ReConFuse: Reconstruction-Error Guided Semantic Fusion for AI-Generated Video Detection
Pith reviewed 2026-06-28 07:11 UTC · model grok-4.3
The pith
Reconstruction errors from a pretrained VAE, fused with semantic features and temporal modeling, detect AI-generated videos with strong generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
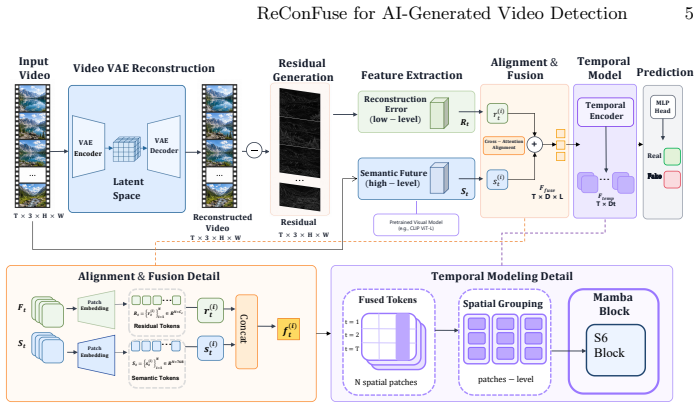
By reconstructing input videos with a pretrained WF-VAE, real and generated videos exhibit distinguishable frame-wise reconstruction error patterns. ReConFuse extracts reconstruction error cues from WF-VAE reconstructed videos, aligns them with multi-frame semantic features, and uses a Mamba-based module to model temporal evolution for video-level classification.
What carries the argument
ReConFuse framework that extracts reconstruction error cues from a fixed pretrained WF-VAE, aligns those cues with semantic features, and applies Mamba-based temporal modeling for classification.
Load-bearing premise
The frame-wise reconstruction errors produced by the fixed pretrained WF-VAE reliably expose distributional differences between real and generated videos that remain useful after semantic alignment and temporal modeling.
What would settle it
A new generator set where ReConFuse accuracy matches or falls below a semantic-only baseline that discards all reconstruction-error input.
Figures


read the original abstract
AI-generated videos are becoming increasingly realistic, raising serious concerns about misinformation, content authenticity, and media trust. Reliable AI-generated video detection is therefore essential for multimedia forensics, yet remains challenging due to the need to capture spatial artifacts, temporal dynamics, and generalize to evolving generative models. In this paper, we explore reconstruction error as a discriminative forensic cue for AI-generated video detection. By reconstructing input videos with a pretrained WF-VAE, we observe that real and generated videos exhibit distinguishable frame-wise reconstruction error patterns, suggesting that reconstruction errors can reveal their distributional discrepancies. However, extending reconstruction-based image detection to videos is non-trivial, since video reconstruction errors are temporally organized across frames and require semantic context for effective interpretation. To address these challenges, we propose ReConFuse, a reconstruction-guided semantic fusion framework for video-level AI-generated video detection. ReConFuse extracts reconstruction error cues from WF-VAE reconstructed videos, aligns them with multi-frame semantic features, and uses a Mamba-based module to model temporal evolution for video-level classification. Experiments across multiple generators and evaluation settings demonstrate the effectiveness and strong generalization ability of ReConFuse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ReConFuse, a reconstruction-guided semantic fusion framework for AI-generated video detection. It extracts frame-wise reconstruction error cues using a fixed pretrained WF-VAE, aligns these errors with multi-frame semantic features, and applies a Mamba-based temporal modeling module to produce video-level classifications. The central claim is that experiments across multiple generators and evaluation settings demonstrate the method's effectiveness and strong generalization ability.
Significance. If the empirical claims are substantiated with quantitative evidence, the approach could introduce a useful forensic cue based on reconstruction discrepancies that captures distributional differences between real and generated videos, potentially aiding generalization to unseen generators in multimedia forensics.
major comments (1)
- [Abstract] Abstract: The assertion that 'experiments across multiple generators and evaluation settings demonstrate the effectiveness and strong generalization ability of ReConFuse' is presented without any quantitative results, baselines, ablation studies, dataset descriptions, or error analysis. This is load-bearing for the paper's central empirical contribution, as the soundness of the method cannot be assessed from the provided text.
minor comments (2)
- The description of how reconstruction errors are aligned with semantic features and fed into the Mamba module would benefit from explicit equations or pseudocode to clarify the fusion process.
- Pretraining details and architecture of the WF-VAE (e.g., whether it remains completely fixed during inference) should be stated more precisely to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment. We address the concern regarding the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'experiments across multiple generators and evaluation settings demonstrate the effectiveness and strong generalization ability of ReConFuse' is presented without any quantitative results, baselines, ablation studies, dataset descriptions, or error analysis. This is load-bearing for the paper's central empirical contribution, as the soundness of the method cannot be assessed from the provided text.
Authors: We acknowledge that the abstract, as currently written, summarizes the empirical claims at a high level without including specific quantitative metrics. The full manuscript (Sections 4 and 5) contains the requested details: quantitative results across multiple generators (e.g., accuracy, AUC on held-out generators), comparisons to baselines, ablation studies on the fusion and Mamba components, dataset descriptions, and error analysis. To address the referee's point directly, we will revise the abstract to incorporate key quantitative highlights (e.g., performance gains and generalization metrics) while remaining within length limits. This revision will make the central claim more self-contained. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes a pipeline that extracts frame-wise reconstruction errors from a fixed pretrained WF-VAE, aligns those errors with multi-frame semantic features, and applies a Mamba-based temporal module for video-level classification. No equations, fitting procedures, or derivation steps are presented that would reduce any claimed result to its own inputs by construction. The central claims rest on empirical experiments across generators rather than self-definitional mappings, fitted inputs renamed as predictions, or load-bearing self-citations. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: IEEE International Workshop on Information Foren- sics and Security
Afchar, D., Nozick, V., Yamagishi, J., Echizen, I.: Mesonet: A compact facial video forgery detection network. In: IEEE International Workshop on Information Foren- sics and Security. pp. 1–7 (2018)
2018
-
[2]
arXiv preprint arXiv:1803.01271 (2018)
Bai, S., Kolter, J.Z., Koltun, V.: An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv preprint arXiv:1803.01271 (2018)
Pith/arXiv arXiv 2018
-
[3]
Bertasius, G., Wang, H., Torresani, L.: Is space-time attention all you need for video understanding? In: International Conference on Machine Learning. pp. 813– 824 (2021)
2021
-
[4]
In: arXiv preprint arXiv:2311.15127 (2023)
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., Jampani, V., Rombach, R.: Stable video diffusion: Scaling latent video diffusion models to large datasets. In: arXiv preprint arXiv:2311.15127 (2023)
Pith/arXiv arXiv 2023
-
[5]
Chang, C., Liu, Z., Lyu, X., Qi, X.: What matters in detecting ai-generated videos like Sora? arXiv preprint arXiv:2406.19568 (2024)
arXiv 2024
-
[6]
In: arXiv preprint arXiv:2405.19707 (2024)
Chen, Y., Li, J., Zhang, X., Liu, H., Wang, W., Li, W.: Demamba: Ai- generated video detection on million-scale genvideo benchmark. In: arXiv preprint arXiv:2405.19707 (2024)
arXiv 2024
-
[7]
In: Fifth Message Un- derstanding Conference (1993)
Chinchor, N., Sundheim, B.M.: MUC-5 evaluation metrics. In: Fifth Message Un- derstanding Conference (1993)
1993
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chu, B., Xu, X., Wang, X., Zhang, Y., You, W., Zhou, L.: FIRE: Robust de- tection of diffusion-generated images via frequency-guided reconstruction error. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12830–12839 (2025)
2025
-
[9]
Data Intelligence 6(4), 968–993 (2024)
Dai, X., Yu, Z., Hiang, C., Gao, C., He, Q., Wu, D., Xu, Z.: Detecting novel malware classes with a foundational multi-modality data analysis model. Data Intelligence 6(4), 968–993 (2024). https://doi.org/10.3724/2096-7004.di.2024.0056
-
[10]
In: arXiv preprint arXiv:2006.07397 (2020) ReConFuse for AI-Generated Video Detection 13
Dolhansky, B., Bitton, J., Pflaum, B., Lu, J., Howes, R., Wang, M., Ferrer, C.C.: The deepfake detection challenge dataset. In: arXiv preprint arXiv:2006.07397 (2020) ReConFuse for AI-Generated Video Detection 13
Pith/arXiv arXiv 2006
-
[11]
Data Intelli- gence7(4), 1169–1191 (2025)
Gao, X., Chen, W., Cui, Y., Dai, X., Dai, L.: Progressive adversarial contrastive learning: Towards efficient data augmentation in adversarial defense. Data Intelli- gence7(4), 1169–1191 (2025). https://doi.org/10.3724/2096-7004.di.2025.0190
-
[12]
In: International Conference on Learning Representations (2024)
Gu, A., Dao, T.: Mamba: Linear-time sequence modeling with selective state spaces. In: International Conference on Learning Representations (2024)
2024
-
[13]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 770–778 (2016)
2016
-
[14]
In: arXiv preprint arXiv:2210.02303 (2022)
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J., Salimans, T.: Imagen video: High definition video generation with diffusion models. In: arXiv preprint arXiv:2210.02303 (2022)
Pith/arXiv arXiv 2022
-
[15]
Neural Computation 9(8), 1735–1780 (1997)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Computation 9(8), 1735–1780 (1997)
1997
-
[16]
IEEE Transactions on Knowledge and Data Engineering17(3), 299–310 (2005)
Huang, J., Ling, C.X.: Using AUC and accuracy in evaluating learning algorithms. IEEE Transactions on Knowledge and Data Engineering17(3), 299–310 (2005)
2005
-
[17]
arXiv preprint arXiv:1705.06950 (2017)
Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T., Natsev, P., et al.: The kinetics human action video dataset. arXiv preprint arXiv:1705.06950 (2017)
Pith/arXiv arXiv 2017
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, L., Bao, J., Zhang, T., Yang, H., Chen, D., Wen, F., Guo, B.: Face x-ray for more general face forgery detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5001–5010 (2020)
2020
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, Y., Yang, X., Sun, P., Qi, H., Lyu, S.: Celeb-df: A large-scale challenging dataset for deepfake forensics. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3207–3216 (2020)
2020
-
[20]
Li, Z., Lin, B., Ye, Y., Chen, L., Cheng, X., Yuan, S., Yuan, L.: WF-VAE: Enhanc- ing video VAE by wavelet-driven energy flow for latent video diffusion model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition. pp. 17778–17788 (2025). https://doi.org/10.1109/CVPR52734.2025.01656
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Z., Ning, J., Cao, Y., Wei, Y., Zhang, Z., Lin, S., Hu, H.: Video swin trans- former. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3202–3211 (2022)
2022
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Luo, Y., Du, J., Yan, K., Ding, S.: LaRE 2: Latent reconstruction error based method for diffusion-generated image detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[23]
In: European Conference on Computer Vision
Ni, B., Peng, H., Chen, M., Zhang, S., Meng, G., Fu, J., Xiang, S., Ling, H.: Expanding language-image pretrained models for general video recognition. In: European Conference on Computer Vision. pp. 1–18 (2022)
2022
-
[24]
In: Pro- ceedings of the AAAI Conference on Artificial Intelligence (2026)
Ni, Z., Yan, Q., Huang, M., Yuan, T., Tang, Y., Hu, H., Chen, X., Wang, Y.: GenVidBench: A challenging benchmark for detecting ai-generated video. In: Pro- ceedings of the AAAI Conference on Artificial Intelligence (2026)
2026
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ojha, U., Li, Y., Lee, Y.J.: Towards universal fake image detectors that gener- alize across generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 24480–24489 (2023)
2023
-
[26]
OpenAI Technical Report (2024), https://openai.com/research/video-generation-models-as-world-simulators
OpenAI: Video generation models as world simulators. OpenAI Technical Report (2024), https://openai.com/research/video-generation-models-as-world-simulators
2024
-
[28]
arXiv preprint arXiv:2402.13126 (2024) 14 X
Pang, Y., Zhang, Y., Wang, T.: VGMShield: Mitigating misuse of video generative models. arXiv preprint arXiv:2402.13126 (2024) 14 X. Chen et al
arXiv 2024
-
[29]
Data Intelligence7(2), 358– 380 (2025)
Qin, Y., Xie, H., Li, Y., Tan, B., Ding, S.: Enhancing intermodal interaction for unified vision-language understanding and generation. Data Intelligence7(2), 358– 380 (2025). https://doi.org/10.3724/2096-7004.di.2025.0034
-
[30]
In: International Conference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning. pp. 8748–8763 (2021)
2021
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ricker, J., Lukovnikov, D., Fischer, A.: Aeroblade: Training-free detection of latent diffusion images using autoencoder reconstruction error. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9130– 9140 (2024)
2024
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10684–10695 (2022)
2022
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Rossler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J., Nießner, M.: Face- forensics++: Learning to detect manipulated facial images. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1–11 (2019)
2019
-
[34]
In: International Conference on Learning Representations (2023)
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., Parikh, D., Gupta, S., Taigman, Y.: Make-a-video: Text-to- video generation without text-video data. In: International Conference on Learning Representations (2023)
2023
-
[35]
In: Advances in Neural Information Processing Systems (2024)
Song, X., Guo, X., Zhang, J., Li, Q., Bai, L., Liu, X., Zhai, G., Liu, X.: On learn- ing multi-modal forgery representation for diffusion generated video detection. In: Advances in Neural Information Processing Systems (2024)
2024
-
[36]
In: Advances in Neural Information Processing Systems
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems. pp. 5998–6008 (2017)
2017
-
[37]
In: International Conference on Learning Representations (2023)
Villegas, R., Babaeizadeh, M., Kindermans, P.J., Moraldo, H., Zhang, H., Saffar, M., Castro, S., Kunze, J., Erhan, D.: Phenaki: Variable length video generation from open domain textual description. In: International Conference on Learning Representations (2023)
2023
-
[38]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
Wang, Z., Bao, J., Zhou, W., Wang, W., Hu, H., Chen, H., Li, H.: Dire for diffusion- generated image detection. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 22445–22455 (2023)
2023
-
[39]
arXiv preprint arXiv:2505.12620 (2025)
Wen, H., He, Y., Huang, Z., Li, T., Yu, Z., Huang, X., Qi, L., Wu, B., Li, X., Cheng, G.: Busterx: Mllm-powered ai-generated video forgery detection and explanation. arXiv preprint arXiv:2505.12620 (2025)
Pith/arXiv arXiv 2025
-
[40]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Xu, J., Mei, T., Yao, T., Rui, Y.: MSR-VTT: A large video description dataset for bridging video and language. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 5288–5296 (2016)
2016
-
[41]
In: Advances in Neural Information Processing Systems (2025)
Zhang, S., Lian, Z., Yang, J., Li, D., Pang, G., Liu, F., Han, B., Li, S., Tan, M.: Physics-driven spatiotemporal modeling for ai-generated video detection. In: Advances in Neural Information Processing Systems (2025)
2025
-
[42]
In: arXiv preprint arXiv:2508.00701 (2025)
Zheng, C., Suo, R., Lin, C., Zhao, Z., Yang, L., Liu, S., Yang, M., Wang, C., Shen, C.: D3: Training-free ai-generated video detection using second-order features. In: arXiv preprint arXiv:2508.00701 (2025)
arXiv 2025
-
[43]
https://chatglm.cn/ (2026), generative AI assistant
Zhipu AI: Zhipu qingyan. https://chatglm.cn/ (2026), generative AI assistant. Ac- cessed: 2026-05-28
2026
-
[44]
Data Intelligence7(2), 461–484 (2025)
Zhu, Y., Li, Y., Wang, J., Gao, M., Wei, J.: FaKnow: A unified library for fake news detection. Data Intelligence7(2), 461–484 (2025). https://doi.org/10.3724/2096- 7004.di.2024.0026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.