CompactQE: Interpretable Translation Quality Estimation via Small Open-Weight LLMs
Pith reviewed 2026-05-20 18:50 UTC · model grok-4.3
The pith
Small open-weight LLMs under 30 billion parameters serve as effective, private alternatives to large proprietary models for machine translation quality estimation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
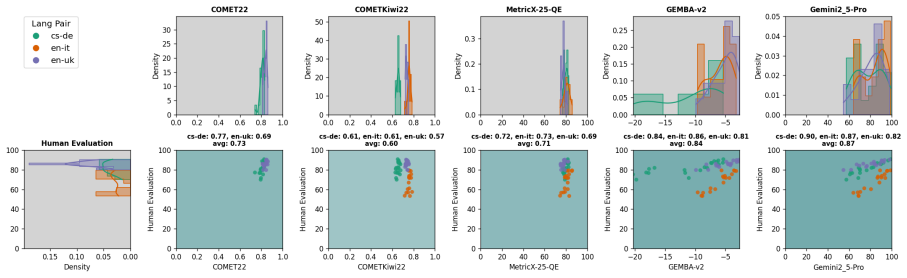
Using a single-pass prompting strategy, smaller open-source LLMs with fewer than 30 billion parameters simultaneously generate quality scores, MQM error annotations, suggested error corrections, and full post-editions. These models achieve highly competitive system-level correlations with human judgments that outperform traditional neural metrics, fine-tuned models, and human inter-annotator agreement, effectively approximating the capabilities of much larger proprietary LLMs.
What carries the argument
Single-pass prompting on compact open-weight LLMs to produce multiple QE outputs including scores, MQM annotations, corrections, and post-editions in one go.
If this is right
- Small LLMs can replace large proprietary ones for QE tasks without losing much performance.
- Users gain interpretable outputs like specific error corrections alongside scores.
- The method reduces costs and protects data privacy by allowing local model use.
- Performance exceeds human inter-annotator agreement in system-level correlations.
Where Pith is reading between the lines
- Deploying these models locally could enable real-time QE in production translation systems without sending data to external servers.
- Similar single-pass techniques might extend to other evaluation tasks in NLP beyond machine translation.
- Further testing on low-resource languages could reveal if the approach generalizes beyond the evaluated setups.
Load-bearing premise
The single-pass prompting strategy can accurately elicit multiple types of quality estimation outputs without a substantial drop in quality compared to using separate prompts or fine-tuning.
What would settle it
An experiment where the small models' system-level correlation with human judgments falls below that of traditional neural metrics on a held-out test set of translations.
Figures




read the original abstract
Current state-of-the-art Quality Estimation (QE) in machine translation relies on massive, proprietary LLMs, raising data privacy concerns. We demonstrate that smaller, open-source LLMs (<30B parameters) are a viable, cost-effective and privacy-preserving alternative. Using a single-pass prompting strategy, our models simultaneously generate quality scores, MQM error annotations, suggested error corrections, and full post-editions. Our analysis shows these models achieve highly competitive system-level correlations with human judgments that outperform traditional neural metrics, fine-tuned models, and human inter-annotator agreement, effectively approximating the capabilities of much larger proprietary LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CompactQE, a framework that applies small open-weight LLMs (<30B parameters) to machine translation quality estimation via a single-pass prompting strategy. The models are prompted to output quality scores, MQM-style error annotations, suggested corrections, and full post-editions in one generation pass. The central empirical claim is that these models attain system-level correlations with human judgments that are competitive with or superior to traditional neural QE metrics, fine-tuned models, and human inter-annotator agreement, thereby offering a cost-effective, privacy-preserving, and interpretable alternative to large proprietary LLMs.
Significance. If the reported correlations are robust, the work would meaningfully advance practical QE by showing that accessible open models can match or exceed the system-level performance of larger systems while adding interpretability through multi-output generation. The emphasis on open weights and reduced computational requirements addresses real deployment barriers around cost and data privacy.
major comments (1)
- [Methods] The viability of the single-pass multi-output prompting strategy is load-bearing for the central claim that small LLMs can approximate larger models without substantial quality loss. The manuscript describes this strategy in the Methods but provides no ablation that compares single-pass generation against separate specialized prompts (or fine-tuning) for scores, MQM annotations, corrections, and post-editions on the same models and datasets. Without such controls, it remains unclear whether the competitive correlations are attributable to model capability or to prompt engineering choices.
minor comments (2)
- [Abstract] The abstract states that the models outperform human inter-annotator agreement but does not name the specific test sets, language pairs, or number of systems evaluated; these details appear later but a brief reference would improve readability.
- [Results] Table or figure captions for the correlation results should explicitly list the exact baseline implementations and any statistical significance tests used to support claims of outperformance.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the manuscript. We address the major comment point by point below and will incorporate revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Methods] The viability of the single-pass multi-output prompting strategy is load-bearing for the central claim that small LLMs can approximate larger models without substantial quality loss. The manuscript describes this strategy in the Methods but provides no ablation that compares single-pass generation against separate specialized prompts (or fine-tuning) for scores, MQM annotations, corrections, and post-editions on the same models and datasets. Without such controls, it remains unclear whether the competitive correlations are attributable to model capability or to prompt engineering choices.
Authors: We agree that an ablation comparing single-pass multi-output prompting to separate specialized prompts would help isolate the contribution of the prompting strategy. Our current results show that the single-pass approach enables small open-weight models to produce competitive system-level correlations while generating multiple outputs (scores, MQM annotations, corrections, and post-editions) in one pass, which is central to the efficiency and interpretability claims. However, without the requested controls it is not possible to fully rule out that prompt engineering choices play a substantial role. In the revised manuscript we will add an ablation on a representative subset of models and datasets that directly compares the single-pass strategy against equivalent separate prompts for each output type. This will clarify the extent to which the observed performance stems from model capability versus the multi-output prompting design. revision: yes
Circularity Check
No circularity; empirical results benchmarked against external human judgments
full rationale
The paper presents an empirical study of prompting small open-weight LLMs for MT quality estimation. It reports system-level correlations with human judgments and compares them to published neural metrics, fine-tuned QE models, and human IAA. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All load-bearing claims rest on direct, external comparisons rather than internal construction or self-referential definitions. This is a standard empirical evaluation that remains self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human inter-annotator agreement and MQM annotations constitute reliable external benchmarks for QE system quality.
Reference graph
Works this paper leans on
-
[1]
Aho, Alfred V. and Ullman, Jeffrey D. , title =. 1972 , volume=1, publisher =
work page 1972
-
[2]
Interspeech 2006 --- Ninth International Conference on Spoken Language Processing , address=
Unsupervised language model adaptation using latent semantic marginals , author=. Interspeech 2006 --- Ninth International Conference on Spoken Language Processing , address=. 2006 , pages=
work page 2006
- [3]
-
[4]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year=1981, title=. Journal of the Association for Computing Machinery , volume=28, issue=1, pages=
work page 1981
-
[5]
Coling 2008, 22nd International Conference on Computational Linguistics , address=
Anne Gledson and John Keane , year=2008, title=. Coling 2008, 22nd International Conference on Computational Linguistics , address=
work page 2008
-
[6]
Dan Gusfield , title=
-
[7]
Yik-Cheung Tam and Tanja Schultz , year=2007, title=. Proceedings of ICASSP 2007, International Conference on Acoustics, Speech, and Signal Processing , address=
work page 2007
-
[8]
GEMBA V2: Ten Judgments Are Better Than One
Junczys-Dowmunt, Marcin. GEMBA V2: Ten Judgments Are Better Than One. Proceedings of the Tenth Conference on Machine Translation. 2025. doi:10.18653/v1/2025.wmt-1.67
- [9]
-
[10]
In: Webber, B., Cohn, T., He, Y., Liu, Y
Rei, Ricardo and Stewart, Craig and Farinha, Ana C and Lavie, Alon. COMET : A Neural Framework for MT Evaluation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.213
-
[11]
In: Koehn, P., Haddow, B., Kocmi, T., Monz, C
Kocmi, Tom and Federmann, Christian. GEMBA - MQM : Detecting Translation Quality Error Spans with GPT -4. Proceedings of the Eighth Conference on Machine Translation. 2023. doi:10.18653/v1/2023.wmt-1.64
-
[12]
Fernandes, Patrick and Deutsch, Daniel and Finkelstein, Mara and Riley, Parker and Martins, Andr \'e and Neubig, Graham and Garg, Ankush and Clark, Jonathan and Freitag, Markus and Firat, Orhan. The Devil Is in the Errors: Leveraging Large Language Models for Fine-grained Machine Translation Evaluation. Proceedings of the Eighth Conference on Machine Tran...
-
[13]
Multidimensional quality metrics: a flexible system for assessing translation quality
Lommel, Arle Richard and Burchardt, Aljoscha and Uszkoreit, Hans. Multidimensional quality metrics: a flexible system for assessing translation quality. Proceedings of Translating and the Computer 35. 2013
work page 2013
-
[14]
Error Span Annotation: A Balanced Approach for Human Evaluation of Machine Translation
Kocmi, Tom and Zouhar, Vil \'e m and Avramidis, Eleftherios and Grundkiewicz, Roman and Karpinska, Marzena and Popovi \'c , Maja and Sachan, Mrinmaya and Shmatova, Mariya. Error Span Annotation: A Balanced Approach for Human Evaluation of Machine Translation. Proceedings of the Ninth Conference on Machine Translation. 2024. doi:10.18653/v1/2024.wmt-1.131
- [15]
-
[16]
and Zerva, Chrysoula and Farinha, Ana C and Maroti, Christine and C
Rei, Ricardo and Treviso, Marcos and Guerreiro, Nuno M. and Zerva, Chrysoula and Farinha, Ana C and Maroti, Christine and C. de Souza, Jos \'e G. and Glushkova, Taisiya and Alves, Duarte and Coheur, Luisa and Lavie, Alon and Martins, Andr \'e F. T. C omet K iwi: IST -Unbabel 2022 Submission for the Quality Estimation Shared Task. Proceedings of the Sevent...
-
[17]
and Rei, Ricardo and Stigt, Daan van and Coheur, Luisa and Colombo, Pierre and Martins, André F
Guerreiro, Nuno M. and Rei, Ricardo and Stigt, Daan van and Coheur, Luisa and Colombo, Pierre and Martins, Andr \'e F. T. x COMET : Transparent Machine Translation Evaluation through Fine-grained Error Detection. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00683
-
[18]
Error Analysis Prompting Enables Human-Like Translation Evaluation in Large Language Models
Lu, Qingyu and Qiu, Baopu and Ding, Liang and Zhang, Kanjian and Kocmi, Tom and Tao, Dacheng. Error Analysis Prompting Enables Human-Like Translation Evaluation in Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.520
- [19]
-
[20]
Lu, Qingyu and Ding, Liang and Zhang, Kanjian and Zhang, Jinxia and Tao, Dacheng. MQM - APE : Toward High-Quality Error Annotation Predictors with Automatic Post-Editing in LLM Translation Evaluators. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[21]
Automatic Post-Editing of Machine Translation: A Neural Programmer-Interpreter Approach
Vu, Thuy-Trang and Haffari, Gholamreza. Automatic Post-Editing of Machine Translation: A Neural Programmer-Interpreter Approach. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1341
- [22]
- [23]
- [24]
- [25]
- [26]
-
[27]
In: Haddow, B., Kocmi, T., Koehn, P., Monz, C
Lavie, Alon and Hanneman, Greg and Agrawal, Sweta and Kanojia, Diptesh and Lo, Chi-Kiu and Zouhar, Vil \'e m and Blain, Frederic and Zerva, Chrysoula and Avramidis, Eleftherios and Deoghare, Sourabh and Sindhujan, Archchana and Wang, Jiayi and Adelani, David Ifeoluwa and Thompson, Brian and Kocmi, Tom and Freitag, Markus and Deutsch, Daniel. Findings of t...
-
[28]
Large Language Models Are State-of-the-Art Evaluators of Translation Quality
Kocmi, Tom and Federmann, Christian. Large Language Models Are State-of-the-Art Evaluators of Translation Quality. Proceedings of the 24th Annual Conference of the European Association for Machine Translation. 2023
work page 2023
-
[29]
Thompson, Brian and Mathur, Nitika and Deutsch, Daniel and Khayrallah, Huda. Improving Statistical Significance in Human Evaluation of Automatic Metrics via Soft Pairwise Accuracy. Proceedings of the Ninth Conference on Machine Translation. 2024. doi:10.18653/v1/2024.wmt-1.118
-
[30]
Ties Matter: Meta-Evaluating Modern Metrics with Pairwise Accuracy and Tie Calibration
Deutsch, Daniel and Foster, George and Freitag, Markus. Ties Matter: Meta-Evaluating Modern Metrics with Pairwise Accuracy and Tie Calibration. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.798
-
[31]
Juraska, Juraj and Domhan, Tobias and Finkelstein, Mara and Nakagawa, Tetsuji and Kovacs, Geza and Deutsch, Daniel and Wang, Pidong and Freitag, Markus. M etric X -25 and G em S pan E val: G oogle T ranslate Submissions to the WMT 25 Evaluation Shared Task. Proceedings of the Tenth Conference on Machine Translation. 2025. doi:10.18653/v1/2025.wmt-1.70
-
[32]
Zerva, Chrysoula and Blain, Fr \'e d \'e ric and Rei, Ricardo and Lertvittayakumjorn, Piyawat and C. de Souza, Jos \'e G. and Eger, Steffen and Kanojia, Diptesh and Alves, Duarte and Or a san, Constantin and Fomicheva, Marina and Martins, Andr \'e F. T. and Specia, Lucia. Findings of the WMT 2022 Shared Task on Quality Estimation. Proceedings of the Seven...
-
[33]
Blain, Frederic and Zerva, Chrysoula and Rei, Ricardo and Guerreiro, Nuno M. and Kanojia, Diptesh and C. de Souza, Jos \'e G. and Silva, Beatriz and Vaz, T \^a nia and Jingxuan, Yan and Azadi, Fatemeh and Orasan, Constantin and Martins, Andr \'e. Findings of the WMT 2023 Shared Task on Quality Estimation. Proceedings of the Eighth Conference on Machine Tr...
-
[34]
JSON Repair - A python module to repair invalid JSON, commonly used to parse the output of LLMs
Stefano Baccianella. JSON Repair - A python module to repair invalid JSON, commonly used to parse the output of LLMs
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.