Bridging 3D Gaussians and Semantic Occupancy for Comprehensive Open-Vocabulary Scene Understanding from Unposed Images
Pith reviewed 2026-07-03 16:54 UTC · model grok-4.3
The pith
COVScene lifts semantic Gaussians into a dense occupancy field inside the training graph so volumetric regularization supplies gradients to opacity, geometry, and semantics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
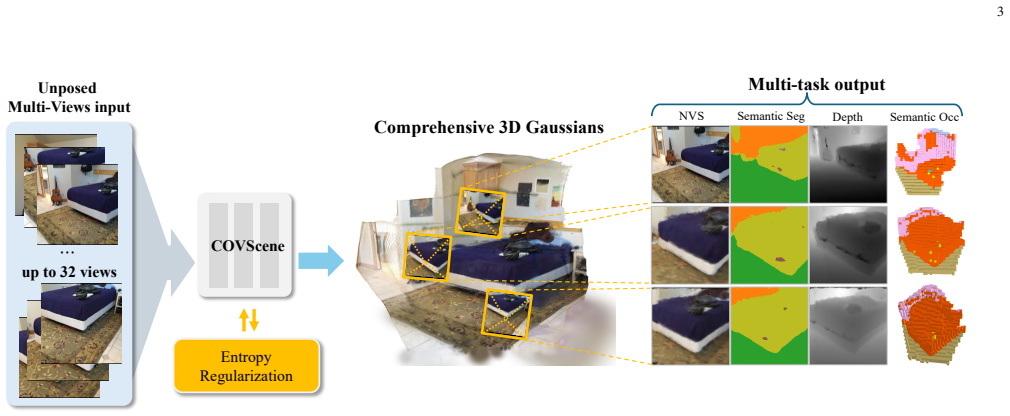
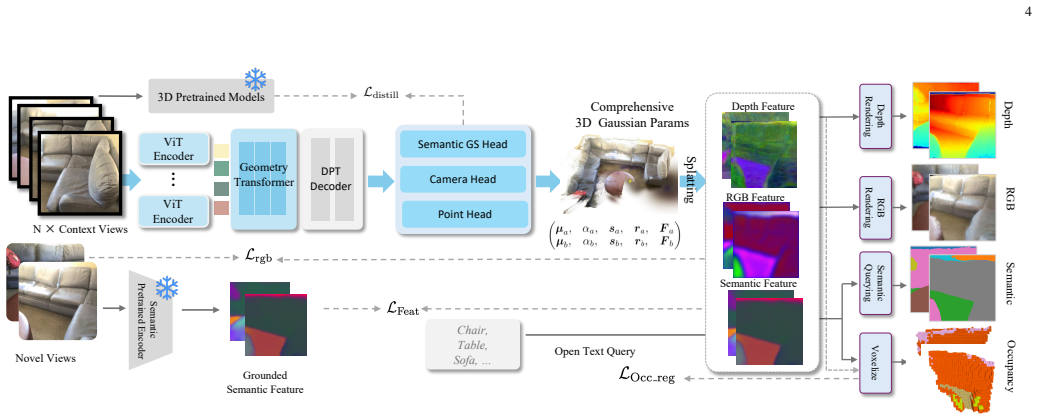
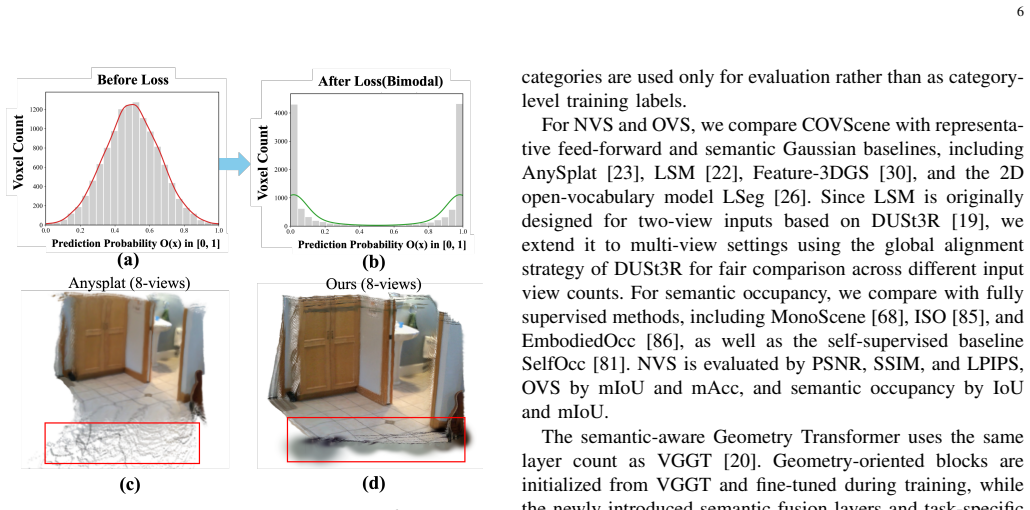
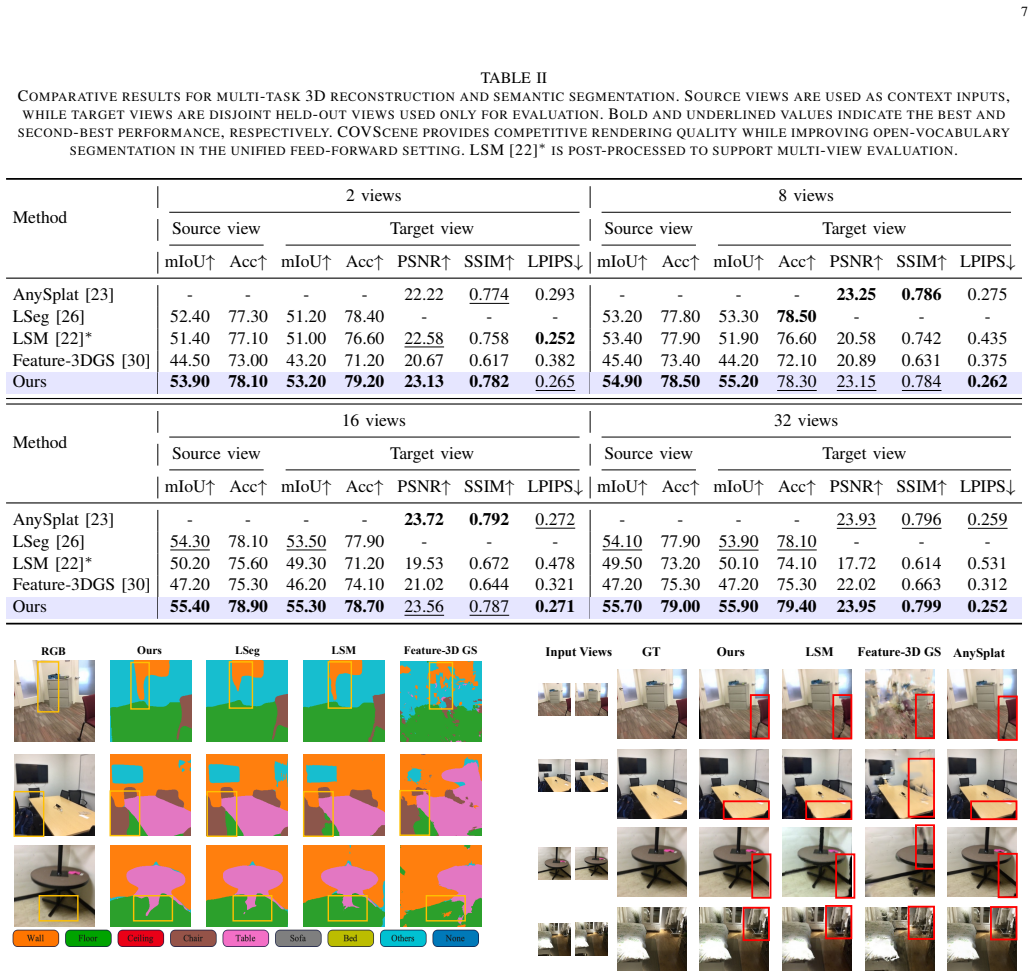
By lifting the predicted semantic Gaussians into an occupancy field inside the training computation graph, COVScene allows volumetric regularization to directly optimize Gaussian opacity, geometry, and semantic features, yielding improved open-vocabulary segmentation and semantic occupancy prediction from sparse unposed images without any direct voxel supervision.
What carries the argument
Differentiable volumetric lifting that converts semantic Gaussians into a dense occupancy field during training and back-propagates occupancy regularization gradients to the Gaussians.
If this is right
- Novel view synthesis quality remains competitive while semantic tasks are added.
- Open-vocabulary segmentation accuracy rises relative to image-space-only Gaussian baselines.
- Semantic occupancy prediction improves over self-supervised methods that lack voxel supervision.
- A single set of Gaussians supports rendering, semantic queries, and occupancy output.
Where Pith is reading between the lines
- The same lifting idea could be applied to other explicit 3D representations to regularize unobserved space.
- Removing the need for external calibration and voxel labels may simplify deployment on consumer cameras.
- The occupancy field produced at inference time could be tested directly for downstream tasks such as path planning.
Load-bearing premise
That differentiable lifting of Gaussians into an occupancy field will generate useful gradients for unobserved regions and keep occupancy predictions accurate without any direct voxel-level supervision.
What would settle it
If ablating the volumetric lifting step during training produces equal or better semantic occupancy accuracy on held-out ScanNet scenes, the claimed benefit of the coupling collapses.
Figures

read the original abstract
Comprehensive 3D scene understanding from sparse, unposed images requires a model to recover renderable geometry, open-vocabulary semantics, and free/occupied 3D space without relying on external camera calibration. Recent feed-forward Gaussian methods improve pose-free reconstruction and semantic rendering, but their Gaussian primitives are mainly optimized through image-space objectives and remain weakly constrained in unobserved regions. We propose \textit{COVScene}, a pose-free semantic Gaussian framework that couples renderable Gaussian primitives with a dense semantic occupancy field through differentiable volumetric lifting. Instead of converting Gaussians to voxels only at evaluation time, COVScene lifts the predicted semantic Gaussians inside the training computation graph, so volumetric regularization provides gradients to Gaussian opacity, geometry, and semantic features. The framework combines a semantic-aware Geometry Transformer, multi-task Gaussian decoding, geometric foundation distillation, and occupancy entropy regularization to support novel view synthesis, open-vocabulary semantic querying, and semantic occupancy prediction within a single representation. Experiments on ScanNet and ScanNet++ show that COVScene maintains competitive rendering quality, improves open-vocabulary segmentation, and achieves stronger semantic occupancy prediction than the self-supervised baseline without direct voxel-level supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces COVScene, a pose-free framework that couples semantic 3D Gaussian primitives with a dense semantic occupancy field via differentiable volumetric lifting inside the training graph. Volumetric regularization (occupancy entropy) is claimed to back-propagate gradients to Gaussian opacity, geometry, and features, including in unobserved regions. The method integrates a semantic-aware Geometry Transformer, multi-task Gaussian decoding, geometric foundation distillation, and entropy regularization to jointly support novel-view synthesis, open-vocabulary semantic querying, and semantic occupancy prediction. Experiments on ScanNet and ScanNet++ report competitive rendering quality alongside gains in open-vocabulary segmentation and occupancy prediction relative to a self-supervised baseline that lacks direct voxel supervision.
Significance. If the differentiable lifting successfully supplies non-vanishing gradients to unobserved Gaussians, the work would meaningfully advance unified Gaussian-volumetric representations for self-supervised 3D scene understanding. The single-representation multi-task design and avoidance of external calibration or voxel labels are notable strengths; the use of geometric foundation distillation is also a constructive element.
major comments (2)
- [Abstract / §3] Abstract and method description: the central claim that occupancy entropy regularization supplies informative gradients to Gaussian parameters for regions outside all training camera frustums is load-bearing yet unsupported by any derivation or sensitivity analysis of the lifting operator (splatting/alpha-compositing integral). Without this, it remains possible that image-space losses dominate and unobserved geometry/semantics stay under-constrained, undermining the reported occupancy gains without voxel supervision.
- [Experiments] Experiments section: quantitative improvements on ScanNet are stated without error bars, standard deviations across runs, or ablations isolating the contribution of volumetric lifting versus the Geometry Transformer or foundation distillation; this prevents verification that the occupancy regularization is the operative factor.
minor comments (3)
- [Abstract] The abstract does not specify the exact form of the lifting operator or how occupancy is queried from Gaussians inside the computation graph, hindering immediate reproducibility.
- [Method] Notation for the semantic occupancy field and its relation to Gaussian opacity is introduced without an explicit equation linking the two representations.
- [Figures / Tables] Figure captions and table headers should clarify whether reported metrics are computed only on observed or also on extrapolated voxels.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify areas where additional technical detail and experimental rigor would strengthen the manuscript. We address each point below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and method description: the central claim that occupancy entropy regularization supplies informative gradients to Gaussian parameters for regions outside all training camera frustums is load-bearing yet unsupported by any derivation or sensitivity analysis of the lifting operator (splatting/alpha-compositing integral). Without this, it remains possible that image-space losses dominate and unobserved geometry/semantics stay under-constrained, undermining the reported occupancy gains without voxel supervision.
Authors: We agree that an explicit derivation of gradient flow through the differentiable volumetric lifting operator is needed to substantiate the claim. In the revised manuscript we will add a dedicated subsection deriving the back-propagation of the occupancy entropy loss through the alpha-compositing integral, showing that the integral admits non-zero gradients for Gaussians whose projected support lies outside any training frustum. We will also include a sensitivity analysis (gradient magnitude plots and ablation on frustum masking) confirming that the entropy term supplies informative gradients to unobserved regions rather than being dominated by image-space losses. revision: yes
-
Referee: [Experiments] Experiments section: quantitative improvements on ScanNet are stated without error bars, standard deviations across runs, or ablations isolating the contribution of volumetric lifting versus the Geometry Transformer or foundation distillation; this prevents verification that the occupancy regularization is the operative factor.
Authors: We acknowledge that the current experimental section lacks statistical reporting and targeted ablations. In the revision we will (i) report mean and standard deviation of all metrics across five independent runs with different random seeds, and (ii) add a new ablation table that systematically disables volumetric lifting while keeping the Geometry Transformer and foundation distillation fixed (and vice versa). These additions will isolate the contribution of occupancy entropy regularization and allow readers to verify its role in the reported gains. revision: yes
Circularity Check
No circularity: derivation relies on external distillation and independent regularization
full rationale
The abstract and description present COVScene as a new framework that introduces differentiable volumetric lifting of Gaussians into an occupancy field, combined with geometric foundation distillation and entropy regularization. No equations, fitted parameters, or self-citations are shown that reduce any prediction to its own inputs by construction. The lifting step is presented as an architectural choice providing gradients, not as a self-referential fit. The method is benchmarked against external baselines on ScanNet/ScanNet++ without evidence of load-bearing self-citation chains or ansatz smuggling. This is the common case of a self-contained proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pi-net: Point-to-image knowledge distillation for camera-based 3d semantic scene completion,
Y . Xue, H. Pi, Z. Tang, K. Li, and R. Li, “Pi-net: Point-to-image knowledge distillation for camera-based 3d semantic scene completion,” IEEE Transactions on Multimedia, 2026. 9
2026
-
[2]
From front to rear: 3d semantic scene completion through planar convolution and attention- based network,
J. Li, Q. Song, X. Yan, Y . Chen, and R. Huang, “From front to rear: 3d semantic scene completion through planar convolution and attention- based network,”IEEE Transactions on Multimedia, 2023
2023
-
[3]
3dgeodet: General-purpose geometry-aware image-based 3d object detection,
Y . Zhang, Y . Wang, Y . Cui, and L.-P. Chau, “3dgeodet: General-purpose geometry-aware image-based 3d object detection,”IEEE Transactions on Multimedia, 2025
2025
-
[4]
Convolutional neural network-based occupancy map accuracy improvement for video-based point cloud compression,
W. Jia, L. Li, A. Akhtar, Z. Li, and S. Liu, “Convolutional neural network-based occupancy map accuracy improvement for video-based point cloud compression,”IEEE Transactions on Multimedia, 2022
2022
-
[5]
3ur-llm: An end- to-end multimodal large language model for 3d scene understanding,
H. Xiong, Y . Zhuge, J. Zhu, L. Zhang, and H. Lu, “3ur-llm: An end- to-end multimodal large language model for 3d scene understanding,” IEEE Transactions on Multimedia, 2025
2025
-
[6]
Adaptive in adapter: Boosting open-vocabulary semantic segmentation with adaptive dropout adapter,
C. Wang, W. Xu, R. Xu, Z. Zhang, S. Xu, J. Zhang, X. Teng, W. Meng, and X. Zhang, “Adaptive in adapter: Boosting open-vocabulary semantic segmentation with adaptive dropout adapter,”IEEE Transactions on Multimedia, 2026
2026
-
[7]
Det-agent: Open- vocabulary object localization and detection with reinforcement learning agent,
R. Zhang, X.-J. Wu, C. Wang, and C.-L. Liu, “Det-agent: Open- vocabulary object localization and detection with reinforcement learning agent,”IEEE Transactions on Multimedia, 2026
2026
-
[8]
Unleash the power of vision-language models by visual attention prompt and multimodal interaction,
W. Zhang, L. Wu, Z. Zhang, T. Yu, C. Ma, X. Jin, X. Yang, and W. Zeng, “Unleash the power of vision-language models by visual attention prompt and multimodal interaction,”IEEE Transactions on Multimedia, 2025
2025
-
[9]
Cas-ovd: Cascaded open-vocabulary detection of small objects using multi-refined region proposal network in autonomous driving,
Z. Fang, Y . Wu, J. Ren, J. Zheng, Y . Yan, and L. Zhang, “Cas-ovd: Cascaded open-vocabulary detection of small objects using multi-refined region proposal network in autonomous driving,”IEEE Transactions on Multimedia, 2026
2026
-
[10]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” inECCV, 2020
2020
-
[11]
3d gaussian splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering,”ACM Transactions on Graphics, 2023
2023
-
[12]
Structure-from-motion revisited,
J. L. Schonberger and J.-M. Frahm, “Structure-from-motion revisited,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016
2016
-
[13]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d re- construction,
D. Charatan, S. L. Li, A. Tagliasacchi, and V . Sitzmann, “pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d re- construction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024
2024
-
[14]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images,
Y . Chen, H. Xu, C. Zheng, B. Zhuang, M. Pollefeys, A. Geiger, T.-J. Cham, and J. Cai, “Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images,” inEuropean Conference on Computer Vision, 2024
2024
-
[15]
VolSplat: Rethinking Feed-Forward 3D Gaussian Splatting with Voxel-Aligned Prediction
W. Wang, Y . Chen, Z. Zhang, H. Liu, H. Wang, Z. Feng, W. Qin, Z. Zhu, D. Y . Chen, and B. Zhuang, “V olsplat: Rethinking feed-forward 3d gaussian splatting with voxel-aligned prediction,”arXiv preprint arXiv:2509.19297, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images,
B. Ye, S. Liu, H. Xu, X. Li, M. Pollefeys, M.-H. Yang, and S. Peng, “No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images,” inInternational Conference on Learning Representa- tions (ICLR), 2025
2025
-
[17]
Splatter image: Ultra- fast single-view 3d reconstruction,
S. Szymanowicz, C. Rupprecht, and A. Vedaldi, “Splatter image: Ultra- fast single-view 3d reconstruction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024
2024
-
[18]
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
B. Smart, C. Zheng, I. Laina, and V . A. Prisacariu, “Splatt3r: Zero- shot gaussian splatting from uncalibrated image pairs,”arXiv preprint arXiv:2408.13912, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Dust3r: Geometric 3d vision made easy,
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud, “Dust3r: Geometric 3d vision made easy,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[20]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[21]
Mapanything: Universal feed-forward metric 3d re- construction,
N. Keetha, N. M ¨uller, J. Sch ¨onberger, L. Porzi, Y . Zhang, T. Fischer, A. Knapitsch, D. Zauss, E. Weber, N. Antunes, J. Luiten, M. Lopez- Antequera, S. R. Bul `o, C. Richardt, D. Ramanan, S. Scherer, and P. Kontschieder, “Mapanything: Universal feed-forward metric 3d re- construction,” inInternational Conference on 3D Vision (3DV), 2026
2026
-
[22]
Large spatial model: End-to- end unposed images to semantic 3d,
Z. Fan, J. Zhang, W. Cong, P. Wang, R. Li, K. Wen, S. Zhou, A. Kadambi, Z. Wang, D. Xuet al., “Large spatial model: End-to- end unposed images to semantic 3d,”Advances in neural information processing systems, 2024
2024
-
[23]
Anysplat: Feed-forward 3d gaussian splatting from unconstrained views,
L. Jiang, Y . Mao, L. Xu, T. Lu, K. Ren, Y . Jin, X. Xu, M. Yu, J. Pang, F. Zhaoet al., “Anysplat: Feed-forward 3d gaussian splatting from unconstrained views,”ACM Transactions on Graphics (TOG), 2025
2025
-
[24]
Q. Tian, X. Tan, J. Gong, Y . Xie, and L. Ma, “Uniforward: Unified 3d scene and semantic field reconstruction via feed-forward gaussian splat- ting from only sparse-view images,”arXiv preprint arXiv:2506.09378, 2025
-
[25]
X. Sun, H. Jiang, L. Liu, S. Nam, G. Kang, X. Wang, W. Sui, Z. Su, W. Liu, X. Wang, and E. Park, “Uni3r: Unified 3d reconstruction and semantic understanding via generalizable gaussian splatting from unposed multi-view images,”arXiv preprint arXiv:2508.03643, 2025
-
[26]
Language-driven semantic segmentation,
B. Li, K. Q. Weinberger, S. J. Belongie, V . Koltun, and R. Ranftl, “Language-driven semantic segmentation,” inInternational Conference on Learning Representations, 2022
2022
-
[27]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning, 2021
2021
-
[28]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[29]
Semantic gaussians: Open-vocabulary scene understanding with 3d gaussian splatting,
J. Guo, X. Ma, Y . Fan, H. Liu, and Q. Li, “Semantic gaussians: Open-vocabulary scene understanding with 3d gaussian splatting,”arXiv preprint arXiv:2403.15624, 2024
-
[30]
Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields,
S. Zhou, H. Chang, S. Jiang, Z. Fan, Z. Zhu, D. Xu, P. Chari, S. You, Z. Wang, and A. Kadambi, “Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[31]
Language embedded 3d gaussians for open-vocabulary scene understanding,
J.-C. Shi, M. Wang, H.-B. Duan, and S.-H. Guan, “Language embedded 3d gaussians for open-vocabulary scene understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2024
2024
-
[32]
Language embedded 3d gaussians for open-vocabulary scene querying,
M. Wang, J.-C. Shi, S.-H. Guan, and H.-B. Duan, “Language embedded 3d gaussians for open-vocabulary scene querying,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[33]
Spatialsplat: Efficient semantic 3d from sparse unposed images,
Y . Sheng, J. Deng, X. Zhang, Y . Zhang, B. Hua, Y . Zhang, and J. Ji, “Spatialsplat: Efficient semantic 3d from sparse unposed images,”arXiv preprint arXiv:2505.23044, 2025
-
[34]
Freesplat: Generalizable 3d gaussian splatting towards free view synthesis of indoor scenes,
Y . Wang, T. Huang, H. Chen, and G. H. Lee, “Freesplat: Generalizable 3d gaussian splatting towards free view synthesis of indoor scenes,” Advances in Neural Information Processing Systems, 2024
2024
-
[35]
Scannet: Richly-annotated 3d reconstructions of indoor scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017
2017
-
[36]
Scannet++: A high- fidelity dataset of 3d indoor scenes,
C. Yeshwanth, Y .-C. Liu, M. Nießner, and A. Dai, “Scannet++: A high- fidelity dataset of 3d indoor scenes,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[37]
pixelNeRF: Neural radiance fields from one or few images,
A. Yu, V . Ye, M. Tancik, and A. Kanazawa, “pixelNeRF: Neural radiance fields from one or few images,” inCVPR, 2021
2021
-
[38]
Fusing panoptic seg- mentation and geometry information for robust visual slam in dynamic environments,
H. Zhu, C. Yao, Z. Zhu, Z. Liu, and Z. Jia, “Fusing panoptic seg- mentation and geometry information for robust visual slam in dynamic environments,” inCASE, 2022
2022
-
[39]
Instant neural graphics primitives with a multiresolution hash encoding,
T. M ¨uller, A. Evans, C. Schied, and A. Keller, “Instant neural graphics primitives with a multiresolution hash encoding,”ACM Trans. Graph., 2022
2022
-
[40]
K-planes: Explicit radiance fields in space, time, and appearance,
S. Fridovich-Keil, G. Meanti, F. R. Warburg, B. Recht, and A. Kanazawa, “K-planes: Explicit radiance fields in space, time, and appearance,” in CVPR, 2023
2023
-
[41]
Epipolar transformers,
Y . He, R. Yan, K. Fragkiadaki, and S.-I. Yu, “Epipolar transformers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020
2020
-
[42]
Mvsnet: Depth inference for unstructured multi-view stereo,
Y . Yao, Z. Luo, S. Li, T. Fang, and L. Quan, “Mvsnet: Depth inference for unstructured multi-view stereo,”European Conference on Computer Vision (ECCV), 2018
2018
-
[43]
Mvsplat360: Feed-forward 360 scene synthesis from sparse views,
Y . Chen, C. Zheng, H. Xu, B. Zhuang, A. Vedaldi, T.-J. Cham, and J. Cai, “Mvsplat360: Feed-forward 360 scene synthesis from sparse views,”Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[44]
Drivingforward: Feed-forward 3d gaussian splatting for driving scene reconstruction from flexible surround-view input,
Q. Tian, X. Tan, Y . Xie, and L. Ma, “Drivingforward: Feed-forward 3d gaussian splatting for driving scene reconstruction from flexible surround-view input,” inProceedings of the AAAI Conference on Ar- tificial Intelligence, 2025
2025
-
[45]
Yonosplat: You only need one model for feedforward 3d gaussian splatting,
B. Ye, B. Chen, H. Xu, D. Barath, and M. Pollefeys, “Yonosplat: You only need one model for feedforward 3d gaussian splatting,” in International Conference on Learning Representations (ICLR), 2026
2026
-
[46]
Mv-dust3r+: Single-stage scene reconstruction from sparse 10 views in 2 seconds,
Z. Tang, Y . Fan, D. Wang, H. Xu, R. Ranjan, A. Schwing, and Z. Yan, “Mv-dust3r+: Single-stage scene reconstruction from sparse 10 views in 2 seconds,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025
2025
-
[47]
Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views,
S. Zhang, J. Wang, Y . Xu, N. Xue, C. Rupprecht, X. Zhou, Y . Shen, and G. Wetzstein, “Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025
2025
-
[48]
Pf3plat: Pose-free feed-forward 3d gaussian splatting for novel view synthesis,
S. Hong, J. Jung, H. Shin, J. Han, J. Yang, C. Luo, and S. Kim, “Pf3plat: Pose-free feed-forward 3d gaussian splatting for novel view synthesis,” inForty-second International Conference on Machine Learning, 2025
2025
-
[49]
Lerf: Language embedded radiance fields,
J. Kerr, C. M. Kim, K. Goldberg, A. Kanazawa, and M. Tancik, “Lerf: Language embedded radiance fields,” inInternational Conference on Computer Vision (ICCV), 2023
2023
-
[50]
One at a time: Progressive multi-step volumetric probability learning for reliable 3d scene perception,
B. Li, Y . Sun, J. Dong, Z. Zhu, J. Liu, X. Jin, and W. Zeng, “One at a time: Progressive multi-step volumetric probability learning for reliable 3d scene perception,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 4, 2024, pp. 3028–3036
2024
-
[51]
Garfield: Group anything with radiance fields,
C. M. Kim, M. Wu, J. Kerr, M. Tancik, K. Goldberg, and A. Kanazawa, “Garfield: Group anything with radiance fields,” inConference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[52]
B. Li, Y . Sun, Z. Liang, D. Du, Z. Zhang, X. Wang, Y . Wang, X. Jin, and W. Zeng, “Bridging stereo geometry and bev representation with reliable mutual interaction for semantic scene completion,”arXiv preprint arXiv:2303.13959, 2023
-
[53]
Langsplat: 3d language gaussian splatting,
M. Qin, W. Li, J. Zhou, H. Wang, and H. Pfister, “Langsplat: 3d language gaussian splatting,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[54]
OmniNWM: Omniscient Driving Navigation World Models
B. Li, Z. Ma, D. Du, B. Peng, Z. Liang, Z. Liu, C. Ma, Y . Jin, H. Zhao, W. Zenget al., “Omninwm: Omniscient driving navigation world models,”arXiv preprint arXiv:2510.18313, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Occscene: Semantic occupancy-based cross-task mutual learning for 3d scene generation,
B. Li, X. Jin, J. Wang, Y . Shi, Y . Sun, X. Wang, Z. Ma, B. Xie, C. Ma, X. Yanget al., “Occscene: Semantic occupancy-based cross-task mutual learning for 3d scene generation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[56]
Opensplat3d: Open-vocabulary 3d instance segmentation using gaussian splatting,
J. Piekenbrinck, C. Schmidt, A. Hermans, N. Vaskevicius, T. Linder, and B. Leibe, “Opensplat3d: Open-vocabulary 3d instance segmentation using gaussian splatting,” inProceedings of the Computer Vision and Pattern Recognition Conference (CVPR) Workshops, 2025
2025
-
[57]
B. Li, S. Yang, B. Peng, X. Guo, E. Zhang, Y . Tao, J. Duan, D. Xu, Q. Dou, X. Jinet al., “From articulated kinematics to routed visual control for action-conditioned surgical video generation,”arXiv preprint arXiv:2605.08712, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
Uniscene: Unified occupancy-centric driving scene generation,
B. Li, J. Guo, H. Liu, Y . Zou, Y . Ding, X. Chen, H. Zhu, F. Tan, C. Zhang, T. Wanget al., “Uniscene: Unified occupancy-centric driving scene generation,” inProceedings of the computer vision and pattern recognition conference, 2025, pp. 11 971–11 981
2025
-
[59]
Hierarchical context alignment with disentangled geometric and temporal modeling for semantic occupancy prediction,
B. Li, J. Deng, Y . Sun, X. Wang, X. Jin, and W. Zeng, “Hierarchical context alignment with disentangled geometric and temporal modeling for semantic occupancy prediction,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[60]
4d langsplat: 4d language gaussian splatting via multimodal large language models,
W. Li, R. Zhou, J. Zhou, Y . Song, J. Herter, M. Qin, G. Huang, and H. Pfister, “4d langsplat: 4d language gaussian splatting via multimodal large language models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[61]
Tun3d: Towards real-world scene understanding from unposed images,
A. Konushin, N. Drozdov, B. Gabdullin, A. Zakharov, A. V orontsova, D. Rukhovich, and M. Kolodiazhnyi, “Tun3d: Towards real-world scene understanding from unposed images,” inIEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[62]
Jiang, A. Tagliasacchi, M. Pollefeys, and T. Funkhouser, “Openscene: 3d scene understanding with open vocabu- laries,
S. Peng, K. Genova, C. “. Jiang, A. Tagliasacchi, M. Pollefeys, and T. Funkhouser, “Openscene: 3d scene understanding with open vocabu- laries,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[63]
Roboocc: Enhancing the geometric and semantic scene understanding for robots,
Z. Zhang, Q. Zhang, W. Cui, S. Shi, Y . Guo, G. Han, W. Zhao, H. Ren, R. Xu, and J. Tang, “Roboocc: Enhancing the geometric and semantic scene understanding for robots,”arXiv preprint arXiv:2504.14604, 2025
-
[64]
Gaussian grouping: Segment and edit anything in 3d scenes,
M. Ye, M. Danelljan, F. Yu, and L. Ke, “Gaussian grouping: Segment and edit anything in 3d scenes,” inECCV, 2024
2024
-
[65]
Ov-nerf: Open-vocabulary neural radiance fields with vision and language foundation models for 3d semantic understanding,
G. Liao, K. Zhou, Z. Bao, K. Liu, and Q. Li, “Ov-nerf: Open-vocabulary neural radiance fields with vision and language foundation models for 3d semantic understanding,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[66]
Fast and efficient: Mask neural fields for 3d scene segmentation,
Z. Gao, L. Li, L. Jiao, F. Liu, X. Liu, W. Ma, Y . Guo, and S. Yang, “Fast and efficient: Mask neural fields for 3d scene segmentation,”arXiv preprint arXiv:2407.01220, 2024
-
[67]
Q. Tian, X. Tan, J. Ying, X. Wang, Y . Xie, and L. Ma, “Fleg: Feed- forward language embedded gaussian splatting from any views,”arXiv preprint arXiv:2512.17541, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Monoscene: Monocular 3d semantic scene completion,
A.-Q. Cao and R. De Charette, “Monoscene: Monocular 3d semantic scene completion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[69]
Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving,
Y . Wei, L. Zhao, W. Zheng, Z. Zhu, J. Zhou, and J. Lu, “Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving,”2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[70]
Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving,
X. Tian, T. Jiang, L. Yun, Y . Mao, H. Yang, Y . Wang, Y . Wang, and H. Zhao, “Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving,” inThirty-seventh Conference on Neural Informa- tion Processing Systems Datasets and Benchmarks Track, 2023
2023
-
[71]
Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception,
X. Wang, Z. Zhu, W. Xu, Y . Zhang, Y . Wei, X. Chi, Y . Ye, D. Du, J. Lu, and X. Wang, “Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception,”2023 IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), 2023
2023
-
[72]
Semantickitti: A dataset for semantic scene understand- ing of lidar sequences,
J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall, “Semantickitti: A dataset for semantic scene understand- ing of lidar sequences,”2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019
2019
-
[73]
Scaling up occupancy-centric driving scene generation: Dataset and method,
B. Li, X. Jin, H. Zhu, H. Liu, R. Li, J. Guo, K. Cai, C. Ma, Y . Jin, H. Zhaoet al., “Scaling up occupancy-centric driving scene generation: Dataset and method,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[74]
Tri- perspective view for vision-based 3d semantic occupancy prediction,
Y .-K. Huang, W. Zheng, Y . Zhang, J. Zhou, and J. Lu, “Tri- perspective view for vision-based 3d semantic occupancy prediction,” 2023 IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2023
2023
-
[75]
Occformer: Dual-path transformer for vision-based 3d semantic occupancy prediction,
Y . Zhang, Z. Zhu, and D. Du, “Occformer: Dual-path transformer for vision-based 3d semantic occupancy prediction,”IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), 2023
2023
-
[76]
Hierarchical temporal context learning for camera-based semantic scene completion,
B. Li, J. Deng, W. Zhang, Z. Liang, D. Du, X. Jin, and W. Zeng, “Hierarchical temporal context learning for camera-based semantic scene completion,” inEuropean Conference on Computer Vision, 2024
2024
-
[77]
V oxformer: Sparse voxel transformer for camera- based 3d semantic scene completion,
Y . Li, Z. Yu, C. B. Choy, C. Xiao, J. M. ´Alvarez, S. Fidler, C. Feng, and A. Anandkumar, “V oxformer: Sparse voxel transformer for camera- based 3d semantic scene completion,”2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[78]
Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction,
Y . Huang, W. Zheng, Y . Zhang, J. Zhou, and J. Lu, “Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction,” European Conference on Computer Vision (ECCV), 2024
2024
-
[79]
Gaussianformer-2: Probabilistic gaussian superposition for ef- ficient 3d occupancy prediction,
Y . Huang, A. Thammatadatrakoon, W. Zheng, Y . Zhang, D. Du, and J. Lu, “Gaussianformer-2: Probabilistic gaussian superposition for ef- ficient 3d occupancy prediction,”IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[80]
Semantic causality-aware vision-based 3d occupancy predic- tion,
D. Chen, H. Zheng, Y . Zhou, X. Li, W. Liao, T. He, P. Peng, and J. Shen, “Semantic causality-aware vision-based 3d occupancy predic- tion,”IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.