COSM: A Cooperative Scheduling Framework for Concurrent PIM and CPU Execution on Mobile Devices
Pith reviewed 2026-07-01 06:25 UTC · model grok-4.3
The pith
COSM lets PIM and CPU run concurrently on mobile devices by filling CPU idle times with PIM commands, achieving up to 2.8 times higher PIM throughput with less than 2 percent CPU slowdown.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
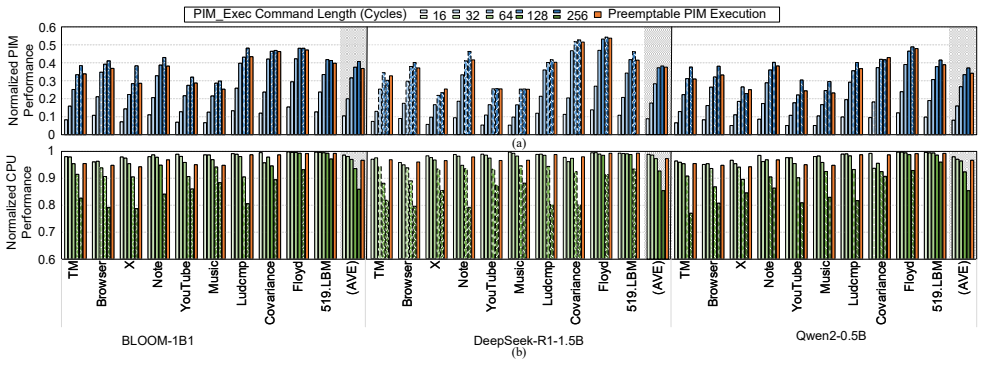
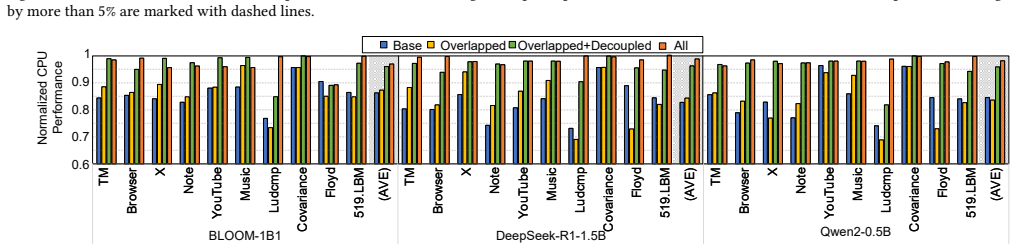
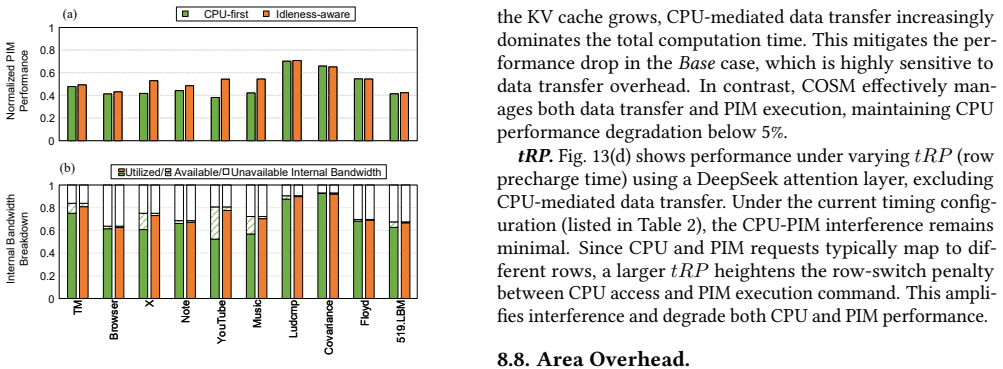
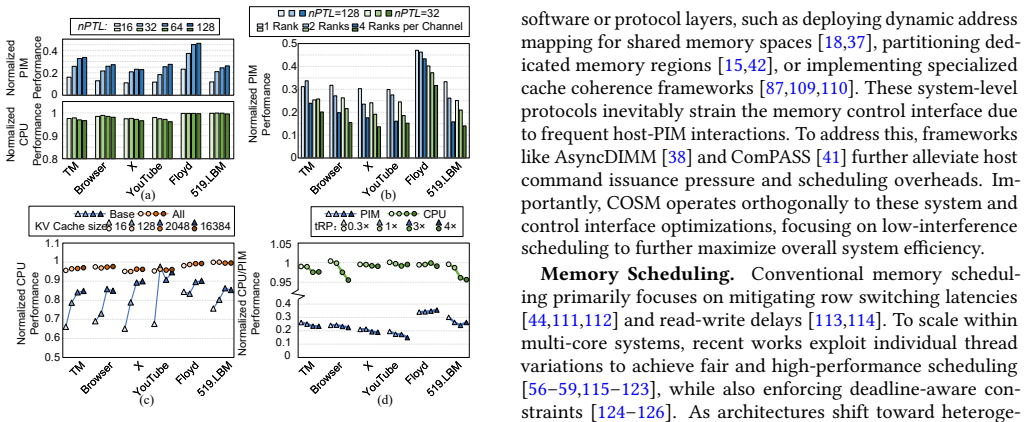
The central discovery is that a low-interference PIM control interface, which produces the maximum number of PIM commands without affecting CPU memory accesses, combined with an idleness-aware scheduler that inserts PIM commands into idle windows in the CPU access sequence, enables concurrent execution. This approach not only conceals PIM latency from the CPU but also allows PIM execution to overlap with data transfers. On workloads involving LLMs and mobile applications, it delivers up to 2.8x PIM throughput improvement over baseline methods while incurring under 2.0% CPU performance loss.
What carries the argument
The idleness-aware scheduling method that places PIM commands into CPU idle time windows, supported by a low-interference PIM control interface.
If this is right
- PIM latency can be hidden from the CPU, preserving its performance during concurrent runs.
- PIM execution can overlap with data transfer for better overall efficiency.
- Bank conflicts and bus congestion are minimized through careful command generation and timing.
- Mobile devices can support both LLMs and other apps concurrently with PIM acceleration.
Where Pith is reading between the lines
- The method might apply to other shared-memory PIM systems if idle patterns are similar.
- Hardware designers could add idle detection logic to memory controllers based on this idea.
- Testing on a wider range of workloads could reveal if the 2.8x gain is consistent across different access patterns.
Load-bearing premise
CPU memory access sequences must contain sufficient idle time windows, and the PIM interface must avoid creating extra bank conflicts or congestion not captured in the model.
What would settle it
Measuring PIM throughput and CPU performance on actual mobile hardware executing the same LLM and workload traces, checking if gains persist when idle windows are limited or conflicts increase.
Figures





read the original abstract
The development of on-device large language models (LLMs) is driven by the need for privacy and fast response times. Energy-intensive data transfer on mobile devices makes Processing-in-Memory (PIM) an effective solution. Due to stringent DRAM cost constraints, limited physical footprint on circuit boards, and the interaction between applications and LLMs, it is imperative for the CPU and PIM to operate concurrently within a shared memory space. However, challenges such as bank conflicts and bus congestion can arise, potentially diminishing the performance and energy benefits of PIM. To address this challenge, we introduce COSM, a cooperative scheduling framework designed to facilitate the concurrent operation of PIM and CPU tasks on mobile platforms. Our key innovations include: 1) a low-interference PIM control interface that generates the maximum number of PIM commands without disrupting CPU memory accesses; 2) an idleness-aware scheduling method that integrates PIM commands into available idle time windows within the CPU's access sequence. COSM not only hides PIM execution latency from the CPU, but also overlaps PIM execution with data transfer. Experiments on concurrent execution of LLMs and mobile workloads, including mobile applications and compute-intensive kernels, demonstrate that COSM improves PIM throughput by up to 2.8x compared to the baseline scheduling method with less than 2.0% CPU performance loss.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces COSM, a cooperative scheduling framework for concurrent PIM and CPU execution on mobile devices. It proposes a low-interference PIM control interface that maximizes PIM commands without disrupting CPU accesses and an idleness-aware scheduler that inserts PIM commands into CPU idle time windows. On concurrent LLM and mobile workloads, it claims up to 2.8x PIM throughput improvement versus a baseline scheduler with under 2% CPU performance loss.
Significance. If the evaluation holds, the work addresses a practical barrier to PIM adoption on mobile platforms by enabling safe overlap of PIM and CPU traffic in a shared DRAM space, which could improve both performance and energy efficiency for on-device LLMs under tight cost and footprint constraints.
major comments (2)
- [Abstract] Abstract: the reported 2.8x PIM throughput gain and <2% CPU loss are presented without any description of the experimental setup, workload selection criteria, error bars, simulator fidelity (bank-level timing, bus model), or the method used to identify and measure CPU idle windows. These omissions are load-bearing because the central claim rests on the scheduler successfully locating usable idle slots and the interface issuing maximum commands without unmodeled contention.
- [Evaluation] Evaluation section (implied by the abstract's experimental claims): the paper does not demonstrate that the measured overlap survives when CPU access sequences are taken from production mobile DRAM traces rather than filtered or generated workloads, nor does it quantify residual bank conflicts or bus congestion that the low-interference interface might still induce. This directly affects whether the 2.8x figure is an artifact of idealized idle-window assumptions.
minor comments (1)
- [Abstract] Abstract: the baseline scheduler against which the 2.8x gain is measured is not named or briefly characterized.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 2.8x PIM throughput gain and <2% CPU loss are presented without any description of the experimental setup, workload selection criteria, error bars, simulator fidelity (bank-level timing, bus model), or the method used to identify and measure CPU idle windows. These omissions are load-bearing because the central claim rests on the scheduler successfully locating usable idle slots and the interface issuing maximum commands without unmodeled contention.
Authors: Abstracts are concise by design, but we agree that the numerical claims would benefit from additional context. The Evaluation section provides the simulator details (cycle-accurate model with bank-level timing and bus model), workload selection criteria (real mobile applications and compute-intensive kernels run concurrently with LLM inference), error bars on all figures, and the idleness-aware scheduling algorithm for detecting CPU idle windows. We will revise the abstract to add one sentence briefly noting that results come from detailed simulation of representative mobile workloads. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by the abstract's experimental claims): the paper does not demonstrate that the measured overlap survives when CPU access sequences are taken from production mobile DRAM traces rather than filtered or generated workloads, nor does it quantify residual bank conflicts or bus congestion that the low-interference interface might still induce. This directly affects whether the 2.8x figure is an artifact of idealized idle-window assumptions.
Authors: The workloads are drawn from actual mobile applications and kernels executing alongside LLM inference, which capture realistic access patterns under mobile constraints. The low-interference interface and idleness-aware scheduler are evaluated for their ability to limit contention, with results showing <2% CPU slowdown. We did not evaluate against raw production DRAM traces. We will add a paragraph in the Evaluation section discussing workload representativeness and any observed residual bank or bus effects to address this concern. revision: partial
Circularity Check
No significant circularity; claims rest on empirical evaluation against baseline
full rationale
The paper introduces COSM as a scheduling framework with two stated innovations (low-interference PIM interface and idleness-aware scheduling) and reports throughput and overhead numbers from direct experimental comparison on LLM + mobile workloads. No equations, fitted parameters, or self-citation chains are presented in the provided text that would reduce the 2.8x claim or the <2% loss figure to quantities defined by the inputs themselves. The central results are therefore independent empirical measurements rather than self-referential derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Moshi: a speech-text foundation model for real-time dialogue
A. Défossez, L. Mazaré, M. Orsini, A. Royer, P. Pérez, H. Jégou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue, ” arXiv e-prints, p. arXiv:2410.00037, Sep. 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction,
Q. Chen, Y. Chen, Y. Chen, M. Chen, Y. Chen, C. Deng, Z. Du, R. Gao, C. Gao, Z. Gao, Y. Li, X. Lv, J. Liu, H. Luo, B. Ma, C. Ni, X. Shi, J. Tang, H. Wang, H. Wang, W. Wang, Y. Wang, Y. Xu, F. Yu, Z. Yan, Y. Yang, B. Yang, X. Yang, G. Yang, T. Zhao, Q. Zhang, S. Zhang, N. Zhao, P. Zhang, C. Zhang, and J. Zhou, “MinMo: A Multimodal Large Language Model for ...
-
[3]
Voila: Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play,
Y. Shi, Y. Shu, S. Dong, G. Liu, J. Sesay, J. Li, and Z. Hu, “Voila: Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play, ” arXiv e-prints, p. arXiv:2505.02707, May 2025
-
[4]
Simultaneous Ma- chine Translation with Large Language Models,
M. Wang, J. Zhao, T.-T. Vu, F. Shiri, E. Shareghi, and G. Haffari, “Simultaneous Ma- chine Translation with Large Language Models, ”arXiv e-prints, p. arXiv:2309.06706, Sep. 2025
-
[5]
LLMs Can Achieve High-quality Simultaneous Machine Translation as Efficiently as Offline,
B. Fu, M. Liao, K. Fan, C. Li, L. Zhang, Y. Chen, and X. Shi, “LLMs Can Achieve High-quality Simultaneous Machine Translation as Efficiently as Offline, ”arXiv e-prints, p. arXiv:2504.09570, Apr. 2025
-
[6]
MediaPipe: A Framework for Building Perception Pipelines
C. Lugaresi, J. Tang, H. Nash, C. McClanahan, E. Uboweja, M. Hays, F. Zhang, C.-L. Chang, M. G. Yong, J. Lee, W.-T. Chang, W. Hua, M. Georg, and M. Grundmann, “MediaPipe: A Framework for Building Perception Pipelines, ”arXiv e-prints, p. arXiv:1906.08172, Jun. 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[7]
MotionBridge: Dynamic Video Inbetweening with Flexible Controls,
M. Tanveer, Y. Zhou, S. Niklaus, A. Mahdavi Amiri, H. Zhang, K. K. Singh, and N. Zhao, “MotionBridge: Dynamic Video Inbetweening with Flexible Controls, ” arXiv e-prints, p. arXiv:2412.13190, Dec. 2024
-
[8]
Apple Intelligence,
Apple Inc., “Apple Intelligence, ” https://www.apple.com/apple-intelligence/, 2024, accessed: 2025-11-05
2024
-
[9]
Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition,
H. Chen, Y. Wang, K. Han, D. Li, L. Li, Z. Bi, J. Li, H. Wang, F. Mi, M. Zhu, B. Wang, K. Song, Y. Fu, X. He, Y. Luo, C. Zhu, Q. He, X. Wu, W. He, H. Hu, Y. Tang, D. Tao, X. Chen, and Y. Wang, “Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition, ”arXiv e-prints, p. arXiv:2505.22375, May 2025
-
[10]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone,
Y. Yao, T. Yu, A. Zhang, C. Wang, J. Cui, H. Zhu, T. Cai, H. Li, W. Zhao, Z. Heet al., “MiniCPM-V: A GPT-4V Level MLLM on Your Phone, ”Nat Commun 16, 5509 (2025), 2025
2025
-
[11]
Samsung Electronics,Galaxy.ai - The #1 All-in-One AI Platform, https://galaxy.ai/, 2024, accessed: 2025-11-05
2024
-
[12]
BlueLM-V-3B: Algorithm and System Co-Design for Multimodal Large Language Models on Mobile Devices,
X. Lu, Y. Chen, C. Chen, H. Tan, B. Chen, Y. Xie, R. Hu, G. Tan, R. Wu, Y. Hu, Y. Zeng, L. Wu, L. Bian, Z. Wang, L. Liu, Y. Yang, H. Xiao, A. Zhou, Y. Wen, X. Chen, S. Ren, and H. Li, “BlueLM-V-3B: Algorithm and System Co-Design for Multimodal Large Language Models on Mobile Devices, ” inProceedings of the IEEE/CVF Conference on Computer Vision and Patter...
2025
-
[13]
Unlocking On-Device Generative AI with an NPU and Heterogeneous Computing,
Qualcomm Technologies, Inc., “Unlocking On-Device Generative AI with an NPU and Heterogeneous Computing, ” Qualcomm, Tech. Rep., 2024, accessed: 2025-11-15
2024
-
[14]
vivo Unveils New AI Strategy: BlueHeart Large Model Matrix and Major Upgrade to OriginOS 5,
vivo, “vivo Unveils New AI Strategy: BlueHeart Large Model Matrix and Major Upgrade to OriginOS 5, ” https://www.vivo.com.cn/brand/news/detail?id=1271, 2024, accessed: 2025-11-15
2024
-
[15]
The true Processing In Memory accelerator,
F. Devaux, “The true Processing In Memory accelerator, ” in2019 IEEE Hot Chips 31 Symposium (HCS), Aug 2019, pp. 1–24
2019
-
[16]
A 1ynm 1.25V 8Gb, 16Gb/s/pin GDDR6-based Accelerator-in-Memory supporting 1TFLOPS MAC Operation and Various Activation Functions for Deep- Learning Applications,
S. Lee, K. Kim, S. Oh, J. Park, G. Hong, D. Ka, K. Hwang, J. Park, K. Kang, J. Kim, J. Jeon, N. Kim, Y. Kwon, K. Vladimir, W. Shin, J. Won, M. Lee, H. Joo, H. Choi, J. Lee, D. Ko, Y. Jun, K. Cho, I. Kim, C. Song, C. Jeong, D. Kwon, J. Jang, I. Park, J. Chun, and J. Cho, “A 1ynm 1.25V 8Gb, 16Gb/s/pin GDDR6-based Accelerator-in-Memory supporting 1TFLOPS MAC...
2022
-
[17]
PUSHtap: PIM-based In-Memory HTAP with Unified Data Storage Format,
Y. Zhao, M. Gao, H. Zhang, F. Liu, G. Chen, H. Xian, H. Guan, and L. Jiang, “PUSHtap: PIM-based In-Memory HTAP with Unified Data Storage Format, ” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ser. ASPLOS ’25, 2025, pp. 179–194
2025
-
[18]
UM-PIM: DRAM-based PIM with Uniform & Shared Memory Space,
Y. Zhao, M. Gao, F. Liu, Y. Hu, Z. Wang, H. Lin, J. Li, H. Xian, H. Dong, T. Yang, N. Jing, X. Liang, and L. Jiang, “UM-PIM: DRAM-based PIM with Uniform & Shared Memory Space, ” in2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), June 2024, pp. 644–659
2024
-
[19]
PAPI: Exploiting Dynamic Parallelism in Large Language Model De- coding with a Processing-In-Memory-Enabled Computing System,
Y. He, H. Mao, C. Giannoula, M. Sadrosadati, J. Gómez-Luna, H. Li, X. Li, Y. Wang, and O. Mutlu, “PAPI: Exploiting Dynamic Parallelism in Large Language Model De- coding with a Processing-In-Memory-Enabled Computing System, ” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vo...
2025
-
[20]
NeuPIMs: NPU-PIM Heterogeneous Acceleration for Batched LLM Inferencing,
G. Heo, S. Lee, J. Cho, H. Choi, S. Lee, H. Ham, G. Kim, D. Mahajan, and J. Park, “NeuPIMs: NPU-PIM Heterogeneous Acceleration for Batched LLM Inferencing, ” in Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ser. ASPLOS ’24, 2024, pp. 722–737
2024
-
[21]
Unifying Two Operators with One PIM: Leveraging Hybrid Bonding for Efficient LLM Inference,
J. Chen, Y. Qi, K. Sun, Z. Lin, T. Wang, C. Ma, and Y. Wang, “Unifying Two Operators with One PIM: Leveraging Hybrid Bonding for Efficient LLM Inference, ” inAdvanced Parallel Processing Technologies, C. Li, X. Qian, D. Gizopoulos, and B. Grot, Eds., 2026, pp. 215–230
2026
-
[22]
Pimba: A Processing-in-Memory Acceleration for Post-Transformer Large Language Model Serving,
W. Kim, Y. Lee, Y. Kim, J. Hwang, S. Oh, J. Jung, A. Huseynov, W. G. Park, C. H. Park, D. Mahajan, and J. Park, “Pimba: A Processing-in-Memory Acceleration for Post-Transformer Large Language Model Serving, ” inProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’25, 2025, pp. 292–307
2025
-
[23]
AttAcc! Unleashing the Power of PIM for Batched Transformer-based Generative Model Inference,
J. Park, J. Choi, K. Kyung, M. J. Kim, Y. Kwon, N. S. Kim, and J. H. Ahn, “AttAcc! Unleashing the Power of PIM for Batched Transformer-based Generative Model Inference, ” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser. ASPLOS ’24, 2024, p. 103119
2024
-
[24]
Pyramid: Accelerating LLM Infer- ence With Cross-Level Processing-in-Memory,
L. Yan, X. Lu, X. Chen, Y. Han, and X.-H. Sun, “Pyramid: Accelerating LLM Infer- ence With Cross-Level Processing-in-Memory, ”IEEE Computer Architecture Letters, vol. 24, no. 1, pp. 121–124, Jan 2025
2025
-
[25]
A scalable processing-in-memory ac- celerator for parallel graph processing,
J. Ahn, S. Hong, S. Yoo, O. Mutlu, and K. Choi, “A scalable processing-in-memory ac- celerator for parallel graph processing, ” in2015 ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), June 2015, pp. 105–117
2015
-
[26]
PIM-enabled instructions: A low-overhead, locality-aware processing-in-memory architecture,
J. Ahn, S. Yoo, O. Mutlu, and K. Choi, “PIM-enabled instructions: A low-overhead, locality-aware processing-in-memory architecture, ” in2015 ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), June 2015, pp. 336–348
2015
-
[27]
Google Neural Network Models for Edge Devices: Analyzing and Mitigating Machine Learning Inference Bottlenecks,
A. Boroumand, S. Ghose, B. Akin, R. Narayanaswami, G. F. Oliveira, X. Ma, E. Shiu, and O. Mutlu, “Google Neural Network Models for Edge Devices: Analyzing and Mitigating Machine Learning Inference Bottlenecks, ” in2021 30th International Conference on Parallel Architectures and Compilation Techniques (PACT), Sep. 2021, pp. 159–172
2021
-
[28]
SISA: Set-Centric Instruction Set Architecture for Graph Mining on Processing-in-Memory Systems,
M. Besta, R. Kanakagiri, G. Kwasniewski, R. Ausavarungnirun, J. Beránek, K. Kanel- lopoulos, K. Janda, Z. Vonarburg-Shmaria, L. Gianinazzi, I. Stefan, J. G. Luna, J. Goli- nowski, M. Copik, L. Kapp-Schwoerer, S. Di Girolamo, N. Blach, M. Konieczny, O. Mutlu, and T. Hoefler, “SISA: Set-Centric Instruction Set Architecture for Graph Mining on Processing-in-...
2021
-
[29]
Google Workloads for Con- sumer Devices: Mitigating Data Movement Bottlenecks,
A. Boroumand, S. Ghose, Y. Kim, R. Ausavarungnirun, E. Shiu, R. Thakur, D. Kim, A. Kuusela, A. Knies, P. Ranganathan, and O. Mutlu, “Google Workloads for Con- sumer Devices: Mitigating Data Movement Bottlenecks, ” inProceedings of the Twenty-Third International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLO...
2018
-
[30]
PIM Is All You Need: A CXL-Enabled GPU-Free System for Large Language Model Inference,
Y. Gu, A. Khadem, S. Umesh, N. Liang, X. Servot, O. Mutlu, R. Iyer, and R. Das, “PIM Is All You Need: A CXL-Enabled GPU-Free System for Large Language Model Inference, ” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser. ASPLOS ’25, 2025, pp. 862–881
2025
-
[31]
Mutlu, S
O. Mutlu, S. Ghose, J. Gómez-Luna, and R. Ausavarungnirun,A Modern Primer on Processing in Memory, 2023, pp. 171–243
2023
-
[32]
Processing data where it makes sense in modern computing systems: En- abling in-memory computation,
O. Mutlu, “Processing data where it makes sense in modern computing systems: En- abling in-memory computation, ” in2018 7th Mediterranean Conference on Embedded Computing (MECO), June 2018, pp. 8–9
2018
-
[33]
Benchmarking a New Paradigm: Experimental Analysis and Characterization of a Real Processing-in-Memory System,
J. Gómez-Luna, I. E. Hajj, I. Fernandez, C. Giannoula, G. F. Oliveira, and O. Mutlu, “Benchmarking a New Paradigm: Experimental Analysis and Characterization of a Real Processing-in-Memory System, ”IEEE Access, vol. 10, pp. 52 565–52 608, 2022
2022
-
[34]
Evaluating Machine LearningWorkloads on Memory-Centric Com- puting Systems,
J. Gómez-Luna, Y. Guo, S. Brocard, J. Legriel, R. Cimadomo, G. F. Oliveira, G. Singh, and O. Mutlu, “Evaluating Machine LearningWorkloads on Memory-Centric Com- puting Systems, ” in2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), April 2023, pp. 35–49
2023
-
[35]
Benchmarking Memory-Centric Computing Systems: Analysis of Real Processing- In-Memory Hardware,
J. Gómez-Luna, I. El Hajj, I. Fernandez, C. Giannoula, G. F. Oliveira, and O. Mutlu, “Benchmarking Memory-Centric Computing Systems: Analysis of Real Processing- In-Memory Hardware, ” in2021 12th International Green and Sustainable Computing Conference (IGSC), Oct 2021, pp. 1–7
2021
-
[36]
Samsung PIM/PNM for Transfmer Based AI : Energy Efficiency on PIM/PNM Cluster,
J. H. Kim, Y. Ro, J. So, S. Lee, S.-h. Kang, Y. Cho, H. Kim, B. Kim, K. Kim, S. Park, J.-S. Kim, S. Cha, W.-J. Lee, J. Jung, J.-G. Lee, J. Lee, J. Song, S. Lee, J. Cho, J. Yu, and K. Sohn, “Samsung PIM/PNM for Transfmer Based AI : Energy Efficiency on PIM/PNM Cluster, ” in2023 IEEE Hot Chips 35 Symposium (HCS), Aug 2023, pp. 1–31
2023
-
[37]
PIM-MMU: A Memory Management Unit for Accelerating Data Transfers in Commercial PIM Systems,
D. Lee, B. Hyun, T. Kim, and M. Rhu, “PIM-MMU: A Memory Management Unit for Accelerating Data Transfers in Commercial PIM Systems, ” in2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), Nov 2024, pp. 627–642
2024
-
[38]
AsyncDIMM: Achieving Asynchronous Execution in DIMM-Based Near-Memory Processing,
L. Chen, D. Lyu, J. Jiang, Q. Wang, Z. Mao, and N. Jing, “AsyncDIMM: Achieving Asynchronous Execution in DIMM-Based Near-Memory Processing, ” in2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), March 2025, pp. 518–532
2025
-
[39]
Near Data Acceleration with Concurrent Host Access,
B. Y. Cho, Y. Kwon, S. Lym, and M. Erez, “Near Data Acceleration with Concurrent Host Access, ” in2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), May 2020, pp. 818–831
2020
-
[40]
Concurrent PIM and Load/Store Servicing in PIM-Enabled Memory,
S. Gupta, N. Madan, S. Puthoor, N. Jayasena, and S. Dwarkadas, “Concurrent PIM and Load/Store Servicing in PIM-Enabled Memory, ” in2025 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), May 2025, pp. 320–334
2025
-
[41]
ComPASS: A Compatible PIM Protocol Architecture and Scheduling Solution for Processor-PIM Collaboration,
S. Yu, H. Kim, K. Jeun, S. Hwang, S. Cho, and E. Lee, “ComPASS: A Compatible PIM Protocol Architecture and Scheduling Solution for Processor-PIM Collaboration, ” inProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’25, 2025, pp. 49–62
2025
-
[42]
25.4 A 20nm 6GB Function-In-Memory DRAM, Based on HBM2 with a 1.2TFLOPS Programmable Computing Unit Using Bank- Level Parallelism, for Machine Learning Applications,
Y.-C. Kwon, S. H. Lee, J. Lee, S.-H. Kwon, J. M. Ryu, J.-P. Son, O. Seongil, H.-S. Yu, H. Lee, S. Y. Kim, Y. Cho, J. G. Kim, J. Choi, H.-S. Shin, J. Kim, B. Phuah, H. Kim, M. J. Song, A. Choi, D. Kim, S. Kim, E.-B. Kim, D. Wang, S. Kang, Y. Ro, S. Seo, J. Song, J. Youn, K. Sohn, and N. S. Kim, “25.4 A 20nm 6GB Function-In-Memory DRAM, Based on HBM2 with a...
2021
-
[43]
JEDEC JESD209-5C: Low Power Double Data Rate 5 (LPDDR5),
JEDEC, “JEDEC JESD209-5C: Low Power Double Data Rate 5 (LPDDR5), ” JEDEC Solid State Technology Association, Tech. Rep., 6 2023, revision of JESD209-5B (June 2021)
2023
-
[44]
A case for exploiting subarray-level parallelism (SALP) in DRAM,
Y. Kim, V. Seshadri, D. Lee, J. Liu, and O. Mutlu, “A case for exploiting subarray-level parallelism (SALP) in DRAM, ” in2012 39th Annual International Symposium on Computer Architecture (ISCA), June 2012, pp. 368–379
2012
-
[45]
Tiered-latency DRAM: A low latency and low cost DRAM architecture,
D. Lee, Y. Kim, V. Seshadri, J. Liu, L. Subramanian, and O. Mutlu, “Tiered-latency DRAM: A low latency and low cost DRAM architecture, ” in2013 IEEE 19th Interna- tional Symposium on High Performance Computer Architecture (HPCA), Feb 2013, pp. 615–626
2013
-
[46]
PIM-AI: A Novel Architecture for High- Efficiency LLM Inference,
C. Ortega, Y. Falevoz, and R. Ayrignac, “PIM-AI: A Novel Architecture for High- Efficiency LLM Inference, ”arXiv e-prints, p. arXiv:2411.17309, Nov. 2024
-
[47]
ALPHA-PIM: Analysis of Linear Algebraic Process- ing for High-Performance Graph Applications on a Real Processing-In-Memory Sys- tem,
M. Barkhordar, A. Tabatabaeian, M. Sadrosadati, C. Giannoula, J. G. Luna, I. El Hajj, O. Mutlu, and A. R. Alameldeen, “ALPHA-PIM: Analysis of Linear Algebraic Process- ing for High-Performance Graph Applications on a Real Processing-In-Memory Sys- tem, ” in2025 IEEE International Symposium on Workload Characterization (IISWC), Oct 2025, pp. 257–271
2025
-
[48]
PyGim: An Efficient Graph Neural Network Library for Real Processing-In-Memory Architectures,
C. Giannoula, P. Yang, I. Fernandez, J. Yang, S. Durvasula, Y. X. Li, M. Sadrosadati, J. G. Luna, O. Mutlu, and G. Pekhimenko, “PyGim: An Efficient Graph Neural Network Library for Real Processing-In-Memory Architectures, ”Proc. ACM Meas. Anal. Comput. Syst., vol. 8, no. 3, Dec. 2024
2024
-
[49]
SparseP: Efficient Sparse Matrix Vector Multiplication on Real Processing-In- Memory Architectures,
C. Giannoula, I. Fernandez, J. Gómez-Luna, N. Koziris, G. Goumas, and O. Mutlu, “SparseP: Efficient Sparse Matrix Vector Multiplication on Real Processing-In- Memory Architectures, ” in2022 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), July 2022, pp. 288–291
2022
-
[50]
System Architecture and Software Stack for GDDR6-AiM,
Y. Kwon, K. Vladimir, N. Kim, W. Shin, J. Won, M. Lee, H. Joo, H. Choi, G. Kim, B. An, J. Kim, J. Lee, I. Kim, J. Park, C. Park, Y. Song, B. Yang, H. Lee, S. Kim, D. Kwon, S. Lee, K. Kim, S. Oh, J. Park, G. Hong, D. Ka, K. Hwang, J. Park, K. Kang, J. Kim, J. Jeon, M. Lee, M. Shin, M. Shin, J. Cha, C. Jung, K. Chang, C. Jeong, E. Lim, I. Park, J. Chun, and...
2022
-
[51]
Hardware Architecture and Software Stack for PIM Based on Commercial DRAM Technology : Industrial Product,
S. Lee, S.-h. Kang, J. Lee, H. Kim, E. Lee, S. Seo, H. Yoon, S. Lee, K. Lim, H. Shin, J. Kim, O. Seongil, A. Iyer, D. Wang, K. Sohn, and N. S. Kim, “Hardware Architecture and Software Stack for PIM Based on Commercial DRAM Technology : Industrial Product, ” in2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), June 2021, pp. 43–56
2021
-
[52]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, X. Zhang, X. Yu, Y. Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B. Wang, B. Wu, B. Feng, C. Lu, C. Zhao, C. Deng, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Ding, H. Gao, H. Qu, H. Li, J. Gu...
2025
-
[53]
Memory access scheduling,
S. Rixner, W. J. Dally, U. J. Kapasi, P. Mattson, and J. D. Owens, “Memory access scheduling, ” inProceedings of the 27th Annual International Symposium on Computer Architecture, ser. ISCA ’00, 2000, pp. 128–138
2000
-
[54]
Controller for a synchronous DRAM that maximizes throughput by allowing memory requests and commands to be issued out of order,
D. M. Zuravleff and J. I. Robinson, “Controller for a synchronous DRAM that maximizes throughput by allowing memory requests and commands to be issued out of order, ” May 1997, US Patent 5,630,096
1997
-
[55]
Memory Performance Attacks: Denial of Memory Service in Multi-Core Systems,
T. Moscibroda and O. Mutlu, “Memory Performance Attacks: Denial of Memory Service in Multi-Core Systems, ” in16th USENIX Security Symposium (USENIX Security 07), Aug 2007
2007
-
[56]
Stall-Time Fair Memory Access Scheduling for Chip Multiprocessors,
O. Mutlu and T. Moscibroda, “Stall-Time Fair Memory Access Scheduling for Chip Multiprocessors, ” in40th Annual IEEE/ACM International Symposium on Microar- chitecture (MICRO 2007), Dec 2007, pp. 146–160
2007
-
[57]
Parallelism-Aware Batch Scheduling: Enhancing both Performance and Fairness of Shared DRAM Systems,
O. Mutlu and T. Moscibroda, “Parallelism-Aware Batch Scheduling: Enhancing both Performance and Fairness of Shared DRAM Systems, ” in2008 International Symposium on Computer Architecture, June 2008, pp. 63–74
2008
-
[58]
The Blacklisting Memory Scheduler: Achieving high performance and fairness at low cost,
L. Subramanian, D. Lee, V. Seshadri, H. Rastogi, and O. Mutlu, “The Blacklisting Memory Scheduler: Achieving high performance and fairness at low cost, ” in2014 IEEE 32nd International Conference on Computer Design (ICCD), Oct 2014, pp. 8–15
2014
-
[59]
ATLAS: A scalable and high- performance scheduling algorithm for multiple memory controllers,
Y. Kim, D. Han, O. Mutlu, and M. Harchol-Balter, “ATLAS: A scalable and high- performance scheduling algorithm for multiple memory controllers, ” inHPCA - 16 2010 The Sixteenth International Symposium on High-Performance Computer Architecture, Jan 2010, pp. 1–12
2010
-
[60]
Ramu- lator 2.0: A Modern, Modular, and Extensible DRAM Simulator,
H. Luo, Y. C. Tuğrul, F. N. Bostancı, A. Olgun, A. G. Yağlıkçı, and O. Mutlu, “Ramu- lator 2.0: A Modern, Modular, and Extensible DRAM Simulator, ”IEEE Computer Architecture Letters, vol. 23, no. 1, pp. 112–116, Jan 2024
2024
-
[61]
Ramulator V2.0a,
CMU-SAFARI, “Ramulator V2.0a, ” https://github.com/CMU-SAFARI/ramulator2, 2023, accessed: 2025-11-05
2023
-
[62]
Ramulator: A Fast and Extensible DRAM Simulator,
Y. Kim, W. Yang, and O. Mutlu, “Ramulator: A Fast and Extensible DRAM Simulator, ” IEEE Computer Architecture Letters, vol. 15, no. 1, pp. 45–49, 2016
2016
-
[63]
DRAMPower 5: An Open-Source Power Simulator for Current Generation DRAM Standards,
L. Steiner, T. Psota, M. Mörz, D. Christ, M. Jung, and N. Wehn, “DRAMPower 5: An Open-Source Power Simulator for Current Generation DRAM Standards, ” in Proceedings of the Rapid Simulation and Performance Evaluation for Design Workshop, ser. RAPIDO ’25, 2025, pp. 8–16
2025
-
[64]
Snapdragon 888 5G Mobile Plat- form,
Qualcomm Technologies, Inc., “Snapdragon 888 5G Mobile Plat- form, ” https://www.qualcomm.com/smartphones/products/8-series/ snapdragon-888-5g-mobile-platform, 2020, accessed: 2026-02-19
2020
-
[65]
ZSim: fast and accurate microarchitectural simu- lation of thousand-core systems,
D. Sanchez and C. Kozyrakis, “ZSim: fast and accurate microarchitectural simu- lation of thousand-core systems, ” inProceedings of the 40th Annual International Symposium on Computer Architecture, ser. ISCA ’13, 2013, pp. 475–486
2013
-
[66]
Xiaomi Mi 11 Pro - Technical Specifications,
Xiaomi Corporation, “Xiaomi Mi 11 Pro - Technical Specifications, ” https://www. mi.com/mi11Pro/specs, 2021, accessed: 2026-02-19
2021
-
[67]
Stalker — Frida Documentation,
F. Developers, “Stalker — Frida Documentation, ” https://frida.re/docs/stalker/, 2025, accessed: 2025-11-15
2025
-
[68]
Android 15,
Google LLC, “Android 15, ” https://developer.android.google.cn/about/versions/15, 2024, accessed: 2025-11-05
2024
-
[69]
G. Yeap, S. S. Lin, Y. M. Chen, H. L. Shang, P. W. Wang, H. C. Lin, Y. C. Peng, J. Y. Sheu, M. Wang, X. Chen, B. R. Yang, C. P. Lin, F. C. Yang, Y. K. Leung, D. W. Lin, C. P. Chen, K. F. Yu, D. H. Chen, C. Y. Chang, H. K. Chen, P. Hung, C. S. Hou, Y. K. Cheng, J. Chang, L. Yuan, C. K. Lin, C. C. Chen, Y. C. Yeo, M. H. Tsai, H. T. Lin, C. O. Chui, K. B. Hu...
2019
-
[70]
Auto-tuning a high-level language targeted to GPU codes,
S. Grauer-Gray, L. Xu, R. Searles, S. Ayalasomayajula, and J. Cavazos, “Auto-tuning a high-level language targeted to GPU codes, ” in2012 Innovative Parallel Computing (InPar), May 2012, pp. 1–10
2012
-
[71]
SPEC CPU2017,
Standard Performance Evaluation Corporation (SPEC), “SPEC CPU2017, ” https: //www.spec.org/cpu2017/, 2017, accessed: 2025-11-15
2017
-
[72]
BigScience Language Open-science Open-access Multilingual (BLOOM) Language Model,
BigScience, “BigScience Language Open-science Open-access Multilingual (BLOOM) Language Model, ” https://huggingface.co/bigscience/bloom-1b1, 2022, accessed: 2025-11-05
2022
-
[73]
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, C. Zhou, C. Li, C. Li, D. Liu, F. Huang, G. Dong, H. Wei, H. Lin, J. Tang, J. Wang, J. Yang, J. Tu, J. Zhang, J. Ma, J. Yang, J. Xu, J. Zhou, J. Bai, J. He, J. Lin, K. Dang, K. Lu, K. Chen, K. Yang, M. Li, M. Xue, N. Ni, P. Zhang, P. Wang, R. Peng, R. Men, R. Gao, R. Lin, S. Wang, S. Bai, S. Tan, T. Zhu, T. Li, T...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
FALA: Locality-Aware PIM- Host Cooperation for Graph Processing with Fine-Grained Column Access,
C. Shin, J. Song, S. Na, J. Sung, H. Jang, and J. Lee, “FALA: Locality-Aware PIM- Host Cooperation for Graph Processing with Fine-Grained Column Access, ” in Proceedings of the 58th IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’25, 2025, p. 15201534
2025
-
[75]
Ambit: In-Memory Accelerator for Bulk Bitwise Operations Using Commodity DRAM Technology,
V. Seshadri, D. Lee, T. Mullins, H. Hassan, A. Boroumand, J. Kim, M. A. Kozuch, O. Mutlu, P. B. Gibbons, and T. C. Mowry, “Ambit: In-Memory Accelerator for Bulk Bitwise Operations Using Commodity DRAM Technology, ” in2017 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Oct 2017, pp. 273–287
2017
-
[76]
SIMDRAM: a framework for bit- serial SIMD processing using DRAM,
N. Hajinazar, G. F. Oliveira, S. Gregorio, J. a. D. Ferreira, N. M. Ghiasi, M. Patel, M. Alser, S. Ghose, J. Gómez-Luna, and O. Mutlu, “SIMDRAM: a framework for bit- serial SIMD processing using DRAM, ” inProceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS ’21, 2021, pp...
2021
-
[77]
MIMDRAM: An End-to-End Processing-Using-DRAM System for High-Throughput, Energy-Efficient and Programmer-Transparent Multiple- Instruction Multiple-Data Computing,
G. F. Oliveira, A. Olgun, A. G. Yağlıkçı, F. N. Bostancı, J. Gómez-Luna, S. Ghose, and O. Mutlu, “MIMDRAM: An End-to-End Processing-Using-DRAM System for High-Throughput, Energy-Efficient and Programmer-Transparent Multiple- Instruction Multiple-Data Computing, ” in2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA), March 2...
2024
-
[78]
Pro- teus: Achieving High-Performance Processing-Using-DRAM with Dynamic Bit- Precision, Adaptive Data Representation, and Flexible Arithmetic,
G. F. de Oliveira Junior, M. Kabra, Y. Guo, K. Chen, A. G. Yaglikci, M. Soysal, M. Sadrosadati, J. Olivares Bueno, S. Ghose, J. Gómez-Luna, and O. Mutlu, “Pro- teus: Achieving High-Performance Processing-Using-DRAM with Dynamic Bit- Precision, Adaptive Data Representation, and Flexible Arithmetic, ” inProceedings of the 39th ACM International Conference o...
2025
-
[79]
DRISA: A DRAM-based Reconfigurable In-Situ Accelerator,
S. Li, D. Niu, K. T. Malladi, H. Zheng, B. Brennan, and Y. Xie, “DRISA: A DRAM-based Reconfigurable In-Situ Accelerator, ” in2017 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Oct 2017, pp. 288–301
2017
-
[80]
Compute Caches,
S. Aga, S. Jeloka, A. Subramaniyan, S. Narayanasamy, D. Blaauw, and R. Das, “Compute Caches, ” in2017 IEEE International Symposium on High Performance Computer Architecture (HPCA), Feb 2017, pp. 481–492
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.