Cross-Lingual Exploration for Parametric Knowledge
Pith reviewed 2026-06-26 00:00 UTC · model grok-4.3
The pith
Cross-lingual prompting strategies unlock more parametric knowledge than native-language scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
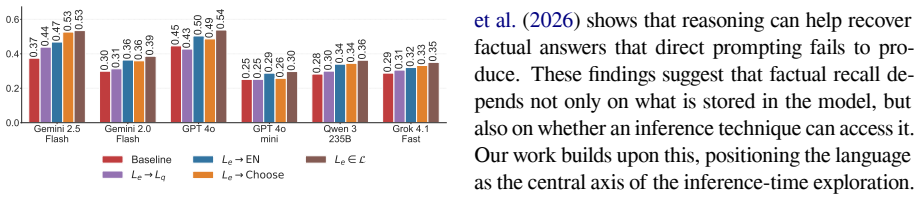
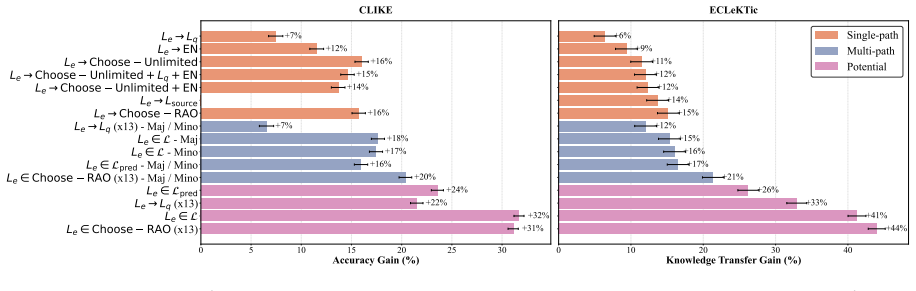
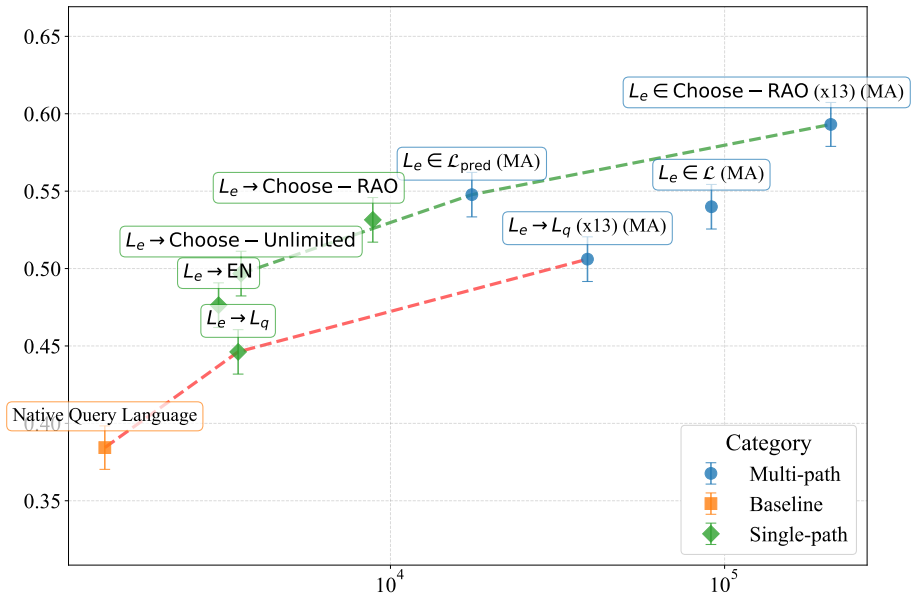
Parametric knowledge in LLMs is not equally accessible across languages. By exploring cross-lingual prompting strategies along four inherent dimensions, models achieve significantly better knowledge transfer and factual recall than native-language scaling at the same compute budget, with corresponding gains in cross-lingual consistency that exceed what accuracy improvements alone would predict.
What carries the argument
Four inherent dimensions of cross-lingual exploration that govern how prompting strategies retrieve parametric knowledge from the model.
If this is right
- Factual recall improves across typologically diverse languages without additional training.
- Cross-lingual consistency rises beyond levels expected from accuracy gains alone.
- Inference-time compute is used more efficiently than equivalent native-language scaling.
- Multilingual factual benchmarks become more reliable measures when cross-lingual exploration is applied.
Where Pith is reading between the lines
- Models may store knowledge in partially language-agnostic internal representations that prompting can align across languages.
- The approach could be combined with other inference techniques such as chain-of-thought or retrieval to further amplify gains.
- Training objectives that explicitly encourage cross-lingual consistency might reduce the need for exploration at inference time.
Load-bearing premise
The four dimensions are the main drivers of improved retrieval and the benchmarks isolate genuine parametric knowledge rather than prompt artifacts or surface patterns.
What would settle it
A controlled experiment on facts absent from the model's training data in which cross-lingual prompt variations produce no recall gain over native-language prompts at matched compute.
Figures


read the original abstract
Parametric knowledge in Large Language Models is not equally accessible across languages. As a result, standard inference techniques often struggle to surface localized facts, leading to failures in cross-lingual knowledge transfer and consistency. In this work, we investigate techniques for accessing hidden factual knowledge by exploring cross-lingual prompting strategies. We identify four inherent dimensions of cross-lingual exploration that directly govern parametric knowledge retrieval and evaluate them on multilingual factual benchmarks covering 17 typologically diverse languages. Our results demonstrate that cross-lingual exploration significantly improves knowledge transfer and factual recall, representing a more efficient compute Pareto frontier than native-language scaling. Furthermore, we observe corresponding improvements in cross-lingual consistency, exceeding what can be explained by accuracy gains alone. Overall, our work establishes multilingual prompt exploration as a highly effective inference-time strategy for unlocking latent parametric knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that parametric knowledge in LLMs is unequally accessible across languages and that four dimensions of cross-lingual prompting exploration can unlock latent facts. Evaluated on multilingual factual benchmarks spanning 17 typologically diverse languages, the approach reportedly yields better knowledge transfer and recall than native-language scaling, plus gains in cross-lingual consistency that exceed what accuracy improvements alone would predict.
Significance. If the empirical isolation of parametric knowledge holds and the consistency gains are robustly demonstrated, the work would identify a low-compute inference-time lever for multilingual factual performance. This could shift emphasis from additional pretraining or scaling toward systematic prompt-space exploration, provided the four dimensions are shown to be general rather than benchmark-specific.
major comments (3)
- [Abstract / Results] The central claim that consistency improvements exceed accuracy gains alone is load-bearing for the contribution yet the abstract (and available text) provides no description of the statistical controls, regression analysis, or ablation used to separate these effects. Without this, the assertion cannot be evaluated.
- [Experimental evaluation] The interpretation that gains reflect access to hidden parametric knowledge rather than prompting artifacts or training-data leakage rests on an unverified isolation assumption. The manuscript does not report controls for fact novelty relative to pretraining data, comparison to non-parametric retrieval baselines, or language-specific exposure ablations.
- [Method / Identification of dimensions] No details are supplied on how the four dimensions were derived, whether they were ablated individually, or how their relative contributions were quantified on the 17-language suite. This makes it impossible to assess whether they are the primary governing factors as stated.
minor comments (1)
- [Abstract] The abstract refers to 'corresponding improvements in cross-lingual consistency' without defining the consistency metric or reporting inter-language agreement statistics.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, clarifying our approach and indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / Results] The central claim that consistency improvements exceed accuracy gains alone is load-bearing for the contribution yet the abstract (and available text) provides no description of the statistical controls, regression analysis, or ablation used to separate these effects. Without this, the assertion cannot be evaluated.
Authors: The current manuscript does not detail the statistical controls or regression analysis in the abstract or main text. We will revise the abstract and add a concise description of the regression model (controlling for accuracy) used to isolate consistency effects in the results section. revision: yes
-
Referee: [Experimental evaluation] The interpretation that gains reflect access to hidden parametric knowledge rather than prompting artifacts or training-data leakage rests on an unverified isolation assumption. The manuscript does not report controls for fact novelty relative to pretraining data, comparison to non-parametric retrieval baselines, or language-specific exposure ablations.
Authors: We acknowledge that the manuscript lacks explicit controls for pretraining leakage, non-parametric baselines, or exposure ablations. We will add a limitations discussion of the isolation assumption. Full verification would require new experiments beyond the current scope, so we treat this as a partial revision by clarifying the assumption rather than adding all requested controls. revision: partial
-
Referee: [Method / Identification of dimensions] No details are supplied on how the four dimensions were derived, whether they were ablated individually, or how their relative contributions were quantified on the 17-language suite. This makes it impossible to assess whether they are the primary governing factors as stated.
Authors: The manuscript does not currently provide these methodological details. We will expand the methods section to describe the derivation process from preliminary experiments, include individual dimension ablations, and report relative contributions via quantified results on the 17-language suite. revision: yes
Circularity Check
No circularity: empirical evaluation on external benchmarks
full rationale
The paper presents an empirical study of cross-lingual prompting strategies evaluated on multilingual factual benchmarks across 17 languages. No equations, derivations, fitted parameters, or first-principles claims are described that reduce to self-definition, fitted inputs renamed as predictions, or self-citation chains. The central claims rest on observed performance differences rather than any construction that equates outputs to inputs by definition. This is the expected outcome for a purely experimental prompting paper with no theoretical derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Advances in Neural Information Processing Systems , pages =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , pages =. 2020 , publisher =
2020
-
[3]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[11]
Beneath the Surface of Consistency: Exploring Cross-lingual Knowledge Representation Sharing in LLM s
Ifergan, Maxim and Choshen, Leshem and Aharoni, Roee and Szpektor, Idan and Abend, Omri. Beneath the Surface of Consistency: Exploring Cross-lingual Knowledge Representation Sharing in LLM s. Findings of the Association for Computational Linguistics: NAACL 2025. 2025
2025
-
[12]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =. Advances in Neural Information Processing Systems , pages =. 2020 , publisher =
2020
-
[14]
Zhao, Xin and Yoshinaga, Naoki and Oba, Daisuke. Tracing the Roots of Facts in Multilingual Language Models: Independent, Shared, and Transferred Knowledge. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.eacl-long.127
-
[15]
Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers
Wendler, Chris and Veselovsky, Veniamin and Monea, Giovanni and West, Robert. Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.820
-
[17]
2026 , url=
Large Reasoning Models Struggle to Transfer Parametric Knowledge Across Scripts , author=. 2026 , url=
2026
-
[19]
2024 , journal=
GPT-4o System Card , author=. 2024 , journal=
2024
-
[20]
2024 , url=
GPT-4o mini: advancing cost-efficient intelligence , author=. 2024 , url=
2024
-
[22]
2025 , month = nov, howpublished =
Grok 4.1 Model Card , author=. 2025 , month = nov, howpublished =
2025
-
[24]
Journal of the National Cancer Institute , volume=
Statistical aspects of the analysis of data from retrospective studies of disease , author=. Journal of the National Cancer Institute , volume=. 1959 , publisher=
1959
-
[25]
2013 , edition=
Applied Logistic Regression , author=. 2013 , edition=
2013
-
[27]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle=. Locating and Editing Factual Associations in
-
[29]
Inside-Out: Hidden Factual Knowledge in
Gekhman, Zorik and Ben David, Eyal and Orgad, Hadas and Ofek, Eran and Belinkov, Yonatan and Szpektor, Idan and Herzig, Jonathan and Reichart, Roi , booktitle=. Inside-Out: Hidden Factual Knowledge in. 2025 , url=
2025
-
[31]
Proceedings - 2024 IEEE International Conference on Big Data, BigData 2024 , pages =
Embracing Foundation Models for Advancing Scientific Discovery , author=. Proceedings - 2024 IEEE International Conference on Big Data, BigData 2024 , pages =. 2024 , publisher=
2024
-
[32]
Transformer Circuits Thread , year=
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author=. Transformer Circuits Thread , year=
-
[34]
Language Specific Knowledge: Do Models Know Better in
Agarwal, Ishika and Bozdag, Nimet Beyza and Patel, Nisval and Hakkani-T. Language Specific Knowledge: Do Models Know Better in. 2025 , eprint =
2025
-
[35]
Ishika Agarwal, Nimet Beyza Bozdag, Nisval Patel, and Dilek Hakkani-T \"u r. 2025. https://arxiv.org/abs/2505.14990 Language specific knowledge: Do models know better in X than in english? Preprint, arXiv:2505.14990
Pith/arXiv arXiv 2025
-
[36]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. https://proceedings.neurips.cc/paper/202...
2020
-
[37]
Julen Etxaniz, Gorka Azkune, Aitor Soroa, Oier Lopez de Lacalle, and Mikel Artetxe. 2024. https://doi.org/10.18653/v1/2024.naacl-short.46 Do multilingual language models think better in E nglish? In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Shor...
-
[38]
Constanza Fierro and Anders S gaard. 2022. https://doi.org/10.18653/v1/2022.findings-acl.240 Factual consistency of multilingual pretrained language models . In Findings of the Association for Computational Linguistics: ACL 2022, pages 3046--3052. Association for Computational Linguistics
-
[39]
Zorik Gekhman, Roee Aharoni, Eran Ofek, Mor Geva, Roi Reichart, and Jonathan Herzig. 2026. https://arxiv.org/abs/2603.09906 Thinking to recall: How reasoning unlocks parametric knowledge in llms . arXiv preprint arXiv:2603.09906
arXiv 2026
-
[40]
Zorik Gekhman, Eyal Ben David, Hadas Orgad, Eran Ofek, Yonatan Belinkov, Idan Szpektor, Jonathan Herzig, and Roi Reichart. 2025. https://arxiv.org/abs/2503.15299 Inside-out: Hidden factual knowledge in LLM s . In Proceedings of the 2nd Conference on Language Modeling (COLM)
arXiv 2025
-
[41]
Gemini Team, Google . 2025. https://arxiv.org/abs/2507.06261 Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities . arXiv preprint arXiv:2507.06261
Pith/arXiv arXiv 2025
-
[42]
Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.751 Dissecting recall of factual associations in auto-regressive language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12216--12235. Association for Computational Linguistics
-
[43]
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.446 Transformer feed-forward layers are key-value memories . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484--5495. Association for Computational Linguistics
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[44]
Omer Goldman, Uri Shaham, Dan Malkin, Sivan Eiger, Avinatan Hassidim, Yossi Matias, Joshua Maynez, Adi Mayrav Gilady, Jason Riesa, Shruti Rijhwani, Laura Rimell, Idan Szpektor, Reut Tsarfaty, and Matan Eyal. 2025. https://arxiv.org/abs/2502.21228 Eclektic: a novel challenge set for evaluation of cross-lingual knowledge transfer . arXiv preprint arXiv:2502.21228
arXiv 2025
-
[45]
Sikun Guo, Amir Hassan Shariatmadari, Guangzhi Xiong, and Aidong Zhang. 2024. https://doi.org/10.1109/BigData62323.2024.10825618 Embracing foundation models for advancing scientific discovery . In Proceedings - 2024 IEEE International Conference on Big Data, BigData 2024, pages 1746--1755. IEEE
-
[46]
Hosmer, David W., Stanley Lemeshow, and Rodney X
Jr. Hosmer, David W., Stanley Lemeshow, and Rodney X. Sturdivant. 2013. https://doi.org/10.1002/9781118548387 Applied Logistic Regression , 3rd edition. John Wiley & Sons
-
[47]
Maxim Ifergan, Leshem Choshen, Roee Aharoni, Idan Szpektor, and Omri Abend. 2025. https://aclanthology.org/2025.findings-naacl.475/ Beneath the surface of consistency: Exploring cross-lingual knowledge representation sharing in LLM s . In Findings of the Association for Computational Linguistics: NAACL 2025, pages 4630--4644. Association for Computational...
2025
-
[48]
Zhengbao Jiang, Antonios Anastasopoulos, Jun Araki, Haibo Ding, and Graham Neubig. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.479 X - FACTR : Multilingual factual knowledge retrieval from pretrained language models . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5943--5959. Association for ...
-
[49]
Nora Kassner, Philipp Dufter, and Hinrich Sch \"u tze. 2021. https://doi.org/10.18653/v1/2021.eacl-main.284 Multilingual LAMA : Investigating knowledge in multilingual pretrained language models . In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 3250--3258. Association for C...
-
[50]
Nathan Mantel and William Haenszel. 1959. https://doi.org/10.1093/jnci/22.4.719 Statistical aspects of the analysis of data from retrospective studies of disease . Journal of the National Cancer Institute, 22(4):719--748
-
[51]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in GPT . In Advances in Neural Information Processing Systems, volume 35, pages 17359--17372
2022
-
[52]
Itai Mondshine, Tzuf Paz-Argaman, and Reut Tsarfaty. 2025. https://doi.org/10.18653/v1/2025.findings-naacl.73 Beyond E nglish: The impact of prompt translation strategies across languages and tasks in multilingual LLM s . In Findings of the Association for Computational Linguistics: NAACL 2025, pages 1331--1354. Association for Computational Linguistics
-
[53]
OpenAI . 2024 a . https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence Gpt-4o mini: advancing cost-efficient intelligence . Accessed: 2026-05-20
2024
-
[54]
OpenAI . 2024 b . https://arxiv.org/abs/2410.21276 Gpt-4o system card . arXiv preprint arXiv:2410.21276
Pith/arXiv arXiv 2024
-
[55]
Fabio Petroni, Tim Rockt \"a schel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. 2019. https://doi.org/10.18653/v1/D19-1250 Language models as knowledge bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Process...
-
[56]
Jirui Qi, Raquel Fern \'a ndez, and Arianna Bisazza. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.658 Cross-lingual consistency of factual knowledge in multilingual language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 10650--10666. Association for Computational Linguistics
-
[57]
Libo Qin, Qiguang Chen, Fuxuan Wei, Shijue Huang, and Wanxiang Che. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.163 Cross-lingual prompting: Improving zero-shot chain-of-thought reasoning across languages . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2695--2709. Association for Computational Linguistics
-
[58]
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, and 1 others. 2023. https://doi.org/10.1038/s41586-023-06291-2 Large language models encode clinical knowledge . Nature, 620(7972):172--180
-
[59]
Qwen Team. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . arXiv preprint arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[60]
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, Alex Tamkin, Esin Durmus, Tristan Hume, Francesco Mosconi, C Daniel Freeman, and 7 others. 2024. https://transformer-circuits.pub/2024/scal...
2024
-
[61]
Mor Ventura, Eyal Ben-David, Anna Korhonen, and Roi Reichart. 2025. https://doi.org/10.1162/tacl_a_00732 Navigating cultural chasms: Exploring and unlocking the cultural POV of text-to-image models . Transactions of the Association for Computational Linguistics, 13:142--166
-
[62]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. https://openreview.net/forum?id=1PL1NIMMrw Self-consistency improves chain of thought reasoning in language models . In The Eleventh International Conference on Learning Representations
2023
-
[63]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, volume 35, pages 24824--24837
2022
-
[64]
xAI . 2025. Grok 4.1 model card. https://data.x.ai/2025-11-17-grok-4-1-model-card.pdf. Released November 17, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.