LLM-based Models for Detecting Emerging Topics in Service Feedback
Pith reviewed 2026-06-26 05:06 UTC · model grok-4.3
The pith
A hybrid system of fine-tuned LLMs and expert oversight detects emerging topics in tax feedback with closer expert alignment than baseline models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the proposed methodology integrates fine-tuned and quantized LLMs with expert oversight in a human-in-the-loop framework to detect emerging service quality topics in multilingual feedback, yielding outputs that align more closely with assessments from experienced tax officers than baseline models while also limiting fabrication of unsupported content.
What carries the argument
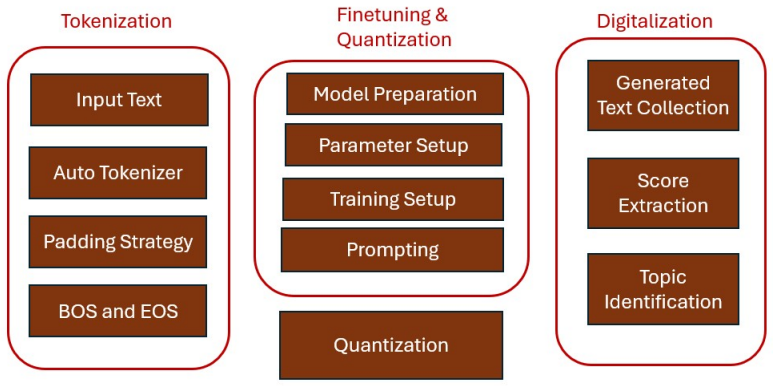
The human-AI collaboration framework that pairs fine-tuned quantized large language models with expert oversight to analyze feedback text and surface emerging topics.
If this is right
- Public agencies gain the ability to review larger volumes of multilingual feedback without a matching increase in manual effort.
- Potential inequities in service delivery become visible through the detected topics for targeted policy response.
- Decision-making in tax administrations can draw on more timely evidence derived from actual customer comments.
- The oversight step produces topic lists with fewer unsupported or fabricated elements than fully automated LLM outputs.
Where Pith is reading between the lines
- The same structure could be tested on feedback from other public services where language and volume create similar review bottlenecks.
- Repeated validation cycles might allow the model to require progressively less expert input while preserving alignment.
- A practical check would compare whether topics flagged early by the system later appear as measurable changes in compliance or complaint volumes.
Load-bearing premise
That the judgments provided by the tax officers form an independent and stable reference standard unaffected by the model outputs themselves.
What would settle it
A new collection of feedback texts where the topics generated by the proposed system receive consistently lower relevance or accuracy ratings from tax officers than topics from baseline models would falsify the alignment claim.
Figures


read the original abstract
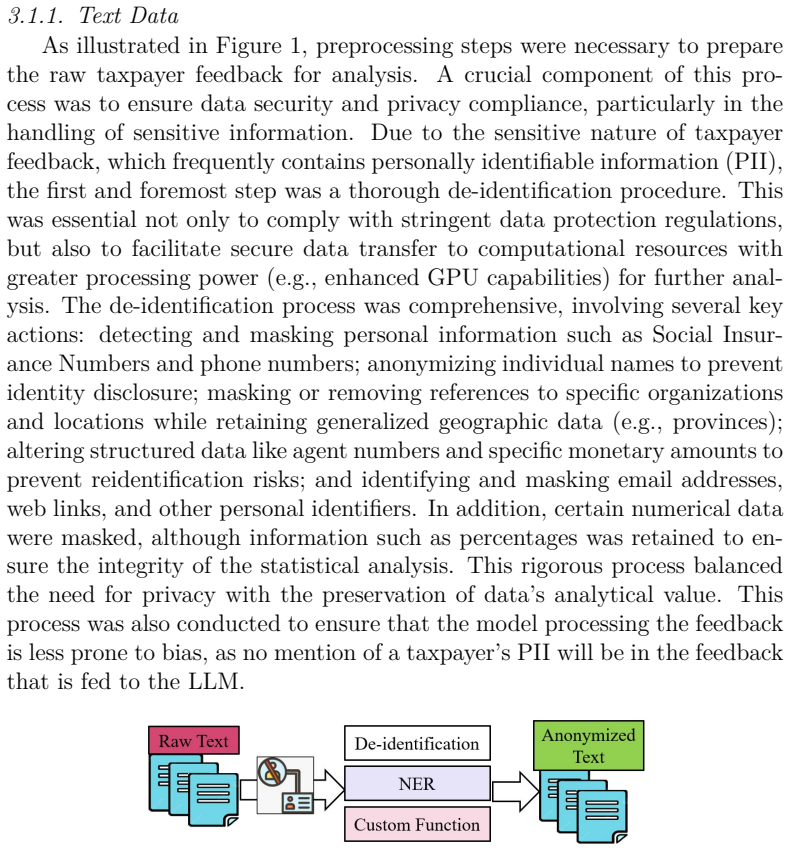
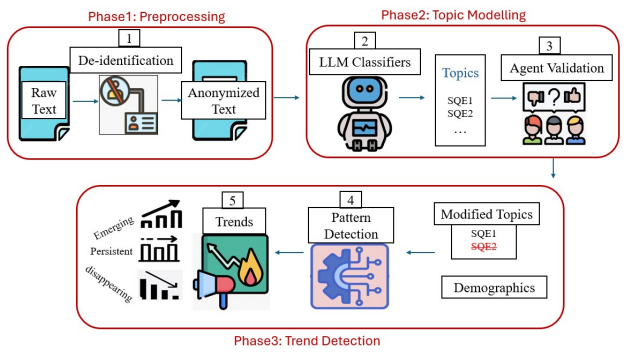
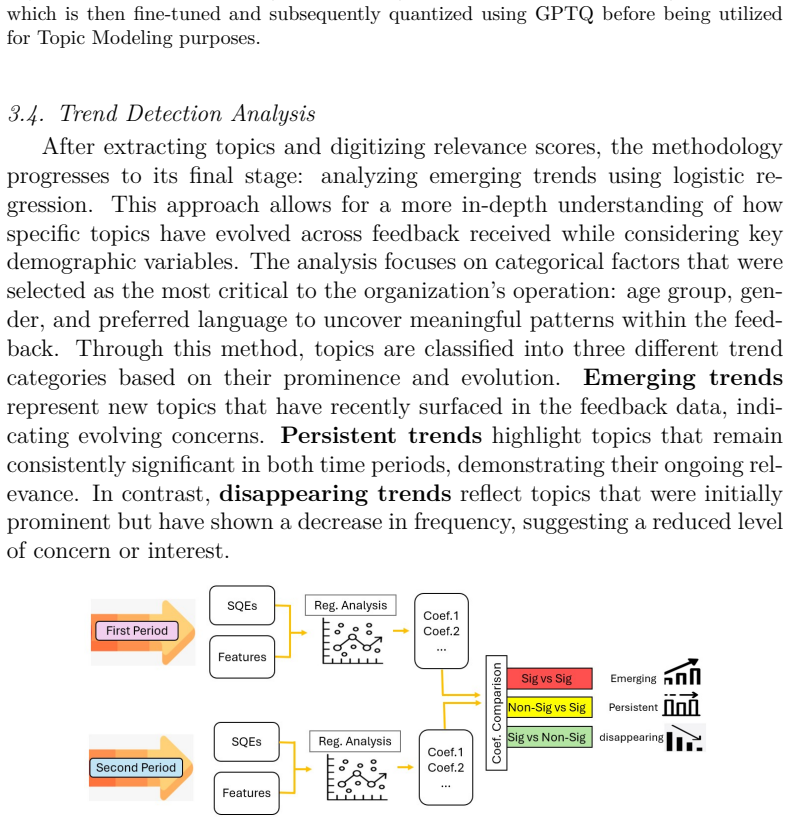
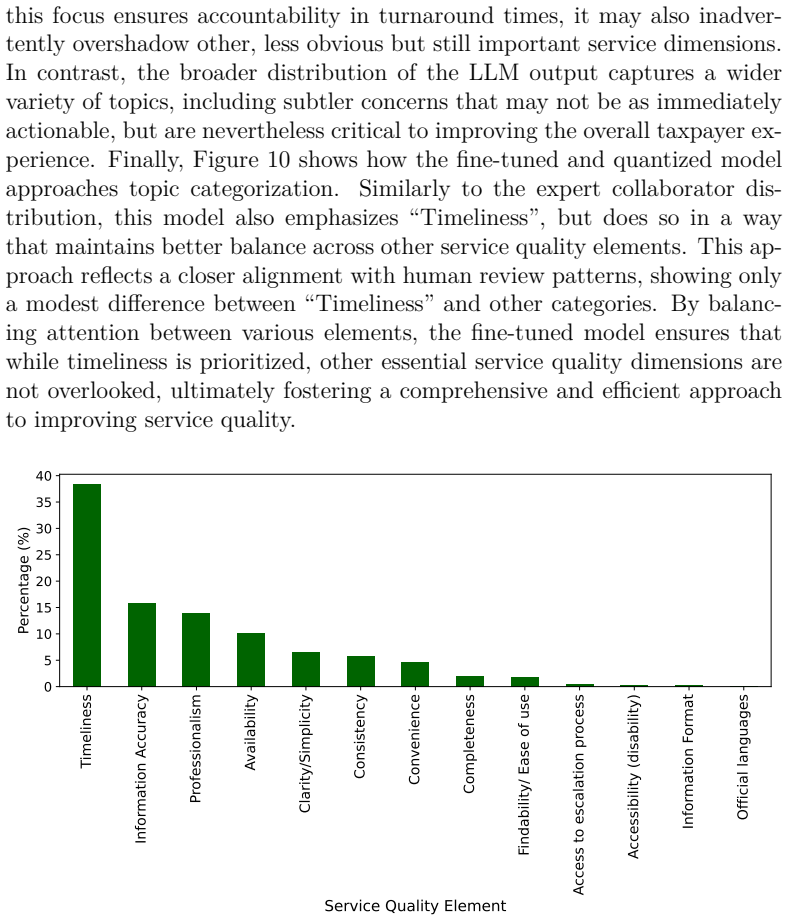
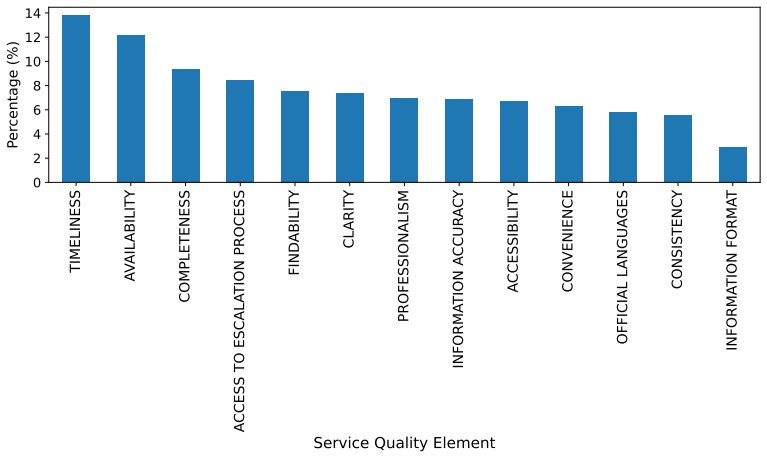
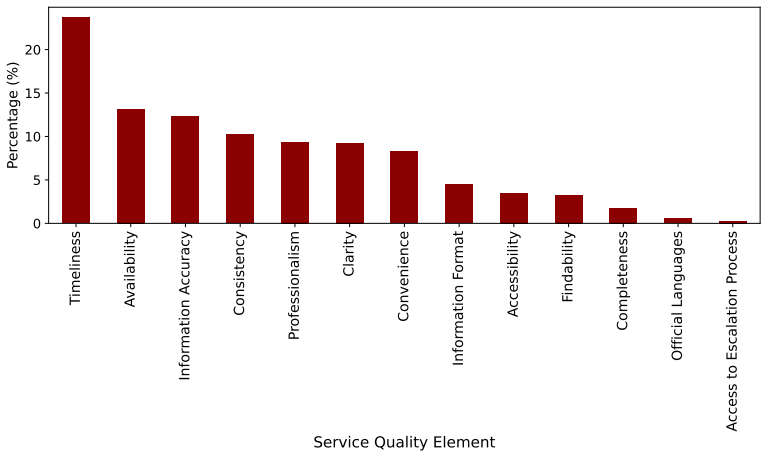
Enhancing the analysis of service feedback is essential for public sector organizations, particularly tax administrations, where trust and compliance depend on fair and effective service delivery. As feedback volumes grow, identifying emerging service quality issues and potential disparities across diverse populations becomes increasingly challenging. Traditional approaches often rely on manual review or static expert-defined indicators, limiting scalability and the ability to capture complex patterns in textual feedback. This paper presents a novel methodology that integrates large language models (LLMs), statistical techniques, and human-AI collaboration to improve multilingual customer feedback analysis. The primary objective is to detect emerging service quality topics that may also reveal potential inequities in service delivery. Our framework combines fine-tuned, quantized LLMs with expert oversight to produce accurate, computationally efficient, and context-aware analyses. The proposed approach was evaluated using similarity analysis and assessments from experienced tax officers, demonstrating stronger alignment with expert judgments than baseline models. By incorporating a human-in-the-loop framework, the methodology reduces LLM fabrication while improving the reliability and relevance of generated insights. The results demonstrate the practicality of combining LLMs with human expertise to support scalable, evidence-based decision-making in public sector organizations. This work contributes to the development of responsible AI systems that enhance service quality, responsiveness, fairness, and public trust through more effective analysis of multilingual customer feedback.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a methodology integrating fine-tuned quantized LLMs, statistical techniques, and human-AI collaboration to detect emerging service quality topics and potential inequities in multilingual customer feedback for public-sector organizations such as tax administrations. It claims the approach was evaluated via similarity analysis and assessments by experienced tax officers, showing stronger alignment with expert judgments than baseline models while the human-in-the-loop step reduces LLM fabrication and improves reliability.
Significance. If the empirical claims are substantiated with quantitative evidence, the work could provide a scalable framework for evidence-based analysis of service feedback in government contexts, supporting improved responsiveness, fairness, and trust. It targets a practical challenge where manual or static methods are insufficient for growing data volumes.
major comments (1)
- [Abstract] Abstract: The central claim that the proposed approach demonstrates 'stronger alignment with expert judgments than baseline models' supplies no quantitative metrics (similarity scores, agreement coefficients, p-values), no dataset size, no count of tax officers, no blinding or independence protocol, and no description of how outputs were presented to experts. This is load-bearing because the paper's contribution is framed entirely as an empirical improvement in reliability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need to strengthen the abstract's presentation of the empirical claims. We address the point directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the proposed approach demonstrates 'stronger alignment with expert judgments than baseline models' supplies no quantitative metrics (similarity scores, agreement coefficients, p-values), no dataset size, no count of tax officers, no blinding or independence protocol, and no description of how outputs were presented to experts. This is load-bearing because the paper's contribution is framed entirely as an empirical improvement in reliability.
Authors: We agree that the abstract, as currently written, is too high-level and does not supply the quantitative details needed to substantiate the central claim on its own. The body of the manuscript reports the similarity analysis and the tax-officer assessments, but these specifics are not summarized in the abstract. We will revise the abstract to include the key quantitative results (similarity scores, dataset size, number of officers) and a concise description of the evaluation protocol. We will also verify that the methods section explicitly states the blinding/independence procedures and how outputs were shown to experts; if any of these elements require additional clarification, they will be added during revision. revision: yes
Circularity Check
No circularity: empirical methodology with no derivations or self-referential reductions
full rationale
The paper presents an LLM-plus-human-in-the-loop methodology for topic detection evaluated by similarity analysis and tax-officer assessments. No equations, parameter-fitting steps, self-citations, or ansatzes appear in the supplied abstract or described structure. The central claim of stronger expert alignment is framed as an external empirical result rather than a quantity derived from the model's own outputs or prior self-citations. Because no load-bearing derivation chain exists that reduces to its own inputs by construction, the work is self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. L. Scott, S. A. Bone, G. L. Christensen, A. Lederer, M. Mende, B. G. Christensen, M. Cozac, Revealing and mitigating racial bias and discrimination in financial services, Journal of Marketing Research 61 (4) (2024) 598–618
2024
-
[2]
URLhttps://citizenfirst.ca/assets/uploads/ research-repository/Joint-Councils-Executive-Report-February-2020
Joint councils’ executive report february 2020, accessed: 2025-02-22. URLhttps://citizenfirst.ca/assets/uploads/ research-repository/Joint-Councils-Executive-Report-February-2020. pdf 35
2020
-
[3]
URLhttps://fedscoop.com/federal-government-websites-public-satisfaction/
FedScoop, Federal government websites public satisfaction, accessed: 2025-02-22 (2024). URLhttps://fedscoop.com/federal-government-websites-public-satisfaction/
2025
-
[4]
K. Michael, In this special section: Algorithmic bias—australia’s ro- bodebt and its human rights aftermath, IEEE Transactions on Tech- nology and Society 5 (3) (2024) 254–263.doi:10.1109/TTS.2024. 1234567
-
[5]
N. Li, X. Yang, I. A. Wong, R. Law, J. Y. Xu, Automating tourism online reviews: A neural network based aspect-oriented sentiment clas- sification, Journal of Hospitality and Tourism Technology 14 (1) (2023) 1–20.doi:10.1108/JHTT-03-2021-0099
-
[6]
X. Chen, Y. Chen, G. Yin, Exploring the motivations behind behavior: A theory-driven deep-learning framework for cyberviolence behavior de- tection, Decision Support Systems (2025) 114409
2025
-
[7]
Gunarathne, H
P. Gunarathne, H. Rui, A. Seidmann, Racial bias in customer service: evidence from twitter, Information Systems Research 33 (1) (2022) 43– 54
2022
-
[8]
Guilbeault, S
D. Guilbeault, S. Delecourt, T. Hull, B. S. Desikan, M. Chu, E. Nadler, Online images amplify gender bias, Nature 626 (8001) (2024) 1049–1055
2024
-
[9]
Zheng, G
J. Zheng, G. Yin, Y. Tan, J. Ding, Does help help? an empirical analysis of social desirability bias in ratings, Information Systems Research 35 (3) (2024) 1052–1073
2024
-
[10]
Linzmajer, S
M. Linzmajer, S. Brach, G. Walsh, T. Wagner, Customer ethnic bias in service encounters, Journal of Service Research 23 (2) (2020) 194–210
2020
-
[11]
Y. Xie, W. Yeoh, J. Wang, How self-selection bias in online reviews affects buyer satisfaction: A product type perspective, Decision Support Systems 181 (2024) 114199
2024
-
[12]
J. Guo, X. Wang, Y. Wu, Positive emotion bias: Role of emotional content from online customer reviews in purchase decisions, Journal of Retailing and Consumer Services 52 (2020) 101891. 36
2020
-
[13]
N. Chen, A. Li, K. Talluri, Reviews and self-selection bias with opera- tional implications, Management Science 67 (12) (2021) 7472–7492
2021
-
[14]
Kumar, K
Y. Kumar, K. Huang, A. Perez, G. Yang, J. J. Li, P. Morreale, D. Kruger, R. Jiang, Bias and cyberbullying detection and data gen- eration using transformer artificial intelligence models and top large language models, Electronics 13 (17) (2024) 3431
2024
-
[15]
Ravfogel, et al., Bias and fairness in large language models: A survey, Computational Linguistics 50 (3) (2024) 1097–1130
S. Ravfogel, et al., Bias and fairness in large language models: A survey, Computational Linguistics 50 (3) (2024) 1097–1130
2024
-
[16]
Hasan, D
Z. Hasan, D. Vaz, V. S. Athota, S. S. M. D´ esir´ e, V. Pereira, Can artificial intelligence (ai) manage behavioural biases among financial planners?, Journal of Global Information Management (JGIM) 31 (2) (2022) 1–18
2022
-
[17]
Y. Zhang, et al., From bias to fairness: The role of domain-specific knowledge and efficient fine-tuning in large language models, Journal of Artificial Intelligence Research 58 (2024) 201–225
2024
-
[18]
Pillai, Y
R. Pillai, Y. Ghanghorkar, B. Sivathanu, R. Algharabat, N. P. Rana, Adoption of artificial intelligence (ai) based employee experience (eex) chatbots, Information Technology & People 37 (1) (2024) 449–478
2024
-
[19]
M. Adam, M. Wessel, A. Benlian, Ai-based chatbots in customer service and their effects on user compliance, Electronic Markets 31 (2021) 427– 445
2021
-
[20]
Shah, et al., A review of natural language processing in contact centre automation, Pattern Analysis and Applications 26 (2023) 823–846
S. Shah, et al., A review of natural language processing in contact centre automation, Pattern Analysis and Applications 26 (2023) 823–846
2023
-
[21]
M. H. Miraz, A. Ya’u, S. Adeyinka-Ojo, J. B. Sarkar, M. T. Hasan, K. Hoque, H. H. Jin, Intention to use determinants of ai chatbots to improve customer relationship management efficiency, Cogent Business & Management 11 (1).doi:10.1080/23311975.2024.2411445
-
[22]
E. Mogaji, J. Farquhar, P. van Esch, C. Durodi´ e, R. Perez-Vega, Guest editorial: Artificial intelligence in financial services marketing, Interna- tional Journal of Bank Marketingdoi:10.1108/ijbm-09-2022-617
-
[23]
M. A. Camilleri, Artificial intelligence governance: Ethical considera- tions and implications for social responsibility, Expert systems 41 (7) (2024) e13406. 37
2024
-
[24]
Zimmermann, L
J. Zimmermann, L. E. Champagne, J. M. Dickens, B. T. Hazen, Ap- proaches to improve preprocessing for latent dirichlet allocation topic modeling, Decision Support Systems 185 (2024) 114310
2024
-
[25]
H. Li, Y. Qian, Y. Jiang, Y. Liu, F. Zhou, A novel label-based multi- modal topic model for social media analysis, Decision Support Systems 164 (2023) 113863
2023
-
[26]
B. A. H. Murshed, S. Mallappa, J. Abawajy, Short text topic modelling approaches in the context of big data: taxonomy, survey, and analysis, Artificial Intelligence Review. URLhttps://link.springer.com/article/10.1007/ s10462-023-10345-9
-
[27]
Rogers, O
A. Rogers, O. Kovaleva, A. Rumshisky, A primer in bertology: What we know about how bert works, Transactions of the Association for Computational Linguistics 8 (2020) 842–866
2020
-
[28]
Mishra, et al., Temporal analysis of computational economics: A topic modeling approach, International Journal of Data Science and An- alytics (2024) 1–15
M. Mishra, et al., Temporal analysis of computational economics: A topic modeling approach, International Journal of Data Science and An- alytics (2024) 1–15
2024
-
[29]
Y. F. Zhao, E. Niforatos, T. Custis, Y. Lu, J. Luo, Large language mod- els in design and manufacturing, Journal of Computing and Information Science in Engineering (2024) 1–6
2024
-
[30]
F. Sufi, An innovative way of analyzing covid topics with llm, Journal of Economy and Technologydoi:10.1016/j.ject.2024.11.004
-
[31]
Tzelves, P
L. Tzelves, P. Juliebø-Jones, B. K. Somani, The evolution of minimally invasive urologic surgery: Innovations, challenges, and opportunities, Frontiers in Surgery 11 (2024) 1525713
2024
-
[32]
O. Friha, M. A. Ferrag, B. Kantarci, B. Cakmak, A. Ozgun, N. Ghoualmi-Zine, Llm-based edge intelligence: A comprehensive sur- vey on architectures, applications, security and trustworthiness, IEEE Open Journal of the Communications Society 5 (2024) 5799–5856. doi:10.1109/OJCOMS.2024.3456549
-
[33]
A. M. Pereira, J. A. B. Moura, E. D. B. Costa, T. Vieira, A. R. Landim, E. Bazaki, V. Wanick, Customer models for artificial intelligence-based 38 decision support in fashion online retail supply chains, Decision Support Systems 158 (2022) 113795
2022
-
[34]
Schetgen, M
L. Schetgen, M. Bogaert, D. Van den Poel, Predicting donation behav- ior: Acquisition modeling in the nonprofit sector using facebook data, Decision Support Systems 141 (2021) 113446
2021
-
[35]
A. Ojo, N. Rizun, G. Walsh, M. I. Mashinchi, M. Venosa, M. N. Rao, Prioritising national healthcare service issues from free text feedback–a computational text analysis & predictive modelling approach, Decision Support Systems 181 (2024) 114215
2024
-
[36]
De Caigny, K
A. De Caigny, K. W. De Bock, S. Verboven, Hybrid black-box classi- fication for customer churn prediction with segmented interpretability analysis, Decision Support Systems 181 (2024) 114217
2024
-
[37]
S. Yi, X. Liu, Machine learning-based customer sentiment analysis for recommending shoppers, shops based on customers’ review, Complex & Intelligent Systems 6 (3) (2020) 621–634
2020
-
[38]
Hwang, J
S. Hwang, J. Kim, E. Park, S. J. Kwon, Who will be your next customer: A machine learning approach to customer return visits in airline services, Journal of Business Research 121 (2020) 121–126
2020
-
[39]
Maibaum, J
F. Maibaum, J. Kriebel, J. N. Foege, Selecting textual analysis tools to classify sustainability information in corporate reporting, Decision Support Systems 183 (2024) 114269
2024
-
[40]
Simester, A
D. Simester, A. Timoshenko, S. I. Zoumpoulis, Targeting prospective customers: Robustness of machine-learning methods to typical data challenges, Management Science 66 (6) (2020) 2495–2522
2020
-
[41]
Zaghloul, S
M. Zaghloul, S. Barakat, A. Rezk, Predicting e-commerce customer sat- isfaction: Traditional machine learning vs. deep learning approaches, Journal of Retailing and Consumer Services 79
-
[42]
Feldman, D
J. Feldman, D. J. Zhang, X. Liu, N. Zhang, Customer choice models vs. machine learning: Finding optimal product displays on alibaba, Opera- tions Research 70 (1) (2022) 309–328. 39
2022
-
[43]
M. S. Islam, M. Ferdusi, T. T. Aurpa, Words of war: A hybrid bert-cnn approach for topic-wise sentiment analysis on the russia-ukraine war, Expert Systems with Applications (2025) 127759
2025
-
[44]
A. R. Nair, Natural language processing (nlp) in chatbot customer ser- vice, International Journal for Research in Applied Science and Engi- neering Technology 13 (3) (2025) 715–721.doi:10.22214/ijraset. 2025.67353
-
[45]
L. R. Krosuri, R. S. Aravapalli, Novel heuristic-based hybrid resnext with recurrent neural network to handle multi class classification of sen- timent analysis, Machine Learning: Science and Technology 4 (1) (2023) 015033
2023
-
[46]
K. A. Tarnowska, Z. Ras, Nlp-based customer loyalty improvement rec- ommender system (clirs2), Big Data and Cognitive Computing 5 (1)
-
[47]
Shahin, F
M. Shahin, F. F. Chen, A. Hosseinzadeh, M. Maghanaki, A. Eghbalian, A novel approach to voice of customer extraction using gpt-3.5 turbo: Linking advanced nlp and lean six sigma 4.0, The International Journal of Advanced Manufacturing Technology 131 (7) (2024) 3615–3630
2024
-
[48]
T. Shu, Z. Wang, L. Lin, H. Jia, J. Zhou, Customer perceived risk measurement with nlp method in electric vehicles consumption market: Empirical study from china, Energies 15 (5)
-
[49]
W. Huang, K. F. Hew, L. K. Fryer, Chatbots for language learning—are they really useful? a systematic review of chatbot-supported language learning, Journal of Computer Assisted Learning 38 (1) (2022) 237–257. doi:10.1111/jcal.12610
-
[50]
K. Yang, R. Y. Lau, A. Abbasi, Getting personal: A deep learning artifact for text-based measurement of personality, Information Systems Research 34 (1) (2023) 194–222
2023
-
[51]
Bauer, M
K. Bauer, M. von Zahn, O. Hinz, Expl(ai)ned: The impact of explain- able artificial intelligence on users’ information processing, Information Systems Research 34 (4) (2023) 1582–1602. 40
2023
-
[52]
Guidotti, A
R. Guidotti, A. Monreale, S. Ruggieri, F. Turini, F. Giannotti, D. Pe- dreschi, A survey of methods for explaining black box models, ACM computing surveys (CSUR) 51 (5) (2018) 1–42
2018
-
[53]
Morley, L
J. Morley, L. Floridi, L. Kinsey, A. Elhalal, From what to how: an initial review of publicly available ai ethics tools, methods and research to translate principles into practices, Science and engineering ethics 26 (4) (2020) 2141–2168
2020
-
[54]
Face, Zephyr-7b-beta: A fine-tuned 7b parameter language model (2023)
H. Face, Zephyr-7b-beta: A fine-tuned 7b parameter language model (2023). URLhttps://huggingface.co/HuggingFaceH4/zephyr-7b-beta
2023
-
[55]
AI, Mistral-7b-instruct-v0.2: A high-performance language model (2023)
M. AI, Mistral-7b-instruct-v0.2: A high-performance language model (2023). URLhttps://huggingface.co/mistralai/Mistral-7B-v0.2
2023
-
[56]
AI, Mistral-7b-instruct-v0.2: A high-performance instruction-tuned language model (2023)
M. AI, Mistral-7b-instruct-v0.2: A high-performance instruction-tuned language model (2023). URLhttps://huggingface.co/mistralai/ Mistral-7B-Instruct-v0.2
2023
-
[57]
Frantar, S
E. Frantar, S. Ashkboos, T. Hoefler, D. Alistarh, Gptq: Accu- rate post-training quantization for generative pre-trained transformers, arXiv.Org
-
[58]
Frantar, et al., Gradient-preserving quantization for efficient large model training and inference, Journal of Neural Network Research
E. Frantar, et al., Gradient-preserving quantization for efficient large model training and inference, Journal of Neural Network Research
-
[59]
Smith, A
J. Smith, A. Doe, Advanced techniques in model quantization: Preserv- ing accuracy during training, IEEE Transactions on Neural Networks and Learning Systems
-
[60]
Garg, Ubis: Unigram bigram importance score for feature selection from short text, Expert Systems with Applications 195 (2022) 116563
M. Garg, Ubis: Unigram bigram importance score for feature selection from short text, Expert Systems with Applications 195 (2022) 116563
2022
-
[61]
Dettmers, A
T. Dettmers, A. Pagnoni, A. Holtzman, L. Zettlemoyer, Qlora: Efficient finetuning of quantized llms, Advances in neural information processing systems 36 (2023) 10088–10115. 41
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.