Benchmarking Vision-Language-Action Models on SO-101: Failure and Recovery Analysis
Pith reviewed 2026-06-27 18:01 UTC · model grok-4.3
The pith
Pretrained VLA policies outperform imitation learning on low-cost SO-101 robots but performance stays highly task-dependent with execution instability as the main failure mode.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
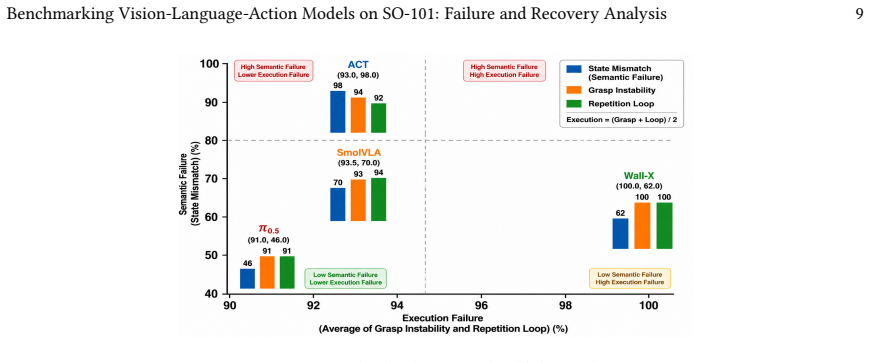
On the SO-101 platform the benchmark shows that stronger pretrained VLA policies generally outperform the imitation learning baseline across four tasks, although success rates remain highly task-dependent under low-cost robotic conditions. Execution instability is the dominant failure source while recovery capability differs substantially across architectures. The evaluation uses a structured failure taxonomy, semantic- and execution-level decomposition, and recovery-aware metrics beyond binary success rates.
What carries the argument
The SO-101 benchmark with four manipulation tasks, unified evaluation protocols, structured failure taxonomy, and recovery-aware metrics that decompose failures and assess recovery.
If this is right
- Pretrained VLA models deliver higher task success than imitation learning under low-cost deployment.
- Task success rates depend strongly on the specific manipulation task chosen.
- Execution instability accounts for the largest share of policy failures.
- Recovery performance after errors varies substantially between different model architectures.
- Failure and recovery analysis yields more information than binary success rates alone.
Where Pith is reading between the lines
- Future model development may need to target execution stability as a priority separate from pretraining strength.
- Consistent performance on consumer robots could require additional task-specific adaptation beyond standard fine-tuning.
- Extending the benchmark to additional low-cost platforms would test whether the observed patterns generalize.
- Recovery mechanisms represent a distinct direction for improving real-world robustness.
Load-bearing premise
The four tasks together with unified evaluation protocols enable systematic comparison under embodiment uncertainty.
What would settle it
If pretrained VLA policies fail to outperform the imitation learning baseline on the SO-101 platform across the four tasks or if execution instability does not emerge as the dominant failure source in the structured taxonomy.
Figures

read the original abstract
Vision-Language-Action (VLA) models have demonstrated strong generalization in robotic manipulation, yet existing evaluations are primarily conducted in simulation or on expensive robotic platforms, leaving their robustness on affordable real-world robots largely unexplored. We present a standardized real-world benchmark for evaluating representative VLA and imitation learning policies on the low-cost SO-101 robotic platform. The benchmark comprises four representative manipulation tasks together with unified evaluation protocols, enabling systematic comparison under embodiment uncertainty. Using real-world teleoperated demonstrations, we fine-tune and evaluate $\pi_{0.5}$, SmolVLA, Wall-X, and ACT directly on the physical platform. Beyond conventional task success rates, the benchmark incorporates a structured failure taxonomy, semantic- and execution-level failure decomposition, and recovery-aware evaluation metrics to characterize policy robustness. Experimental results show that stronger pretrained VLA policies generally outperform the imitation learning baseline, although performance remains highly task-dependent under low-cost robotic deployment conditions. Execution instability emerges as the dominant failure source, while recovery capability varies substantially across architectures. These results highlight the importance of failure and recovery analysis beyond binary task success and establish SO-101 as a practical benchmark for evaluating embodied AI systems under realistic low-cost robotic deployment conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a real-world benchmark on the low-cost SO-101 robotic arm for evaluating Vision-Language-Action (VLA) models and an imitation-learning baseline. It defines four manipulation tasks with unified protocols, fine-tunes and tests π0.5, SmolVLA, Wall-X, and ACT from teleoperated demonstrations, and augments standard success rates with a structured failure taxonomy, semantic/execution-level decomposition, and recovery-aware metrics. The central empirical finding is that stronger pretrained VLA policies generally outperform the baseline, yet performance is highly task-dependent, execution instability is the dominant failure mode, and recovery capability varies across architectures.
Significance. If the reported measurements hold, the work supplies a practical, accessible testbed for embodied AI under realistic hardware constraints and embodiment uncertainty. The emphasis on failure decomposition and recovery metrics, rather than binary success alone, is a constructive addition to the evaluation toolkit. The explicit qualification that results are task-dependent avoids over-generalization and aligns with the benchmark's stated scope.
minor comments (2)
- Abstract: the high-level claims would be strengthened by the inclusion of at least one quantitative result (e.g., mean success rate or dominant failure percentage) with an indication of variability across runs or tasks.
- The four-task composition is presented as enabling systematic comparison; a brief justification in §3 or §4 for why these particular tasks adequately sample the space of low-cost manipulation would help readers assess the scope of the benchmark.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report does not enumerate any specific major comments, so we have no point-by-point responses to provide. We remain ready to incorporate any minor editorial or clarification changes requested by the editor.
Circularity Check
No significant circularity; purely empirical benchmark
full rationale
The paper is a real-world empirical benchmark study that reports direct experimental measurements of policy performance, failure modes, and recovery on the SO-101 platform across four tasks. No derivations, equations, fitted parameters presented as predictions, or self-citation chains appear in the provided text or abstract. Central claims rest on observed task success rates and failure taxonomy rather than any reduction to inputs by construction, satisfying the self-contained criterion for score 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four manipulation tasks are representative and the unified protocols enable systematic comparison under embodiment uncertainty.
Reference graph
Works this paper leans on
-
[1]
Danny Driess, Fei Xia, Mehdi S M Sajjadi, et al. 2023. PaLM-E: An Embodied Multimodal Language Model.arXiv preprint arXiv:2303.03378(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Franka Emika GmbH. 2020. Franka Emika Panda Robot. https://www.franka.de/technology. Accessed: 2026-05-28
2020
-
[3]
Physical Intelligence, Kevin Black, Noah Brown, et al. 2025. 𝑝𝑖 0.5: A Vision-Language-Action Model with Open-World Generalization.arXiv preprint arXiv:2504.16054(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J Davison. 2020. RLBench: The Robot Learning Benchmark & Learning Environment. IEEE Robotics and Automation Letters5, 2 (2020), 3019–3026. doi:10.1109/LRA.2020.2974707
-
[5]
M. J. Kim, K. Pertsch, S. Karamcheti, et al. 2024. OpenVLA: An Open-Source Vision-Language-Action Model.arXiv preprint arXiv:2406.09246(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
LeRobot Community. 2024. SO-101 Low-Cost Robotic Manipulation Platform. https://github.com/huggingface/lerobot. Open-source low-cost robot platform used for embodied AI research
2024
-
[7]
Open X-Embodiment Collaboration et al. 2023. Open X-Embodiment: Robotic Learning Datasets and RT-X Models.arXiv preprint arXiv:2310.08864 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Xinchuan Qiu and Yi Yu. 2026. SO-101 400-Demonstrations VLA Evaluation Dataset. https://huggingface.co/collections/Qiu-Xinchuan/400-so-101- vla-evaluate-dataset
2026
-
[9]
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. 2025. SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics.arXiv preprint arXiv:2506.01844 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Octo Model Team, D Ghosh, H Walke, et al. 2024. Octo: An Open-Source Generalist Robot Policy.arXiv preprint arXiv:2405.12213(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Trossen Robotics. 2020. WidowX Robot Arm. https://www.trossenrobotics.com/widowxrobotarm. Accessed: 2026-05-28
2020
-
[12]
X-Square Robot Team. 2025. Building General-Purpose Robots Based on Embodied Foundation Models. https://github.com/X-Square-Robot/wall-x
2025
-
[13]
Tony Z Zhao, Vikash Kumar, Sergey Levine, et al. 2023. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware.arXiv preprint arXiv:2304.13705(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Yuke Zhu, Josiah Wong, Ajay Mandlekar, et al. 2020. robosuite: A Modular Simulation Framework and Benchmark for Robot Learning. https: //arxiv.org/abs/2009.12293. InConference on Robot Learning (CoRL)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[15]
Blake Zitkovich, Tianli Yu, Sherry Xu, et al. 2023. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. InConference on Robot Learning (CoRL). 2165–2183. Manuscript submitted to ACM
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.