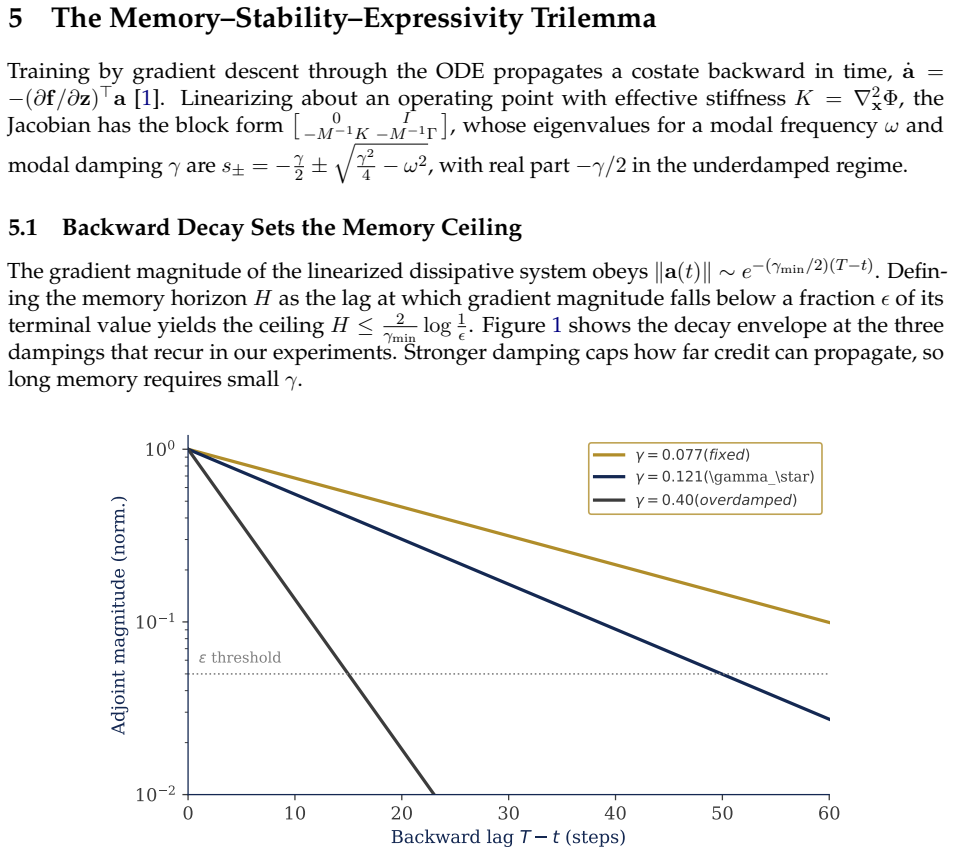
Between Amnesia and Chaos: A Memory Stability Expressivity Trilemma for Trainable Dissipative Oscillator Networks
Pith reviewed 2026-06-27 18:40 UTC · model grok-4.3
The pith
Damping in oscillator networks creates a trilemma limiting simultaneous gains in memory horizon, gradient stability, and dynamical expressivity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
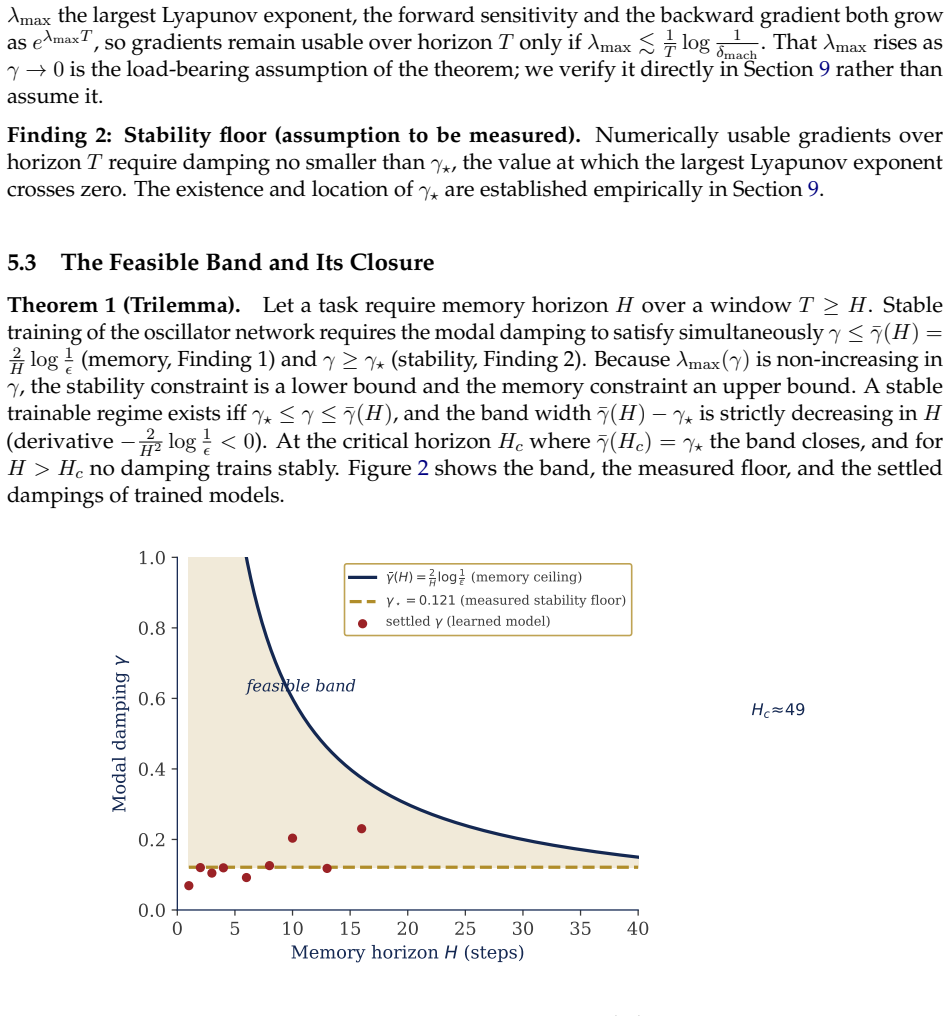
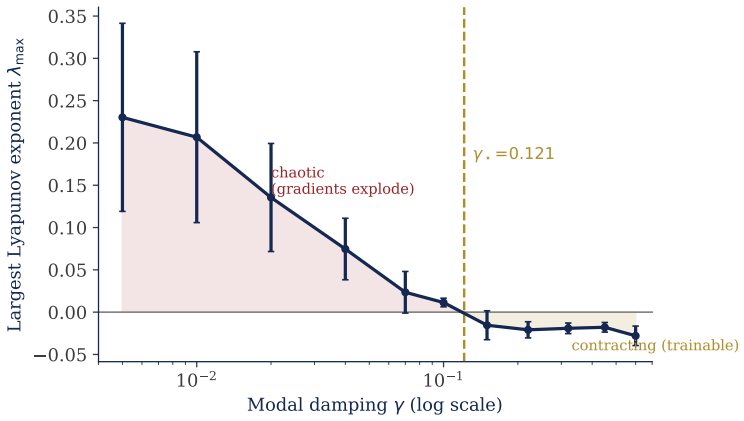
The central result is a trilemma: memory horizon, gradient stability, and dynamical expressivity cannot be simultaneously maximized, because all three are governed by the damping. The backward gradient decays at a rate set by the damping, capping how far back credit can propagate, while forward sensitivities grow exponentially in the largest Lyapunov exponent, so usable gradients require damping above a stability floor. Since the Lyapunov exponent falls as damping rises while the memory ceiling falls as the horizon grows, stable training is confined to a band that contracts with horizon and closes at a critical point.
What carries the argument
The damping coefficient, which sets the decay rate of backward gradients, the largest Lyapunov exponent of the forward dynamics, and the effective memory horizon of the network.
If this is right
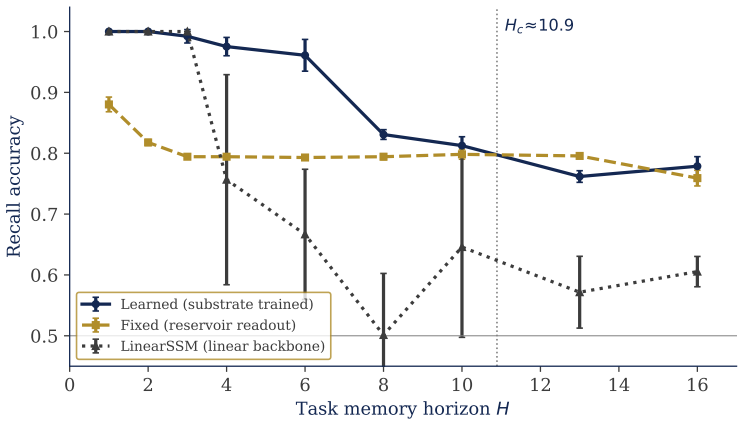
- Learned substrates outperform frozen ones at short horizons but the advantage closes and reverses near eleven steps.
- Trained models settle near the stability floor without external prompting.
- The analytic memory ceiling overestimates the empirical crossover by a factor of roughly five.
- Stable training remains possible only inside a damping band that contracts as the required horizon lengthens.
Where Pith is reading between the lines
- The reported gap between detectable and learnable gradients suggests that improved gradient estimators could widen the usable band.
- Similar damping-governed trade-offs may appear in other dissipative physical learning systems beyond oscillators.
- For tasks requiring horizons beyond the observed crossover, hybrid designs that freeze part of the substrate may remain preferable.
Load-bearing premise
The backward gradient decays at a rate set by the damping while forward sensitivities grow exponentially in the largest Lyapunov exponent, so usable gradients require damping above a stability floor and the Lyapunov exponent falls as damping rises.
What would settle it
An experiment in which a network trained at high damping and long memory horizon achieves both stable gradients and high expressivity without performance reversal would falsify the trilemma.
Figures
read the original abstract
Physical reservoir computing harnesses nonlinear mechanical dynamics but, by convention, freezes the substrate and trains only a linear readout, presuming the substrate is not usefully trainable. We revisit that premise for networks of nonlinear oscillators whose mass, damping, and stiffness are learned end-to-end through a symplectic integrator. Our central result is a trilemma: memory horizon, gradient stability, and dynamical expressivity cannot be simultaneously maximized, because all three are governed by the damping. The backward gradient decays at a rate set by the damping, capping how far back credit can propagate, while forward sensitivities grow exponentially in the largest Lyapunov exponent, so usable gradients require damping above a stability floor. Since the Lyapunov exponent falls as damping rises while the memory ceiling falls as the horizon grows, stable training is confined to a band that contracts with horizon and closes at a critical point. We test every step on a twenty-oscillator network. A damping sweep finds the largest Lyapunov exponent monotone and crossing zero at a well-defined stability floor, confirming the theorem's key assumption. A compute-matched comparison of learned versus frozen substrate on delayed recall across nine horizons shows the learned substrate dominating at short horizons and the advantage closing and reversing near a horizon of eleven steps, the predicted signature of band closure; trained models settle near the stability floor, seeking the edge of chaos unprompted. The analytic ceiling overestimates the empirical crossover roughly fivefold, a gap between detectable and learnable gradient that we report rather than tune away. The contribution is a confirmed account of when training a physical substrate beats freezing it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that trainable dissipative oscillator networks exhibit a trilemma in which memory horizon, gradient stability, and dynamical expressivity cannot be simultaneously maximized, as all three quantities are governed by the damping parameter. Backward gradient decay is set by damping while forward sensitivities grow with the largest Lyapunov exponent, confining stable training to a contracting band that closes at a critical horizon. Experiments on a twenty-oscillator network confirm that the largest Lyapunov exponent is monotone in damping and crosses zero at a stability floor; a compute-matched comparison on delayed recall shows the learned substrate advantage closing and reversing near horizon eleven, the predicted signature of band closure, although the analytic ceiling overestimates the empirical crossover by a factor of five.
Significance. If the central result holds, the work supplies a concrete, damping-based account of when end-to-end training of a physical substrate outperforms the conventional frozen-reservoir approach, backed by an explicit damping sweep and compute-matched baselines. The decision to report rather than adjust away the analytic-empirical gap is a methodological strength that keeps the contribution falsifiable.
major comments (1)
- [empirical validation of band closure] The factor-of-five mismatch between the analytic memory ceiling and the observed reversal at horizon 11 (reported in the empirical validation) is load-bearing for the claim that the trilemma is tightly controlled by damping alone; the manuscript should either derive a tighter bound that incorporates discretization or finite-precision effects or demonstrate that the qualitative band-closure signature remains robust under those perturbations.
Simulated Author's Rebuttal
We thank the referee for the constructive assessment and the recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [empirical validation of band closure] The factor-of-five mismatch between the analytic memory ceiling and the observed reversal at horizon 11 (reported in the empirical validation) is load-bearing for the claim that the trilemma is tightly controlled by damping alone; the manuscript should either derive a tighter bound that incorporates discretization or finite-precision effects or demonstrate that the qualitative band-closure signature remains robust under those perturbations.
Authors: The manuscript already reports the factor-of-five discrepancy explicitly, framing it as the distinction between the analytic (detectable-gradient) ceiling and the empirical (learnable-gradient) crossover rather than tuning parameters to eliminate the gap. This preserves falsifiability, consistent with the referee's positive significance assessment. Deriving a tighter bound that folds in discretization or finite-precision effects would require a substantially more technical analysis of the symplectic integrator and floating-point dynamics, which lies outside the current scope. Instead, we will add a concise paragraph to the discussion section that (i) reiterates the reported gap, (ii) notes that the qualitative band-closure signature—the learned-substrate advantage closing and reversing near horizon 11—remains robust across the full damping sweep and compute-matched baselines, and (iii) confirms that trained models spontaneously settle near the stability floor. This constitutes a partial revision focused on clarifying the robustness of the observed signature without claiming quantitative tightness. revision: partial
Circularity Check
No circularity: trilemma follows from explicit damping dependence of gradients and LE, confirmed by independent sweep and task tests
full rationale
The central derivation links memory horizon to backward gradient decay rate (set by damping), forward growth to largest Lyapunov exponent (which decreases with damping), and expressivity to the resulting stability band. This is obtained directly from the oscillator equations and symplectic integrator without fitting parameters to the target quantities or renaming known results. The damping sweep on the 20-oscillator network verifies monotonicity and zero-crossing of the LE as an external check; the delayed-recall comparison across horizons reports the observed reversal at horizon 11 and the 5x analytic overestimate without tuning or self-citation load-bearing steps. No self-definitional, fitted-input, or uniqueness-imported patterns appear; the account remains falsifiable against the reported empirical gap.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The backward gradient decays at a rate set by the damping, capping how far back credit can propagate.
- domain assumption Forward sensitivities grow exponentially in the largest Lyapunov exponent, requiring damping above a stability floor.
Reference graph
Works this paper leans on
-
[1]
Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David Duvenaud.Neural Ordinary Differential Equations. NeurIPS, 2018.https://arxiv.org/abs/1806.07366
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
arXiv preprint arXiv:2003.04630 , year=
Miles Cranmer, Sam Greydanus, Stephan Hoyer, Peter Battaglia, David Spergel, and Shirley Ho.Lagrangian Neural Networks. ICLR Deep Differential Equations Workshop, 2020. https: //arxiv.org/abs/2003.04630
-
[3]
NeurIPS, 2019.https://arxiv.org/abs/1906.01563
Sam Greydanus, Misko Dzamba, and Jason Yosinski.Hamiltonian Neural Networks. NeurIPS, 2019.https://arxiv.org/abs/1906.01563
-
[4]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher Ré.Efficiently Modeling Long Sequences with Structured State Spaces. ICLR, 2022.https://arxiv.org/abs/2111.00396
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao.Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv:2312.00752, 2023.https://arxiv.org/abs/2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Springer, 2nd edition, 2006
Ernst Hairer, Christian Lubich, and Gerhard Wanner.Geometric Numerical Integration: Structure- Preserving Algorithms for Ordinary Differential Equations. Springer, 2nd edition, 2006. 11
2006
-
[7]
Japanese Journal of Applied Physics, 59(6):060501, 2020.https://arxiv.org/abs/2005.00992
Kohei Nakajima.Physical Reservoir Computing: An Introductory Perspective. Japanese Journal of Applied Physics, 59(6):060501, 2020.https://arxiv.org/abs/2005.00992
-
[8]
Recent Advances in Physical Reservoir Computing: A Review
Gouhei Tanaka, Toshiyuki Yamane, Jean Benoit Héroux, Ryosho Nakane, Naoki Kanazawa, Seiji Takeda, Hidetoshi Numata, Daiju Nakano, and Akira Hirose.Recent Advances in Physical Reservoir Computing: A Review. Neural Networks, 115:100–123, 2019. https://arxiv.org/ abs/1808.04962. 12
work page internal anchor Pith review Pith/arXiv arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.