Finding the Time to Think: Learning Planning Budgets in Real-Time RL
Pith reviewed 2026-06-30 09:24 UTC · model grok-4.3
The pith
A lightweight gating policy learns to select state-dependent planning budgets for agents in real-time RL environments where deliberation consumes time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
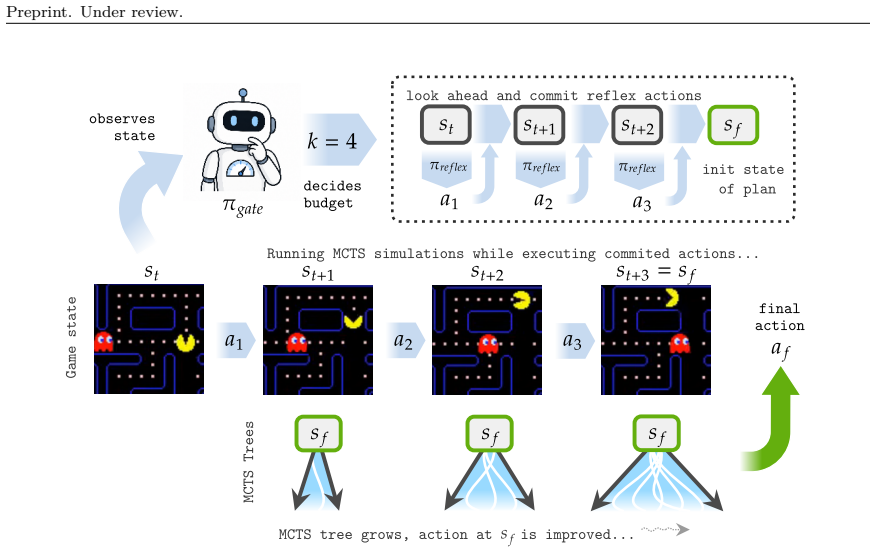
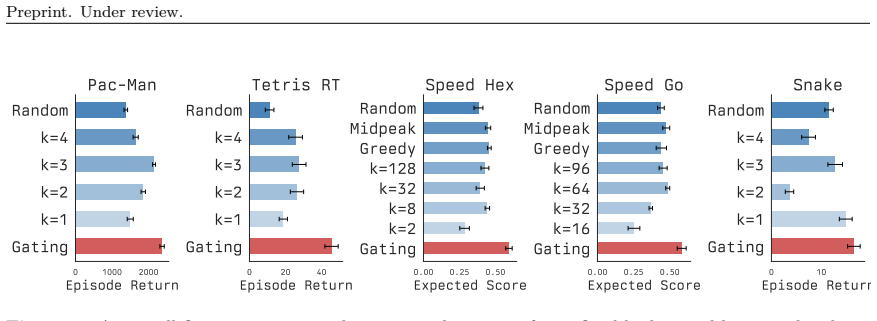
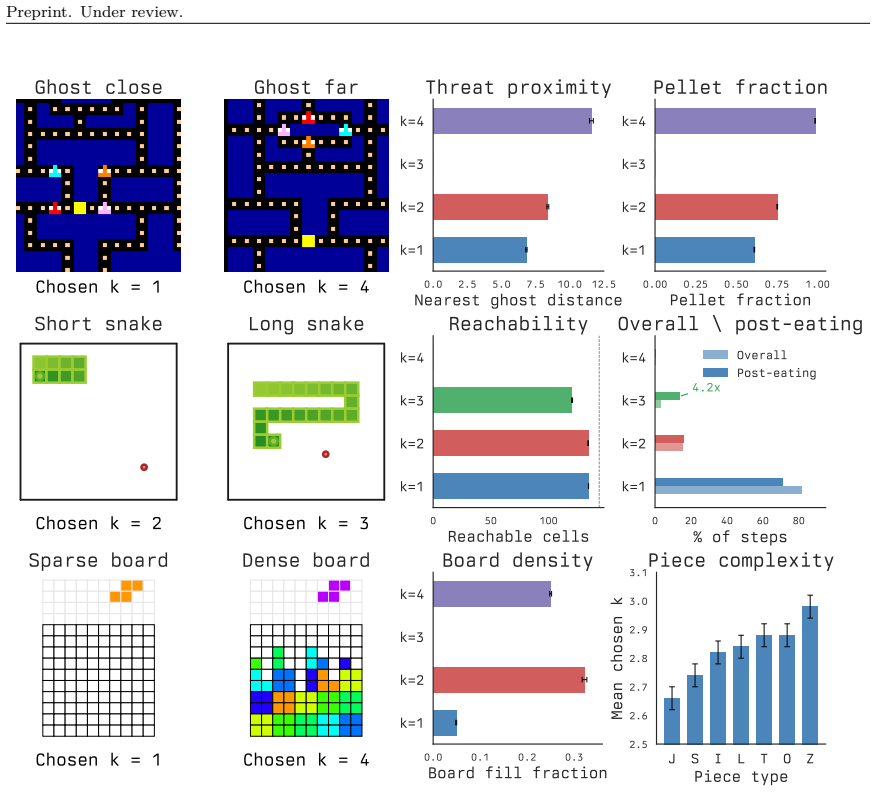
In variable-delay real-time RL the agent selects the duration of deliberation at each decision point because the environment continues to progress. For the planning agents considered, the suitable delay varies with state, yet directly planning the length of the plan itself tends to paralyze action selection. Training a lightweight gating policy to choose state-dependent budgets instead yields higher performance than fixed or heuristic baselines across the tested games and transfers to asynchronous real-time hardware configurations.
What carries the argument
A lightweight gating policy that selects state-dependent planning budgets on top of a base planner.
If this is right
- State-dependent budget selection improves scores over any constant planning time in the real-time game domains.
- The learned gate transfers directly to asynchronous execution where environment and planner run on separate processors.
- Avoiding explicit planning over the budget itself prevents the paralysis observed when agents try to optimize their own thinking time.
- The approach applies uniformly to multiple planning-based agents across distinct real-time environments.
Where Pith is reading between the lines
- Similar gating could be added to planners in continuous-control tasks where action latency directly affects safety or cost.
- Joint training of the gate and the base planner might further reduce the total compute needed for a given performance level.
- In competitive settings the gate could implicitly learn to allocate more time when the opponent is in a threatening state.
Load-bearing premise
The suitable amount of planning time at each moment depends on the current state in a way that a separate policy can learn without excessive overhead.
What would settle it
A controlled comparison in which the best single fixed planning budget, chosen after exhaustive search, matches or exceeds the gating policy's score in every real-time game environment.
Figures

read the original abstract
Deliberating takes time. In real-time settings, that time is not free. Standard reinforcement learning (RL) sidesteps this as the environment waits indefinitely for the agent's decision. Instead, we study real-time RL environments where the environment progresses while waiting for the agent's action. Building on prior real-time formalizations, we introduce variable-delay real-time RL, where the agent chooses how long to deliberate at each decision point since the environment progresses. For the planning agents we use, the right delay is state-dependent, and naively planning how long to plan can paralyze the agent. We instead approach this setting by training a lightweight gating policy on top of a planner to select state-dependent planning budgets. Across real-time Pac-Man, Tetris, Snake, Speed Hex, and Speed Go, our gating policy outperforms fixed-budget and heuristic baselines, and transfers to a real-time setup where the environment and agent run on two different GPUs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces variable-delay real-time RL in which the agent selects a state-dependent deliberation time at each step. It proposes training a lightweight gating policy atop a base planner to choose these planning budgets, avoiding paralysis from naive meta-planning. The gating policy is reported to outperform fixed-budget and heuristic baselines across real-time Pac-Man, Tetris, Snake, Speed Hex, and Speed Go, and to transfer successfully to a two-GPU distributed real-time environment.
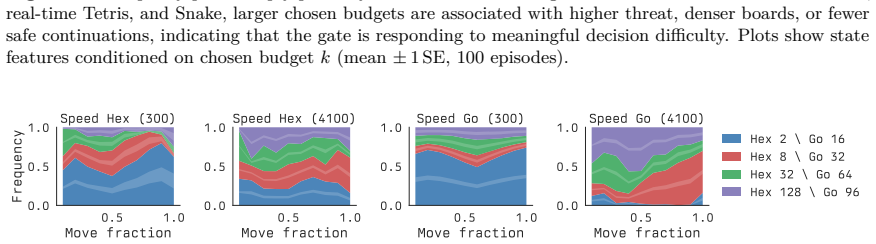
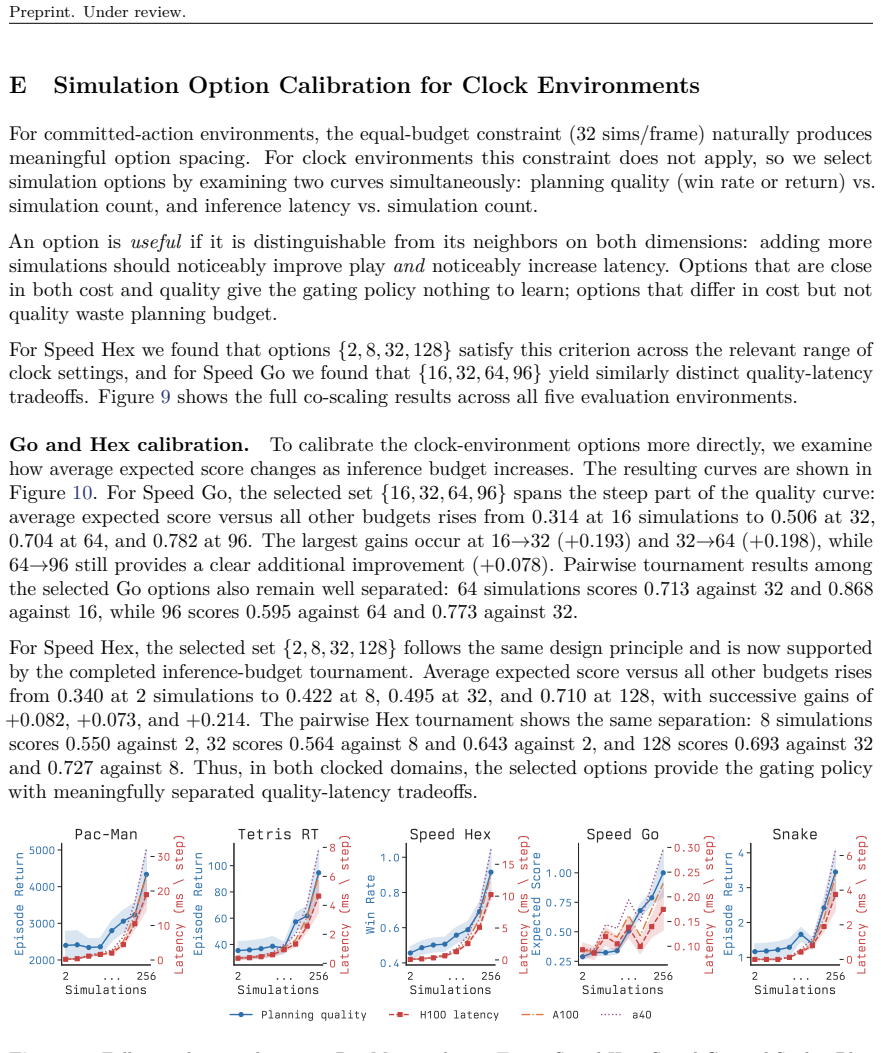
Significance. If the empirical results are robust, the work provides a practical mechanism for adaptive computation in real-time RL settings where environment progress during deliberation is explicit. The multi-game evaluation and the two-GPU transfer experiment are positive elements that would strengthen applicability claims, provided the gating overhead is shown to be negligible.
major comments (2)
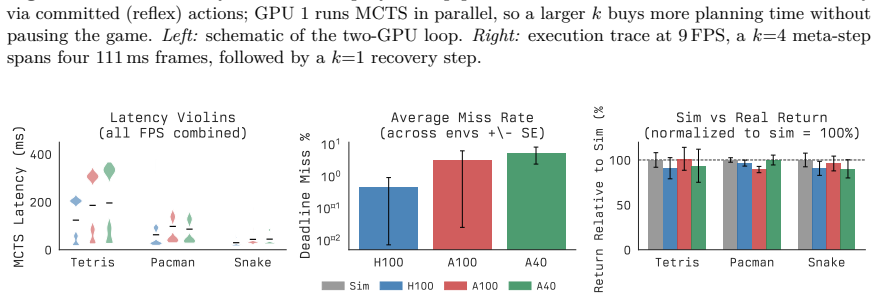
- [real-time transfer experiment] The real-time transfer claim (two-GPU setup) is load-bearing for the strongest result. The manuscript must report measured inference latency of the gating policy itself and demonstrate that this latency remains small relative to the budgets it selects; otherwise the effective planning time deviates from the intended value and comparisons to fixed-budget baselines become invalid.
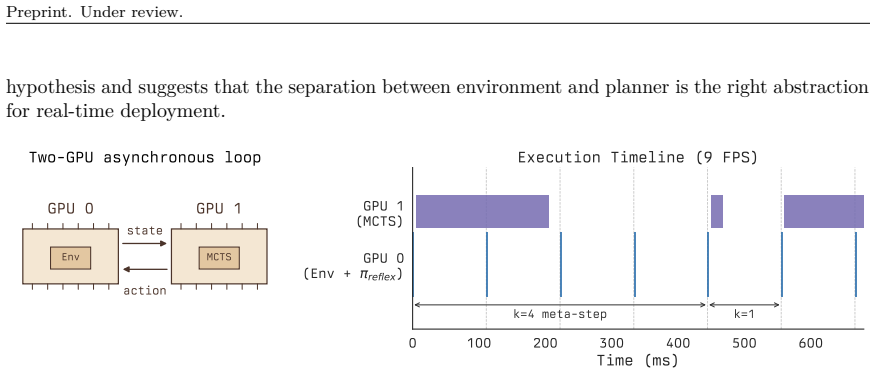
- [experimental evaluation] The outperformance claims across five games rest on quantitative results that are not summarized in the abstract. The paper should include, for each game, mean performance with error bars, number of runs, and explicit controls for total compute or wall-clock time to allow verification that gains are not artifacts of unequal resource allocation.
minor comments (1)
- [method] Clarify the training procedure for the gating policy (reward signal, data collection, and whether it is trained jointly or separately) to make the method reproducible.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [real-time transfer experiment] The real-time transfer claim (two-GPU setup) is load-bearing for the strongest result. The manuscript must report measured inference latency of the gating policy itself and demonstrate that this latency remains small relative to the budgets it selects; otherwise the effective planning time deviates from the intended value and comparisons to fixed-budget baselines become invalid.
Authors: We agree this validation is necessary. In the revision we will add direct measurements of gating-policy inference latency on the same hardware used for the two-GPU experiment and show that the added latency is negligible relative to the budgets chosen by the policy (typically <5% of the smallest budget). This will confirm that the reported planning times remain accurate and that baseline comparisons are unaffected. revision: yes
-
Referee: [experimental evaluation] The outperformance claims across five games rest on quantitative results that are not summarized in the abstract. The paper should include, for each game, mean performance with error bars, number of runs, and explicit controls for total compute or wall-clock time to allow verification that gains are not artifacts of unequal resource allocation.
Authors: The experimental section already reports per-game means, standard deviations, and the number of independent runs (n=10 for all environments). We will (1) insert a concise quantitative summary into the abstract and (2) add an explicit paragraph in the experimental setup detailing the wall-clock-time and total-FLOP budgets enforced across all methods, confirming that every agent receives identical compute resources per decision cycle. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper trains a lightweight gating policy via standard RL to select state-dependent planning budgets in variable-delay real-time environments. The central claim rests on empirical outperformance against fixed-budget and heuristic baselines across multiple games, plus a two-GPU transfer experiment. No equations or steps reduce a claimed prediction or result to a fitted parameter or self-citation by construction; the gating policy is learned independently rather than defined in terms of its own outputs. The derivation chain uses external benchmarks and does not invoke uniqueness theorems or ansatzes from prior self-work as load-bearing justification.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning
Pranjal Aggarwal and Sean Welleck. L1: Controlling how long a reasoning model thinks with reinforcement learning.arXiv preprint arXiv:2503.04697,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Handling delay in real-time reinforcement learning.arXiv preprint arXiv:2503.23478,
Ivan Anokhin, Rishav Rishav, Matthew Riemer, Stephen Chung, Irina Rish, and Samira Ebrahimi Kahou. Handling delay in real-time reinforcement learning.arXiv preprint arXiv:2503.23478,
-
[3]
Pondernet: Learning to ponder.arXiv preprint arXiv:2107.05407,
Andrea Banino, Jan Balaguer, and Charles Blundell. Pondernet: Learning to ponder.arXiv preprint arXiv:2107.05407,
-
[4]
Akhilan Boopathy, Aneesh Muppidi, Peggy Yang, Abhiram Iyer, William Yue, and Ila Fiete
URLhttps://arxiv.org/abs/2306.09884. Akhilan Boopathy, Aneesh Muppidi, Peggy Yang, Abhiram Iyer, William Yue, and Ila Fiete. Permu- tation invariant learning with high-dimensional particle filters.arXiv preprint arXiv:2410.22695,
-
[5]
Learning to select computations
Frederick Callaway, Sayan Gul, Paul M Krueger, Thomas L Griffiths, and Falk Lieder. Learning to select computations.arXiv preprint arXiv:1711.06892,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Lingjiao Chen, Matei Zaharia, and James Zou. Frugalgpt: How to use large language models while reducing cost and improving performance.arXiv preprint arXiv:2305.05176,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Esther Derman, Gal Dalal, and Shie Mannor
URLhttp://github.com/deepmind. Esther Derman, Gal Dalal, and Shie Mannor. Acting in delayed environments with non-stationary markov policies.arXiv preprint arXiv:2101.11992,
-
[8]
Thinkless: Llm learns when to think.arXiv preprint arXiv:2505.13379,
Gongfan Fang, Xinyin Ma, and Xinchao Wang. Thinkless: Llm learns when to think.arXiv preprint arXiv:2505.13379,
-
[9]
TreeQN and ATreeC: Differentiable Tree-Structured Models for Deep Reinforcement Learning
Gregory Farquhar, Tim Rocktäschel, Maximilian Igl, and Shimon Whiteson. Treeqn and atreec: Dif- ferentiable tree-structured models for deep reinforcement learning.arXiv preprint arXiv:1710.11417,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
High entropy leads to symmetry-equivariant policies in Dec-POMDPs
Johannes Forkel and Jakob Foerster. Entropy is all you need for inter-seed cross-play in hanabi. arXiv preprint arXiv:2511.22581,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Metacontrol for adaptive imagination-based optimization.arXiv preprint arXiv:1705.02670,
Jessica B Hamrick, Andrew J Ballard, Razvan Pascanu, Oriol Vinyals, Nicolas Heess, and Pe- ter W Battaglia. Metacontrol for adaptive imagination-based optimization.arXiv preprint arXiv:1705.02670,
-
[14]
Combining q-learning and search with amortized value estimates
Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Tobias Pfaff, Theophane Weber, Lars Buesing, and Peter W Battaglia. Combining q-learning and search with amortized value estimates. arXiv preprint arXiv:1912.02807,
-
[15]
On the role of planning in model-based deep reinforcement learning.arXiv preprint arXiv:2011.04021,
Jessica B Hamrick, Abram L Friesen, Feryal Behbahani, Arthur Guez, Fabio Viola, Sims Witherspoon, Thomas Anthony, Lars Buesing, Petar Veličković, and Théophane Weber. On the role of planning in model-based deep reinforcement learning.arXiv preprint arXiv:2011.04021,
-
[16]
Selecting Computations: Theory and Applications
Nicholas Hay, Stuart Russell, David Tolpin, and Solomon Eyal Shimony. Selecting computations: Theory and applications.arXiv preprint arXiv:1408.2048,
work page internal anchor Pith review Pith/arXiv arXiv 2048
-
[17]
Reasoning, Metareasoning, and Mathematical Truth: Studies of Theorem Proving under Limited Resources
Eric J Horvitz and Adrian Klein. Reasoning, metareasoning, and mathematical truth: Studies of theorem proving under limited resources.arXiv preprint arXiv:1302.4960,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Metareasoning for Planning Under Uncertainty
Christopher H Lin, Andrey Kolobov, Ece Kamar, and Eric Horvitz. Metareasoning for planning under uncertainty.arXiv preprint arXiv:1505.00399,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
s1: Simple test- time scaling
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple test- time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 20286–20332,
2025
-
[20]
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E Gonzalez, M Waleed Kadous, and Ion Stoica. Routellm: Learning to route llms with preference data.arXiv preprint arXiv:2406.18665,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
14 Preprint. Under review. Matthew Riemer, Gopeshh Subbaraj, Glen Berseth, and Irina Rish. Enabling realtime reinforcement learning at scale with staggered asynchronous inference.arXiv preprint arXiv:2412.14355,
-
[22]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Dast: Difficulty-adaptive slow-thinking for large reasoning models
Yi Shen, Jian Zhang, Jieyun Huang, Shuming Shi, Wenjing Zhang, Jiangze Yan, Ning Wang, Kai Wang, Zhaoxiang Liu, and Shiguo Lian. Dast: Difficulty-adaptive slow-thinking for large reasoning models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pp. 2322–2331,
2025
-
[25]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
URLhttps://openreview.net/forum?id=yGglBJ1pjZ. Ted Xiao, Eric Jang, Dmitry Kalashnikov, Sergey Levine, Julian Ibarz, Karol Hausman, and Alexander Herzog. Thinking while moving: Deep reinforcement learning with concurrent control.arXiv preprint arXiv:2004.06089,
-
[27]
running a simulation
A Reproducibility The full JAX implementation of every environment, base planner, and gating policy in this paper, together with pretrained checkpoints for all five environments and the two-GPU deployment harness, is released athttps://aneeshers.github.io/realtime-rl/. Each result reported in Sections 5 and 7 has a corresponding environment-variable-drive...
2018
-
[28]
estimates the advantage at timestept as aλ-weighted sum of one-step TD residuals, ˆAt = ∞∑ l=0 (γλ)lδt+l, δ t =r t +γV(st+1)−V(st),(6) which assumes a unit time gap between consecutive states. In our SMDP, consecutive meta-statesst and st+kt are separated by a variable number of environment frameskt, so the per-step discount in the TD residual becomesγkt:...
2000
-
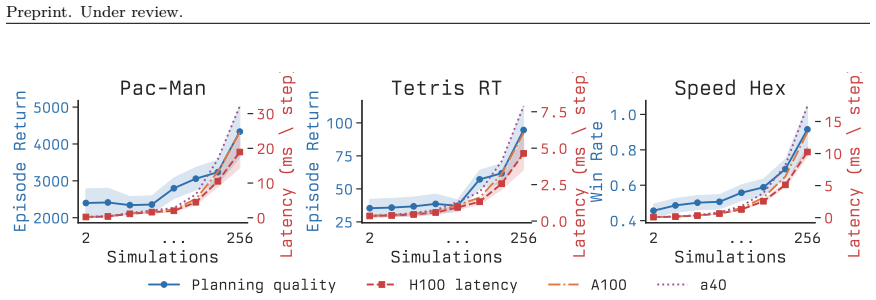
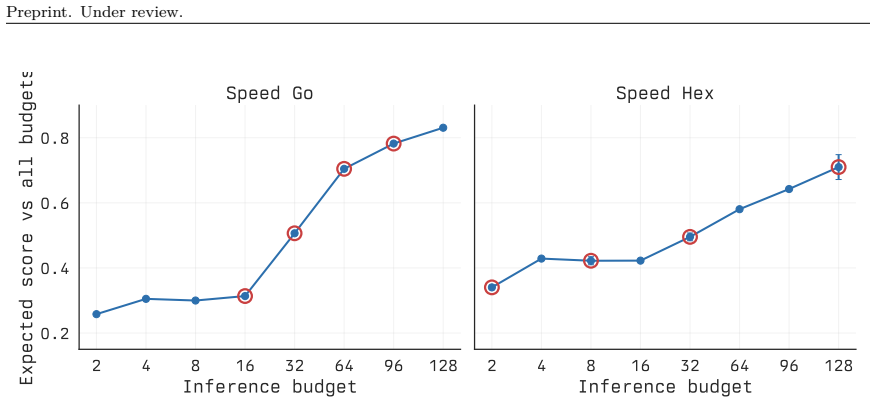
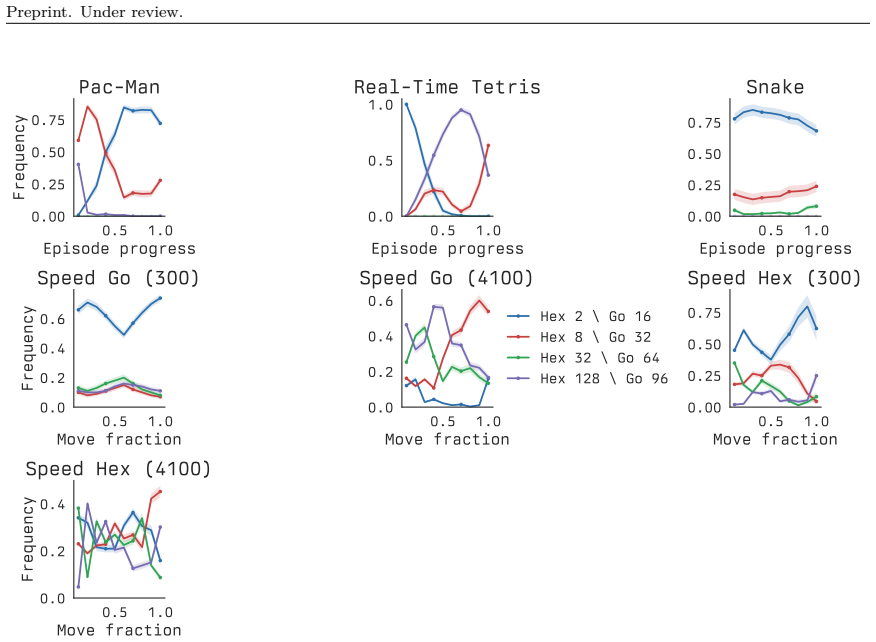
[29]
Thus, in both clocked domains, the selected options provide the gating policy with meaningfully separated quality-latency tradeoffs. 2 ... 256 Simulations 2000 3000 4000 5000Episode Return Pac-Man 2 ... 256 Simulations 40 60 80 100Episode Return Tetris RT 2 ... 256 Simulations 0.4 0.6 0.8 1.0Win Rate Speed Hex 2 ... 256 Simulations 0.25 0.50 0.75 1.00Expe...
2000
-
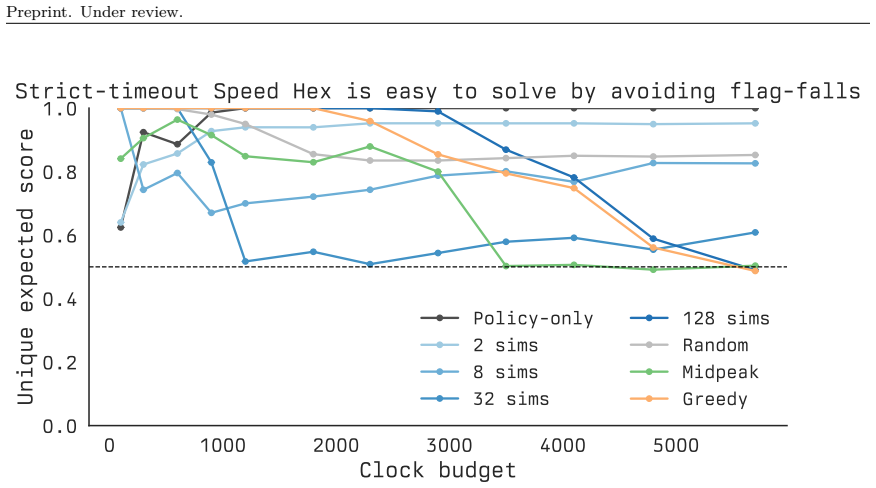
[30]
Once timeout is an immediate terminal event, stronger search is no longer reliably beneficial; it often just increases the probability of burning too much clock
This pattern is the opposite of what we observe in the main benchmark. Once timeout is an immediate terminal event, stronger search is no longer reliably beneficial; it often just increases the probability of burning too much clock. In other words, the game becomes easier 22 Preprint. Under review. 0 1000 2000 3000 4000 5000 Clock budget 0.0 0.2 0.4 0.6 0...
2000
-
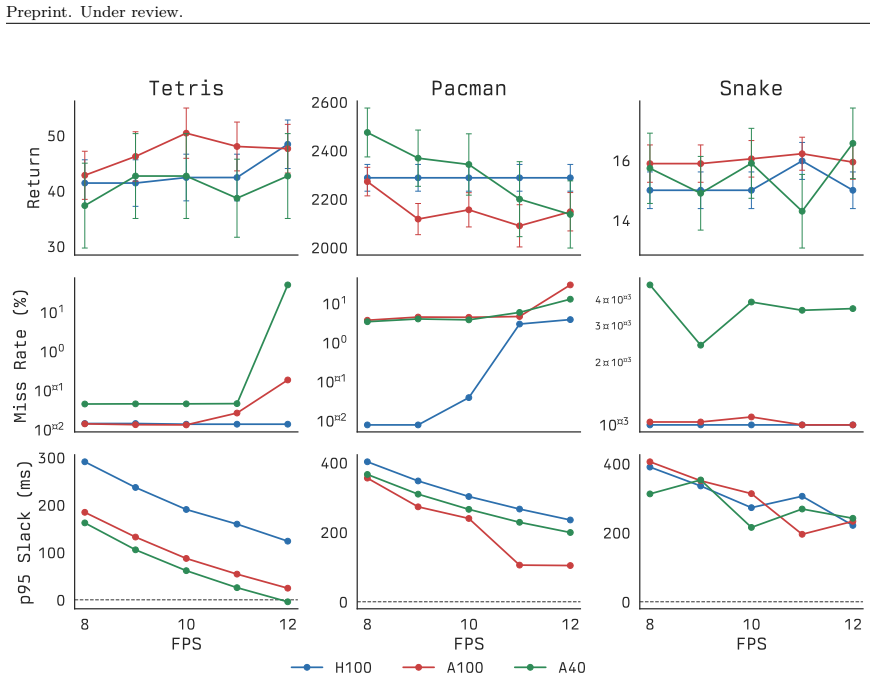
[31]
In our internal runs, the end-to-end training workflow dropped from roughly two weeks in an earlier less-batched pipeline to roughly six hours in the optimized JAX implementation
for search,vmap for environment parallelism,jit for whole-program compilation,pmap for device parallelism, and lax.scan for both MCTS inner loops and PPO rollout loops — reduce wall-clock training time dramatically. In our internal runs, the end-to-end training workflow dropped from roughly two weeks in an earlier less-batched pipeline to roughly six hour...
2000
-
[32]
This is the discrete-time SMDP solved during training
withdeterministicholding timeτ=k, so successive meta-decisions are spacedk environment steps apart and the appropriate discount isγk. This is the discrete-time SMDP solved during training. Deployment.In real-time deployment the holding time between meta-decisions equalsk×Tframe: MCTS runs concurrently on GPU 1 while the environment executes thek reflex fr...
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.