Rethinking Embodied Navigation via Relational Inductive Bias
Pith reviewed 2026-06-27 13:09 UTC · model grok-4.3
The pith
DB-Nav reshapes object navigation search space using dual relational biases to suppress unreliable cues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
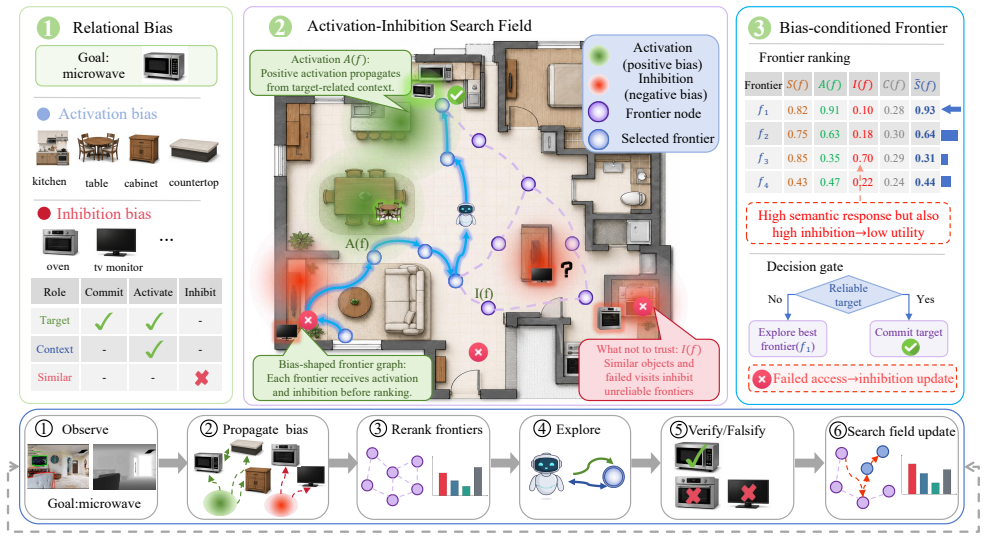
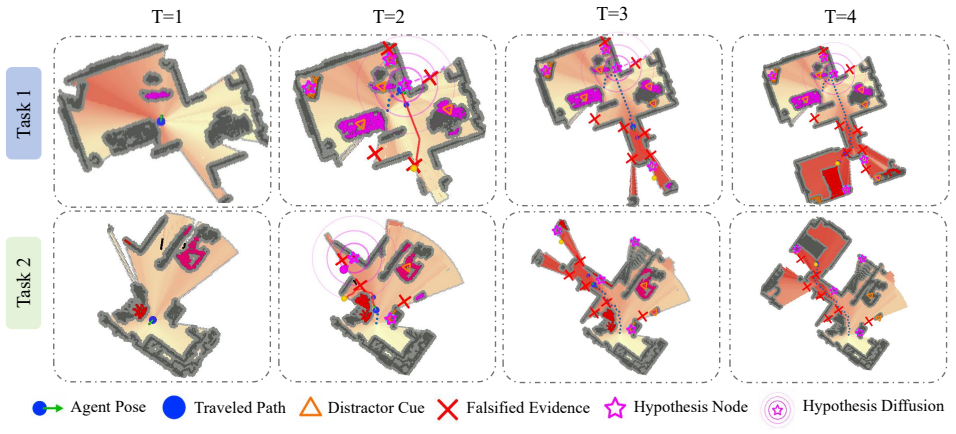
The paper claims that unifying an Activation Bias, which propagates contextual evidence, and an Inhibition Bias, which suppresses unreliable regions, inside a Relational Activation-Inhibition Exploration Graph allows frontier values to be modulated directly from online observations and failed accesses, thereby avoiding systematic contamination of mapping and decision making in object navigation.
What carries the argument
The Relational Activation-Inhibition Exploration Graph, which unifies Activation Bias for spreading evidence and Inhibition Bias for suppressing unreliable regions to adjust frontier exploration values.
If this is right
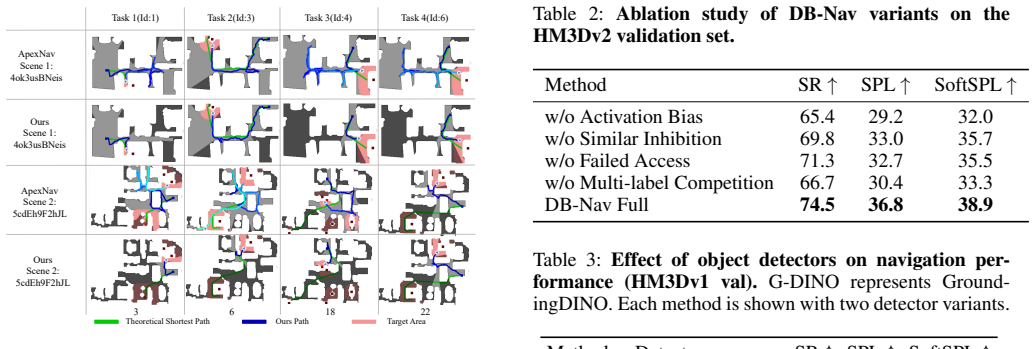
- Higher success rate and Success weighted by Path Length on ObjectNav benchmarks compared with prior methods.
- Navigation remains lightweight and does not require costly online vision-language model reasoning.
- Explicit relational biases provide interpretability for why certain frontiers are chosen or avoided.
- Robustness increases against false positives, outdated static priors, and repeated failed explorations.
Where Pith is reading between the lines
- The same bias mechanism could be tested on point-goal navigation or other embodied tasks that face noisy perceptual input.
- Tracking failure history explicitly might improve reliability in reinforcement-learning agents operating under partial observability.
- Lower dependence on heavy models could allow navigation policies to run on robots with limited onboard compute.
Load-bearing premise
Relational biases can be computed and unified from online observations and failed accesses without creating new systematic errors or needing extra perception modules.
What would settle it
A controlled test in which DB-Nav shows no gain or a drop in success rate when the environment contains many objects that produce high rates of false positive detections.
Figures



read the original abstract
Object navigation requires an agent to locate a target in an unknown environment through visual observations. Existing methods typically rely on open-vocabulary detectors or vision-language models (VLMs) to answer where to search, but often overlook what not to trust - which semantic cues are unreliable. Open-vocabulary perception is prone to systematic misleading evidence: false positives, outdated static priors, and repeated failed exploration due to lack of embodied verification, which contaminates mapping and decision-making. Such errors are rooted in structured object relations in real-world scenes. To address this, we propose DB-Nav, a framework that reshapes the search space via dual relational biases. It factorizes target-centric relations into an Activation Bias (propagates contextual evidence) and an Inhibition Bias (suppresses unreliable regions via perceptual confusion and action-level falsification). These biases are unified into a Relational Activation-Inhibition Exploration Graph that modulates frontier exploration values using online observations and failed accesses. Experiments on ObjectNav benchmarks show that DB-Nav significantly outperforms existing methods in success rate (SR) and Success weighted by Path Length (SPL), offering a lightweight, interpretable, and robust navigation framework without costly online VLM reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DB-Nav for object navigation, factorizing target-centric relations into an Activation Bias (propagating contextual evidence) and an Inhibition Bias (suppressing unreliable regions via perceptual confusion and action-level falsification). These are unified into a Relational Activation-Inhibition Exploration Graph that modulates frontier exploration values from online observations and failed accesses. The central claim is that this yields significant gains in success rate (SR) and Success weighted by Path Length (SPL) on ObjectNav benchmarks while remaining lightweight and avoiding online VLM reasoning.
Significance. If the bias computation mechanisms prove reliable and free of new systematic errors, the approach could supply an interpretable, parameter-light alternative to VLM-dependent navigation by explicitly encoding what not to trust. The relational inductive bias framing and use of failed accesses are potentially valuable contributions, but the significance hinges on whether the reported SR/SPL improvements survive detailed ablation and error analysis.
major comments (2)
- [Abstract / Method description] The abstract and method overview provide no equations, pseudocode, or quantitative validation for how perceptual confusion is measured or how action-level falsification updates the graph; without these, it is impossible to assess whether the Inhibition Bias avoids the false-positive and outdated-prior problems it aims to solve.
- [Experiments] The central performance claim (outperformance on ObjectNav benchmarks) rests on the assumption that the dual biases can be computed solely from online observations without new perception modules or error propagation, yet no ablation isolating the contribution of the Inhibition Bias or reporting error bars on SR/SPL is referenced.
minor comments (1)
- [Experiments] Dataset details, baseline implementations, and exact ObjectNav episode counts should be stated explicitly to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and strengthen the experimental validation.
read point-by-point responses
-
Referee: [Abstract / Method description] The abstract and method overview provide no equations, pseudocode, or quantitative validation for how perceptual confusion is measured or how action-level falsification updates the graph; without these, it is impossible to assess whether the Inhibition Bias avoids the false-positive and outdated-prior problems it aims to solve.
Authors: We agree that the abstract and high-level method overview would benefit from explicit formulations. The full method section defines perceptual confusion as the normalized discrepancy between open-vocabulary detections and multi-view consistency checks, and action-level falsification as a decay factor applied to frontier values upon repeated failed accesses. To address the concern, we will insert the core equations and a pseudocode algorithm into the method overview, enabling direct evaluation of how the Inhibition Bias mitigates false positives and outdated priors from online observations alone. revision: yes
-
Referee: [Experiments] The central performance claim (outperformance on ObjectNav benchmarks) rests on the assumption that the dual biases can be computed solely from online observations without new perception modules or error propagation, yet no ablation isolating the contribution of the Inhibition Bias or reporting error bars on SR/SPL is referenced.
Authors: The reported results demonstrate overall gains from the dual-bias graph. To isolate the Inhibition Bias contribution and quantify robustness, we will add an ablation comparing the full model against an Activation-Bias-only variant, plus standard deviation error bars on SR and SPL computed over multiple random seeds. These additions will directly test the assumption of error-free online computation without new modules. revision: yes
Circularity Check
No circularity detected; claims rest on empirical results without self-referential derivation
full rationale
The provided abstract and description introduce DB-Nav as a framework that computes Activation Bias and Inhibition Bias from online observations to modulate an exploration graph, but contain no equations, parameter-fitting steps, self-citations, or uniqueness theorems that reduce any claimed result to its own inputs by construction. No predictions are presented as derived from fitted values, and the performance claims are benchmark comparisons rather than internal derivations. The derivation chain is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
invented entities (3)
-
Activation Bias
no independent evidence
-
Inhibition Bias
no independent evidence
-
Relational Activation-Inhibition Exploration Graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
R.; Fischer, M.; Malik, J.; and Savarese, S
Armeni, I.; He, Z.-Y.; Gwak, J.; Zamir, A. R.; Fischer, M.; Malik, J.; and Savarese, S. 2019. 3D Scene Graph: A Structure for Unified Semantics, 3D Space, and Camera . In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2019
-
[3]
X.; Dai, A.; Funkhouser, T.; Halber, M.; Niessner, M.; Savva, M.; Song, S.; Zeng, A.; and Zhang, Y
Chang, A. X.; Dai, A.; Funkhouser, T.; Halber, M.; Niessner, M.; Savva, M.; Song, S.; Zeng, A.; and Zhang, Y. 2017. Matterport3D: Learning from RGB-D Data in Indoor Environments . In Proceedings of the International Conference on 3D Vision (3DV)
2017
-
[4]
S.; Gandhi, D.; Gupta, A.; Malik, J.; and Salakhutdinov, R
Chaplot, D. S.; Gandhi, D.; Gupta, A.; Malik, J.; and Salakhutdinov, R. 2020 a . Learning to Explore using Active Neural SLAM . In Proceedings of the International Conference on Learning Representations (ICLR)
2020
-
[5]
S.; Gandhi, D.; Gupta, A.; and Salakhutdinov, R
Chaplot, D. S.; Gandhi, D.; Gupta, A.; and Salakhutdinov, R. 2020 b . Object Goal Navigation using Goal-Oriented Semantic Exploration . In Advances in Neural Information Processing Systems (NeurIPS)
2020
-
[6]
S.; Salakhutdinov, R.; Gupta, A.; and Gupta, S
Chaplot, D. S.; Salakhutdinov, R.; Gupta, A.; and Gupta, S. 2020 c . Neural Topological SLAM for Visual Navigation . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2020
-
[7]
Chen, R.; and Zhang, X. 2026. CoS: Contextual Object Semantics for Zero-Shot Navigation . In AAAI Conference on Artificial Intelligence
2026
-
[8]
Chen, X.; Zhou, M.; and Li, T. 2024. PixNav: Pixel-Level Visual Navigation for Zero-Shot Object Goals . In International Conference on Robotics and Automation (ICRA)
2024
-
[9]
Cheng, T.; Song, L.; Ge, Y.; Liu, W.; Wang, X.; and Shan, Y. 2024. YOLO-World: Real-Time Open-Vocabulary Object Detection . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2024
-
[10]
Deitke, M.; Han, W.; Herrasti, A.; Kembhavi, A.; Kolve, E.; Mottaghi, R.; Salvador, J.; Schwenk, D.; VanderBilt, E.; Wallingford, M.; Weihs, L.; Yatskar, M.; and Farhadi, A. 2020. RoboTHOR: An Open Simulation-to-Real Embodied AI Platform . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2020
-
[11]
Deitke, T.; Xie, L.; and Chen, R. 2022. ProcTHOR: Procedural Object Navigation in Simulated Environments . In Advances in Neural Information Processing Systems (NeurIPS)
2022
-
[12]
Y.; Wortsman, M.; Ilharco, G.; Schmidt, L.; and Song, S
Gadre, S. Y.; Wortsman, M.; Ilharco, G.; Schmidt, L.; and Song, S. 2023. CoWs on Pasture: Baselines and Benchmarks for Language-Driven Zero-Shot Object Navigation . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2023
-
[13]
Georgakis, G.; Bucher, B.; Schmeckpeper, K.; Singh, S.; and Daniilidis, K. 2021. Learning to Map for Active Semantic Goal Navigation . In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2021
-
[14]
M.; Sen, B.; Agarwal, A.; Rivera, C.; Paul, W.; Ellis, K.; Chellappa, R.; Gan, C.; de Melo, C
Gu, Q.; Kuwajerwala, A.; Morin, S.; Jatavallabhula, K. M.; Sen, B.; Agarwal, A.; Rivera, C.; Paul, W.; Ellis, K.; Chellappa, R.; Gan, C.; de Melo, C. M.; Tenenbaum, J. B.; Torralba, A.; Shkurti, F.; and Paull, L. 2024. ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning . In Proceedings of the IEEE International Conference on Roboti...
2024
-
[15]
Gupta, S.; Tolani, V.; Davidson, J.; Levine, S.; Sukthankar, R.; and Malik, J. 2017. Cognitive Mapping and Planning for Visual Navigation . In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2017
-
[16]
Huang, W.; Zhang, L.; and Sun, J. 2025. ASCENT: Floor-Aware Zero-Shot Object Goal Navigation . In ICRA
2025
-
[17]
Kim, S.; Park, J.; and Lee, H. 2024. InstructNav: Instruction-Guided Zero-Shot Object Navigation . In Conference on Robot Learning (CoRL)
2024
-
[18]
C.; Lo, W.-Y.; Dollar, P.; and Girshick, R
Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A. C.; Lo, W.-Y.; Dollar, P.; and Girshick, R. 2023. Segment Anything . In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2023
-
[20]
Kuang, Y.; Lin, H.; and Jiang, M. 2024. OpenFMNav: Towards Open-Set Zero-Shot Object Navigation via Vision-Language Foundation Models . In Findings of the Association for Computational Linguistics: NAACL
2024
-
[21]
Li, J.; Li, D.; Savarese, S.; and Hoi, S. 2023. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models . In Proceedings of the International Conference on Machine Learning (ICML)
2023
-
[22]
Li, Z.; Xu, Q.; and Chen, R. 2024. TriHelper: Tri-Modal Guidance for Zero-Shot Object Navigation . In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
2024
-
[23]
Liu, F.; Chen, R.; and Wang, J. 2025. MFNP: Multi-Factor Navigation Policies for Zero-Shot Object Goals . In ICRA
2025
-
[25]
Majumdar, A.; Aggarwal, G.; Devnani, B.; Hoffman, J.; and Batra, D. 2022. ZSON: Zero-Shot Object-Goal Navigation using Multimodal Goal Embeddings . In Advances in Neural Information Processing Systems (NeurIPS)
2022
-
[26]
Minderer, M.; Gritsenko, A.; Stone, A.; Neumann, M.; Weissenborn, D.; Dosovitskiy, A.; Mahendran, A.; Arnab, A.; Dehghani, M.; Shen, Z.; Wang, X.; Zhai, X.; Kipf, T.; and Houlsby, N. 2022. Simple Open-Vocabulary Object Detection with Vision Transformers . In Proceedings of the European Conference on Computer Vision (ECCV)
2022
-
[27]
Peng, S.; Genova, K.; Jiang, C.; Tagliasacchi, A.; Pollefeys, M.; and Funkhouser, T. 2023. OpenScene: 3D Scene Understanding with Open Vocabularies . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2023
-
[28]
W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; Krueger, G.; and Sutskever, I
Radford, A.; Kim, J. W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; Krueger, G.; and Sutskever, I. 2021. Learning Transferable Visual Models From Natural Language Supervision . In Proceedings of the International Conference on Machine Learning (ICML)
2021
-
[29]
K.; Al-Halah, Z.; and Grauman, K
Ramakrishnan, S. K.; Al-Halah, Z.; and Grauman, K. 2020. Occupancy Anticipation for Efficient Exploration and Navigation . In Proceedings of the European Conference on Computer Vision (ECCV)
2020
-
[30]
K.; Chaplot, D
Ramakrishnan, S. K.; Chaplot, D. S.; Al-Halah, Z.; Malik, J.; and Grauman, K. 2022. PONI: Potential Functions for ObjectGoal Navigation with Interaction-Free Learning . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2022
-
[31]
K.; Gokaslan, A.; Wijmans, E.; Maksymets, O.; Clegg, A.; Turner, J.; Undersander, E.; Galuba, W.; Westbury, A.; Chang, A
Ramakrishnan, S. K.; Gokaslan, A.; Wijmans, E.; Maksymets, O.; Clegg, A.; Turner, J.; Undersander, E.; Galuba, W.; Westbury, A.; Chang, A. X.; Savva, M.; Zhao, Y.; and Batra, D. 2021. Habitat-Matterport 3D Dataset . In Advances in Neural Information Processing Systems Datasets and Benchmarks Track
2021
-
[32]
Savva, M.; Kadian, A.; Maksymets, O.; Zhao, Y.; Wijmans, E.; Jain, B.; Straub, J.; Liu, J.; Koltun, V.; Malik, J.; Parikh, D.; and Batra, D. 2019. Habitat: A Platform for Embodied AI Research . In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2019
-
[34]
Wang, J.; and Li, P. 2026. PanoNav: Panoramic Observation for Zero-Shot Object Navigation . In AAAI Conference on Artificial Intelligence
2026
-
[35]
Wang, L.; Gupta, A.; and Singh, A. 2023. L3MVN: Learning Multi-View Navigation Policies for Zero-Shot Object Goal Navigation . In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
2023
-
[37]
Werby, A.; Huang, C.; Buchner, M.; Valada, A.; and Burgard, W. 2024. Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation . In Proceedings of Robotics: Science and Systems (RSS)
2024
-
[38]
S.; Lee, S.; Essa, I.; Parikh, D.; Savva, M.; and Batra, D
Wijmans, E.; Kadian, A.; Morcos, A. S.; Lee, S.; Essa, I.; Parikh, D.; Savva, M.; and Batra, D. 2020. DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames . In Proceedings of the International Conference on Learning Representations (ICLR)
2020
-
[39]
Wu, P.; Mu, Y.; Wu, B.; Hou, Y.; Ma, J.; Zhang, S.; and Liu, C. 2024. VoroNav: Voronoi-Based Zero-Shot Object Navigation with Large Language Model . In Proceedings of the International Conference on Machine Learning (ICML)
2024
-
[40]
R.; He, Z.; Sax, A.; Malik, J.; and Savarese, S
Xia, F.; Zamir, A. R.; He, Z.; Sax, A.; Malik, J.; and Savarese, S. 2018. Gibson Env: Real-World Perception for Embodied Agents . In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2018
-
[41]
K.; Gervet, T.; Turner, J.; Gokaslan, A.; Maestre, N.; Chang, A
Yadav, K.; Ramrakhya, R.; Ramakrishnan, S. K.; Gervet, T.; Turner, J.; Gokaslan, A.; Maestre, N.; Chang, A. X.; Batra, D.; Savva, M.; Clegg, A. W.; and Chaplot, D. S. 2022. Habitat-Matterport 3D Semantics Dataset . In Advances in Neural Information Processing Systems Datasets and Benchmarks Track
2022
-
[42]
Yamauchi, B. 1997. A Frontier-Based Approach for Autonomous Exploration . In Proceedings of the IEEE International Symposium on Computational Intelligence in Robotics and Automation (CIRA)
1997
-
[43]
Yang, W.; Wang, X.; Farhadi, A.; Gupta, A.; and Mottaghi, R. 2019. Visual Semantic Navigation using Scene Priors . In Proceedings of the International Conference on Learning Representations (ICLR)
2019
-
[44]
Ye, J.; Batra, D.; Das, A.; and Wijmans, E. 2021. Auxiliary Tasks and Exploration Enable ObjectGoal Navigation . In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2021
-
[45]
Yin, H.; Xu, X.; Wu, Z.; Zhou, J.; and Lu, J. 2024. SG-Nav: Online 3D Scene Graph Prompting for LLM-Based Zero-Shot Object Navigation . In Advances in Neural Information Processing Systems (NeurIPS)
2024
-
[46]
Yokoyama, H.; Tanaka, K.; and Saito, N. 2025. ImagineNav: Vision-Language Grounded Zero-Shot Navigation . In International Conference on Learning Representations (ICLR)
2025
-
[47]
Yokoyama, N.; Ha, S.; Batra, D.; Wang, J.; and Bucher, B. 2024. VLFM: Vision-Language Frontier Maps for Zero-Shot Semantic Navigation . In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA)
2024
-
[49]
Zhang, H.; Li, P.; and Wang, Y. 2025. UniGoal: Unified Goal Representation for Zero-Shot Object Navigation . In CVPR
2025
-
[51]
Zhou, K.; Zheng, K.; Pryor, C.; Shen, Y.; Jin, H.; Getoor, L.; and Wang, X. E. 2023. ESC: Exploration with Soft Commonsense Constraints for Zero-Shot Object Navigation . In Proceedings of the International Conference on Machine Learning (ICML)
2023
-
[52]
ObjectNav Revisited: On Evaluation of Embodied Agents Navigating to Objects
Batra, Dhruv and Gokaslan, Aaron and Kembhavi, Aniruddha and Maksymets, Oleksandr and Mottaghi, Roozbeh and Savva, Manolis and Toshev, Alexander and Wijmans, Erik. ObjectNav Revisited: On Evaluation of Embodied Agents Navigating to Objects. arXiv:2006.13171
-
[53]
Habitat: A Platform for Embodied AI Research
Savva, Manolis and Kadian, Abhishek and Maksymets, Oleksandr and Zhao, Yili and Wijmans, Erik and Jain, Bhavana and Straub, Julian and Liu, Jia and Koltun, Vladlen and Malik, Jitendra and Parikh, Devi and Batra, Dhruv. Habitat: A Platform for Embodied AI Research. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
-
[54]
and Dai, Angela and Funkhouser, Thomas and Halber, Maciej and Niessner, Matthias and Savva, Manolis and Song, Shuran and Zeng, Andy and Zhang, Yinda
Chang, Angel X. and Dai, Angela and Funkhouser, Thomas and Halber, Maciej and Niessner, Matthias and Savva, Manolis and Song, Shuran and Zeng, Andy and Zhang, Yinda. Matterport3D: Learning from RGB-D Data in Indoor Environments. Proceedings of the International Conference on 3D Vision (3DV)
-
[55]
and He, Zhiyang and Sax, Alexander and Malik, Jitendra and Savarese, Silvio
Xia, Fei and Zamir, Amir R. and He, Zhiyang and Sax, Alexander and Malik, Jitendra and Savarese, Silvio. Gibson Env: Real-World Perception for Embodied Agents. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
-
[56]
AI2-THOR: An Interactive 3D Environment for Visual AI
Kolve, Eric and Mottaghi, Roozbeh and Han, Winson and VanderBilt, Eli and Weihs, Luca and Herrasti, Alvaro and Gordon, Daniel and Zhu, Yuke and Gupta, Abhinav and Farhadi, Ali. AI2-THOR: An Interactive 3D Environment for Visual AI. arXiv:1712.05474
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
RoboTHOR: An Open Simulation-to-Real Embodied AI Platform
Deitke, Matt and Han, Winson and Herrasti, Alvaro and Kembhavi, Aniruddha and Kolve, Eric and Mottaghi, Roozbeh and Salvador, Jordi and Schwenk, Dustin and VanderBilt, Eli and Wallingford, Matthew and Weihs, Luca and Yatskar, Mark and Farhadi, Ali. RoboTHOR: An Open Simulation-to-Real Embodied AI Platform. Proceedings of the IEEE/CVF Conference on Compute...
-
[58]
and Savva, Manolis and Zhao, Yili and Batra, Dhruv
Ramakrishnan, Santhosh Kumar and Gokaslan, Aaron and Wijmans, Erik and Maksymets, Oleksandr and Clegg, Alex and Turner, John and Undersander, Eric and Galuba, Wojciech and Westbury, Andrew and Chang, Angel X. and Savva, Manolis and Zhao, Yili and Batra, Dhruv. Habitat-Matterport 3D Dataset. Advances in Neural Information Processing Systems Datasets and Be...
-
[59]
Cognitive Mapping and Planning for Visual Navigation
Gupta, Saurabh and Tolani, Varun and Davidson, James and Levine, Sergey and Sukthankar, Rahul and Malik, Jitendra. Cognitive Mapping and Planning for Visual Navigation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
-
[60]
and Lee, Stefan and Essa, Irfan and Parikh, Devi and Savva, Manolis and Batra, Dhruv
Wijmans, Erik and Kadian, Abhishek and Morcos, Ari S. and Lee, Stefan and Essa, Irfan and Parikh, Devi and Savva, Manolis and Batra, Dhruv. DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames. Proceedings of the International Conference on Learning Representations (ICLR)
-
[61]
Auxiliary Tasks and Exploration Enable ObjectGoal Navigation
Ye, Joel and Batra, Dhruv and Das, Abhishek and Wijmans, Erik. Auxiliary Tasks and Exploration Enable ObjectGoal Navigation. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
-
[62]
A Frontier-Based Approach for Autonomous Exploration
Yamauchi, Brian. A Frontier-Based Approach for Autonomous Exploration. Proceedings of the IEEE International Symposium on Computational Intelligence in Robotics and Automation (CIRA)
-
[63]
Learning to Explore using Active Neural SLAM
Chaplot, Devendra Singh and Gandhi, Dhiraj and Gupta, Abhinav and Malik, Jitendra and Salakhutdinov, Ruslan. Learning to Explore using Active Neural SLAM. Proceedings of the International Conference on Learning Representations (ICLR)
-
[64]
Neural Topological SLAM for Visual Navigation
Chaplot, Devendra Singh and Salakhutdinov, Ruslan and Gupta, Abhinav and Gupta, Saurabh. Neural Topological SLAM for Visual Navigation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
-
[65]
Object Goal Navigation using Goal-Oriented Semantic Exploration
Chaplot, Devendra Singh and Gandhi, Dhiraj and Gupta, Abhinav and Salakhutdinov, Ruslan. Object Goal Navigation using Goal-Oriented Semantic Exploration. Advances in Neural Information Processing Systems (NeurIPS)
-
[66]
Learning to Map for Active Semantic Goal Navigation
Georgakis, Georgios and Bucher, Bernadette and Schmeckpeper, Karl and Singh, Siddharth and Daniilidis, Kostas. Learning to Map for Active Semantic Goal Navigation. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
-
[67]
PONI: Potential Functions for ObjectGoal Navigation with Interaction-Free Learning
Ramakrishnan, Santhosh Kumar and Chaplot, Devendra Singh and Al-Halah, Ziad and Malik, Jitendra and Grauman, Kristen. PONI: Potential Functions for ObjectGoal Navigation with Interaction-Free Learning. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
-
[68]
Visual Semantic Navigation using Scene Priors
Yang, Wei and Wang, Xiaolong and Farhadi, Ali and Gupta, Abhinav and Mottaghi, Roozbeh. Visual Semantic Navigation using Scene Priors. Proceedings of the International Conference on Learning Representations (ICLR)
-
[69]
Occupancy Anticipation for Efficient Exploration and Navigation
Ramakrishnan, Santhosh Kumar and Al-Halah, Ziad and Grauman, Kristen. Occupancy Anticipation for Efficient Exploration and Navigation. Proceedings of the European Conference on Computer Vision (ECCV)
-
[70]
and Fischer, Martin and Malik, Jitendra and Savarese, Silvio
Armeni, Iro and He, Zhi-Yang and Gwak, JunYoung and Zamir, Amir R. and Fischer, Martin and Malik, Jitendra and Savarese, Silvio. 3D Scene Graph: A Structure for Unified Semantics, 3D Space, and Camera. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
-
[71]
OpenScene: 3D Scene Understanding with Open Vocabularies
Peng, Songyou and Genova, Kyle and Jiang, Chiyu and Tagliasacchi, Andrea and Pollefeys, Marc and Funkhouser, Thomas. OpenScene: 3D Scene Understanding with Open Vocabularies. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
-
[72]
and Torralba, Antonio and Shkurti, Florian and Paull, Liam
Gu, Qiao and Kuwajerwala, Ali and Morin, Sacha and Jatavallabhula, Krishna Murthy and Sen, Bipasha and Agarwal, Aditya and Rivera, Corban and Paul, William and Ellis, Kirsty and Chellappa, Rama and Gan, Chuang and de Melo, Celso Miguel and Tenenbaum, Joshua B. and Torralba, Antonio and Shkurti, Florian and Paull, Liam. ConceptGraphs: Open-Vocabulary 3D Sc...
-
[73]
Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation
Werby, Abdelrhman and Huang, Chenguang and Buchner, Martin and Valada, Abhinav and Burgard, Wolfram. Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation. Proceedings of Robotics: Science and Systems (RSS)
-
[74]
Tang, Yujie and Wang, Meiling and Deng, Yinan and Zheng, Zibo and Zhong, Jiagui and Yue, Yufeng. OpenObject-NAV: Open-Vocabulary Object-Oriented Navigation Based on Dynamic Carrier-Relationship Scene Graph. arXiv:2409.18743
-
[75]
ESC: Exploration with Soft Commonsense Constraints for Zero-Shot Object Navigation
Zhou, Kaiwen and Zheng, Kaizhi and Pryor, Connor and Shen, Yilin and Jin, Hongxia and Getoor, Lise and Wang, Xin Eric. ESC: Exploration with Soft Commonsense Constraints for Zero-Shot Object Navigation. Proceedings of the International Conference on Machine Learning (ICML)
-
[76]
SG-Nav: Online 3D Scene Graph Prompting for LLM-Based Zero-Shot Object Navigation
Yin, Hang and Xu, Xiuwei and Wu, Zhenyu and Zhou, Jie and Lu, Jiwen. SG-Nav: Online 3D Scene Graph Prompting for LLM-Based Zero-Shot Object Navigation. Advances in Neural Information Processing Systems (NeurIPS)
-
[77]
VoroNav: Voronoi-Based Zero-Shot Object Navigation with Large Language Model
Wu, Pengying and Mu, Yao and Wu, Bingxian and Hou, Yi and Ma, Ji and Zhang, Shanghang and Liu, Chang. VoroNav: Voronoi-Based Zero-Shot Object Navigation with Large Language Model. Proceedings of the International Conference on Machine Learning (ICML)
-
[78]
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. Proceedings of the International Conference on Machine Learning (ICML)
-
[79]
Learning Transferable Visual Models From Natural Language Supervision
Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and Krueger, Gretchen and Sutskever, Ilya. Learning Transferable Visual Models From Natural Language Supervision. Proceedings of the International Conference on Machine Lear...
-
[80]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Jiang, Qing and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and Zhang, Lei. Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. arXiv:2303.05499
work page internal anchor Pith review Pith/arXiv arXiv
-
[81]
and Lo, Wan-Yen and Dollar, Piotr and Girshick, Ross
Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Dollar, Piotr and Girshick, Ross. Segment Anything. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
-
[82]
Faster Segment Anything: Towards Lightweight SAM for Mobile Applications
Zhang, Chaoning and Han, Dongshen and Qiao, Yu and Kim, Jung Uk and Bae, Sung-Ho and Lee, Seungkyu and Hong, Choong Seon. Faster Segment Anything: Towards Lightweight SAM for Mobile Applications. arXiv:2306.14289
work page internal anchor Pith review Pith/arXiv arXiv
-
[83]
YOLO-World: Real-Time Open-Vocabulary Object Detection
Cheng, Tianheng and Song, Lin and Ge, Yixiao and Liu, Wenyu and Wang, Xinggang and Shan, Ying. YOLO-World: Real-Time Open-Vocabulary Object Detection. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
-
[84]
Simple Open-Vocabulary Object Detection with Vision Transformers
Minderer, Matthias and Gritsenko, Alexey and Stone, Austin and Neumann, Maxim and Weissenborn, Dirk and Dosovitskiy, Alexey and Mahendran, Aravindh and Arnab, Anurag and Dehghani, Mostafa and Shen, Zhuoran and Wang, Xiao and Zhai, Xiaohua and Kipf, Thomas and Houlsby, Neil. Simple Open-Vocabulary Object Detection with Vision Transformers. Proceedings of t...
-
[85]
ZSON: Zero-Shot Object-Goal Navigation using Multimodal Goal Embeddings
Majumdar, Arjun and Aggarwal, Gunjan and Devnani, Bhavika and Hoffman, Judy and Batra, Dhruv. ZSON: Zero-Shot Object-Goal Navigation using Multimodal Goal Embeddings. Advances in Neural Information Processing Systems (NeurIPS)
-
[86]
CoWs on Pasture: Baselines and Benchmarks for Language-Driven Zero-Shot Object Navigation
Gadre, Samir Yitzhak and Wortsman, Mitchell and Ilharco, Gabriel and Schmidt, Ludwig and Song, Shuran. CoWs on Pasture: Baselines and Benchmarks for Language-Driven Zero-Shot Object Navigation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
-
[87]
VLFM: Vision-Language Frontier Maps for Zero-Shot Semantic Navigation
Yokoyama, Naoki and Ha, Sehoon and Batra, Dhruv and Wang, Jiuguang and Bucher, Bernadette. VLFM: Vision-Language Frontier Maps for Zero-Shot Semantic Navigation. Proceedings of the IEEE International Conference on Robotics and Automation (ICRA)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.