SENSE-VAD: Sentient and Semantic Video Anomaly Detection for Autonomous Driving
Pith reviewed 2026-07-01 05:47 UTC · model grok-4.3
The pith
Socially complex anomalies in autonomous driving videos form a distinct challenge that current detection methods cannot solve.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SENSE-VAD generates synthetic videos in which anomalies such as a child running from a guardian or a pursuer chasing a pedestrian produce no obvious motion signal yet are anomalous purely due to relational social context, with scenarios separated into individual behaviors, group behaviors, person-object interactions, cyclist interactions, and vehicle-agent categories, each carrying per-frame binary labels, plus real-world normal and anomalous videos as a transfer probe; evaluations confirm that state-of-the-art video anomaly detection methods fail on these cases.
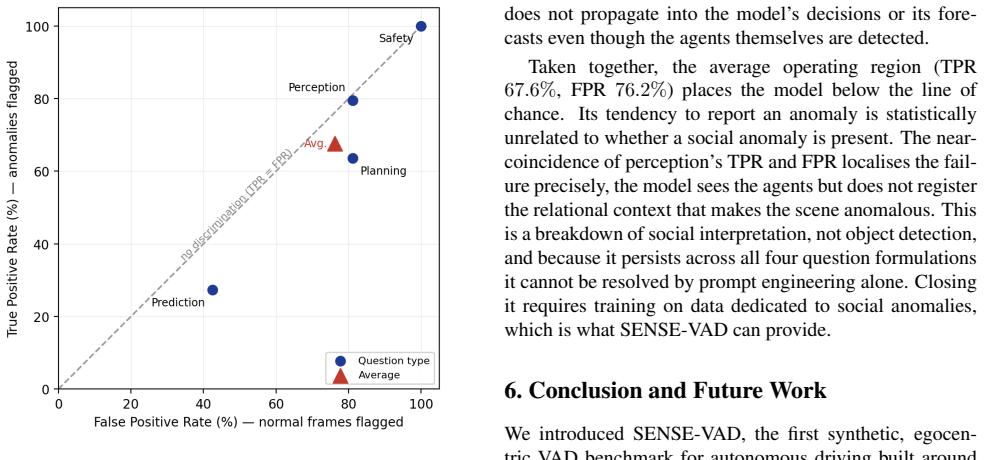
What carries the argument
The SENSE-VAD benchmark, built to enforce separation between social anomaly and motion-based or appearance-based anomaly by generating scenarios where object motion appears unremarkable in isolation.
If this is right
- Existing video anomaly detectors remain ineffective on anomalies defined by social relationships.
- Autonomous driving systems need detection approaches that incorporate relational context between agents.
- Synthetic generation in CARLA and Unreal Engine can produce controlled tests that isolate social anomalies from physical signals.
- Per-frame annotations allow precise measurement of when detectors first flag relational anomalies.
- Real-world videos included in the benchmark enable direct assessment of sim-to-real transfer performance.
Where Pith is reading between the lines
- Detectors that model agent relationships explicitly could close the gap shown on this benchmark.
- The separation principle used here could apply to other safety domains where context defines risk.
- Extending the benchmark with more varied real-world social scenarios would strengthen transfer testing.
- Methods relying on semantic scene graphs might naturally address the relational anomalies highlighted.
Load-bearing premise
The danger in the generated scenarios stems purely from relational social context rather than any detectable motion or appearance deviation that standard detectors could already exploit.
What would settle it
A standard motion-and-appearance video anomaly detector that achieves high accuracy on the SENSE-VAD social anomaly scenarios without any modeling of inter-agent relationships.
Figures


read the original abstract
Autonomous vehicles (AVs) must navigate not only motion-based hazards but also socially complex situations whose danger is constituted by inter-agent relationships rather than movement statistics alone. A child running away from a guardian, a person being carried by another, or a pursuer chasing a pedestrian across a sidewalk are all anomalous in social context, yet none produces an obvious motion signal that current anomaly detectors are equipped to flag. We introduce SENSE-VAD, the first synthetic video anomaly detection benchmark for autonomous driving explicitly designed around socially complex anomalies. Using the CARLA simulator and Unreal Engine (UE), we generate distinct anomaly scenarios across multiple categories: individual behaviors, group behaviors, person--object interactions, cyclist interactions, vehicle & agent, each annotated with per-frame binary labels. A key design principle is the separation of social anomaly from motion-based or appearance-based anomaly: many scenarios involve motion of objects that appears unremarkable in isolation but is anomalous in relational context. We additionally provide real-world normal and anomalous videos as a sim-to-real transfer probe. We evaluate state-of-the-art video anomaly detection baselines and demonstrate that socially complex anomalies constitute a distinct and currently unsolved challenge. Our dataset, annotations, and generation code are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SENSE-VAD, the first synthetic VAD benchmark for autonomous driving centered on socially complex anomalies generated in CARLA and Unreal Engine. Scenarios span categories including individual behaviors, group behaviors, person-object interactions, cyclist interactions, and vehicle-agent interactions, each with per-frame binary anomaly labels. A core design principle is that many anomalies arise purely from inter-agent relational context rather than detectable motion or appearance deviations. The work also supplies real-world normal/anomalous videos for sim-to-real evaluation and reports that state-of-the-art VAD baselines fail on these cases, positioning socially complex anomalies as a distinct, currently unsolved challenge. Dataset, annotations, and generation code are released publicly.
Significance. If the isolation of social anomalies from motion/appearance cues is verified, the benchmark would meaningfully extend VAD research beyond reconstruction-, prediction-, and flow-based methods toward relational reasoning required for AV safety. The explicit public release of dataset, annotations, and generation code is a concrete strength that supports reproducibility and follow-on work.
major comments (2)
- [§4] §4 (Dataset Design): The central claim that 'motion of objects that appears unremarkable in isolation' is load-bearing for the distinct-challenge argument, yet no quantitative check (motion-statistic distributions, optical-flow histograms, or per-category error breakdowns on motion-only inputs) is supplied to confirm that residual trajectory or appearance cues are absent.
- [§5] §5 (Evaluation): The assertion that baselines 'fail' and that social anomalies are 'unsolved' requires per-baseline, per-category metrics plus an ablation isolating relational context; without these, it remains unclear whether observed failures stem from social structure or from unaccounted low-level cues still present in the generated clips.
minor comments (1)
- [§6] The sim-to-real probe is mentioned but lacks detail on how real-world clips were selected or labeled relative to the synthetic taxonomy.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of SENSE-VAD's design principles and evaluation. We respond to each major comment below and will incorporate the suggested analyses in the revised manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Dataset Design): The central claim that 'motion of objects that appears unremarkable in isolation' is load-bearing for the distinct-challenge argument, yet no quantitative check (motion-statistic distributions, optical-flow histograms, or per-category error breakdowns on motion-only inputs) is supplied to confirm that residual trajectory or appearance cues are absent.
Authors: We agree that explicit quantitative verification would strengthen the claim. In the revised manuscript we will add motion-statistic distributions, optical-flow histograms across anomaly categories, and error breakdowns obtained from motion-only or appearance-only baselines to Section 4, confirming that residual low-level cues are minimal by design. revision: yes
-
Referee: [§5] §5 (Evaluation): The assertion that baselines 'fail' and that social anomalies are 'unsolved' requires per-baseline, per-category metrics plus an ablation isolating relational context; without these, it remains unclear whether observed failures stem from social structure or from unaccounted low-level cues still present in the generated clips.
Authors: We acknowledge that the current evaluation would benefit from greater granularity. We will expand Section 5 to include per-baseline and per-category performance tables together with an ablation that compares full relational inputs against motion-only or appearance-only variants, thereby isolating the contribution of social context to the observed failures. revision: yes
Circularity Check
No circularity; dataset contribution and empirical evaluation are self-contained
full rationale
The paper presents a new synthetic benchmark (SENSE-VAD) generated in CARLA/UE for socially complex anomalies, supplies annotations, and reports that existing VAD baselines fail on it. No equations, parameter fitting, or predictive derivations appear in the provided text. The central claim—that these anomalies form a distinct unsolved challenge—is supported by the dataset design and baseline results rather than by any reduction to prior fitted quantities or self-citation chains. The design principle separating social context from motion/appearance cues is stated as an input assumption of the benchmark construction, not derived from the paper's own outputs. This matches the default expectation of no significant circularity for a dataset/empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CARLA simulator and Unreal Engine can generate video scenarios whose anomalies are defined solely by inter-agent social relationships rather than motion statistics or appearance.
Reference graph
Works this paper leans on
-
[1]
Collaborative learning of anomalies with privacy (clap) for unsupervised video anomaly detection: A new baseline
Anas Al-Lahham, Muhammad Zaigham Zaheer, Nurbek Tastan, and Karthik Nandakumar. Collaborative learning of anomalies with privacy (clap) for unsupervised video anomaly detection: A new baseline. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12416–12425, 2024. 2, 7
2024
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
The fishyscapes benchmark: Measuring blind spots in semantic segmentation.Inter- national Journal of Computer Vision, 129(11):3119–3135,
Hermann Blum, Paul-Edouard Sarlin, Juan Nieto, Roland Siegwart, and Cesar Cadena. The fishyscapes benchmark: Measuring blind spots in semantic segmentation.Inter- national Journal of Computer Vision, 129(11):3119–3135,
-
[4]
Anovox: A benchmark for multimodal anomaly detection in autonomous driving
Daniel Bogdoll, Iramm Hamdard, Lukas Namgyu R ¨oßler, Felix Geisler, Muhammed Bayram, Felix Wang, Jan Imhof, Miguel De Campos, Anushervon Tabarov, Yitian Yang, et al. Anovox: A benchmark for multimodal anomaly detection in autonomous driving. InEuropean Conference on Computer Vision, pages 206–223. Springer, 2024. 2, 3
2024
-
[5]
Anticipating accidents in dashcam videos
Fu-Hsiang Chan, Yu-Ting Chen, Yu Xiang, and Min Sun. Anticipating accidents in dashcam videos. InAsian confer- ence on computer vision, pages 136–153. Springer, 2016. 3
2016
-
[6]
Driving with llms: Fusing object-level vector modality for explainable autonomous driving, 2023
Long Chen, Oleg Sinavski, Jan H ¨unermann, Alice Karnsund, Andrew James Willmott, Danny Birch, Daniel Maund, and Jamie Shotton. Driving with llms: Fusing object-level vector modality for explainable autonomous driving, 2023. 3
2023
-
[7]
Mgfn: Magnitude- contrastive glance-and-focus network for weakly-supervised video anomaly detection
Yingxian Chen, Zhengzhe Liu, Baoheng Zhang, Wilton Fok, Xiaojuan Qi, and Yik-Chung Wu. Mgfn: Magnitude- contrastive glance-and-focus network for weakly-supervised video anomaly detection. InProceedings of the AAAI con- ference on artificial intelligence, pages 387–395, 2023. 2
2023
-
[8]
Asynchronous large language model en- hanced planner for autonomous driving, 2024
Yuan Chen, Zi han Ding, Ziqin Wang, Yan Wang, Lijun Zhang, and Si Liu. Asynchronous large language model en- hanced planner for autonomous driving, 2024. 3
2024
-
[9]
Carla: An open urban driv- ing simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Anto- nio Lopez, and Vladlen Koltun. Carla: An open urban driv- ing simulator. InConference on robot learning, pages 1–16. PMLR, 2017. 2, 3
2017
-
[10]
Dada: Driver attention prediction in driving accident scenarios.IEEE transactions on intelligent trans- portation systems, 23(6):4959–4971, 2021
Jianwu Fang, Dingxin Yan, Jiahuan Qiao, Jianru Xue, and Hongkai Yu. Dada: Driver attention prediction in driving accident scenarios.IEEE transactions on intelligent trans- portation systems, 23(6):4959–4971, 2021. 1, 3
2021
-
[11]
Anomaly detection in video via self- supervised and multi-task learning
Mariana-Iuliana Georgescu, Antonio Barbalau, Radu Tu- dor Ionescu, Fahad Shahbaz Khan, Marius Popescu, and Mubarak Shah. Anomaly detection in video via self- supervised and multi-task learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12742–12752, 2021. 2
2021
-
[12]
Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection
Dong Gong, Lingqiao Liu, Vuong Le, Budhaditya Saha, Moussa Reda Mansour, Svetha Venkatesh, and Anton van den Hengel. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1705–1714,
-
[13]
Sdac: a multimodal synthetic dataset for anomaly and corner case detection in autonomous driving
Lei Gong, Yu Zhang, Yingqing Xia, Yanyong Zhang, and Jianmin Ji. Sdac: a multimodal synthetic dataset for anomaly and corner case detection in autonomous driving. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 1914–1922, 2024. 3
1914
-
[14]
Veo: Our most capable video generation model.https : / / deepmind
Google DeepMind. Veo: Our most capable video generation model.https : / / deepmind . google / technologies/veo/, 2025. Accessed: 2026-06-25. 4
2025
-
[15]
Can vehicle motion planning generalize to realistic long-tail scenarios? In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5388–5395
Marcel Hallgarten, Julian Zapata, Martin Stoll, Katrin Renz, and Andreas Zell. Can vehicle motion planning generalize to realistic long-tail scenarios? In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5388–5395. IEEE, 2024. 3, 7
2024
-
[16]
Learning temporal reg- ularity in video sequences
Mahmudul Hasan, Jonghyun Choi, Jan Neumann, Amit K Roy-Chowdhury, and Larry S Davis. Learning temporal reg- ularity in video sequences. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 733–742, 2016. 2
2016
-
[17]
Henriques, and Anthony Hu
Shu Ishida, Gianluca Corrado, George Fedoseev, Hudson Yeo, Lloyd Russell, Jamie Shotton, Jo ˜ao F. Henriques, and Anthony Hu. Langprop: A code optimization framework us- ing large language models applied to driving, 2024. 3
2024
-
[18]
Real-time weakly supervised video anomaly detection
Hamza Karim, Keval Doshi, and Yasin Yilmaz. Real-time weakly supervised video anomaly detection. InProceedings of the IEEE/CVF winter conference on applications of com- puter vision, pages 6848–6856, 2024. 2, 7
2024
-
[19]
Crash to not crash: Learn to identify dangerous vehicles using a simulator
Hoon Kim, Kangwook Lee, Gyeongjo Hwang, and Changho Suh. Crash to not crash: Learn to identify dangerous vehicles using a simulator. InProceedings of the AAAI Conference on Artificial Intelligence, pages 978–985, 2019. 3
2019
-
[20]
Coda: A real-world road corner case dataset for object detection in autonomous driving
Kaican Li, Kai Chen, Haoyu Wang, Lanqing Hong, Chao- qiang Ye, Jianhua Han, Yukuai Chen, Wei Zhang, Chunjing Xu, Dit-Yan Yeung, et al. Coda: A real-world road corner case dataset for object detection in autonomous driving. In European Conference on Computer Vision, pages 406–423. Springer, 2022. 3
2022
-
[21]
Anomaly detection and localization in crowded scenes.IEEE transactions on pattern analysis and machine intelligence, 36(1):18–32, 2013
Weixin Li, Vijay Mahadevan, and Nuno Vasconcelos. Anomaly detection and localization in crowded scenes.IEEE transactions on pattern analysis and machine intelligence, 36(1):18–32, 2013. 2
2013
-
[22]
Vadtree: Explainable training-free video anomaly detection via hierarchical granularity-aware tree
Wenlong Li, Yifei Xu, Yuan Rao, Zhenhua Wang, and Shuiguang Deng. Vadtree: Explainable training-free video anomaly detection via hierarchical granularity-aware tree. Advances in Neural Information Processing Systems, 38: 148372–148404, 2026. 2, 7
2026
-
[23]
Fu- ture frame prediction for anomaly detection–a new baseline
Wen Liu, Weixin Luo, Dongze Lian, and Shenghua Gao. Fu- ture frame prediction for anomaly detection–a new baseline. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6536–6545, 2018. 2, 6, 7
2018
-
[24]
W. Liu, D. Lian W. Luo, and S. Gao. Future frame pre- diction for anomaly detection – a new baseline. In2018 IEEE Conference on Computer Vision and Pattern Recog- nition (CVPR), 2018. 2
2018
-
[25]
Yueting Liu, Hanshi Wang, Zhengjun Zha, Weiming Hu, and Jin Gao. Pfsd: A multi-modal pedestrian-focus scene 9 dataset for rich tasks in semi-structured environments.arXiv preprint arXiv:2502.15342, 2025. 1
-
[26]
Abnormal event detec- tion at 150 fps in matlab
Cewu Lu, Jianping Shi, and Jiaya Jia. Abnormal event detec- tion at 150 fps in matlab. InProceedings of the IEEE inter- national conference on computer vision, pages 2720–2727,
-
[27]
Drama: Joint risk localization and captioning in driving
Srikanth Malla, Chiho Choi, Isht Dwivedi, Joon Hee Choi, and Jiachen Li. Drama: Joint risk localization and captioning in driving. InProceedings of the IEEE/CVF winter confer- ence on applications of computer vision, pages 1043–1052,
-
[28]
Graph enhanced trajectory anomaly detection
Jonathan Mbuya, Dieter Pfoser, and Antonios Anastasopou- los. Graph enhanced trajectory anomaly detection. InPro- ceedings of the 33rd ACM International Conference on Ad- vances in Geographic Information Systems, pages 411–422,
-
[29]
Complexvad: Detecting interaction anomalies in video
Furkan Mumcu, Michael Jones, Yasin Yilmaz, and Anoop Cherian. Complexvad: Detecting interaction anomalies in video. InProceedings of the Winter Conference on Applica- tions of Computer Vision, pages 1093–1102, 2025. 2, 3
2025
-
[30]
Furkan Mumcu, Michael J Jones, Anoop Cherian, and Yasin Yilmaz. Leveraging multimodal llm descriptions of activ- ity for explainable semi-supervised video anomaly detection. arXiv preprint arXiv:2510.14896, 2025. 2
-
[31]
Reason2drive: Towards interpretable and chain-based reasoning for au- tonomous driving, 2024
Ming Nie, Renyuan Peng, Chunwei Wang, Xinyue Cai, Jianhua Han, Hang Xu, and Li Zhang. Reason2drive: Towards interpretable and chain-based reasoning for au- tonomous driving, 2024. 3
2024
-
[32]
Cosmos World Foundation Model Platform for Physical AI
N Agarwal NVIDIA, Arslan Ali, Maciej Bala, Yogesh Bal- aji, Erik Barker, Tiffany Cai, Prithvij // i jit Chattopadhyay, Yongxin Chen, Yin Cui, Y Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, pages 2501–03575, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Video generation models as world simulators (Sora).https://openai.com/research/video- generation - models - as - world - simulators,
OpenAI. Video generation models as world simulators (Sora).https://openai.com/research/video- generation - models - as - world - simulators,
-
[34]
Accessed: 2026-06-25. 4
2026
-
[35]
Lost and found: detecting small road hazards for self-driving vehi- cles
Peter Pinggera, Sebastian Ramos, Stefan Gehrig, Uwe Franke, Carsten Rother, and Rudolf Mester. Lost and found: detecting small road hazards for self-driving vehi- cles. In2016 IEEE/RSJ International Conference on Intel- ligent Robots and Systems (IROS), pages 1099–1106. IEEE,
-
[36]
Street scene: A new dataset and evaluation protocol for video anomaly detection
Bharathkumar Ramachandra and Michael Jones. Street scene: A new dataset and evaluation protocol for video anomaly detection. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2569– 2578, 2020. 2
2020
-
[37]
Waymo recalls over 3,800 robotaxis over risk of entering closed construction zones.https://www
Reuters. Waymo recalls over 3,800 robotaxis over risk of entering closed construction zones.https://www. reuters . com / legal / litigation / waymo - recall - over - 3800 - robotaxis - over - risk - entering - closed - construction - zones - 2026-06-18/, 2026. Accessed: 2026-06-25. 1
2026
-
[38]
Multi-timescale trajectory predic- tion for abnormal human activity detection
Royston Rodrigues, Neha Bhargava, Rajbabu Velmurugan, and Subhasis Chaudhuri. Multi-timescale trajectory predic- tion for abnormal human activity detection. InProceedings of the IEEE/CVF winter conference on applications of com- puter vision, pages 2626–2634, 2020. 2
2020
-
[39]
Cadp: A novel dataset for cctv traffic camera based accident analysis
Ankit Parag Shah, Jean-Bapstite Lamare, Tuan Nguyen-Anh, and Alexander Hauptmann. Cadp: A novel dataset for cctv traffic camera based accident analysis. In2018 15th IEEE In- ternational Conference on Advanced Video and Signal Based Surveillance (AVSS), pages 1–9. IEEE, 2018. 1, 3
2018
-
[40]
Eventvad: Training-free event-aware video anomaly detection
Yihua Shao, Haojin He, Sijie Li, Siyu Chen, Xinwei Long, Fanhu Zeng, Yuxuan Fan, Muyang Zhang, Ziyang Yan, Ao Ma, et al. Eventvad: Training-free event-aware video anomaly detection. InProceedings of the 33rd ACM Interna- tional Conference on Multimedia, pages 2586–2595, 2025. 7
2025
-
[41]
Learning anomalies with normality prior for unsuper- vised video anomaly detection
Haoyue Shi, Le Wang, Sanping Zhou, Gang Hua, and Wei Tang. Learning anomalies with normality prior for unsuper- vised video anomaly detection. InEuropean Conference on Computer Vision, pages 163–180. Springer, 2024. 2, 7
2024
-
[42]
Drivelm: Driving with graph visual question answering, 2025
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering, 2025. 3, 7
2025
-
[43]
Anoma- lous motion detection on highway using deep learning
Harpreet Singh, Emily M Hand, and Kostas Alexis. Anoma- lous motion detection on highway using deep learning. In 2020 IEEE international conference on image processing (ICIP), pages 1901–1905. IEEE, 2020. 3
2020
-
[44]
Real-world anomaly detection in surveillance videos
Waqas Sultani, Chen Chen, and Mubarak Shah. Real-world anomaly detection in surveillance videos. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 6479–6488, 2018. 2
2018
-
[45]
Haowei Sun, Xintao Yan, Zhijie Qiao, Haojie Zhu, Yi- hao Sun, Jiawei Wang, Shengyin Shen, Darian Hogue, Ra- janikant Ananta, Derek Johnson, et al. Terasim: Uncover- ing unknown unsafe events for autonomous vehicles through generative simulation.arXiv preprint arXiv:2503.03629,
-
[46]
Al- varez
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M. Al- varez. Omnidrive: A holistic vision-language dataset for au- tonomous driving with counterfactual reasoning, 2025. 3
2025
-
[47]
Deepaccident: A motion and accident prediction bench- mark for v2x autonomous driving
Tianqi Wang, Sukmin Kim, Ji Wenxuan, Enze Xie, Chongjian Ge, Junsong Chen, Zhenguo Li, and Ping Luo. Deepaccident: A motion and accident prediction bench- mark for v2x autonomous driving. InProceedings of the AAAI Conference on Artificial Intelligence, pages 5599– 5606, 2024. 3
2024
-
[48]
Not only look, but also listen: Learning multimodal violence detection under weak supervision
Peng Wu, Jing Liu, Yujia Shi, Yujia Sun, Fangtao Shao, Zhaoyang Wu, and Zhiwei Yang. Not only look, but also listen: Learning multimodal violence detection under weak supervision. InEuropean conference on computer vision, pages 322–339. Springer, 2020. 2
2020
-
[49]
Vadclip: Adapting vision-language models for weakly supervised video anomaly detection
Peng Wu, Xuerong Zhou, Guansong Pang, Lingru Zhou, Qingsen Yan, Peng Wang, and Yanning Zhang. Vadclip: Adapting vision-language models for weakly supervised video anomaly detection. InProceedings of the AAAI con- ference on artificial intelligence, pages 6074–6082, 2024. 2, 7
2024
-
[50]
Are vlms ready for autonomous driving? an empiri- cal study from the reliability, data, and metric perspectives,
Shaoyuan Xie, Lingdong Kong, Yuhao Dong, Chonghao Sima, Wenwei Zhang, Qi Alfred Chen, Ziwei Liu, and Liang 10 Pan. Are vlms ready for autonomous driving? an empiri- cal study from the reliability, data, and metric perspectives,
-
[51]
Follow the rules: reasoning for video anomaly detection with large language models
Yuchen Yang, Kwonjoon Lee, Behzad Dariush, Yinzhi Cao, and Shao-Yuan Lo. Follow the rules: reasoning for video anomaly detection with large language models. InEuropean Conference on Computer Vision, pages 304–322. Springer,
-
[52]
Unsupervised traffic accident detection in first-person videos
Yu Yao, Mingze Xu, Yuchen Wang, David J Crandall, and Ella M Atkins. Unsupervised traffic accident detection in first-person videos. In2019 IEEE/RSJ International confer- ence on intelligent robots and systems (IROS), pages 273–
-
[53]
Dota: Unsupervised de- tection of traffic anomaly in driving videos.IEEE transac- tions on pattern analysis and machine intelligence, 45(1): 444–459, 2022
Yu Yao, Xizi Wang, Mingze Xu, Zelin Pu, Yuchen Wang, Ella Atkins, and David J Crandall. Dota: Unsupervised de- tection of traffic anomaly in driving videos.IEEE transac- tions on pattern analysis and machine intelligence, 45(1): 444–459, 2022. 1, 3
2022
-
[54]
Vera: Explainable video anomaly detection via verbalized learning of vision- language models
Muchao Ye, Weiyang Liu, and Pan He. Vera: Explainable video anomaly detection via verbalized learning of vision- language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8679–8688, 2025. 2, 7
2025
-
[55]
Harnessing large language mod- els for training-free video anomaly detection
Luca Zanella, Willi Menapace, Massimiliano Mancini, Yim- ing Wang, and Elisa Ricci. Harnessing large language mod- els for training-free video anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 18527–18536, 2024. 2, 7
2024
-
[56]
Batchnorm-based weakly supervised video anomaly detection.IEEE Transactions on Circuits and Systems for Video Technology, 34(12):13642–13654, 2024
Yixuan Zhou, Yi Qu, Xing Xu, Fumin Shen, Jingkuan Song, and Heng Tao Shen. Batchnorm-based weakly supervised video anomaly detection.IEEE Transactions on Circuits and Systems for Video Technology, 34(12):13642–13654, 2024. 2, 7
2024
-
[57]
[CARLA] densely annotated driving dataset (david)
Alberto Zorzetto. [CARLA] densely annotated driving dataset (david). Kaggle.https://www.kaggle.com/ datasets/albertozorzetto/carla- densely- annotated - driving - dataset, 2021. Accessed: 2026-06-25. 5 11 A. Appendix A.1. Datasheet for SENSE-V AD This datasheet of SENSE-V AD follows the framework of Gebru et al.2. A.1.1. Motivation For what purpose was th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.