Dimensionality Controls When Modularity Helps in Continual Learning
Pith reviewed 2026-06-27 01:13 UTC · model grok-4.3
The pith
Modularity improves continual learning only in low-dimensional regimes induced by small initial weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
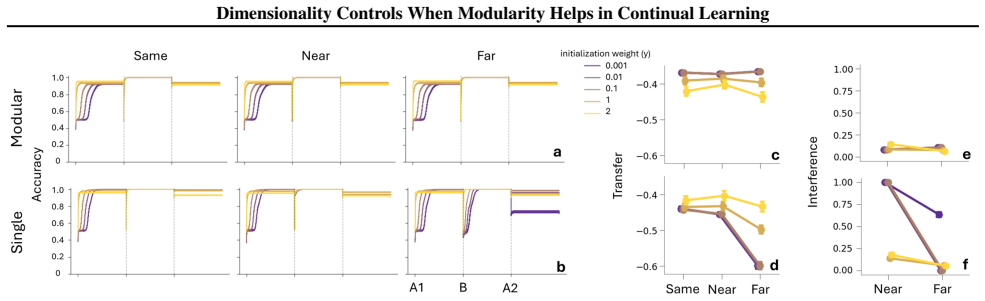
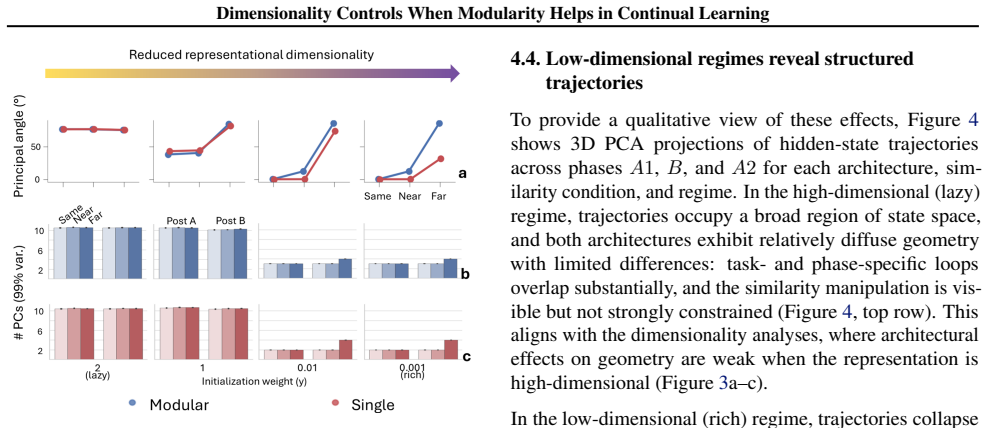
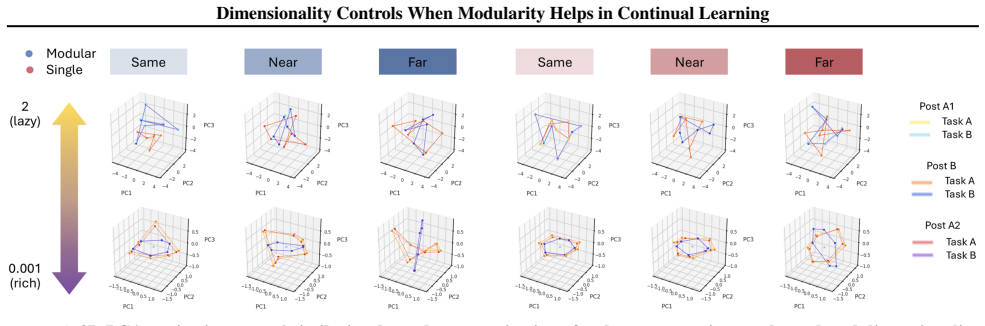
In the lower-dimensional rich regime the modular network develops graded task-specific subspaces that overlap for similar tasks, partially align for moderately dissimilar tasks, and separate for dissimilar tasks, producing a more compositional and interpretable organization than the single network; in the high-dimensional lazy regime both architectures achieve similar performance and internal geometry, indicating that explicit modular structure has little impact when representations are weakly constrained.
What carries the argument
Representational regime induced by initialization scale, which co-varies with dimensionality and controls whether the task-partitioned recurrent network forms adaptive, similarity-graded subspaces.
If this is right
- Explicit modular structure provides no functional advantage in high-dimensional lazy regimes.
- Modular networks produce more compositional task organizations than single networks when dimensionality is low.
- The benefit of modularity is governed by the regime induced by weight scale rather than by architecture alone.
- Safety and robustness can be reframed as problems of adaptive allocation of representational subspaces.
Where Pith is reading between the lines
- The same regime dependence may appear in non-recurrent architectures if low dimensionality can be enforced by other means.
- Single networks might be made to approximate the modular subspace pattern if trained under explicit low-dimensional constraints.
- Task similarity could be used as a diagnostic to predict when adding modularity will be worth the added complexity.
Load-bearing premise
That manipulating initialization scale cleanly induces distinct high- versus low-dimensional representational regimes without introducing other uncontrolled differences in optimization dynamics or capacity.
What would settle it
An experiment that varies initialization scale while holding measured representational dimensionality fixed and checks whether the performance gap and subspace organization differences between modular and single networks disappear.
Figures
read the original abstract
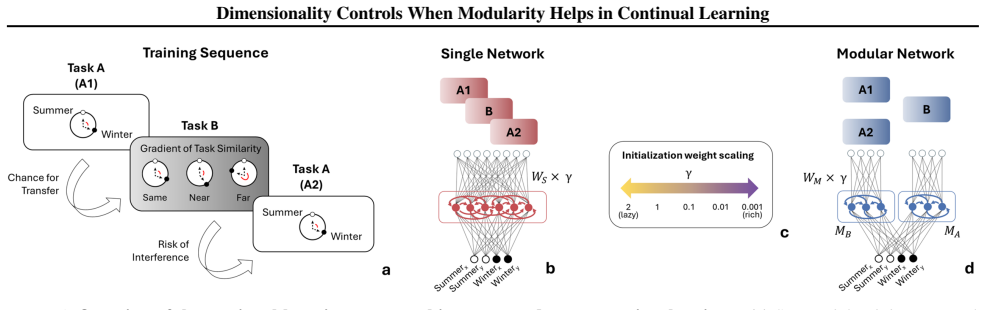
Compositional learning systems must balance plasticity, the ability to acquire new knowledge, with stability, the preservation of previously learned components, especially when tasks share structure and risk interference. We study how modular architecture, task similarity, and representational dimensionality jointly shape compositional continual learning in a sequential A-B-A paradigm, comparing a task-partitioned recurrent network to a single-network baseline while inducing high- and low-dimensional regimes via weight-scale manipulations. In a high-dimensional "lazy" regime, both architectures achieve similar performance and internal geometry, suggesting that explicit modular structure has little impact when representations are weakly constrained. In a lower-dimensional "rich" regime, modularity becomes decisive: the modular network develops graded task-specific subspaces that overlap for similar tasks, partially align for moderately dissimilar tasks, and separate for dissimilar tasks, yielding a more compositional and interpretable organization than the single network. These findings identify the representational regime induced by initialization scale, which co-varies with representational dimensionality, as a key factor governing when compositional, modular structure is functionally beneficial in continual learning, and support viewing safety and robustness as problems of adaptive allocation of representational subspaces rather than fixed separation versus sharing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies the joint effects of modular architecture, task similarity, and representational dimensionality on compositional continual learning in a sequential A-B-A paradigm. It compares a task-partitioned recurrent network against a single-network baseline, using weight-scale manipulations at initialization to induce high-dimensional 'lazy' and low-dimensional 'rich' regimes. The central claim is that modularity has negligible impact in the lazy regime but becomes decisive in the rich regime, where the modular network forms graded task-specific subspaces (overlapping for similar tasks, partially aligned for moderately dissimilar tasks, and separated for dissimilar tasks) that yield more compositional and interpretable representations than the single network.
Significance. If the results hold after addressing potential confounds, the work provides a concrete empirical link between initialization-induced representational regime and the functional benefit of explicit modularity, reframing plasticity-stability issues and robustness as problems of adaptive subspace allocation. The direct comparison of internal geometries across architectures and regimes is a strength of the study.
major comments (1)
- [Abstract / Methods] Abstract and Methods (weight-scale manipulation): The central attribution of the modular advantage to dimensionality per se is load-bearing, yet the initialization-scale manipulation simultaneously alters gradient magnitudes, effective step sizes, and the relative rates of feature versus kernel evolution. These dynamical effects need not be matched between the task-partitioned recurrent network and the single-network baseline; without explicit controls or analysis demonstrating that the observed subspace geometry differences survive such matching, the causal claim that dimensionality (rather than uncontrolled optimization differences) governs when modularity helps cannot be sustained.
minor comments (1)
- [Abstract] Abstract: The description of how dimensionality is quantified and verified (e.g., via effective dimension, participation ratio, or similar) is not provided, making it difficult to assess the regime separation.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for the detailed comment. We address the concern regarding the weight-scale manipulation below.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods (weight-scale manipulation): The central attribution of the modular advantage to dimensionality per se is load-bearing, yet the initialization-scale manipulation simultaneously alters gradient magnitudes, effective step sizes, and the relative rates of feature versus kernel evolution. These dynamical effects need not be matched between the task-partitioned recurrent network and the single-network baseline; without explicit controls or analysis demonstrating that the observed subspace geometry differences survive such matching, the causal claim that dimensionality (rather than uncontrolled optimization differences) governs when modularity helps cannot be sustained.
Authors: We agree that the initialization-scale manipulation affects multiple factors beyond dimensionality, including gradient magnitudes, effective step sizes, and the relative rates of feature versus kernel evolution, and that these may differ between the task-partitioned recurrent network and the single-network baseline. Our experiments apply the same scale to both architectures to induce the lazy versus rich regimes, but we do not include explicit matching or controls for the dynamical quantities. The manuscript's central claim is that modularity confers a benefit specifically in the low-dimensional rich regime induced by the manipulation (as opposed to the high-dimensional lazy regime), with the observed differences in subspace geometry. In the revised manuscript we will add a dedicated paragraph in the Discussion (and a brief note in Methods) acknowledging this confound, clarifying that our conclusions apply to the regimes as induced rather than to dimensionality in isolation, and discussing why the architecture-by-regime interaction remains informative even without full dynamical matching. We will also note this as a limitation and outline how future work could address it with additional controls. revision: partial
Circularity Check
Empirical comparison with no load-bearing derivations or self-referential steps
full rationale
The paper reports results from controlled simulations comparing task-partitioned recurrent networks against single-network baselines under high- versus low-dimensional regimes induced by initialization scale. The abstract and described claims consist of observational statements about performance and internal geometry (graded subspaces, overlap patterns) without any mathematical derivation chain, parameter fitting presented as prediction, or self-citation invoked as uniqueness theorem. No equations or steps reduce the central attribution (modularity decisive only in rich regime) to a tautology or fitted input by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Disentangling and mitigating the impact of task similarity for continual learning , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
arXiv preprint arXiv:2007.07400 , year=
Anatomy of catastrophic forgetting: Hidden representations and task semantics , author=. arXiv preprint arXiv:2007.07400 , year=
arXiv 2007
-
[3]
Neurobiology of Learning and Memory , volume=
The emergence of task-relevant representations in a nonlinear decision-making task , author=. Neurobiology of Learning and Memory , volume=. 2023 , publisher=
2023
-
[4]
Proceedings of the Royal Society b: Biological sciences , volume=
The evolutionary origins of modularity , author=. Proceedings of the Royal Society b: Biological sciences , volume=. 2013 , publisher=
2013
-
[5]
PLoS computational biology , volume=
Neural modularity helps organisms evolve to learn new skills without forgetting old skills , author=. PLoS computational biology , volume=. 2015 , publisher=
2015
-
[6]
Journal of cognitive neuroscience , volume=
Brain modularity mediates the relation between task complexity and performance , author=. Journal of cognitive neuroscience , volume=. 2017 , publisher=
2017
-
[7]
Neuron , volume=
Orthogonal representations for robust context-dependent task performance in brains and neural networks , author=. Neuron , volume=. 2022 , publisher=
2022
-
[8]
Nature Communications , year=
The effects of task similarity during representation learning in brains and neural networks , author=. Nature Communications , year=
-
[9]
International Conference on Machine Learning , pages=
Continual learning in the teacher-student setup: Impact of task similarity , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[10]
Nature Human Behaviour , volume=
Humans and neural networks show similar patterns of transfer and interference during continual learning , author=. Nature Human Behaviour , volume=. 2026 , publisher=
2026
-
[11]
Nature Communications , volume=
Dynamics of specialization in neural modules under resource constraints , author=. Nature Communications , volume=. 2025 , publisher=
2025
-
[12]
Proceedings of the national academy of sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the national academy of sciences , volume=. 2017 , publisher=
2017
-
[13]
Proceedings of the National Academy of Sciences , volume=
Alleviating catastrophic forgetting using context-dependent gating and synaptic stabilization , author=. Proceedings of the National Academy of Sciences , volume=. 2018 , publisher=
2018
-
[14]
NeurIPS 2025 AI for Science Workshop , year=
Dimensionality and Topological Stability of Neural Representations in the Human Brain Predict Learning Outcomes , author=. NeurIPS 2025 AI for Science Workshop , year=
2025
-
[15]
Connection Science , volume=
Catastrophic forgetting, rehearsal and pseudorehearsal , author=. Connection Science , volume=. 1995 , publisher=
1995
-
[16]
Advances in neural information processing systems , volume=
Experience replay for continual learning , author=. Advances in neural information processing systems , volume=
-
[17]
Nature communications , volume=
Brain-inspired replay for continual learning with artificial neural networks , author=. Nature communications , volume=. 2020 , publisher=
2020
-
[18]
bioRxiv , pages=
Impact of Task Similarity and Training Regimes on Cognitive Transfer and Interference , author=. bioRxiv , pages=. 2025 , publisher=
2025
-
[19]
Jeffrey and Fusi, Stefano , title =
Johnston, W. Jeffrey and Fusi, Stefano , title =. 2026 , doi =. https://www.biorxiv.org/content/early/2026/01/06/2024.09.30.615925.full.pdf , journal =
2026
-
[20]
Trends in cognitive sciences , volume=
Representational geometry: integrating cognition, computation, and the brain , author=. Trends in cognitive sciences , volume=. 2013 , publisher=
2013
-
[21]
Current opinion in neurobiology , volume=
Signatures of task learning in neural representations , author=. Current opinion in neurobiology , volume=. 2023 , publisher=
2023
-
[22]
2022 , school=
Representation learning for continual task performance , author=. 2022 , school=
2022
-
[23]
bioRxiv , year=
Modular representations emerge in neural networks trained to perform context-dependent tasks , author=. bioRxiv , year=
-
[24]
IEEE Transactions on Artificial Intelligence , volume=
Continual learning: A review of techniques, challenges, and future directions , author=. IEEE Transactions on Artificial Intelligence , volume=. 2023 , publisher=
2023
-
[25]
arXiv preprint arXiv:2506.03951 , year=
Rethinking the stability-plasticity trade-off in continual learning from an architectural perspective , author=. arXiv preprint arXiv:2506.03951 , year=
-
[26]
BioRxiv , pages=
Rich and lazy learning of task representations in brains and neural networks , author=. BioRxiv , pages=. 2021 , publisher=
2021
-
[27]
Science Advances , volume=
Emergence and reconfiguration of modular structure for artificial neural networks during continual familiarity detection , author=. Science Advances , volume=. 2024 , publisher=
2024
-
[28]
Nature Neuroscience , volume=
Leveraging insights from neuroscience to build adaptive artificial intelligence , author=. Nature Neuroscience , volume=. 2026 , publisher=
2026
-
[29]
International Conference on Learning Representations , volume=
How connectivity structure shapes rich and lazy learning in neural circuits , author=. International Conference on Learning Representations , volume=
-
[30]
Neuroimage , volume=
Network communication models narrow the gap between the modular organization of structural and functional brain networks , author=. Neuroimage , volume=. 2022 , publisher=
2022
-
[31]
Nature Machine Intelligence , volume=
Spatially embedded recurrent neural networks reveal widespread links between structural and functional neuroscience findings , author=. Nature Machine Intelligence , volume=. 2023 , publisher=
2023
-
[32]
Nature Neuroscience , pages=
Neural population geometry and optimal coding of tasks with shared latent structure , author=. Nature Neuroscience , pages=. 2026 , publisher=
2026
-
[33]
2026 , eprint=
Modularity is the Bedrock of Natural and Artificial Intelligence , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.