Pano3D: Unified 3D Reconstruction and Panoptic Segmentation
Pith reviewed 2026-07-01 07:21 UTC · model grok-4.3
The pith
A single neural network performs both 3D reconstruction and panoptic segmentation when trained jointly on geometric and semantic losses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By augmenting 3D feedforward reconstruction models with a set-based mask decoder and training jointly with geometric and semantic losses, the method equips these networks with panoptic segmentation capabilities, yielding mutually beneficial improvements and state-of-the-art results on ScanNet, ScanNet200, and ScanNet++.
What carries the argument
A set-based mask decoder added to reconstruction backbones, with features initialized from geometry and finetuned jointly.
Load-bearing premise
The assumption that initializing from geometric features and finetuning with a joint loss will improve both tasks without trade-offs or the need for careful loss balancing.
What would settle it
Training the reconstruction model and a separate segmentation model individually and comparing their combined performance to the joint model on the same datasets would test if mutual benefits exist.
Figures
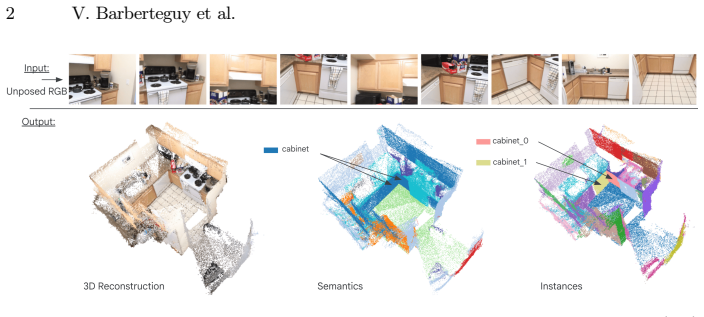
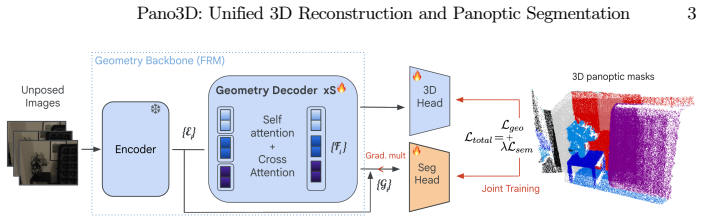
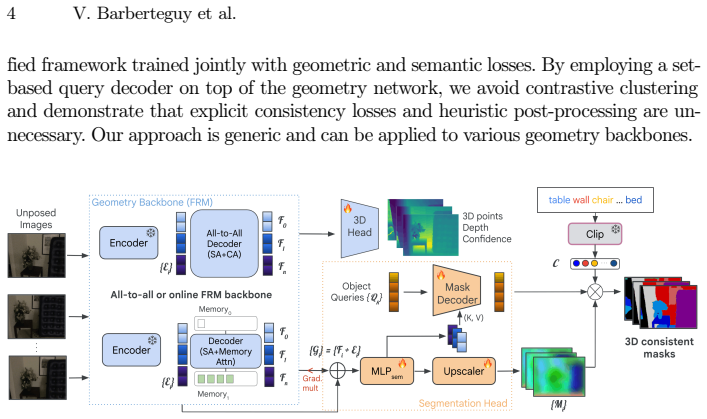
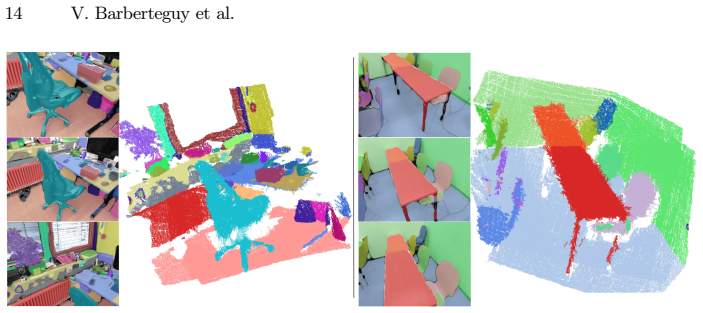


read the original abstract
Recent advances in 3D feedforward reconstruction neural networks have achieved remarkable success in dense reconstruction from images without any camera parameters. Yet, equipping these models with robust semantic understanding remains an open problem. Here we introduce an approach that performs 3D reconstruction and 3D panoptic segmentation in a unified framework. We build on existing 3D reconstruction models and augment them with a set-based mask decoder. The approach is jointly trained with a geometric and semantic loss, which are shown to be mutually beneficial. More precisely, the features are initialized from the geometric information and then finetuned to capture jointly geometry and semantics. We demonstrate the generality of our approach by successfully applying our framework both to online and all-to-all attention reconstruction backbones. Our method achieves state-of-the-art performance in 3D panoptic segmentation across ScanNet, ScanNet200, and ScanNet++ datasets. Ablation studies show that such joint training of a unified model equips 3D feedforward reconstruction neural networks with panoptic segmentation and yields mutually beneficial improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Pano3D, a unified framework for simultaneous 3D reconstruction and 3D panoptic segmentation. It augments existing feedforward reconstruction models (both online and all-to-all attention variants) with a set-based mask decoder and performs joint training using a combined geometric and semantic loss. Features are initialized from geometric information and then finetuned jointly; the authors claim this yields mutually beneficial improvements and state-of-the-art 3D panoptic segmentation results on ScanNet, ScanNet200, and ScanNet++.
Significance. If the quantitative claims hold, the work would address the open problem of adding robust semantic understanding to parameter-free 3D reconstruction networks and demonstrate that joint geometric-semantic optimization can improve both tasks. The reported generality across reconstruction backbones would be a useful contribution to unified 3D vision models.
major comments (2)
- [Abstract] Abstract: the central claims of SOTA performance in 3D panoptic segmentation and mutually beneficial joint training are asserted without any quantitative metrics, error bars, dataset splits, ablation tables, or per-task deltas, so the primary empirical contribution cannot be evaluated from the text.
- [Ablation studies] Ablation studies (as described): the claim that joint geometric-semantic training produces bidirectional gains without trade-offs rests on unspecified loss weighting, convergence behavior, and relative metric improvements; without these details the mutual-benefit assertion remains unverified.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger empirical grounding in the abstract and ablation descriptions. We will revise the manuscript accordingly to address these points while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of SOTA performance in 3D panoptic segmentation and mutually beneficial joint training are asserted without any quantitative metrics, error bars, dataset splits, ablation tables, or per-task deltas, so the primary empirical contribution cannot be evaluated from the text.
Authors: We agree that the abstract as written does not include quantitative support. In the revised version we will add specific metrics (e.g., PQ scores on ScanNet/ScanNet200/ScanNet++ with comparisons to prior methods) and note the per-task gains from joint training. Dataset splits and evaluation protocol are already detailed in the experimental section and will be referenced concisely in the abstract. revision: yes
-
Referee: [Ablation studies] Ablation studies (as described): the claim that joint geometric-semantic training produces bidirectional gains without trade-offs rests on unspecified loss weighting, convergence behavior, and relative metric improvements; without these details the mutual-benefit assertion remains unverified.
Authors: The manuscript reports ablation results showing mutual benefits, but we acknowledge the description lacks explicit loss weights, convergence details, and per-metric deltas. We will expand the ablation section (and associated tables) to report the exact loss coefficients used, training dynamics where relevant, and quantitative improvements on both geometric and semantic metrics when training jointly versus separately. revision: yes
Circularity Check
No circularity; empirical joint-training claims rest on external datasets and ablations
full rationale
The paper augments prior reconstruction backbones with a set-based mask decoder and reports joint geometric-semantic training results on ScanNet variants. No equations, fitted parameters, or uniqueness theorems are defined in terms of the target outputs. Ablation claims of mutual benefit are presented as measured deltas on held-out data rather than reductions by construction. Self-citations, if present, are not load-bearing for the central empirical result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Joint training with geometric and semantic losses produces mutually beneficial improvements
- domain assumption Features initialized from geometric information can be successfully finetuned for joint geometry and semantics
Reference graph
Works this paper leans on
-
[1]
In: CVPR (2025)
Cabon, Y., Stoffl, L., Antsfeld, L., Csurka, G., Chidlovskii, B., Revaud, J., Leroy, V.: MUSt3R: Multi-view network for stereo 3D reconstruction. In: CVPR (2025)
2025
-
[2]
In: ECCV (2020)
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: ECCV (2020)
2020
-
[3]
arXiv preprint arXiv:2506.02112 (2025)
Chen, X., Xia, T., Xu, S., Yang, J., Chai, J., Cheng, Z.: Sab3r: Semantic-augmented backbone in 3d reconstruction. arXiv preprint arXiv:2506.02112 (2025)
-
[4]
In: CVPR (2020)
Cheng, B., Collins, M.D., Zhu, Y., Liu, T., Huang, T.S., Adam, H., Chen, L.C.: Panoptic-deeplab: A simple, strong, and fast baseline for bottom-up panoptic segmentation. In: CVPR (2020)
2020
-
[5]
In: CVPR (2022)
Cheng, B., Misra, I., Schwing, A.G., Kirillov, A., Girdhar, R.: Masked-attention mask transformer for universal image segmentation. In: CVPR (2022)
2022
-
[6]
In: CVPR (2017)
Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: CVPR (2017)
2017
-
[7]
In: ICLR (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. In: ICLR (2021)
2021
-
[8]
NeurIPS (2024)
Fan, Z., Zhang, J., Cong, W., Wang, P., Li, R., Wen, K., Zhou, S., Kadambi, A., Wang, Z., Xu, D., et al.: Large spatial model: End-to-end unposed images to semantic 3d. NeurIPS (2024)
2024
-
[9]
In: 3DV (2022)
Fu, X., Zhang, S., Chen, T., Lu, Y., Zhu, L., Zhou, X., Geiger, A., Liao, Y.: Panoptic nerf: 3d-to-2d label transfer for panoptic urban scene segmentation. In: 3DV (2022)
2022
-
[10]
In: ECCV (2022)
Ghiasi, G., Gu, X., Cui, Y., Lin, T.Y.: Scaling open-vocabulary image segmentation with image-level labels. In: ECCV (2022)
2022
-
[11]
arXiv preprint arXiv:2507.22052 (2025)
Gong, Z., Li, X., Tosi, F., Han, J., Mattoccia, S., Cai, J., Poggi, M.: Ov3r: Open- vocabulary semantic 3d reconstruction from rgb videos. arXiv preprint arXiv:2507.22052 (2025)
-
[12]
In: CVPR (2017)
He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask r-cnn. In: CVPR (2017)
2017
-
[13]
In: CVPR (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
2016
-
[14]
ICLR (2017)
Hendrycks, D., Gimpel, K.: Gaussian error linear units (gelus). ICLR (2017)
2017
-
[15]
Hu, J., Wang, S., Wang, X.: PE3R: Perception-efficient 3D reconstruction. arXiv:2503.07507 (2025)
-
[16]
CVPR (2024)
Jain, A., Katara, P., Gkanatsios, N., Harley, A.W., Sarch, G., Aggarwal, K., Chaudhary, V., Fragkiadaki, K.: ODIN: A single model for 2D and 3D segmentation. CVPR (2024)
2024
-
[17]
ACM Transactions on Graphics (TOG) (2023)
Kerbl, B., Kopanas, G., Leimkuehler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics (TOG) (2023)
2023
-
[18]
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization (2017)
2017
-
[19]
CVPR (2018)
Kirillov, A., He, K., Girshick, R.B., Rother, C., Dollár, P.: Panoptic segmentation. CVPR (2018)
2018
-
[20]
ArXiv (2022)
Kobayashi, S., Matsumoto, E., Sitzmann, V.: Decomposing nerf for editing via feature field distillation. ArXiv (2022)
2022
-
[21]
Koch, S., Wald, J., Matsuki, H., Hermosilla, P., Ropinski, T., Tombari, F.: Unified semantictransformerfor3dsceneunderstanding.arXivpreprintarXiv:2512.14364(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
In: ECCV (2024) Pano3D: Unified 3D Reconstruction and Panoptic Segmentation 17
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3D with MASt3R. In: ECCV (2024) Pano3D: Unified 3D Reconstruction and Panoptic Segmentation 17
2024
-
[23]
Language-driven Semantic Segmentation
Li, B., Weinberger, K.Q., Belongie, S., Koltun, V., Ranftl, R.: Language-driven semantic segmentation. arXiv preprint arXiv:2201.03546 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
In: ICLR (2025)
Li, H., Zou, Z., Liu, F., Zhang, X., Hong, F., Cao, Y., Lan, Y., Zhang, M., Yu, G., Zhang, D., Liu, Z.: IGGT: Instance-grounded geometry transformer for semantic 3D reconstruction. In: ICLR (2025)
2025
-
[25]
In: CVPR (2017)
Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: CVPR (2017)
2017
-
[26]
In: ECCV (2014)
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: Common objects in context. In: ECCV (2014)
2014
-
[27]
In: CVPR (2021)
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows. In: CVPR (2021)
2021
-
[28]
Image and Vision Computing (2002)
Luo, B., Hancock, E.: Iterative procrustes alignment with the em algorithm. Image and Vision Computing (2002)
2002
-
[29]
In: International Conference on Data Mining Workshops (ICDMW) (2017)
McInnes, L., Healy, J.: Accelerated hierarchical density based clustering. In: International Conference on Data Mining Workshops (ICDMW) (2017)
2017
-
[30]
Communications of the ACM (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM (2021)
2021
-
[31]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
In: CVPR (2023)
Peng, S., Genova, K., Jiang, C., Tagliasacchi, A., Pollefeys, M., Funkhouser, T., et al.: Openscene: 3d scene understanding with open vocabularies. In: CVPR (2023)
2023
-
[33]
In: ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: ICML (2021)
2021
-
[34]
In: CVPR (2021)
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision transformers for dense prediction. In: CVPR (2021)
2021
-
[35]
ArXiv (2024)
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C.K., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K.V., Carion, N., Wu, C., Girshick, R.B., Doll’ar, P., Feichtenhofer, C.: Sam 2: Segment anything in images and videos. ArXiv (2024)
2024
-
[36]
In: CVPR (2022)
Robert, D., Vallet, B., Landrieu, L.: Learning multi-view aggregation in the wild for large-scale 3d semantic segmentation. In: CVPR (2022)
2022
-
[37]
In: ICCV (2021)
Roberts, M., Ramapuram, J., Ranjan, A., Kumar, A., Bautista, M.A., Paczan, N., Webb, R., Susskind, J.M.: Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. In: ICCV (2021)
2021
-
[38]
In: ECCV (2022)
Rozenberszki, D., Litany, O., Dai, A.: Language-grounded indoor 3d semantic segmentation in the wild. In: ECCV (2022)
2022
-
[39]
ArXiv (2025)
Stary, M., Gaubil, J., Tewari, A.K., Sitzmann, V.: Understanding multi-view transformers. ArXiv (2025)
2025
-
[40]
ArXiv (2025)
Sun, X., Jiang, H., Liu, L., Nam, S., Kang, G., Wang, X., Sui, W., Su, Z., Liu, W., Wang, X., Park, E.: Uni3R: Unified 3D reconstruction and semantic understanding via generalizable gaussian splatting from unposed multi-view images. ArXiv (2025)
2025
-
[41]
In: CVPR (2025)
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: VGGT: Visual geometry grounded transformer. In: CVPR (2025)
2025
-
[42]
In: CVPR (2024)
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: DUSt3R: Geometric 3D vision made easy. In: CVPR (2024)
2024
-
[43]
In: ICLR (2026)
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.:π3: Permutation-equivariant visual geometry learning. In: ICLR (2026)
2026
-
[44]
In: CVPR (2023) 18 V
Weinzaepfel, P., Lucas, T., Leroy, V., Cabon, Y., Arora, V., Brégier, R., Csurka, G., Antsfeld, L., Chidlovskii, B., Revaud, J.: Croco v2: Improved cross-view completion pre-training for stereo matching and optical flow. In: CVPR (2023) 18 V. Barberteguy et al
2023
-
[45]
ArXiv (2025)
Xu, Q., Wei, D., Zhao, L., Li, W., Huang, Z., Ji, S., Liu, P.: Siu3r: Simultaneous scene understanding and 3d reconstruction beyond feature alignment. ArXiv (2025)
2025
-
[46]
ArXiv (2023)
Yang, Y., Wu, X., He, T., Zhao, H., Liu, X.: Sam3d: Segment anything in 3d scenes. ArXiv (2023)
2023
-
[47]
In: CVPR (2023)
Yeshwanth, C., Liu, Y.C., Nießner, M., Dai, A.: Scannet++: A high-fidelity dataset of 3d indoor scenes. In: CVPR (2023)
2023
-
[48]
In: CVPR (2024)
Zhou, S., Chang, H., Jiang, S., Fan, Z., Zhu, Z., Xu, D., Chari, P., You, S., Wang, Z., Kadambi, A.: Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields. In: CVPR (2024)
2024
-
[49]
Zust, L., Cabon, Y., Marrie, J., Antsfeld, L., Chidlovskii, B., Revaud, J., Csurka, G.: Panst3r: Multi-view consistent panoptic segmentation. In: CVPR (2025) Pano3D: Unified 3D Reconstruction and Panoptic Segmentation 19 APPENDIX In this supplementary document, we provide additional technical details, expanded experimental results, and visualizations. Spe...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.