidence.
Authors: The 20 requirements were selected from established benchmarks that reflect real-world test-optimization scenarios. While the current study does not include experiments on novel natural-language inputs or additional hardware back-ends, we will revise the manuscript to explicitly qualify the scope of our claims, acknowledge the limitation on external validity, and outline planned extensions for future work on novel inputs and varied back-ends. revision: partial
Circularity Check
No circularity: empirical success rates measured on external benchmarks with independent baseline
full rationale
The paper presents an LLM multi-agent system (QPipe) and reports measured success rates (100% compilation, 96.7% execution) plus outperformance versus an offline GA baseline on 20 NL requirements drawn from existing benchmarks. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. The evaluation uses external benchmarks and an independent baseline; ablation studies address internal components but do not reduce the reported metrics to self-definition or self-citation. The central claims are direct empirical observations rather than derivations that collapse to their inputs by construction. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
When software engineering meets quantum computing.Communi- cations of the ACM, 65(4):84–88, 2022
Shaukat Ali, Tao Yue, and Rui Abreu. When software engineering meets quantum computing.Communi- cations of the ACM, 65(4):84–88, 2022
2022
-
[2]
Qpipe workflow empirical study, July 2026
Anonymous Authors. Qpipe workflow empirical study, July 2026. URLhttps://doi.org/10.5281/zeno do.21094908
-
[3]
Qpipe workflow tool, July 2026
Anonymous Authors. Qpipe workflow tool, July 2026. URLhttps://doi.org/10.5281/zenodo.2109483 7
-
[4]
Claude models overview.https://platform.claude.com/docs/en/about-claude/models/o verview, 2026
Anthropic. Claude models overview.https://platform.claude.com/docs/en/about-claude/models/o verview, 2026. Accessed: 2026-06-22. 14
2026
-
[5]
Qhackbench: Benchmarking large language models for quantum code gener- ation using pennylane hackathon challenges
AbdulBasit, MinghaoShao, MuhammadHaiderAsif, NouhailaInnan, MuhammadKashif, AlbertoMarchi- sio, and Muhammad Shafique. Qhackbench: Benchmarking large language models for quantum code gener- ation using pennylane hackathon challenges. In2025 IEEE International Conference on Quantum Artificial Intelligence (QAI), pages 316–322. IEEE, 2025
2025
-
[6]
Pattern-based generation and adaptation of quantum workflows
Martin Beisel, Johanna Barzen, Frank Leymann, Lavinia Stiliadou, Daniel Vietz, and Benjamin Weder. Pattern-based generation and adaptation of quantum workflows. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), pages 3072–3084. IEEE, 2025
2025
-
[7]
Charlie Campbell, Wayne Luk, Hao Chen, and Hongxiang Fan. Enhancing LLM-based quantum code generation with multi-agent optimization and quantum error correction. In2025 62nd ACM/IEEE Design Automation Conference, DAC. IEEE, 2025. doi: 10.1109/DAC63849.2025.11133316
-
[8]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
The smelly eight: An empirical study on the prevalence of code smells in quantum computing
Qihong Chen, Rúben Câmara, José Campos, André Souto, and Iftekhar Ahmed. The smelly eight: An empirical study on the prevalence of code smells in quantum computing. In2023 IEEE/ACM 45th Inter- national Conference on Software Engineering (ICSE), pages 358–370. IEEE, 2023
2023
-
[10]
Qai4ase: Quantum artifi- cial intelligence for automotive software engineering
Mirko De Vincentiis, Fabio Cassano, Alessandro Pagano, and Antonio Piccinno. Qai4ase: Quantum artifi- cial intelligence for automotive software engineering. InProceedings of the 1st International Workshop on Quantum Programming for Software Engineering, pages 19–21, 2022
2022
-
[11]
Supporting controlled experimentation with testing techniques: An infrastructure and its potential impact.Empirical Software Engineering, 10(4): 405–435, 2005
Hyunsook Do, Sebastian Elbaum, and Gregg Rothermel. Supporting controlled experimentation with testing techniques: An infrastructure and its potential impact.Empirical Software Engineering, 10(4): 405–435, 2005
2005
-
[12]
ZhenxiaoFu, FanChen, andLeiJiang. Qagent: Anllm-basedmulti-agentsystemforautonomousopenqasm programming.arXiv preprint arXiv:2508.20134, 2025. URLhttps://arxiv.org/abs/2508.20134
-
[13]
Google shared dataset of test suite results.https://code.google.com/archive/p/google-sha red-dataset-of-test-suite-results, 2011
Google. Google shared dataset of test suite results.https://code.google.com/archive/p/google-sha red-dataset-of-test-suite-results, 2011. Accessed: 2026-06-27
2011
-
[14]
Quanbench: Benchmarking quantum code generation with large language models
Xiaoyu Guo, Minggu Wang, and Jianjun Zhao. Quanbench: Benchmarking quantum code generation with large language models. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 2657–2669, 2025. doi: 10.1109/ASE63991.2025.00218
-
[15]
Search-based software engineering: Trends, techniques and applications.ACM Computing Surveys (CSUR), 45(1):1–61, 2012
Mark Harman, S Afshin Mansouri, and Yuanyuan Zhang. Search-based software engineering: Trends, techniques and applications.ACM Computing Surveys (CSUR), 45(1):1–61, 2012
2012
-
[16]
Test optimization in dnn testing: a survey.ACM Transactions on Software Engineering and Methodology, 33 (4):1–42, 2024
Qiang Hu, Yuejun Guo, Xiaofei Xie, Maxime Cordy, Lei Ma, Mike Papadakis, and Yves Le Traon. Test optimization in dnn testing: a survey.ACM Transactions on Software Engineering and Methodology, 33 (4):1–42, 2024
2024
-
[17]
A methodological analysis of empirical studies in quantum software testing.ACM Transactions on Software Engineering and Methodology, 2026
Yuechen Li, Minqi Shao, Jianjun Zhao, and Qichen Wang. A methodological analysis of empirical studies in quantum software testing.ACM Transactions on Software Engineering and Methodology, 2026
2026
-
[18]
Llama 4: Model Cards and Prompt Formats.https://www.llama.com/docs/model-cards-and-p rompt-formats/llama4/, 2025
Meta. Llama 4: Model Cards and Prompt Formats.https://www.llama.com/docs/model-cards-and-p rompt-formats/llama4/, 2025. Accessed: 2026-06-25
2025
-
[19]
Quantum software engineering: Roadmap and challenges ahead.ACM Transactions on Software Engineering and Methodology, 34(5):1–48, 2025
Juan Manuel Murillo, Jose Garcia-Alonso, Enrique Moguel, Johanna Barzen, Frank Leymann, Shaukat Ali, Tao Yue, Paolo Arcaini, Ricardo Pérez-Castillo, Ignacio García-Rodríguez de Guzmán, et al. Quantum software engineering: Roadmap and challenges ahead.ACM Transactions on Software Engineering and Methodology, 34(5):1–48, 2025
2025
-
[20]
A 2030 roadmap for software engineering.ACM Transactions on Software Engineering and Methodology, 34(5):1–55, 2025
Mauro Pezzè, Silvia Abrahão, Birgit Penzenstadler, Denys Poshyvanyk, Abhik Roychoudhury, and Tao Yue. A 2030 roadmap for software engineering.ACM Transactions on Software Engineering and Methodology, 34(5):1–55, 2025
2030
-
[21]
An B. B. Pham, Hoa T. Nguyen, and Muhammad Usman. Qbuglm: An agentic benchmarking framework for llm-based quantum software debugging.arXiv preprint arXiv:2606.07314, 2026. URLhttps://arxi v.org/abs/2606.07314
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Atcs data.https://bitbucket.or g/HelgeS/atcs-data/src/master/, 2018
Helge Spieker, Arnaud Gotlieb, Dusica Marijan, and Morten Mossige. Atcs data.https://bitbucket.or g/HelgeS/atcs-data/src/master/, 2018. Public dataset release used for continuous integration test-case selection studies; accessed: 2026-06-27. 15
2018
-
[23]
Reformu- lating regression test suite optimization using quantum annealing-an empirical study.International Journal on Software Tools for Technology Transfer, 26(6):767–780, 2024
Antonio Trovato, Manuel De Stefano, Fabiano Pecorelli, Dario Di Nucci, and Andrea De Lucia. Reformu- lating regression test suite optimization using quantum annealing-an empirical study.International Journal on Software Tools for Technology Transfer, 26(6):767–780, 2024
2024
-
[24]
Qaoa-gpt: Efficient generation of adaptive and regular quantum approximate optimization algorithm circuits
Ilya Tyagin, Marwa H Farag, Kyle Sherbert, Karunya Shirali, Yuri Alexeev, and Ilya Safro. Qaoa-gpt: Efficient generation of adaptive and regular quantum approximate optimization algorithm circuits. In 2025 IEEE International Conference on Quantum Computing and Engineering (QCE), volume 1, pages 1505–1515. IEEE, 2025
2025
-
[25]
Pablo Valle, Aitor Arrieta, and Maite Arratibel. Applying and extending the delta debugging algorithm for elevator dispatching algorithms (experience paper).Proceedings of the 32nd ACM SIGSOFT international symposium on software testing and analysis, pages 1055–1067, 2023
2023
-
[26]
Qiskit humaneval: An evaluation benchmark for quantum code generative models
Sanjay Vishwakarma, Francis Harkins, Siddharth Golecha, Vishal Sharathchandra Bajpe, Nicolas Dupuis, Luca Buratti, David Kremer, Ismael Faro, Ruchir Puri, and Juan Cruz-Benito. Qiskit humaneval: An evaluation benchmark for quantum code generative models. In2024 IEEE International Conference on Quantum Computing and Engineering (QCE), volume 1, pages 1169–...
2024
-
[27]
Quantum approximate optimization algorithm for test case optimization.IEEE Transactions on Software Engineering, 50(12):3249–3264, 2024
Xinyi Wang, Shaukat Ali, Tao Yue, and Paolo Arcaini. Quantum approximate optimization algorithm for test case optimization.IEEE Transactions on Software Engineering, 50(12):3249–3264, 2024
2024
-
[28]
Test case minimization with quantum annealers.ACM Transactions on Software Engineering and Methodology, 34(1):1–24, 2024
Xinyi Wang, Asmar Muqeet, Tao Yue, Shaukat Ali, and Paolo Arcaini. Test case minimization with quantum annealers.ACM Transactions on Software Engineering and Methodology, 34(1):1–24, 2024
2024
-
[29]
Xinyi Wang, Shaukat Ali, and Paolo Arcaini. Quantum artificial intelligence for software engineering: the road ahead.arXiv preprint arXiv:2505.04797, 2025. URLhttps://arxiv.org/abs/2505.04797
-
[30]
Quantum neural network classifier for cancer registry system testing: A feasibility study.ACM Transactions on Software Engineering and Methodology, 35(5):1–24, 2026
Xinyi Wang, Shaukat Ali, Paolo Arcaini, Narasimha Raghavan Veeraragavan, and Jan F Nygård. Quantum neural network classifier for cancer registry system testing: A feasibility study.ACM Transactions on Software Engineering and Methodology, 35(5):1–24, 2026
2026
-
[31]
Integrating quantum computing into workflow modeling and execution
Benjamin Weder, Uwe Breitenbücher, Frank Leymann, and Karoline Wild. Integrating quantum computing into workflow modeling and execution. In2020 IEEE/ACM 13th International Conference on Utility and Cloud Computing (UCC), pages 279–291. IEEE, 2020. doi: 10.1109/UCC48980.2020.00046
-
[32]
Deepseek-v4: Towards highly efficient million-token context intelligence
Anyi Xu, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chenchen Ling, et al. Deepseek-v4: Towards highly efficient million-token context intelligence. arXiv preprint arXiv:2606.19348, 2026. URLhttps://arxiv.org/abs/2606.19348
-
[33]
Ising-based Test Optimization and Benchmarking
Yige Yang, Man Zhang, and Tao Yue. Ising-based test optimization and benchmarking.arXiv preprint arXiv:2604.10450, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Regression testing minimization, selection and prioritization: a survey
Shin Yoo and Mark Harman. Regression testing minimization, selection and prioritization: a survey. Software testing, verification and reliability, 22(2):67–120, 2012
2012
-
[35]
Cong Yu, Valter Uotila, Shilong Deng, Qingyuan Wu, Tuo Shi, Songlin Jiang, Lei You, and Bo Zhao. Quasar: Quantum assembly code generation using tool-augmented llms via agentic rl.arXiv preprint arXiv:2510.00967, 2025. URLhttps://arxiv.org/abs/2510.00967
-
[36]
Vista: Verifier-in-the-loop agentic reinforcement learning for quantum program synthesis
Cong Yu, Tuo Shi, Valter Uotila, Shilong Deng, Lei You, and Bo Zhao. Vista: Verifier-in-the-loop agentic reinforcement learning for quantum program synthesis. InProceedings of the ACM Conference on AI and Agentic Systems, CAIS ’26, pages 239–252. Association for Computing Machinery, 2026. doi: 10.1145/37 86335.3813148
work page doi:10.1145/37 2026
-
[37]
Tao Yue and Man Zhang. Q-ready: Predictive feasibility assessment for hybrid quantum-classical applica- tions.arXiv preprint arXiv:2606.16201, 2026. URLhttps://arxiv.org/abs/2606.16201
-
[38]
Llm-qubo: An end-to-end framework for automated qubo transformation from natural language problem descriptions
Huixiang Zhang, Mahzabeen Emu, and Salimur Choudhury. Llm-qubo: An end-to-end framework for automated qubo transformation from natural language problem descriptions. InProceedings of the AAAI Symposium Series, volume 7, pages 411–418, 2025
2025
-
[39]
Man Zhang, Yuechen Li, Tao Yue, and Kai-Yuan Cai. Empirical studies on quantum optimization for software engineering: A systematic analysis.arXiv preprint arXiv:2510.27113, 2025. URLhttps://arxi v.org/abs/2510.27113
-
[40]
Quantum optimization for software engineering: A survey.ACM Trans
Man Zhang, Yuechen Li, Tao Yue, and Kai-Yuan Cai. Quantum optimization for software engineering: A survey.ACM Trans. Softw. Eng. Methodol., May 2026. ISSN 1049-331X. doi: 10.1145/3816147. URL https://doi.org/10.1145/3816147. Just Accepted. 16
- [42]
-
[43]
Quantum-based software engineering.arXiv preprint arXiv:2505.23674, 2025
Jianjun Zhao. Quantum-based software engineering.arXiv preprint arXiv:2505.23674, 2025. URLhttps: //arxiv.org/abs/2505.23674. 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.