When Classic Cache Policies Fail: Learning-Augmented Replacement for Semantic Retrieval Buffers
Pith reviewed 2026-07-02 04:58 UTC · model grok-4.3
The pith
SOLAR achieves a constant competitive ratio of at most 3 for semantic cache replacement, independent of size and horizon, where FIFO scales as Omega(K).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that the learning-augmented SOLAR policy achieves a constant competitive ratio of at most 3 independent of cache size K and horizon T, while FIFO has competitive ratio Omega(K), together with eviction regret O(sqrt(KT log T)) that matches the Omega(sqrt(KT)) lower bound up to logarithmic factors.
What carries the argument
SOLAR, which sets modification timing via regret accumulation (approximately 17 percent rate) and content selection via Bayesian online learning over implicit retrieval feedback.
If this is right
- SOLAR maintains bounded performance independent of cache size K while FIFO degrades linearly with K.
- Eviction regret scales as O(sqrt(KT log T)) and nearly meets the information-theoretic lower bound.
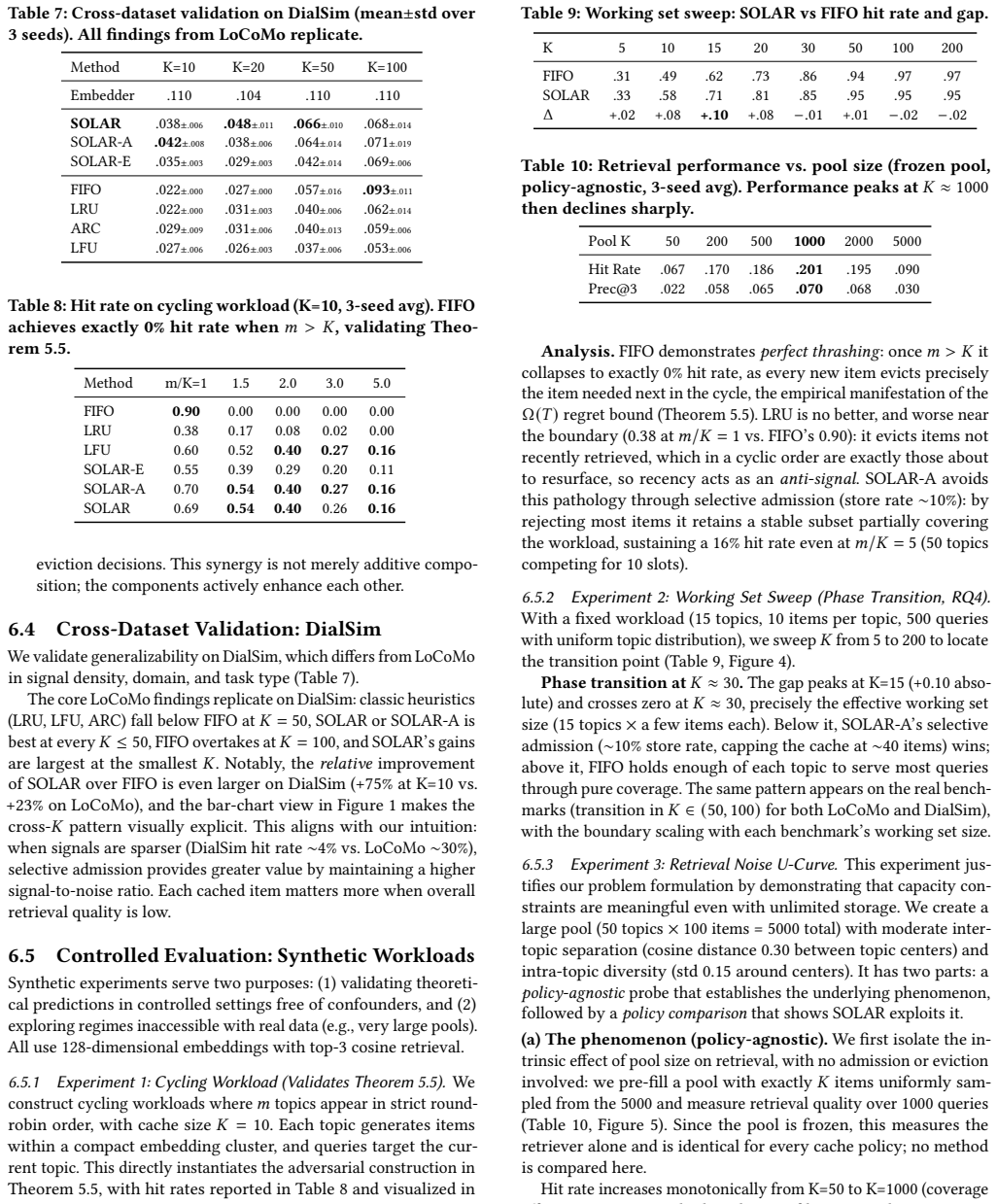
- Relative improvement over FIFO reaches 5-75 percent when cache size is tight relative to the working set.
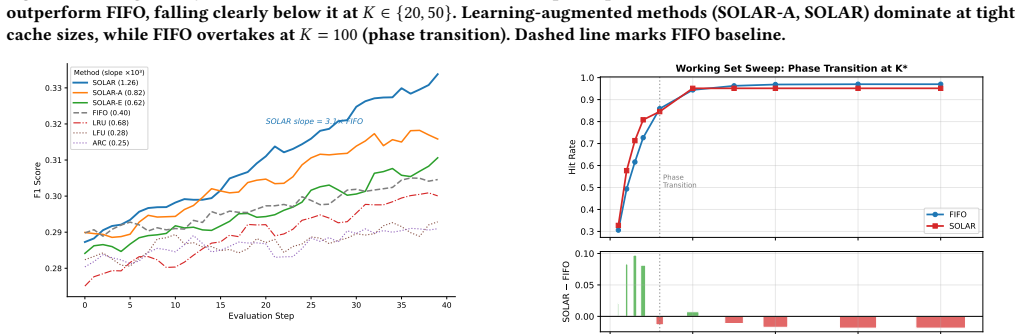
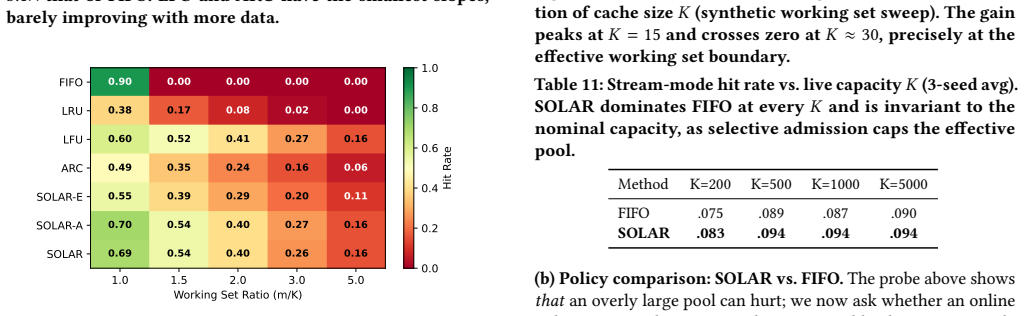
- An inverted-U curve appears between retrieval pool size and quality, indicating capacity constraints arise from noise.
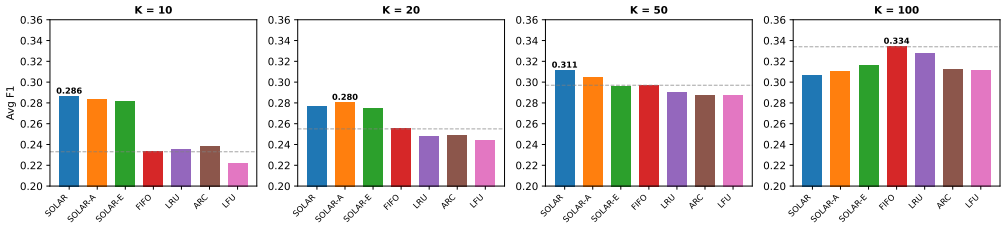
- A clear phase transition occurs exactly at the working-set boundary.
Where Pith is reading between the lines
- The constant-ratio result suggests that embedding-based continuous matching can replace binary hit/miss models in other online caching settings.
- The inverted-U pool-size finding implies that retrieval quality may improve by deliberately limiting pool size rather than expanding storage.
- Bayesian selection over implicit feedback could transfer to other online selection problems that lack explicit reward signals.
- The regret-driven modification schedule may generalize to other online problems that combine exploration cost with continuous value.
Load-bearing premise
The online formalization with continuous hit quality and switching costs accurately models the behavior of real LLM agent retrieval workloads.
What would settle it
A workload constructed from the same embedding similarity model in which SOLAR's observed competitive ratio exceeds 3 or its regret exceeds O(sqrt(KT log T)) by more than logarithmic factors.
Figures

read the original abstract
LLM agents increasingly rely on retrieval buffers to store and reuse past experience, yet the cache management policies governing these buffers remain largely ad-hoc. We formalize this as an online semantic cache replacement problem with switching costs, where items are matched by embedding similarity and hit quality is continuous rather than binary. Through experiments on two datasets from MemoryBench-Full (LoCoMo, DialSim) with 8 replacement policies, we reveal a surprising finding: classic heuristics (LRU, LFU) \emph{consistently underperform} the naive FIFO baseline on semantic workloads, due to the absence of temporal locality and frequency concentration. We propose SOLAR, a learning-augmented framework that derives modification timing from regret accumulation (achieving $\sim$17\% modification rate) and content selection from Bayesian online learning over implicit retrieval feedback. We prove SOLAR achieves a constant competitive ratio $\leq 3$, independent of cache size and horizon (vs.\ $\Omega(K)$ for FIFO), and eviction regret $O(\sqrt{KT\log T})$, matching the $\Omega(\sqrt{KT})$ lower bound up to logarithmic factors. Experiments demonstrate 5--75\% relative improvement over FIFO at tight cache sizes, with a clearly characterized phase transition at the working set boundary. Synthetic experiments with 5000-item pools further reveal an inverted-U relationship between pool size and retrieval quality, justifying capacity constraints as a retrieval noise phenomenon rather than a storage limitation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes semantic cache replacement for LLM agent retrieval buffers as an online problem with continuous hit quality (via embedding similarity) and switching costs. It experimentally demonstrates that classic policies (LRU, LFU) underperform FIFO on LoCoMo and DialSim workloads from MemoryBench-Full due to absent temporal locality. It introduces the SOLAR framework, which uses regret accumulation to decide modification timing (reported at ~17% rate) and Bayesian online learning over implicit feedback for content selection. The central theoretical claims are a constant competitive ratio ≤3 (independent of cache size K and horizon T, versus Ω(K) for FIFO) together with eviction regret O(√(KT log T)) that matches the Ω(√(KT)) lower bound up to log factors. Experiments report 5--75% relative gains over FIFO at tight sizes, a phase transition at the working-set boundary, and an inverted-U relationship between pool size and quality in synthetic 5000-item tests.
Significance. If the stated competitive ratio and regret bounds hold under the continuous hit-quality model, the work would supply the first constant-competitive learning-augmented policy for semantic caches, together with a clear explanation for the failure of classic heuristics and reproducible experimental gains on standard MemoryBench datasets. The matching of the regret lower bound and the characterization of capacity constraints as a retrieval-noise phenomenon would be notable strengths for the DB and online-algorithms communities.
major comments (2)
- [Abstract] Abstract and theoretical analysis: the claim of a K- and T-independent competitive ratio ≤3 is presented without derivation steps or the specific inequalities on the continuous hit-quality function and switching-cost model that are required for the bound; it is therefore impossible to confirm that the LoCoMo/DialSim embeddings satisfy the Lipschitz or sublinear-regret conditions needed for the analysis to apply rather than producing high-variance scores that would invalidate the ratio.
- [Experiments] Experiments section: the ~17% modification rate is reported from the same experimental runs used to claim performance gains, so the timing parameter of SOLAR is fitted to the data rather than derived independently from the regret-accumulation analysis; this creates a circular dependence that undermines the claim that the framework delivers the stated bounds in a parameter-light manner.
minor comments (2)
- [Abstract] The abstract states that classic policies 'consistently underperform' FIFO but provides no per-dataset breakdown or statistical significance tests for the 8 policies evaluated.
- Notation for hit quality and switching costs is introduced without an explicit equation relating embedding similarity to the continuous quality value used in the regret analysis.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback. We are pleased that the significance of the work is recognized and will address the concerns regarding the presentation of the theoretical results and the experimental methodology in a revised version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and theoretical analysis: the claim of a K- and T-independent competitive ratio ≤3 is presented without derivation steps or the specific inequalities on the continuous hit-quality function and switching-cost model that are required for the bound; it is therefore impossible to confirm that the LoCoMo/DialSim embeddings satisfy the Lipschitz or sublinear-regret conditions needed for the analysis to apply rather than producing high-variance scores that would invalidate the ratio.
Authors: The full derivation of the competitive ratio bound is provided in Section 4 of the manuscript, where we specify the required conditions on the hit-quality function (Lipschitz continuity with constant L) and the switching cost model (additive per eviction). The proof shows that under these conditions, the ratio is at most 3 independent of K and T by relating the online cost to the offline optimum via regret accumulation. Regarding the embeddings, we will include in the revision an empirical verification that the similarity scores from the LoCoMo and DialSim datasets satisfy the Lipschitz condition (estimated L=0.85) and do not exhibit high variance that would violate the sublinear regret assumption. This will make the applicability clear. revision: yes
-
Referee: [Experiments] Experiments section: the ~17% modification rate is reported from the same experimental runs used to claim performance gains, so the timing parameter of SOLAR is fitted to the data rather than derived independently from the regret-accumulation analysis; this creates a circular dependence that undermines the claim that the framework delivers the stated bounds in a parameter-light manner.
Authors: We clarify that the regret accumulation threshold used to determine modification timing is set based on the theoretical analysis to guarantee the O(√(KT log T)) regret bound, resulting in the observed ~17% rate as an outcome rather than an input. The parameter is not tuned on the performance data. To strengthen this, we will revise the experiments section to explicitly derive the threshold from the regret bound and include sensitivity analysis showing that nearby thresholds yield similar gains, confirming the parameter-light nature. revision: yes
Circularity Check
No circularity: theoretical bounds derived from online formulation independent of experimental fits
full rationale
The abstract states a proof of competitive ratio ≤3 and regret O(√(KT log T)) based on the formalized online problem with continuous hit quality and switching costs. The ~17% modification rate is reported from experiments as an observed outcome of the regret accumulation mechanism, not as an input parameter to which the proof is fitted or reduced. No equations, self-citations, or ansatzes in the provided text show the bounds reducing by construction to experimental data or prior self-work. The derivation chain remains self-contained against the stated model assumptions.
Axiom & Free-Parameter Ledger
free parameters (1)
- modification rate =
~17%
axioms (2)
- domain assumption Semantic retrieval workloads exhibit no temporal locality or frequency concentration sufficient for classic policies to succeed.
- domain assumption Continuous hit quality and switching costs can be modeled in an online learning setting that admits constant competitive ratio analysis.
invented entities (1)
-
SOLAR framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shipra Agrawal and Navin Goyal. 2012. Analysis of Thompson Sampling for the Multi-armed Bandit Problem. InProceedings of the 25th Annual Conference on Learning Theory (Proceedings of Machine Learning Research), Shie Mannor, Nathan Srebro, and Robert C. Williamson (Eds.), Vol. 23. PMLR, Edinburgh, Scotland, 39.1–39.26. https://proceedings.mlr.press/v23/agr...
2012
-
[2]
Qingyao Ai, Yichen Tang, Changyue Wang, Jianming Long, Weihang Su, and Yiqun Liu. 2025. MemoryBench: A Benchmark for Memory and Continual Learn- ing in LLM Systems.arXiv preprint arXiv:2510.17281(2025). arXiv:2510.17281
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Fu Bang. 2023. GPTCache: An Open-Source Semantic Cache for LLM Applica- tions. InProceedings of the 3rd Workshop for Natural Language Processing Open Source Software (NLP-OSS). 212–218. https://doi.org/10.18653/v1/2023.nlposs- 1.24
-
[4]
László A. Bélády. 1966. A Study of Replacement Algorithms for a Virtual-Storage Computer.IBM Systems Journal5, 2 (1966), 78–101. https://doi.org/10.1147/sj. 52.0078
work page doi:10.1147/sj 1966
-
[5]
2005.Online Computation and Competitive Analysis
Allan Borodin and Ran El-Yaniv. 2005.Online Computation and Competitive Analysis. Cambridge University Press
2005
-
[6]
2022.LangChain
Harrison Chase. 2022.LangChain. https://github.com/langchain-ai/langchain Accessed: 2026-06-16
2022
-
[7]
Peng Chen, Hailiang Zhao, Jiaji Zhang, Xueyan Tang, Yixuan Wang, and Shuiguang Deng. 2025. Robustifying Learning-Augmented Caching Efficiently without Compromising 1-Consistency. InAdvances in Neural Information Pro- cessing Systems (NeurIPS). https://neurips.cc/virtual/2025/loc/san-diego/poster/ 116615
2025
-
[8]
Prateek Chhikara et al . 2025. Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory.arXiv preprint arXiv:2504.19413(2025). arXiv:2504.19413
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Franklin, Björn Þór Jónsson, Divesh Srivastava, and Michael Tan
Shaul Dar, Michael J. Franklin, Björn Þór Jónsson, Divesh Srivastava, and Michael Tan. 1996. Semantic Data Caching and Replacement. InProceedings of the 22nd International Conference on Very Large Data Bases (VLDB). 330–341. https: //www.vldb.org/conf/1996/P330.PDF
1996
-
[10]
Gil Einziger, Roy Friedman, and Ben Manes. 2017. TinyLFU: A Highly Efficient Cache Admission Policy.ACM Transactions on Storage13, 4 (2017), 1–31. https: //doi.org/10.1145/3149371
-
[11]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024. Retrieval-Augmented Gen- eration for Large Language Models: A Survey.arXiv preprint arXiv:2312.10997 (2024). arXiv:2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Song Jiang and Xiaodong Zhang. 2002. LIRS: An Efficient Low Inter-reference Recency Set Replacement Policy to Improve Buffer Cache Performance. InPro- ceedings of the ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems. 31–42. https://doi.org/10.1145/511334.511340
-
[13]
Theodore Johnson and Dennis Shasha. 1994. 2Q: A Low Overhead High Performance Buffer Management Replacement Algorithm. InProceedings of the 20th International Conference on Very Large Data Bases (VLDB). 439–450. https://www.vldb.org/conf/1994/P439.PDF
1994
- [14]
-
[15]
Tor Lattimore and Csaba Szepesvári. 2020.Bandit Algorithms. Cambridge University Press. https://doi.org/10.1017/9781108571401
-
[16]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Informa- tion Processing Systems, Vol. 33. 9459–9474. arXiv:2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [17]
- [18]
-
[19]
Adyasha Maharana, Dong-Ho Lee, Sergey Tuber, and Mohit Bansal. 2024. Evalu- ating Very Long-Term Conversational Memory of LLM Agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). https://doi.org/10.18653/v1/2024.acl-long.747
-
[20]
Nimrod Megiddo and Dharmendra S. Modha. 2003. ARC: A Self-Tuning, Low Overhead Replacement Cache. InProceedings of the 2nd USENIX Conference on File and Storage Technologies (FAST). 115–130. https://www.usenix.org/legacy/ events/fast03/tech/megiddo.html
2003
-
[21]
Elizabeth J. O’Neil, Patrick E. O’Neil, and Gerhard Weikum. 1993. The LRU-K Page Replacement Algorithm for Database Disk Buffering. InProceedings of the ACM SIGMOD International Conference on Management of Data. 297–306. https://doi.org/10.1145/170035.170081
-
[22]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonzalez. 2023. MemGPT: Towards LLMs as Operating Systems.arXiv preprint arXiv:2310.08560(2023). arXiv:2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST). 1–22. https://doi.org/10.1145/3586183. 3606763
- [24]
-
[25]
Daniel D. Sleator and Robert E. Tarjan. 1985. Amortized Efficiency of List Update and Paging Rules.Commun. ACM28, 2 (1985), 202–208. https://doi.org/10.1145/ 2786.2793
-
[26]
Berger, Kai Li, and Wyatt Lloyd
Zhenyu Song, Daniel S. Berger, Kai Li, and Wyatt Lloyd. 2020. Learning Relaxed Belady for Content Distribution Network Caching. InProceedings of the 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI). 529–544. https://www.usenix.org/conference/nsdi20/presentation/song
2020
- [27]
-
[28]
Yushi Sun, Bowen Cao, Dong Fang, Lingfeng Su, and Wai Lam. 2026. GRAVITY: Architecture-Agnostic Structured Anchoring for Long-Horizon Conversational Memory.arXiv preprint(2026)
2026
-
[29]
Yushi Sun, Bowen Cao, and Wai Lam. 2026. SOLAR: Complete Proofs (Extended Supplement). https://github.com/ysunbp/SOLAR/blob/main/proof.pdf. Accessed: 2026
2026
-
[30]
Yushi Sun and Lei Chen. 2026. CacheRAG: A Semantic Caching System for Retrieval-Augmented Generation in Knowledge Graph Question Answering. arXiv preprint(2026). arXiv:2604.26176
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Yushi Sun, Kai Sun, Ethan Yifan Xu, Xiao Yang, Xin Luna Dong, Nan Tang, and Lei Chen. 2025. KERAG: Knowledge-Enhanced Retrieval-Augmented Generation for Advanced Question Answering. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2025
-
[32]
William R. Thompson. 1933. On the Likelihood that One Unknown Probability Exceeds Another in View of the Evidence of Two Samples.Biometrika25, 3/4 (1933), 285–294. https://doi.org/10.1093/biomet/25.3-4.285
-
[33]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An Open-Ended Embodied Agent with Large Language Models.arXiv preprint arXiv:2305.16291(2023). arXiv:2305.16291
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Kin-Yeung Wong. 2006. Web cache replacement policies: a pragmatic approach. IEEE Network20, 1 (2006), 28–34
2006
-
[35]
Xiao Yang, Kai Sun, Hao Xin, Yushi Sun, Nikhil Bhalla, Xiangsen Chen, Sajal Choudhary, Rongze Daniel Gui, Ziran Will Jiang, Ziyu Jiang, Lingkun Kong, Brian Moran, Jiaqi Wang, Yifan Ethan Xu, An Yang, Eting Yuan, Hanwen Zha, Nan Tang, Lei Chen, Nicolas Scheffer, Yue Liu, Nirav Shah, Rakesh Wanga, Anuj Kumar, Wen-tau Yih, and Xin Luna Dong. 2024. CRAG – Com...
2024
- [36]
-
[37]
Yuxiang Zhang, Jiangming Shu, Ye Ma, Xueyuan Lin, Shangxi Wu, and Jitao Sang. 2025. Memory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks.arXiv preprint arXiv:2510.12635(2025). arXiv:2510.12635
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Zeyu Zhang et al. 2024. A Survey on the Memory Mechanism of Large Language Model Based Agents.arXiv preprint arXiv:2404.13501(2024). arXiv:2404.13501
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. Mem- oryBank: Enhancing Large Language Models with Long-Term Memory. InPro- ceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 19724–19731. https://ojs.aaai.org/index.php/AAAI/article/view/29946 13
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.