Not All Tokens Are Worth Caching: Learning Semantic-Aware Eviction for LLM Prefix Caches
Pith reviewed 2026-05-20 22:05 UTC · model grok-4.3
The pith
A semantic-adaptive eviction policy improves LLM prefix cache efficiency by learning the reuse value of different token types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that semantic categories of tokens within prompts have dramatically different reuse frequencies, and that an online-learned multi-queue eviction policy can exploit this to reduce expensive prefill steps in LLM inference.
What carries the argument
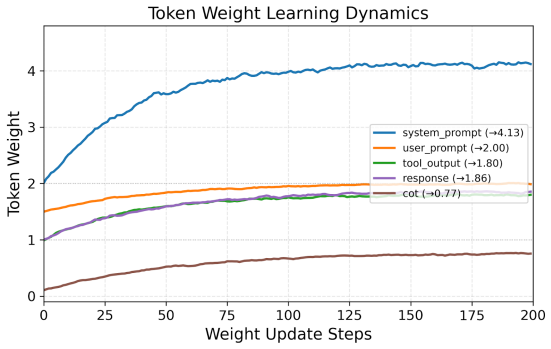
SAECache, which consists of a multi-queue architecture for routing KV blocks, a semantic-aware token weighting mechanism, and a fully adaptive online learning schema for all parameters.
If this is right
- TTFT improves by factors of 1.4 to 2.7 over standard baselines.
- Performance does not degrade under workload changes, unlike fixed policies.
- The system handles both multi-turn conversations and single-turn templated requests effectively.
- No manual tuning is required as parameters adjust automatically.
Where Pith is reading between the lines
- Similar ideas could apply to caching in other LLM components like model weights or activation storage.
- Detecting token types might be enhanced by using the model's own understanding of prompt structure.
- This approach could lead to more efficient resource allocation in large-scale AI deployments.
Load-bearing premise
The reuse rate differences between token types are consistent and provide a signal that existing policies do not already use.
What would settle it
If experiments show similar performance to LRU on workloads where reuse rates are equalized across token types, the benefit of semantic awareness would be disproven.
Figures












read the original abstract
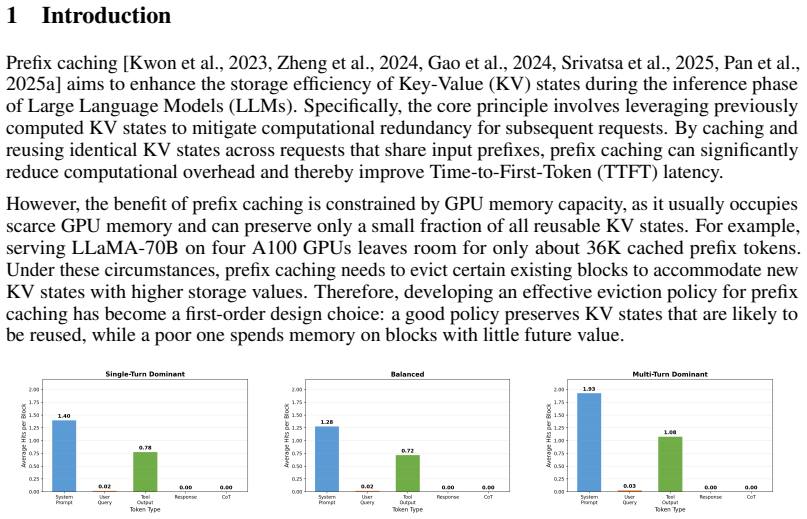
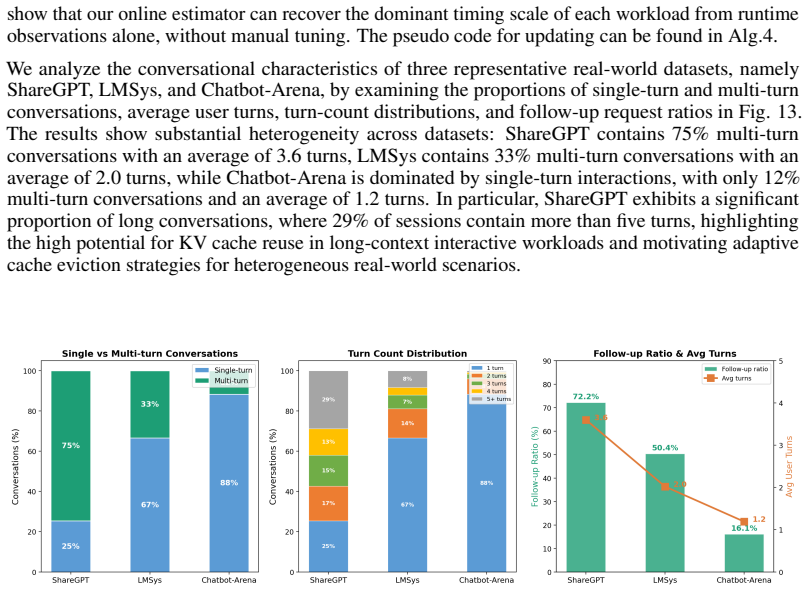
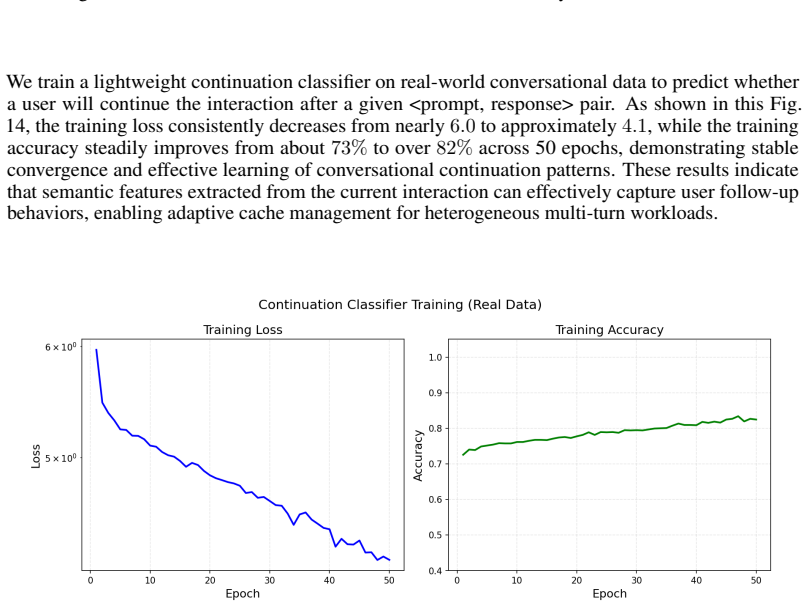
Prefix caching is a key optimization in Large Language Model (LLM) serving, reusing attention Key-Value (KV) states across requests with shared prompt prefixes to reduce expensive prefill computation. However, its benefit depends critically on the eviction policy as GPU memory is scarce, and existing policies such as LRU largely treat cached blocks uniformly. This view ignores a fundamental property of LLM prompts: not all tokens are equally worth caching. We show that different token types within a prompt, including system prompts, user queries, tool outputs, model responses, and chain-of-thought reasoning, exhibit up to 756x variation in reuse rates, yet no existing eviction policy exploits this signal. In this paper, we present SAECache (Semantic-Adaptive Eviction for prefix caches), a semantic-adaptive prefix cache eviction policy that addresses this gap through three innovations: (1) a multi-queue architecture that routes KV blocks to task-specific queues with tailored priority metrics, capturing both session reuse in multi-turn requests and structural reuse in templated single-turn requests; (2) a semantic-aware token weighting mechanism that learns the reuse value of different token types online through eviction feedback; and (3) a fully adaptive online learning schema for all parameter updates, including log-normal timing parameters, position decay power, queue weights, and meta-parameters, which eliminates manual tuning and enables automatic adaptation to deployment-specific workload characteristics. Through extensive evaluation across heterogeneous workloads, we demonstrate that SAECache achieves 1.4x-2.7x TTFT improvement over production-style baselines, while fixed-parameter alternatives can degrade by up to 2.7x under workload mismatch -- a failure mode our adaptive approach avoids entirely.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SAECache, a semantic-adaptive eviction policy for LLM prefix caches. It observes up to 756x variation in reuse rates across token types (system prompts, user queries, tool outputs, model responses, chain-of-thought) and introduces a multi-queue architecture with task-specific priority metrics, semantic-aware token weighting learned online via eviction feedback, and a fully adaptive online learning schema for parameters including log-normal timing parameters, position decay power, queue weights, and meta-parameters. Evaluations across heterogeneous workloads claim 1.4x-2.7x TTFT improvement over production-style baselines, with fixed-parameter alternatives degrading by up to 2.7x under workload mismatch.
Significance. If the results hold, SAECache could significantly improve time-to-first-token (TTFT) in LLM serving systems by better exploiting semantic differences in token reuse, particularly in dynamic, multi-turn, and templated workloads. The fully online adaptation is a notable strength, potentially reducing the need for manual tuning in production deployments. This addresses a practical gap in current LRU-based prefix caching approaches.
major comments (3)
- [§4] §4, evaluation workloads: The reported up to 756x variation in reuse rates across token types is central to the motivation, but the manuscript provides insufficient detail on how these rates were measured, the specific workload characteristics, baselines for comparison, or statistical significance of the variation. This undermines evaluation of whether the signal is robust or workload-specific.
- [Evaluation workloads] Evaluation section: The paper does not report cross-workload stability, such as reuse histograms on held-out prompt corpora or different model families. If the 756x ratio shifts under distribution change, the adaptive meta-parameters may overfit to training traces, weakening the claim of robustness to workload mismatch.
- [Online learning schema] Online learning schema: The fully adaptive online update rule for queue weights and log-normal timing parameters assumes persistent, learnable structure in the reuse signals. However, without evidence that this generalizes beyond the tested traces, it risks chasing transient correlations rather than stable semantics.
minor comments (2)
- [§3] The abstract and §3 could clarify the exact form of the priority metrics used in the multi-queue architecture with a brief example to aid reproducibility.
- Figure captions for the reuse rate histograms should explicitly state the number of traces and token-type definitions for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, agreeing where additional detail or clarification is warranted and explaining our position on the others. Revisions will be incorporated in the next version of the manuscript to improve the evaluation section.
read point-by-point responses
-
Referee: [§4] §4, evaluation workloads: The reported up to 756x variation in reuse rates across token types is central to the motivation, but the manuscript provides insufficient detail on how these rates were measured, the specific workload characteristics, baselines for comparison, or statistical significance of the variation. This undermines evaluation of whether the signal is robust or workload-specific.
Authors: We agree that the measurement details require expansion for full reproducibility. Reuse rates were computed by logging cache hit/miss events per token type (system prompts, user queries, tool outputs, model responses, chain-of-thought) over production traces, with reuse rate defined as hits divided by total occurrences for each category. Workloads comprise multi-turn sessions and templated single-turn prompts from heterogeneous applications, with baselines including standard LRU and fixed-priority variants. We will revise §4 to include the exact formulas, workload statistics (request counts, prompt length distributions), and statistical tests (e.g., variance and significance across categories) to confirm robustness within the evaluated set. revision: yes
-
Referee: [Evaluation workloads] Evaluation section: The paper does not report cross-workload stability, such as reuse histograms on held-out prompt corpora or different model families. If the 756x ratio shifts under distribution change, the adaptive meta-parameters may overfit to training traces, weakening the claim of robustness to workload mismatch.
Authors: The heterogeneous workloads already incorporate distribution shifts via multi-turn and templated variations, and the online adaptation is explicitly designed to handle mismatch (as shown by fixed-parameter degradation). We will add reuse histograms on held-out corpora in the revised evaluation to quantify stability. The approach is model-agnostic, relying on semantic token categories rather than architecture-specific features; we will clarify this point and note that primary results use one model family while the adaptation mechanism generalizes. revision: partial
-
Referee: [Online learning schema] Online learning schema: The fully adaptive online update rule for queue weights and log-normal timing parameters assumes persistent, learnable structure in the reuse signals. However, without evidence that this generalizes beyond the tested traces, it risks chasing transient correlations rather than stable semantics.
Authors: The update rules incorporate temporal averaging and eviction-feedback loops that prioritize persistent reuse patterns over short-term fluctuations, as evidenced by sustained gains across workload shifts in our experiments. We will expand the discussion to include parameter convergence plots and examples illustrating how transient signals are downweighted, reinforcing that the schema targets stable semantic structures. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's core contributions are an empirical observation of reuse-rate variation across token types (up to 756x) followed by a multi-queue architecture and online learning of weights/parameters from eviction feedback. These elements do not reduce any claimed result to its inputs by construction: the learning rule updates from external runtime signals rather than re-deriving the same quantities, no equations equate a 'prediction' to a fitted parameter, and no load-bearing self-citations or imported uniqueness theorems appear. The TTFT gains are presented as evaluation outcomes on heterogeneous workloads, not as a first-principles derivation that collapses into the observed statistics. This is the common case of an adaptive heuristic whose correctness can be checked externally.
Axiom & Free-Parameter Ledger
free parameters (3)
- log-normal timing parameters
- position decay power
- queue weights
axioms (1)
- domain assumption Different token types within prompts exhibit substantially different reuse rates that are stable enough to be exploited by separate queues.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a semantic-aware token weighting mechanism that learns the reuse value of different token types online through eviction feedback
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
Lianmin Zheng and Liangsheng Yin and Zhiqiang Xie and Chuyue Sun and Jeff Huang and Cody Hao Yu and Shiyi Cao and Christos Kozyrakis and Ion Stoica and Joseph E. Gonzalez and Clark W. Barrett and Ying Sheng , editor =. SGLang: Efficient Execution of Structured Language Model Programs , booktitle =. 2024 , url =
work page 2024
-
[3]
Bin Gao and Zhuomin He and Puru Sharma and Qingxuan Kang and Djordje Jevdjic and Junbo Deng and Xingkun Yang and Zhou Yu and Pengfei Zuo , editor =. Cost-Efficient Large Language Model Serving for Multi-turn Conversations with CachedAttention , booktitle =. 2024 , url =
work page 2024
-
[4]
The Thirteenth International Conference on Learning Representations,
Vikranth Srivatsa and Zijian He and Reyna Abhyankar and Dongming Li and Yiying Zhang , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[5]
Marconi: Prefix Caching for the Era of Hybrid LLMs , author=. 2025 , eprint=
work page 2025
-
[7]
KVFlow: Efficient Prefix Caching for Accelerating LLM-Based Multi-Agent Workflows , author=. 2025 , eprint=
work page 2025
-
[10]
Learned Prefix Caching for Efficient
Dongsheng Yang and Austin Li and Kai Li and Wyatt Lloyd , booktitle=. Learned Prefix Caching for Efficient. 2026 , url=
work page 2026
-
[13]
QWEN Bailian usage traces (anon.)
Alibaba Edu . QWEN Bailian usage traces (anon.). https://github.com/alibaba-edu/qwen-bailian-usagetraces-anon, 2025. GitHub repository
work page 2025
-
[14]
Unicache: A unified batch-level learning-based content caching
Yanting Chen, Xu Zhang, Yuchen Yang, Chengying Huan, Shaonan Ma, Jiawei Ye, Peng Wang, and Jie Wu. Unicache: A unified batch-level learning-based content caching. In 33rd IEEE/ACM International Symposium on Quality of Service, IWQoS 2025, Gold Coast, Australia, July 2-4, 2025 , pages 1--10. IEEE , 2025. doi:10.1109/IWQOS65803.2025.11143380. URL https://do...
-
[15]
Token prediction as implicit classification to identify LLM -generated text
Yutian Chen, Hao Kang, Vivian Zhai, Liangze Li, Rita Singh, and Bhiksha Raj. Token prediction as implicit classification to identify LLM -generated text. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13112--13120, Singapore, December 2023. Association fo...
-
[16]
Cost-efficient large language model serving for multi-turn conversations with cachedattention
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. Cost-efficient large language model serving for multi-turn conversations with cachedattention. In Saurabh Bagchi and Yiying Zhang, editors, Proceedings of the 2024 USENIX Annual Technical Conference, USENIX ATC 2024, Santa Clara, CA, USA, ...
work page 2024
-
[17]
Efficient Memory Management for Large Language Model Serving with PagedAttention , booktitle =
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Jason Flinn, Margo I. Seltzer, Peter Druschel, Antoine Kaufmann, and Jonathan Mace, editors, Proceedings of the 29th Symposium on Operating Systems ...
-
[18]
Continuum: Efficient and Robust Multi-Turn LLM Agent Scheduling with KV Cache Time-to-Live
Hanchen Li, Qiuyang Mang, Runyuan He, Qizheng Zhang, Huanzhi Mao, Xiaokun Chen, Alvin Cheung, Joseph Gonzalez, and Ion Stoica. Continuum: Efficient and robust multi-turn LLM agent scheduling with KV cache time-to-live. CoRR, abs/2511.02230, 2025. doi:10.48550/ARXIV.2511.02230. URL https://doi.org/10.48550/arXiv.2511.02230
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.02230 2025
-
[19]
Marconi: Prefix caching for the era of hybrid llms.arXiv preprint arXiv:2411.19379, 2024
Rui Pan, Zhuang Wang, Zhen Jia, Can Karakus, Luca Zancato, Tri Dao, Yida Wang, and Ravi Netravali. Marconi: Prefix caching for the era of hybrid llms, 2025 a . URL https://arxiv.org/abs/2411.19379
-
[20]
Kvflow: Efficient prefix caching for accelerating llm-based multi-agent workflows, 2025 b
Zaifeng Pan, Ajjkumar Patel, Zhengding Hu, Yipeng Shen, Yue Guan, Wan-Lu Li, Lianhui Qin, Yida Wang, and Yufei Ding. Kvflow: Efficient prefix caching for accelerating llm-based multi-agent workflows, 2025 b . URL https://arxiv.org/abs/2507.07400
-
[21]
Preble: Efficient distributed prompt scheduling for LLM serving
Vikranth Srivatsa, Zijian He, Reyna Abhyankar, Dongming Li, and Yiying Zhang. Preble: Efficient distributed prompt scheduling for LLM serving. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025. URL https://openreview.net/forum?id=meKEKDhdnx
work page 2025
-
[22]
Learned prefix caching for efficient LLM inference
Dongsheng Yang, Austin Li, Kai Li, and Wyatt Lloyd. Learned prefix caching for efficient LLM inference. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=Vj48eXaQDM
work page 2026
-
[23]
CC-Bench trajectories: Agentic coding task trajectories
Z.ai . CC-Bench trajectories: Agentic coding task trajectories. https://huggingface.co/datasets/zai-org/CC-Bench-trajectories, 2025. Hugging Face Datasets
work page 2025
-
[24]
Jenga: Effective memory management for serving LLM with heterogeneity
Chen Zhang, Kuntai Du, Shu Liu, Woosuk Kwon, Xiangxi Mo, Yufeng Wang, Xiaoxuan Liu, Kaichao You, Zhuohan Li, Mingsheng Long, Jidong Zhai, Joseph Gonzalez, and Ion Stoica. Jenga: Effective memory management for serving LLM with heterogeneity. In Youjip Won, Youngjin Kwon, Ding Yuan, and Rebecca Isaacs, editors, Proceedings of the ACM SIGOPS 31st Symposium ...
-
[25]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark W. Barrett, and Ying Sheng. Sglang: Efficient execution of structured language model programs. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zh...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.