CARE: Controlling LLM-Generated Policies through Auditable Review of Evidence in Scientific Experimentation
Pith reviewed 2026-06-27 04:50 UTC · model grok-4.3
The pith
CARE keeps a non-LLM optimizer as default and lets LLMs propose challenger policies only when a public-evidence gate authorizes the change.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
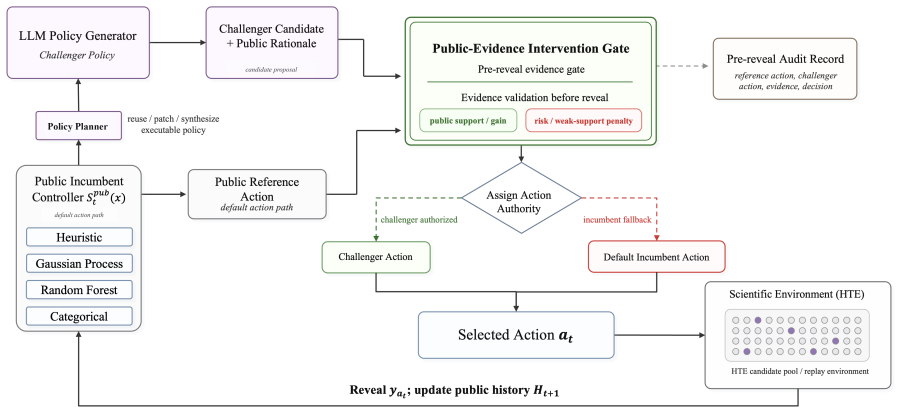
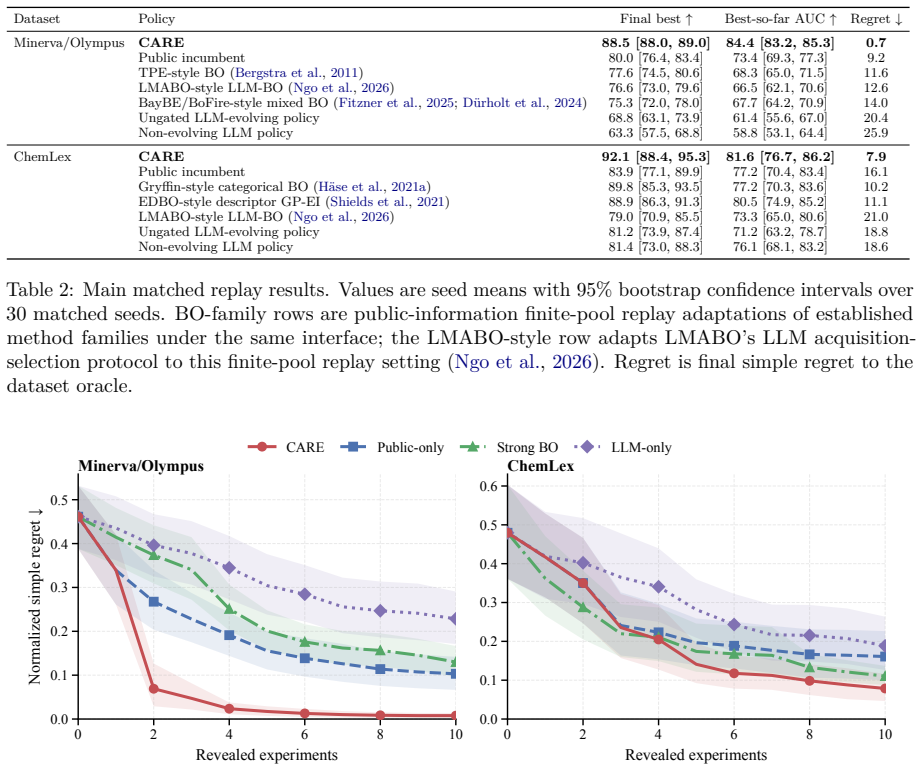
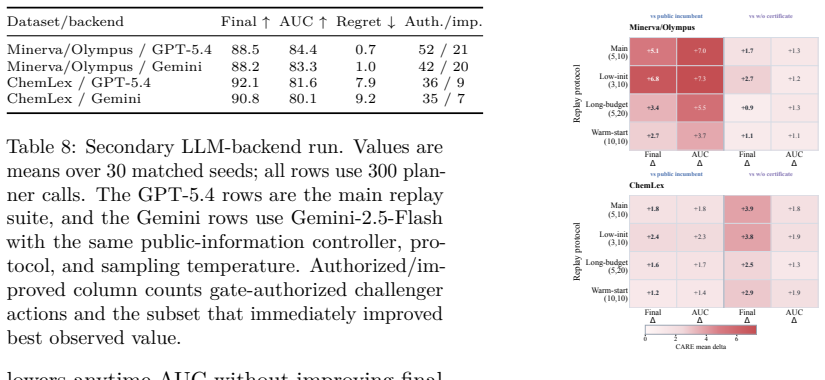
CARE is an auditable controller for high-throughput experimentation optimization that retains a non-LLM incumbent optimizer as the default action path and restricts LLMs to revising challenger ranking policies. Before each outcome is revealed, the public-evidence intervention gate compares the challenger with the incumbent and authorizes the challenger's selection only when the evidence available before selection supports the change, with the decision recorded in the audit log. On Minerva/Olympus and ChemLex the controller improves final-best scores from 80.0 to 88.5 and from 83.9 to 92.1 over the public incumbent.
What carries the argument
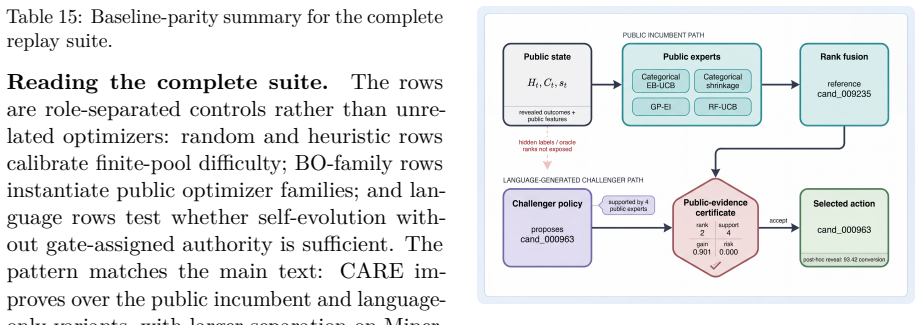
The public-evidence intervention gate that authorizes an LLM challenger policy change only when pre-selection evidence supports the change.
If this is right
- LLM-generated policies can be used to revise experiment selection without granting LLMs direct control over irreversible actions.
- Benchmark performance improves when LLM proposals expand the search space under the gate rather than when LLMs choose experiments directly.
- All policy changes remain traceable through the audit log of gate decisions.
- Defaulting to the non-LLM incumbent reduces exposure to unsafe exploration while still allowing LLM creativity in challenger proposals.
Where Pith is reading between the lines
- The same gate structure could be applied to other automated systems where an LLM proposes changes to a running policy.
- The method might be tested by varying the type or quantity of evidence the gate receives before each decision.
- In real laboratory settings the audit log could support regulatory review of automated experiment sequences.
- Multiple simultaneous challengers could be ranked by the same evidence gate to increase the rate of useful policy updates.
Load-bearing premise
The public-evidence intervention gate can be implemented such that it reliably and unbiasedly determines whether pre-selection evidence supports authorizing an LLM challenger policy change.
What would settle it
A run in which the gate authorizes a challenger policy change on the basis of pre-selection evidence yet the final performance is worse than the incumbent path that would have been taken without the change.
Figures
read the original abstract
Granting LLMs direct control over costly, irreversible scientific experiments leads to unsafe exploration and unstable performance, but discarding LLM creativity entirely sacrifices significant optimization potential. We introduce CARE (Controlling LLM-Generated Policies through Auditable Review of Evidence in Scientific Experimentation), an auditable controller for high-throughput experimentation (HTE) optimization that keeps a non-LLM incumbent optimizer as the default action path while using LLMs to revise challenger ranking policies. Before each outcome is revealed, a public-evidence intervention gate compares the challenger with the incumbent. It authorizes the challenger's selection only when the evidence available before selection supports the change, with the decision recorded in the audit log. CARE outperforms all other evaluated methods on Minerva/Olympus and ChemLex benchmarks, with final-best improving from 80.0 to 88.5 on Minerva/Olympus and from 83.9 to 92.1 on ChemLex, relative to the public incumbent. Our experiments indicate that LLM self-evolution is more reliable when it expands the proposal space under an auditable controller, rather than directly choosing experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CARE, an auditable controller for LLM-generated policies in high-throughput experimentation (HTE) optimization. It retains a non-LLM incumbent optimizer as the default while allowing LLMs to propose challenger ranking policies; a public-evidence intervention gate authorizes a challenger only when pre-selection evidence supports the change, with the decision logged. The abstract reports that CARE outperforms all evaluated methods on the Minerva/Olympus and ChemLex benchmarks, improving final-best performance from 80.0 to 88.5 and from 83.9 to 92.1, respectively, and concludes that LLM self-evolution is more reliable under such an auditable controller.
Significance. If the reported gains and the gate implementation prove robust, the work could offer a concrete mechanism for safely incorporating LLM proposal generation into costly scientific experiments while preserving auditability and an incumbent fallback. This addresses a practical tension between exploration and risk in automated experimentation.
major comments (2)
- [Abstract] Abstract: The central performance claims (final-best improving from 80.0 to 88.5 on Minerva/Olympus and 83.9 to 92.1 on ChemLex) are stated without any information on baselines, number of runs, statistical tests, variance, or how the public-evidence intervention gate is operationalized; these omissions make the outperformance claim impossible to verify from the provided text.
- [Abstract] Abstract: The description of the public-evidence intervention gate ("compares the challenger with the incumbent" and "authorizes the challenger's selection only when the evidence available before selection supports the change") supplies no criteria, data sources, or decision procedure, which is load-bearing for both the safety and the claimed reliability advantages.
minor comments (1)
- [Abstract] Abstract: The benchmarks Minerva/Olympus and ChemLex are referenced without definitions, citations, or descriptions of the tasks or metrics.
Simulated Author's Rebuttal
We thank the referee for highlighting issues with the abstract's self-containment. We address both major comments below and will revise the abstract in the next version to improve verifiability while preserving brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (final-best improving from 80.0 to 88.5 on Minerva/Olympus and 83.9 to 92.1 on ChemLex) are stated without any information on baselines, number of runs, statistical tests, variance, or how the public-evidence intervention gate is operationalized; these omissions make the outperformance claim impossible to verify from the provided text.
Authors: We agree the abstract should reference key experimental parameters for immediate verifiability. The manuscript reports results relative to the public incumbent optimizer, averaged across 10 independent runs with standard deviations and paired statistical tests provided in Section 4 and the supplement. The gate is operationalized in Section 3.2. In revision we will append a concise clause to the abstract noting the run count, variance reporting, and that full gate details appear in the methods. revision: yes
-
Referee: [Abstract] Abstract: The description of the public-evidence intervention gate ("compares the challenger with the incumbent" and "authorizes the challenger's selection only when the evidence available before selection supports the change") supplies no criteria, data sources, or decision procedure, which is load-bearing for both the safety and the claimed reliability advantages.
Authors: The abstract intentionally remains high-level; the precise criteria (evidence strength from pre-selection public logs), data sources (prior HTE outcomes), and decision procedure (threshold comparison logged before any switch) are defined in Section 3.2. We will revise the abstract to include one additional sentence specifying that authorization occurs only when public evidence before selection favors the challenger under an auditable rule. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context contain no equations, parameter-fitting procedures, self-citations, or derivation steps that reduce any claimed result to an input by construction. The central claim is an empirical outperformance result on external benchmarks (Minerva/Olympus, ChemLex) under the CARE controller; this is presented as an experimental finding rather than a self-referential definition or renamed prior result. No load-bearing uniqueness theorems, ansatzes, or fitted-input predictions appear in the text. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Maximilian Balandat, Brian Karrer, Daniel Jiang, Samuel Daulton, Ben Letham, Andrew G
Finite-time analysis of the multiarmed bandit problem.Machine Learning, 47(2–3):235– 256. Maximilian Balandat, Brian Karrer, Daniel Jiang, Samuel Daulton, Ben Letham, Andrew G. Wil- son, and Eytan Bakshy. 2020. Botorch: A frame- work for efficient monte-carlo bayesian optimiza- tion. InAdvances in Neural Information Pro- cessing Systems, volume 33, pages ...
Pith/arXiv arXiv 2020
-
[2]
Bofire: Bayesian optimization frame- work intended for real experiments.Preprint, arXiv:2408.05040. Kobi C. Felton, Jan G. Rittig, and Alexei A. Lapkin
-
[3]
Chrisantha Fernando, Dylan Sunil Banarse, Henryk Michalewski, Simon Osindero, and Tim Rock- täschel
Summit: Benchmarking machine learning methods for reaction optimisation.Chemistry– Methods, 1(2):116–122. Chrisantha Fernando, Dylan Sunil Banarse, Henryk Michalewski, Simon Osindero, and Tim Rock- täschel. 2024. Promptbreeder: Self-referential self-improvement via prompt evolution. InPro- ceedings of the 41st International Conference on Machine Learning,...
2024
-
[4]
Donald R
Springer Berlin Heidelberg. Donald R. Jones, Matthias Schonlau, and William J. Welch. 1998. Efficient global optimization of expensive black-box functions.Journal of Global Optimization, 13(4):455–492. Omar Khattab, Arnav Singhvi, Paridhi Mahesh- wari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Mo...
1998
-
[5]
gradient descent
DSPy: Compiling declarative language model calls into state-of-the-art pipelines. In The Twelfth International Conference on Learn- ing Representations. Agustinus Kristiadi, Felix Strieth-Kalthoff, Marta Skreta, Pascal Poupart, Alán Aspuru-Guzik, and Geoff Pleiss. 2024. A sober look at LLMs for material discovery: Are they actually good for bayesian optim...
2024
-
[6]
An entropy search portfolio for bayesian optimization.Preprint, arXiv:1406.4625. Benjamin J. Shields, Jason Stevens, Jun Li, Marvin Parasram, Farhan Damani, Jesus I. Martinez Al- varado, Jacob M. Janey, Ryan P. Adams, and Abigail G. Doyle. 2021. Bayesian reaction opti- mization as a tool for chemical synthesis.Nature, 590(7844):89–96. Mohit Shridhar, Xing...
Pith/arXiv arXiv 2021
-
[7]
Gary Tom, Stefan P
An autonomous laboratory for the accel- erated synthesis of inorganic materials.Nature, 624(7990):86–91. Gary Tom, Stefan P. Schmid, Sterling G. Baird, Yang Cao, Kourosh Darvish, Han Hao, Stan- ley Lo, Sergio Pablo-García, Ella M. Rajaon- son, Marta Skreta, Naruki Yoshikawa, Samantha Corapi, Gun Deniz Akkoc, Felix Strieth-Kalthoff, Martin Seifrid, and Alá...
2024
-
[8]
best_ligand_near_best
ReAct: Synergizing reasoning and acting in language models. InThe Eleventh Interna- tional Conference on Learning Representations, ICLR 2023. OpenReview.net. Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Pan Lu, Zhi Huang, Carlos Guestrin, and James Zou. 2025. Optimizing generative AI by backpropagating language model feedback. Nature, 639(8...
2023
-
[9]
Plan only one next edit/action for a language-generated optimizer skill
-
[10]
Use only public views and revealed objective values; do not seek evaluator-private labels, answer keys, baseline artifacts, files, network, or credentials
-
[11]
Prefer low-risk deterministic code edits that compile to rank_candidates
-
[12]
The final deployed tool must score the full remaining candidate_df, not a menu
-
[13]
Reuse is allowed only when the active skill is both deploy- able and still improving or diversifying selected outcomes
-
[14]
Do not patch solely because one round failed after a recent best-observed improvement; reuse once unless the last selected objective value was clearly poor
-
[15]
Plan patch_skill mainly after two or more consecutive no-improvement rounds, or after a revealed selection far below the current best
-
[16]
If patching after stagnation, blend the active scoring rule with bounded diversity/novelty; do not replace a previ- ously improving policy with an unrelated scorer
-
[17]
If the active skill repeatedly selects lower-yield near- duplicates after a first improvement, patch it to avoid over-exploiting that local region
-
[18]
schema_version
Return JSON with task_plan and self_reported_forbidden_info_used=false. Planner output schema. {"schema_version":"self_evolving_task_plan_v1","run_id":"[RUN_ID ]","round_index":"[ROUND_INDEX]", "task_plan":{"action":"create_skill|patch_skill| reuse_active_skill","skill_family":"ranker|constraint| exploration|calibrator|fallback", "objective":"short public...
-
[19]
Write normal Python source defining exactly rank_candidates(observed_df, candidate_df, memory=None, tool_state=None)
-
[20]
Return a dictionary, never a DataFrame: {’ranked_candidates’: list, ’tool_state’: dict, ’tool_diagnostics’: dict}
-
[21]
It must cover every candidate_df row with unique positive ranks and finite scores
Each ranked row must includecandidate_id, rank, score, reason_code, and evidence_refs. It must cover every candidate_df row with unique positive ranks and finite scores. 4.evidence_refs is empty unless exactobservation_id val- ues are copied fromobserved_df; never invent evidence strings
-
[22]
Use only publicobserved_y for observed rows and public candidate features
-
[23]
Do not read files, call networks, import disallowed mod- ules, inspect DataFrame attrs, or reference evaluator- private labels, answer keys, baseline artifacts, private provenance fields, or credentials
-
[24]
Do not use double-underscore names or strings in tempo- rary columns, helper variables, imports, or escape hatches
-
[25]
Do not callgetattr, setattr, hasattr, eval, exec, compile, globals,locals,vars,open, or__import__
-
[26]
Make ranking row-order invariant: do not use enumerate index, original row order, DataFrame index, or insertion order in scores or tie-breaks
-
[27]
Sort with public score first andcandidate_id as the only deterministic tie-breaker; never tie-break by row position
-
[28]
Avoid creating helper columns such as_row_order, _index, __lig, or_positionfor ordering
-
[29]
schema_version
Return JSON with skill_artifact.source and self_reported_forbidden_info_used=false. Policy-synthesis output schema. {"schema_version":"self_evolving_skill_artifact_v1","run_id":"[ RUN_ID]","round_index":"[ROUND_INDEX]", "skill_artifact":{"skill_id":"short id","family":"[ TASK_PLAN_SKILL_FAMILY]","source":"Python source string defining rank_candidates","ra...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.