TactSpace: Learning a Physics-enriched Shared Latent Space for Tactile Sim-to-Real Transfer
Pith reviewed 2026-06-26 21:01 UTC · model grok-4.3
The pith
A shared latent space learned from simulated and real tactile signals enables zero-shot transfer without needing accurate raw-signal simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
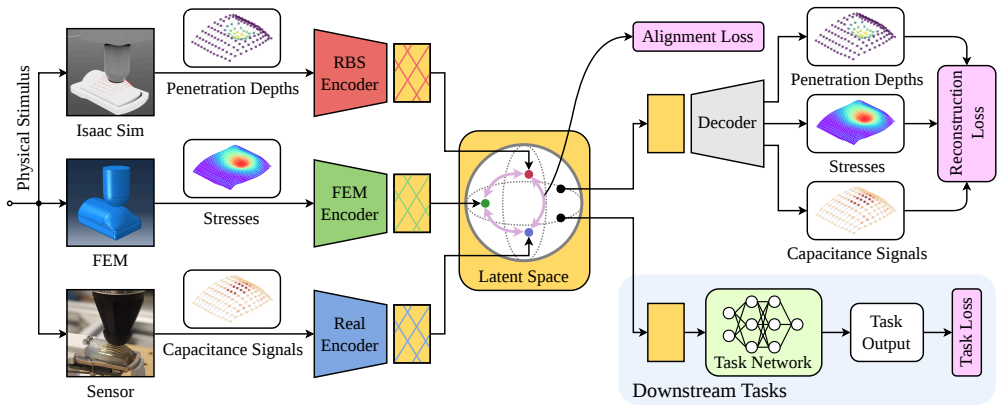
By projecting heterogeneous tactile observations into a shared latent space through modality-specific encoders trained with self- and cross-reconstruction objectives together with contrastive alignment, the resulting representations preserve contact information across simulation and reality, supporting zero-shot transfer and yielding lower error on downstream tasks when multi-physics simulation data are added.
What carries the argument
The shared latent space produced by self- and cross-reconstruction objectives combined with contrastive alignment between modality-specific encoders.
If this is right
- Zero-shot transfer succeeds across physically dissimilar tactile representations.
- Including multiple physics simulation modalities produces embeddings that improve performance on force prediction and shape reconstruction.
- The same embeddings support multiple downstream tasks after training exclusively in simulation.
- An efficient penalty-based tactile simulator released with the work allows scalable generation of the required training data.
Where Pith is reading between the lines
- The alignment technique could be applied to combine readings from several different physical tactile sensors into one model.
- Policies trained in the shared space might require less real-world data collection for contact-rich manipulation.
- The same reconstruction-plus-contrastive recipe could be tested on other mismatched sensor pairs, such as simulated versus real vision or audio.
Load-bearing premise
The reconstruction and contrastive objectives together create embeddings that keep the contact details needed for the downstream tasks even though the raw signals from simulation and reality remain physically dissimilar.
What would settle it
Train the model on simulation data only, then measure force-prediction or shape-reconstruction error on real tactile readings; if the error is no lower than a model trained without the shared-space alignment, the transfer claim does not hold.
Figures


read the original abstract
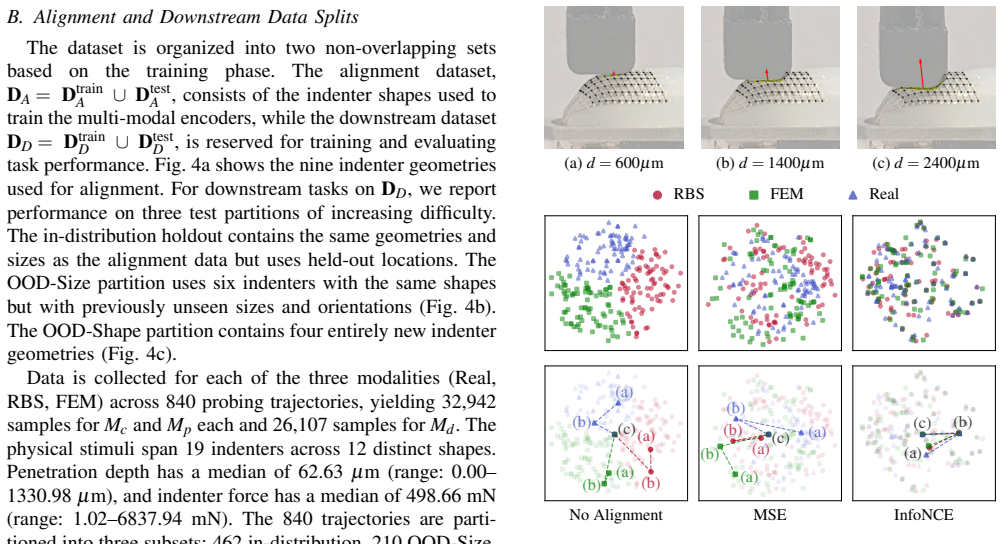
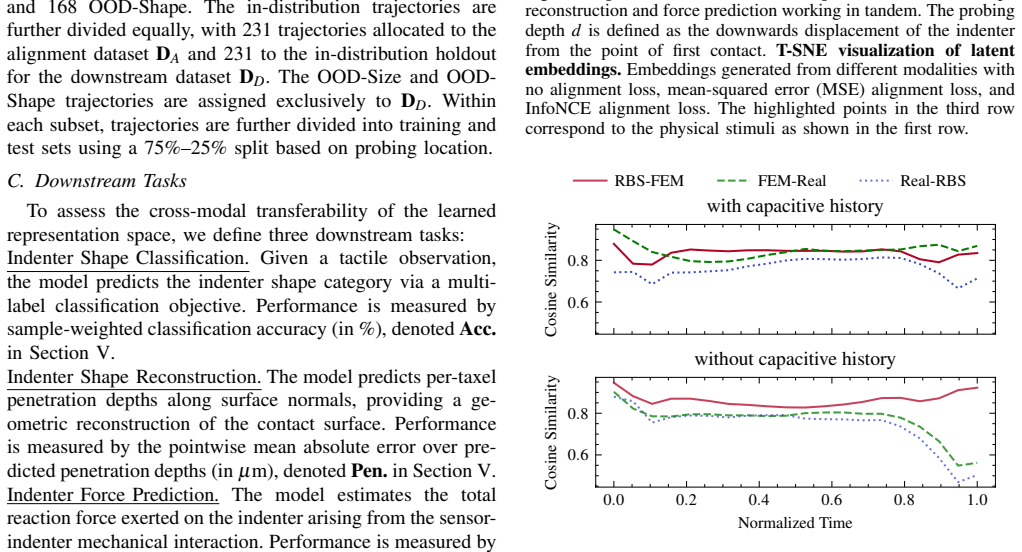
Tactile sensing provides direct measurements of contact interactions that are essential for robotic manipulation. However, current simulators lack the fidelity to faithfully model the complex deformation and transduction mechanics of tactile sensors, severely hindering sim-to-real transfer in robot learning pipelines. To address this challenge, we propose a multi-modal representation learning framework that aligns heterogeneous tactile modalities within a shared latent space, eliminating the need for accurate raw-signal simulation while preserving relevant contact information. Our approach employs modality-specific encoders to project diverse tactile observations, such as simulated penetration depth and real-world capacitance, into a common embedding space. The model is trained using self- and cross-reconstruction objectives alongside contrastive alignment, encouraging modality-invariant yet information-rich representations. We evaluate the learned embeddings on indenter shape identification, force prediction, and geometric reconstruction tasks, training exclusively in simulation and testing directly on real sensor measurements. Our results demonstrate zero-shot sim-to-real transfer across physically dissimilar representations. Furthermore, incorporating multi-physics simulation modalities yields more informative embeddings that transfer across diverse downstream tasks, demonstrating a 16.7% reduction in force prediction error and a 45.8% reduction in shape reconstruction error. Finally, we release an efficient Warp-based implementation of a penalty-based tactile simulation model for Isaac Lab, enabling scalable tactile data generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TactSpace, a multi-modal representation learning framework that projects heterogeneous tactile observations (simulated penetration depth and real-world capacitance) into a shared latent space via modality-specific encoders. Training uses self- and cross-reconstruction objectives together with contrastive alignment to produce modality-invariant embeddings. The model is trained exclusively in simulation and evaluated zero-shot on real sensor data for indenter shape identification, force prediction, and geometric reconstruction tasks, with reported error reductions when incorporating multi-physics simulation modalities. An efficient Warp-based penalty-based tactile simulator for Isaac Lab is also released.
Significance. If the zero-shot transfer claim holds without real data participating in training, the approach would offer a practical route to sim-to-real tactile transfer that sidesteps the need for high-fidelity raw-signal simulation. The release of the simulation implementation supports reproducibility and could benefit the broader robotics community working on contact-rich manipulation.
major comments (2)
- [Abstract] Abstract: The training description states that modality-specific encoders project both 'simulated penetration depth and real-world capacitance' and are optimized with self-/cross-reconstruction plus contrastive alignment, yet the evaluation explicitly claims 'training exclusively in simulation and testing directly on real sensor measurements.' This ambiguity directly undermines the zero-shot claim and requires a precise statement of which data modalities participate in the loss during training.
- [Abstract and §4] Abstract and §4 (results): The reported 16.7% reduction in force prediction error and 45.8% reduction in shape reconstruction error are presented without reference to specific baselines, dataset sizes, number of trials, statistical significance, or error bars. These omissions make it impossible to evaluate whether the quantitative improvements support the central transfer claim.
minor comments (1)
- [Abstract] Abstract: The phrase 'zero-shot sim-to-real transfer across physically dissimilar representations' would benefit from an explicit definition of what 'zero-shot' entails given the presence of a real-modality encoder.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below, clarifying the training protocol and committing to revisions that strengthen the presentation of results without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The training description states that modality-specific encoders project both 'simulated penetration depth and real-world capacitance' and are optimized with self-/cross-reconstruction plus contrastive alignment, yet the evaluation explicitly claims 'training exclusively in simulation and testing directly on real sensor measurements.' This ambiguity directly undermines the zero-shot claim and requires a precise statement of which data modalities participate in the loss during training.
Authors: We agree the abstract wording is imprecise and risks misinterpretation. The full manuscript trains the model exclusively on simulated data (including penetration depth and other multi-physics modalities) using self-reconstruction, cross-reconstruction, and contrastive losses; real-world capacitance data participates only in zero-shot evaluation for the downstream tasks. The phrase 'such as simulated penetration depth and real-world capacitance' was meant to illustrate the heterogeneous modalities the framework can handle in principle, not to indicate that real data enters the training loss. We will revise the abstract to explicitly state that training uses only simulated modalities and that real data is reserved for testing, thereby reinforcing the zero-shot claim. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (results): The reported 16.7% reduction in force prediction error and 45.8% reduction in shape reconstruction error are presented without reference to specific baselines, dataset sizes, number of trials, statistical significance, or error bars. These omissions make it impossible to evaluate whether the quantitative improvements support the central transfer claim.
Authors: The abstract summarizes quantitative gains whose supporting details (baseline methods, dataset sizes, number of trials, and error bars) appear in Section 4 and the associated figures/tables. We acknowledge that the abstract itself would benefit from additional context to allow readers to assess the improvements at a glance. We will revise the abstract to include a concise reference to the evaluation protocol (e.g., 'relative to baseline methods across N trials with reported standard deviations') and will ensure the results section already contains the requested statistical information is cross-referenced more explicitly. revision: partial
Circularity Check
No significant circularity in claimed sim-to-real transfer
full rationale
The paper presents an empirical multi-modal representation learning framework using modality-specific encoders, self-/cross-reconstruction losses, and contrastive alignment. Reported metrics (16.7% force error reduction, 45.8% shape reconstruction improvement) are stated as outcomes of experimental evaluation after training exclusively in simulation. No equations, derivations, or load-bearing steps reduce these results to fitted parameters by construction, self-citation chains, or self-definitional mappings. The zero-shot claim rests on external validation rather than tautological reduction to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Digit: A novel design for a low- cost compact high-resolution tactile sensor with application to in-hand manipulation,
M. Lambeta, P.-W. Chou,et al., “Digit: A novel design for a low- cost compact high-resolution tactile sensor with application to in-hand manipulation,”IEEE Robotics and Automation Letters (RA-L), vol. 5, no. 3, p. 3838–3845, July 2020
2020
-
[2]
Gelsight: High-resolution robot tactile sensors for estimating geometry and force,
W. Yuan, S. Dong, and E. H. Adelson, “Gelsight: High-resolution robot tactile sensors for estimating geometry and force,”Sensors, vol. 17, no. 12, 2017
2017
-
[3]
Printed synaptic transistor–based electronic skin for robots to feel and learn,
F. Liu, S. Deswal,et al., “Printed synaptic transistor–based electronic skin for robots to feel and learn,”Science Robotics, vol. 7, no. 67, p. eabl7286, 2022
2022
-
[4]
Artificial fingertip with embed- ded fiber-shaped sensing arrays for high resolution tactile sensing,
J. Weichart, P. Sivananthaguru,et al., “Artificial fingertip with embed- ded fiber-shaped sensing arrays for high resolution tactile sensing,” Soft Robotics, vol. 11, no. 4, pp. 573–584, 2024, pMID: 38662448
2024
-
[5]
Extended tactile perception: Vi- bration sensing through tools and grasped objects,
T. Taunyazov, L. S. Song,et al., “Extended tactile perception: Vi- bration sensing through tools and grasped objects,” inProc. of the IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), 2021, pp. 1755–1762
2021
-
[6]
Grip stabilization of novel objects using slip prediction,
F. Veiga, J. Peters, and T. Hermans, “Grip stabilization of novel objects using slip prediction,”IEEE Transactions on Haptics, vol. 11, no. 4, pp. 531–542, 2018
2018
-
[7]
Multimodal zero-shot learning for tactile texture recognition,
G. Cao, J. Jiang,et al., “Multimodal zero-shot learning for tactile texture recognition,”Robotics and Autonomous Systems, vol. 176, p. 104688, 2024
2024
-
[8]
Spatio-temporal attention model for tactile texture recognition,
G. Cao, Y . Zhou,et al., “Spatio-temporal attention model for tactile texture recognition,” inProc. of the IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), 2020, pp. 9896–9902
2020
-
[9]
Tactile robotics: An outlook,
S. Luo, N. F. Lepora,et al., “Tactile robotics: An outlook,”IEEE Transactions on Robotics (T-RO), vol. 41, pp. 5564–5583, 2025
2025
-
[10]
Anyrotate: Gravity-invariant in-hand object rotation with sim-to-real touch,
M. Yang, C. Lu,et al., “Anyrotate: Gravity-invariant in-hand object rotation with sim-to-real touch,” inConference on Robot Learning (CoRL), vol. 270. PMLR, 2024, pp. 4727–4747
2024
-
[11]
General in-hand object rotation with vision and touch,
H. Qi, B. Yi,et al., “General in-hand object rotation with vision and touch,” inConference on Robot Learning. PMLR, 2023, pp. 2549– 2564
2023
-
[12]
Taxim: An example-based simulation model for gelsight tactile sensors,
Z. Si and W. Yuan, “Taxim: An example-based simulation model for gelsight tactile sensors,”IEEE Robotics and Automation Letters (RA- L), vol. 7, no. 2, pp. 2361–2368, 2022
2022
-
[13]
Fots: A fast optical tactile simulator for sim2real learning of tactile-motor robot manipulation skills,
Y . Zhao, K. Qian,et al., “Fots: A fast optical tactile simulator for sim2real learning of tactile-motor robot manipulation skills,”IEEE Robotics and Automation Letters, vol. 9, no. 6, pp. 5647–5654, 2024
2024
-
[14]
Representation learning with contrastive predictive coding,
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[15]
Isaac lab: A gpu-accelerated simu- lation framework for multi-modal robot learning,
M. Mittal, P. Roth,et al., “Isaac lab: A gpu-accelerated simu- lation framework for multi-modal robot learning,”arXiv preprint arXiv:2511.04831, 2025
Pith/arXiv arXiv 2025
-
[16]
Smith,ABAQUS/Standard User’s Manual, Version 6.9
M. Smith,ABAQUS/Standard User’s Manual, Version 6.9. United States: Dassault Syst `emes Simulia Corp, 2009
2009
-
[17]
Simulation of optical tactile sensors supporting slip and rotation using path tracing and impm,
Z. Shen, Y . Sun,et al., “Simulation of optical tactile sensors supporting slip and rotation using path tracing and impm,”IEEE Robotics and Automation Letters (RA-L), vol. 9, pp. 11 218–11 225, 2024
2024
-
[18]
Tacsl: A library for visuotactile sensor simulation and learning,
I. Akinola, J. Xu,et al., “Tacsl: A library for visuotactile sensor simulation and learning,”IEEE Transactions on Robotics (T-RO), vol. 41, pp. 2645–2661, 2025
2025
-
[19]
Taccel: Scaling up vision-based tactile robotics via high-performance GPU simulation,
Y . Li, W. Du,et al., “Taccel: Scaling up vision-based tactile robotics via high-performance GPU simulation,” inNeural Information Pro- cessing Systems (NeurIPS), 2025
2025
-
[20]
B. Chen, W. Wan,et al., “Univtac: A unified simulation platform for visuo-tactile manipulation data generation, learning, and benchmark- ing,”arXiv preprint arXiv:2602.10093, 2026
arXiv 2026
-
[21]
Elastic tactile simulation towards tactile- visual perception,
Y . Wang, W. Huang,et al., “Elastic tactile simulation towards tactile- visual perception,” inProc. of ACM International Conference on Multimedia, 2021, pp. 2690–2698
2021
-
[22]
Tactile sim-to-real policy transfer via real- to-sim image translation,
A. Church, J. Lloyd,et al., “Tactile sim-to-real policy transfer via real- to-sim image translation,” inConference on Robot Learning (CoRL), vol. 164. PMLR, 2021, pp. 1645–1654
2021
-
[23]
Tactgen: Tactile sensory data generation via zero-shot sim-to-real transfer,
S. Zhong, A. Albini,et al., “Tactgen: Tactile sensory data generation via zero-shot sim-to-real transfer,”IEEE Transactions on Robotics (T- RO), vol. 41, pp. 1316–1328, 2025
2025
-
[24]
Binding touch to everything: Learning unified multimodal tactile representations,
F. Yang, C. Feng,et al., “Binding touch to everything: Learning unified multimodal tactile representations,” inProc. of the Conf. on Computer Vision and Pattern Recognition (CVPR). IEEE, 2024, pp. 26 330– 26 343
2024
-
[25]
Multimodal visual-tactile rep- resentation learning through self-supervised contrastive pre-training,
V . Dave, F. Lygerakis, and E. Rueckert, “Multimodal visual-tactile rep- resentation learning through self-supervised contrastive pre-training,” inProc. of the IEEE Int. Conf. on Robotics and Automation (ICRA). IEEE, 2024, pp. 8013–8020
2024
-
[26]
Multi-modal representation learning with tactile data,
H.-G. Chi, J. Barreiros,et al., “Multi-modal representation learning with tactile data,” inProc. of the IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 9660–9667
2024
-
[27]
Contrastive touch-to-touch pretraining,
S. Rodriguez, Y . Dou,et al., “Contrastive touch-to-touch pretraining,” inProc. of the IEEE Int. Conf. on Robotics and Automation (ICRA). IEEE, 2025, pp. 5857–5863
2025
-
[28]
Touch and go: Learning from human- collected vision and touch,
F. Yang, C. Ma,et al., “Touch and go: Learning from human- collected vision and touch,” inNeural Information Processing Systems (NeurIPS), vol. 35, 2022, pp. 8081–8103
2022
-
[29]
M2curl: Sample-efficient multimodal reinforcement learning via self-supervised representation learning for robotic manipulation,
F. Lygerakis, V . Dave, and E. Rueckert, “M2curl: Sample-efficient multimodal reinforcement learning via self-supervised representation learning for robotic manipulation,” inInt. Conf. on Ubiquitous Robots (UR). IEEE, 2024, pp. 490–497
2024
-
[30]
Upvital: Unpaired visual-tactile self-supervised representation learning for dexterous robotic manipulation,
G. Han, Q. Liu,et al., “Upvital: Unpaired visual-tactile self-supervised representation learning for dexterous robotic manipulation,” inProc. of the IEEE Int. Conf. on Robotics and Automation (ICRA). IEEE, 2025, pp. 11 838–11 844
2025
-
[31]
Vitacformer: Learning cross-modal rep- resentation for visuo-tactile dexterous manipulation,
L. Heng, H. Geng,et al., “Vitacformer: Learning cross-modal rep- resentation for visuo-tactile dexterous manipulation,”arXiv preprint arXiv:2506.15953, 2025
Pith/arXiv arXiv 2025
-
[32]
Sim-to-real for robotic tactile sensing via physics-based simulation and learned latent projections,
Y . Narang, B. Sundaralingam,et al., “Sim-to-real for robotic tactile sensing via physics-based simulation and learned latent projections,” inProc. of the IEEE Int. Conf. on Robotics and Automation (ICRA). IEEE, 2021, pp. 6444–6451
2021
-
[33]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer,et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” inInt. Conf. on Learning Representations (ICLR), 2021
2021
-
[34]
Efficient tactile simulation with differentiability for robotic manipulation,
J. Xu, S. Kim,et al., “Efficient tactile simulation with differentiability for robotic manipulation,” inConference on Robot Learning (CoRL), vol. 205. PMLR, 14–18 Dec 2023, pp. 1488–1498
2023
-
[35]
Visualizing data using t-sne,
L. van der Maaten and G. Hinton, “Visualizing data using t-sne,” Journal of Machine Learning (JMLR), vol. 9, no. 86, pp. 2579–2605, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.