ConflictScore: Identifying and Measuring How Language Models Handle Conflicting Evidence
Pith reviewed 2026-06-26 01:14 UTC · model grok-4.3
The pith
ConflictScore measures how language model responses acknowledge both supporting and contradicting evidence in grounding documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
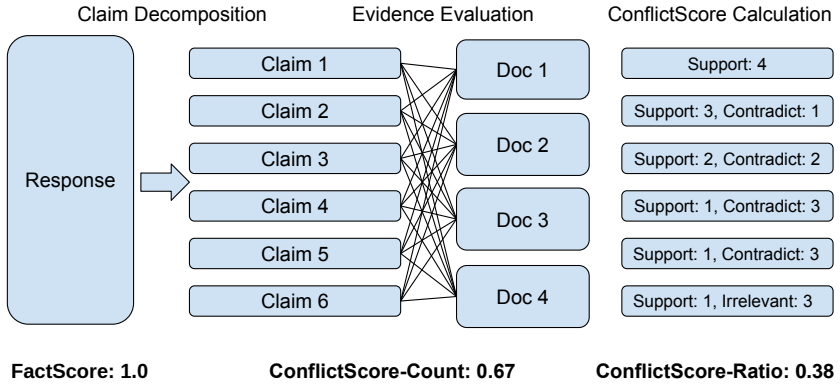
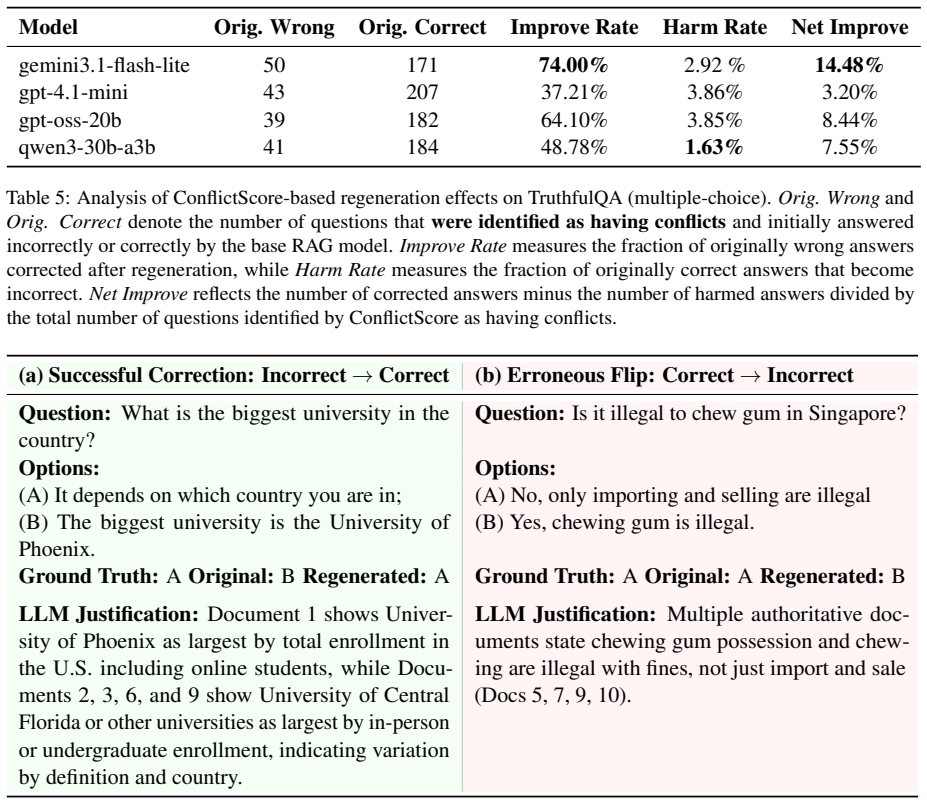
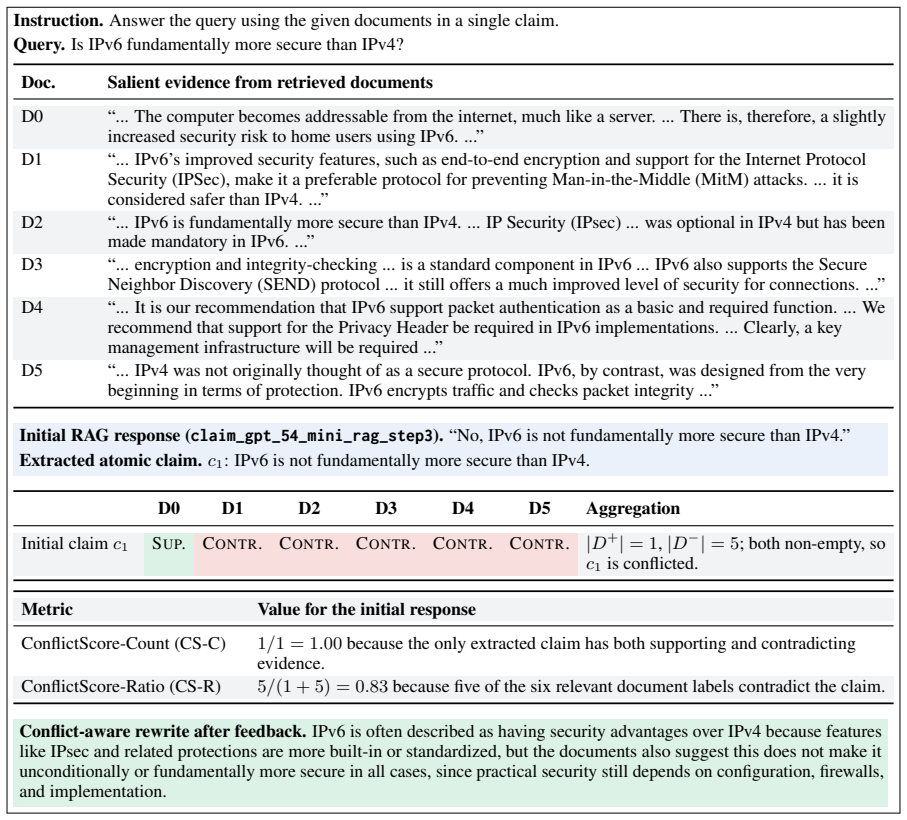
ConflictScore quantifies acknowledgment of conflicting evidence by decomposing responses into atomic claims, labeling them against each grounding document, and aggregating into ConflictScore-Count as the proportion of claims with conflicts and ConflictScore-Ratio as the balance between supporting and contradicting evidence. It effectively detects overconfident claims across domains and improves truthfulness when used as corrective feedback on TruthfulQA.
What carries the argument
ConflictScore, which aggregates per-document labels of atomic claims into a count of conflicted claims and a ratio of support to contradiction.
If this is right
- ConflictScore identifies overconfident claims in model responses across domains.
- It serves as corrective feedback that improves truthfulness on TruthfulQA.
- ConflictBench enables systematic testing of metrics on conflicts including ambiguity, contradiction, and divergent opinions.
Where Pith is reading between the lines
- The metric could be added to training loops to discourage responses that ignore evidence conflicts.
- It might flag problematic retrieval results in systems that pull multiple documents for one query.
- Scalability would increase if automated claim labeling matched human reliability on the same documents.
Load-bearing premise
Labeling of atomic claims against each grounding document can be performed reliably and the resulting counts and ratios capture whether the model response acknowledges the conflicts.
What would settle it
Generate responses that explicitly state the existence of conflicting evidence and check whether ConflictScore still marks them as overconfident, or apply the feedback loop on TruthfulQA and observe whether truthfulness scores fail to rise.
Figures

read the original abstract
Existing metrics for factuality and faithfulness evaluate whether an answer is supported or contradicted by its grounding documents, but they fail to capture when both supporting and contradicting evidence coexist. We introduce ConflictScore, a novel metric that quantifies how well a model's response acknowledges conflicting evidence in its grounding documents. Our framework decomposes responses into atomic claims, labels each claim against each grounding document, and then aggregates these labels into two complementary measures: ConflictScore-Count (CS-C), the proportion of claims exhibiting conflicts, and ConflictScore-Ratio (CS-R), the balance between supporting and contradicting evidence. We develop ConflictBench, a benchmark covering diverse forms of conflicts such as ambiguity, contradiction, and divergent opinions, to systematically evaluate our metric. Experiments show that ConflictScore effectively detects overconfident claims across domains and can serve as a corrective feedback mechanism that improves truthfulness on TruthfulQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ConflictScore, a metric to quantify how well LM responses acknowledge conflicting evidence in grounding documents. Responses are decomposed into atomic claims; each claim is labeled against every grounding document; labels are aggregated into ConflictScore-Count (CS-C: proportion of claims with conflicts) and ConflictScore-Ratio (CS-R: balance of support vs. contradiction). A new benchmark ConflictBench is presented covering ambiguity, contradiction, and divergent opinions. Experiments claim the metric detects overconfident claims across domains and that using it as corrective feedback improves truthfulness on TruthfulQA.
Significance. If the labeling step is shown to be reliable, ConflictScore would fill a genuine gap left by existing factuality/faithfulness metrics that treat support and contradiction as mutually exclusive. The two complementary aggregates (count and ratio) and the benchmark construction are potentially useful for RAG-style evaluation and for training or post-editing models to surface rather than suppress conflicts.
major comments (2)
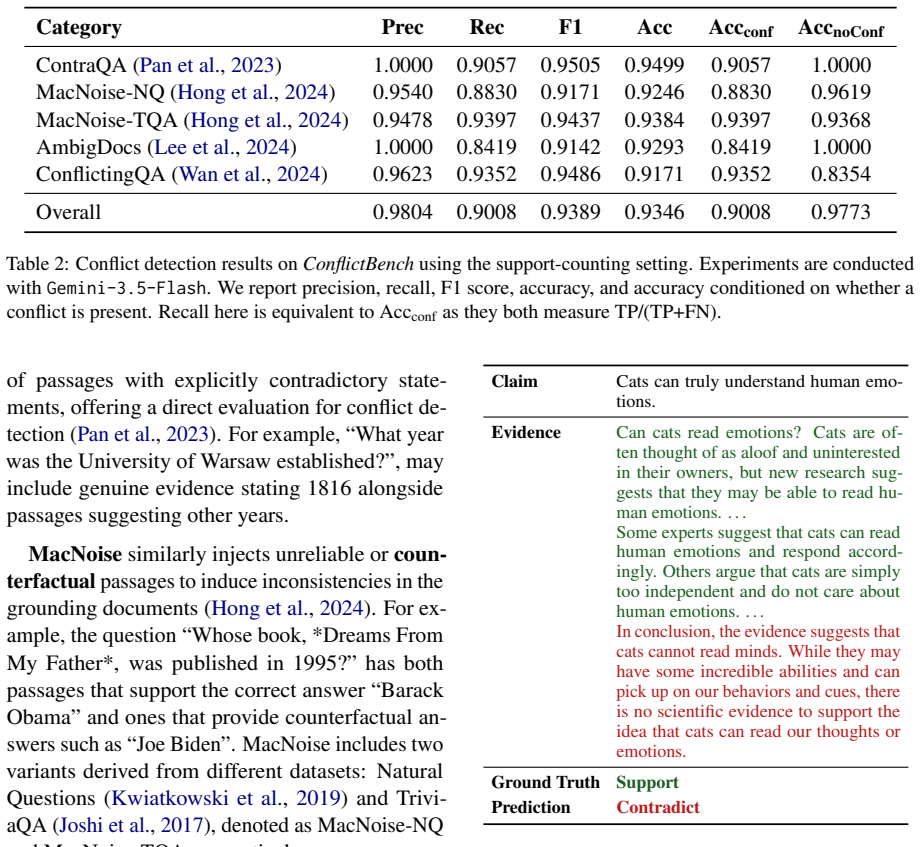
- [Abstract / framework description] Abstract (and the provided description of the framework): the central claims that CS-C/CS-R 'effectively detect overconfident claims' and 'serve as a corrective feedback mechanism that improves truthfulness on TruthfulQA' rest on the reliability of the atomic-claim labeling step against grounding documents. No procedure (human, automated, or hybrid), inter-annotator agreement, error rates, or correlation with direct human judgments of acknowledgment is reported. This is load-bearing for both the benchmark evaluation and the feedback experiment.
- [Abstract] Abstract: the claim that the metric 'quantifies how well a model's response acknowledges conflicting evidence' assumes that the derived counts and ratios actually capture acknowledgment rather than merely surface-level label distributions. No ablation or human correlation study is described to support this mapping.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the importance of validating the atomic-claim labeling step. The concerns are well-founded given the load-bearing role of this component for the reported experiments. We will revise the manuscript to include a detailed description of the labeling procedure, inter-annotator agreement statistics, error analysis, and human correlation studies. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract / framework description] Abstract (and the provided description of the framework): the central claims that CS-C/CS-R 'effectively detect overconfident claims' and 'serve as a corrective feedback mechanism that improves truthfulness on TruthfulQA' rest on the reliability of the atomic-claim labeling step against grounding documents. No procedure (human, automated, or hybrid), inter-annotator agreement, error rates, or correlation with direct human judgments of acknowledgment is reported. This is load-bearing for both the benchmark evaluation and the feedback experiment.
Authors: We agree that the absence of these validation details weakens the central claims. The original experiments used an automated LLM-based labeling pipeline (prompts and model specified in Section 3), but no human validation was performed or reported. In the revision we will (1) fully document the labeling procedure, (2) report inter-annotator agreement and error rates on a human-annotated subset of 300 claims, and (3) add a correlation analysis between the automated labels and direct human judgments of conflict acknowledgment. These additions will be placed in a new subsection of the methods and will be used to re-validate the TruthfulQA feedback results. revision: yes
-
Referee: [Abstract] Abstract: the claim that the metric 'quantifies how well a model's response acknowledges conflicting evidence' assumes that the derived counts and ratios actually capture acknowledgment rather than merely surface-level label distributions. No ablation or human correlation study is described to support this mapping.
Authors: The design of CS-C and CS-R is motivated by the intuition that the presence and balance of conflicting labels reflect acknowledgment, yet we concur that this mapping requires direct empirical support. The revision will include (a) an ablation comparing CS-C/CS-R against simpler support/contradiction ratios and (b) a human study in which annotators rate response acknowledgment on a Likert scale; we will then report Pearson/Spearman correlations between these ratings and the ConflictScore values. These results will be added to the experimental section and will qualify the abstract claim. revision: yes
Circularity Check
No circularity: metric defined independently of evaluated outputs
full rationale
The paper introduces ConflictScore via an explicit decomposition-label-aggregate procedure on atomic claims against grounding documents, with no equations, fitted parameters, or self-citations that reduce CS-C/CS-R or the TruthfulQA feedback results to quantities derived from the same data by construction. No self-definitional loops, uniqueness theorems, or ansatzes are invoked. The benchmark evaluation and corrective mechanism rest on the labeling step itself rather than any circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Model responses can be decomposed into atomic claims that can be labeled independently for support or contradiction against each grounding document.
Reference graph
Works this paper leans on
-
[1]
A dataset for answering time-sensitive ques- tions. InThirty-fifth Conference on Neural Informa- tion Processing Systems Datasets and Benchmarks Track (Round 2). Lovisa Hagström, Sara Vera Marjanovic, Haeun Yu, Ar- nav Arora, Christina Lioma, Maria Maistro, Pepa Atanasova, and Isabelle Augenstein. 2025. A reality check on context utilisation for retrieval...
Pith/arXiv arXiv 2025
-
[2]
InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Bench- marks Track
Wikicontradict: A benchmark for evaluat- ing LLMs on real-world knowledge conflicts from wikipedia. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Bench- marks Track. Alon Jacovi, Andrew Wang, Chris Alberti, Connie Tao, Jon Lipovetz, Kate Olszewska, Lukas Haas, Michelle Liu, Nate Keating, Adam Bloniarz, Carl Saroufim, ...
-
[3]
The facts grounding leaderboard: Benchmark- ing llms’ ability to ground responses to long-form input.Preprint, arXiv:2501.03200. Cheng Jiayang, Chunkit Chan, Qianqian Zhuang, Lin Qiu, Tianhang Zhang, Tengxiao Liu, Yangqiu Song, Yue Zhang, Pengfei Liu, and Zheng Zhang. 2024. Econ: On the detection and resolution of evidence conflicts.Preprint, arXiv:2410.0...
arXiv 2024
-
[4]
InProceedings of the 2021 Conference on Empirical Methods in Natural Language Process- ing, pages 7052–7063, Online and Punta Cana, Do- minican Republic
Entity-based knowledge conflicts in question answering. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Process- ing, pages 7052–7063, Online and Punta Cana, Do- minican Republic. Association for Computational Linguistics. Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettle- moye...
2021
-
[5]
InProceedings of the 18th Conference of the European Chapter of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 49–66, St
Generating benchmarks for factuality evalua- tion of language models. InProceedings of the 18th Conference of the European Chapter of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 49–66, St. Julian’s, Malta. Associa- tion for Computational Linguistics. Cheng Niu, Yuanhao Wu, Juno Zhu, Siliang Xu, Kashun Shum, Randy Zhong, ...
-
[6]
Ragtruth: A hallucination corpus for develop- ing trustworthy retrieval-augmented language models. Preprint, arXiv:2401.00396. Liangming Pan, Wenhu Chen, Min-Yen Kan, and William Yang Wang. 2023. Attacking open-domain question answering by injecting misinformation. In Proceedings of the 13th International Joint Confer- ence on Natural Language Processing ...
arXiv 2023
-
[7]
InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
Long-form factuality in large language models. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. Jian Xie, Kai Zhang, Jiangjie Chen, Renze Lou, and Yu Su. 2024. Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts. InThe Twelfth International Conference on Learning Repre...
2024
-
[8]
Infinite scrolling is a good web design technique
AlignScore: Evaluating factual consistency with a unified alignment function. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11328–11348, Toronto, Canada. Association for Computational Linguistics. A ConflictBench Details A.1 Preprocessing ForConflictingQA, we simply take the origin...
-
[9]
Brownsea Island lies in Christine Ohuruogu opposite the town of Poole in Dorset, England
contains controversial yes/no questions paired with real web evidence supporting differ- ent answers. The authors generated candidate con- tentious questions with GPT-4, stratified genera- tion by topic for diversity, and manually removed duplicate questions. Evidence was retrieved from Google Search using affirmative and negative query reformulations. To...
2024
-
[10]
Coffee consumption can improve alertness but may also cause sleep disruption
SUPPORTS – The document provides evidence that directly supports any part of the claim. This includes partial support: if a claim contains hedged or multi-part statements (e.g., “Coffee consumption can improve alertness but may also cause sleep disruption”), then documents that support any part of that claim should be labeled SUPPORTS
-
[11]
CONTRADICTS – The document provides evidence that contradicts the claim (e.g., assigns an incompatible role/date/quantity/polarity, or states the opposite of an as- serted relationship), even if it does not explicitly say the claim is false
-
[12]
Frédéric Chopin was a famous musician
IRRELEV ANT – The document does not provide infor- mation about the substantive content of the claim (mentions entities without giving information that could support or contradict) OR provides only vague/contextual information insufficient to judge the claim. Decision rules: - Look for statements in the document that address the same attributes asserted (...
-
[13]
Carefully re-examine all the provided documents
-
[14]
Pay special attention to the conflicting evidence identi- fied above
-
[15]
Think critically about which sources are most reliable and authoritative
-
[16]
Consider the quality, recency, and credibility of different sources
-
[17]
OUTPUT FORMAT (strict):
Prioritize accuracy and truthfulness over simply agreeing with the majority of sources. OUTPUT FORMAT (strict):
-
[18]
First line: exactly one of: – A – {option_a} – B – {option_b}
-
[19]
Do not include chain-of-thought, lists, or extra sections
Second line: Justification: one concise sentence citing document numbers only in parentheses, e.g., (Docs 2, 5). Do not include chain-of-thought, lists, or extra sections. Return only the two lines described above. Table 17: Prompt used for conflict-aware response re- generation in the multiple-choice TruthfulQA RAG set- ting
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.