ProductConsistency: Improving Product Identity Preservation in Instruction-Based Image Editing via SFT and RL
Pith reviewed 2026-06-26 21:15 UTC · model grok-4.3
The pith
Fine-tuning image editors with a cyclic consistency reward on a new product dataset improves identity preservation and cuts character error rates 5x.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Supervised fine-tuning on 87k product editing samples followed by reinforcement learning guided by the cyclic consistency reward produces edited images with stronger product identity preservation, better text rendering, and higher overall visual quality than the base models.
What carries the argument
The Cyclic Consistency reward, which enforces semantic preservation of product identity by computing caption similarity between the original product description and captions generated from the edited image.
If this is right
- The Qwen-Image-Edit-2511 model achieves a 5x reduction in character error rate on product text.
- Both models show consistent gains in OCR accuracy, perceptual similarity, and MLLM-based quality scores.
- The ProductConsistency Benchmark enables standardized comparison of future editing models on product identity tasks.
- The SFT-plus-RL pipeline with caption-based rewards can be applied to other open models for the same task.
Where Pith is reading between the lines
- The same cyclic reward structure might transfer to non-product domains where object identity must survive style or context changes.
- Scaling the RL dataset beyond 869 images could further reduce error rates if the caption similarity signal remains stable.
- The benchmark dataset could serve as a testbed for measuring whether other consistency methods (such as feature matching) outperform caption similarity.
Load-bearing premise
Caption similarity scores reliably capture whether fine-grained product features, branding, and text have been preserved after an edit.
What would settle it
A test set of edited images that look identical to the original product by human judgment but receive low cyclic consistency scores (or the reverse) would show the reward does not track identity preservation.
Figures











read the original abstract
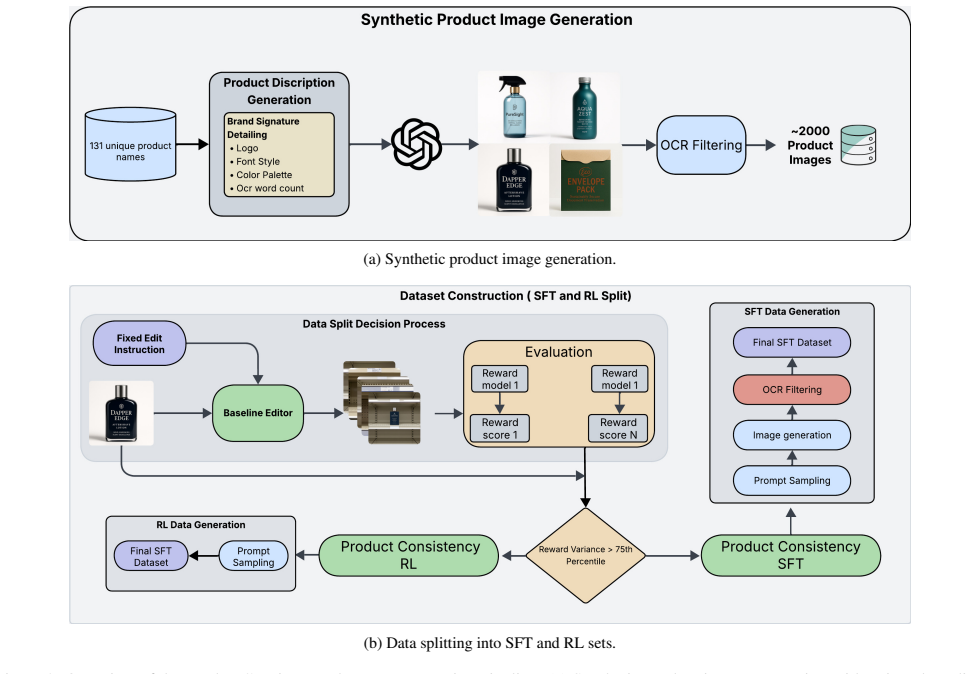
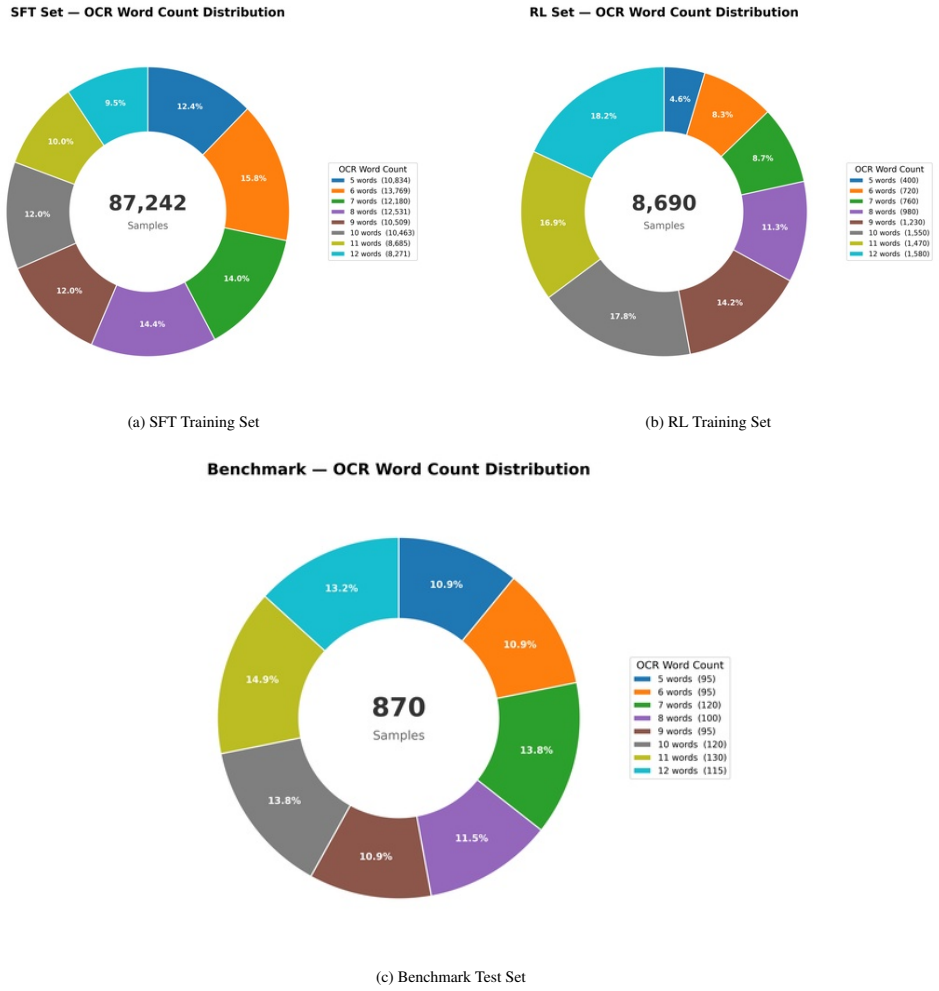
Recent advances in instruction-based image editing have enabled models to perform complex visual edits from natural language instructions. However, in product-centric scenarios where preserving product features, branding, and textual elements are critical, current open and closed source models often struggle to maintain this fine-grained object identity. This issue is further compounded by the lack of datasets for instruction-based product image editing with text fidelity constraints, leaving it largely treated as an implicit capability of instruction-based image editing models. In this work, we introduce the ProductConsistency dataset which is designed to improve product-centric image editing. Our approach includes a supervised fine-tuning (SFT) dataset of 87k samples for product editing, a reinforcement learning (RL) dataset with 869 unique product images, and a new benchmark dataset, the ProductConsistency Benchmark, to allow rigorous and standardized evaluation of editing models. To guide RL training, we propose a Cyclic Consistency reward that enforces semantic preservation of product identity by using caption similarity between the original product description and captions generated from the edited image. We fine-tune both Qwen-Image-Edit-2511 and Flux.1-Kontext-dev using our dataset and demonstrate consistent improvements over baseline models in OCR and Perceptual metrics, and MLLM-based evaluations as well, indicating stronger product consistency, text rendering, and overall visual quality; with the Qwen-Image-Edit-2511 model achieving a 5x reduction in the character error rate. The code and pipeline is available at https://anonymous.4open.science/r/ProductConsistency-6FCC/README.md
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the ProductConsistency dataset for product-centric instruction-based image editing, comprising an 87k-sample SFT dataset, an RL dataset of 869 unique product images, and a dedicated benchmark. It proposes a Cyclic Consistency reward for RL that uses MLLM caption similarity between the original product description and the edited image to enforce semantic preservation of product identity. The authors apply SFT followed by RL to fine-tune Qwen-Image-Edit-2511 and Flux.1-Kontext-dev, reporting consistent gains over baselines in OCR, perceptual, and MLLM-based metrics, including a 5x character error rate reduction for the Qwen model.
Significance. If the gains are shown to be robust, attributable to the proposed reward rather than SFT alone, and generalizable beyond the specific models and datasets, the work would supply useful training resources and a reward formulation for a practically important niche (product image editing with branding and text fidelity constraints).
major comments (1)
- [Cyclic Consistency reward description] The Cyclic Consistency reward (described in the abstract) assumes that caption-level semantic overlap is a reliable proxy for fine-grained product identity, branding, and text fidelity. However, MLLM-generated captions are high-level and can match semantically while missing low-level discrepancies such as altered logos, distorted text, or changed textures. The manuscript must provide explicit validation (e.g., correlation of the reward with human identity judgments or fine-grained perceptual metrics) to establish that the RL stage contributes beyond the SFT data; without this, the 5x CER claim cannot be confidently attributed to the proposed reward.
minor comments (1)
- [Abstract] The abstract states a 5x CER reduction but supplies no baseline model, exact metric definition, or statistical details; these should be stated explicitly even in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the Cyclic Consistency reward. We address the major comment below and outline planned revisions.
read point-by-point responses
-
Referee: The Cyclic Consistency reward (described in the abstract) assumes that caption-level semantic overlap is a reliable proxy for fine-grained product identity, branding, and text fidelity. However, MLLM-generated captions are high-level and can match semantically while missing low-level discrepancies such as altered logos, distorted text, or changed textures. The manuscript must provide explicit validation (e.g., correlation of the reward with human identity judgments or fine-grained perceptual metrics) to establish that the RL stage contributes beyond the SFT data; without this, the 5x CER claim cannot be confidently attributed to the proposed reward.
Authors: We agree that explicit validation of the reward's correlation with fine-grained identity preservation would strengthen attribution of gains to the RL stage. While improvements in OCR CER and perceptual metrics are reported after RL, these do not directly quantify reward reliability. In the revised manuscript we will add a dedicated analysis section correlating Cyclic Consistency reward values with human judgments on a held-out subset and with fine-grained metrics, including an SFT-only ablation to isolate the RL contribution. revision: yes
Circularity Check
No significant circularity; central claims rest on new datasets and externally-defined reward.
full rationale
The paper introduces a new ProductConsistency dataset (87k SFT samples + 869 RL images) and benchmark, plus a Cyclic Consistency reward defined as caption similarity via an external MLLM. No equations reduce a claimed prediction to a fitted input by construction, no self-citations are load-bearing for the core method, and no uniqueness theorems or ansatzes are smuggled in. Evaluations use separate OCR/perceptual/MLLM metrics on held-out data. The reward is a design choice (proxy via captions), not a self-referential loop. Derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Products-10k: A large-scale product recognition dataset.arXiv preprint arXiv:2008.10545, 2020
Yalong Bai, Yuxiang Chen, Wei Yu, Linfang Wang, and Wei Zhang. Products-10k: A large-scale product recognition dataset.arXiv preprint arXiv:2008.10545, 2020. 2, 4
arXiv 2008
-
[2]
Flux.1 fill [dev], 2024
Black Forest Labs. Flux.1 fill [dev], 2024. Model repository on Hugging Face. 1, 4
2024
-
[3]
In- structpix2pix: Learning to follow image editing instructions
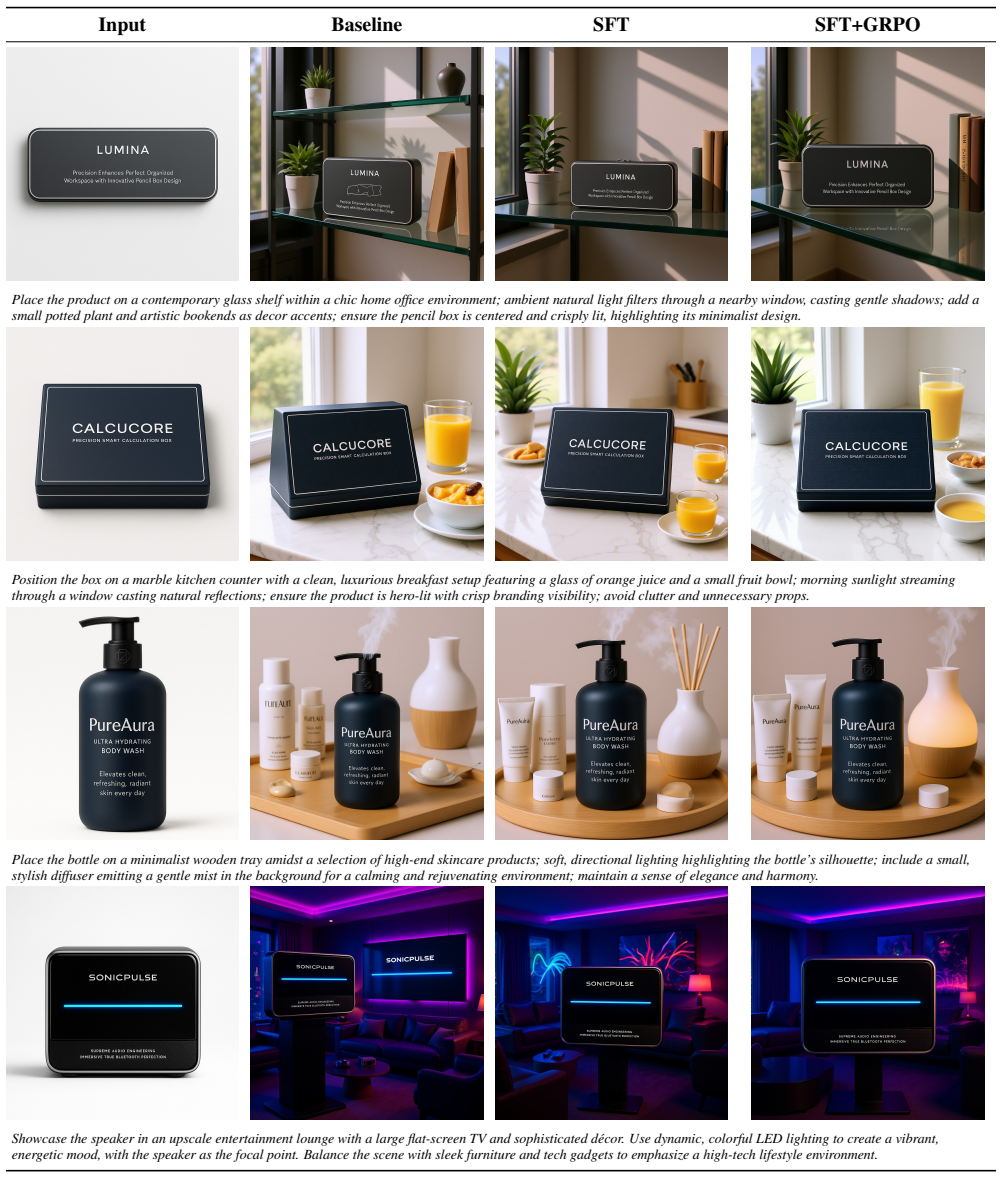
Tim Brooks, Aleksander Holynski, and Alexei A Efros. In- structpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18392–18402, 2023. 1, 4
2023
-
[4]
Hidream-i1: A high-efficient image gen- erative foundation model with sparse diffusion transformer
Qi Cai, Jingwen Chen, Yang Chen, Yehao Li, Fuchen Long, Yingwei Pan, Zhaofan Qiu, Yiheng Zhang, Fengbin Gao, Peihan Xu, et al. Hidream-i1: A high-efficient image gen- erative foundation model with sparse diffusion transformer. arXiv preprint arXiv:2505.22705, 2025. 1, 4
Pith/arXiv arXiv 2025
-
[5]
Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision-language benchmark
Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun. Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision-language benchmark. InForty- first International Conference on Machine Learning, 2024. 7
2024
-
[6]
Fine-grained im- age captioning with clip reward
Jaemin Cho, Seunghyun Yoon, Ajinkya Kale, Franck Der- noncourt, Trung Bui, and Mohit Bansal. Fine-grained im- age captioning with clip reward. InFindings of the Asso- ciation for Computational Linguistics: NAACL 2022, pages 517–527, 2022. 4
2022
-
[7]
Abo: Dataset and benchmarks for real-world 3d object un- derstanding
Jasmine Collins, Shubham Goel, Kenan Deng, Achlesh- war Luthra, Leon Xu, Erhan Gundogdu, Xi Zhang, Tomas F Yago Vicente, Thomas Dideriksen, Himanshu Arora, et al. Abo: Dataset and benchmarks for real-world 3d object un- derstanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21126– 21136, 2022. 2, 4
2022
-
[8]
Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. 7
Pith/arXiv arXiv 2025
-
[9]
Prompt tuning inversion for text-driven image editing using diffusion models
Wenkai Dong, Song Xue, Xiaoyue Duan, and Shumin Han. Prompt tuning inversion for text-driven image editing using diffusion models. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 7430–7440,
-
[10]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning ca- pability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 4
Pith/arXiv arXiv 2025
-
[11]
Tempflow-grpo: When timing matters for grpo in flow models.arXiv preprint arXiv:2508.04324, 2025
Xiaoxuan He, Siming Fu, Yuke Zhao, Wanli Li, Jian Yang, Dacheng Yin, Fengyun Rao, and Bo Zhang. Tempflow-grpo: When timing matters for grpo in flow models.arXiv preprint arXiv:2508.04324, 2025. 2, 4, 6
Pith/arXiv arXiv 2025
-
[12]
Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion
Xuan Ju, Xian Liu, Xintao Wang, Yuxuan Bian, Ying Shan, and Qiang Xu. Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion. InEuropean Conference on Computer Vision, pages 150–168. Springer,
-
[13]
Viescore: Towards explainable metrics for conditional image synthesis evaluation
Max Ku, Dongfu Jiang, Cong Wei, Xiang Yue, and Wenhu Chen. Viescore: Towards explainable metrics for conditional image synthesis evaluation. InProceedings of the 62nd An- nual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 12268–12290, 2024. 7
2024
-
[14]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742,
-
[15]
Hongyu Li, Manyuan Zhang, Dian Zheng, Ziyu Guo, Yi- meng Jia, Kaituo Feng, Hao Yu, Yexin Liu, Yan Feng, Peng Pei, et al. Editthinker: Unlocking iterative reasoning for any image editor.arXiv preprint arXiv:2512.05965, 2025. 1, 4
arXiv 2025
-
[16]
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Miles Yang, and Zhao Zhong. Mixgrpo: Unlocking flow- based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802, 2025. 2, 4, 6
Pith/arXiv arXiv 2025
-
[17]
Con- trolnet++: Improving conditional controls with efficient consistency feedback: Project page: liming-ai
Ming Li, Taojiannan Yang, Huafeng Kuang, Jie Wu, Zhaoning Wang, Xuefeng Xiao, and Chen Chen. Con- trolnet++: Improving conditional controls with efficient consistency feedback: Project page: liming-ai. github. io/controlnet plus plus. InEuropean Conference on Com- puter Vision, pages 129–147. Springer, 2024. 1, 4
2024
-
[18]
Stylediffusion: Prompt-embedding inversion for text-based editing.arXiv preprint arXiv:2303.15649,
Senmao Li, Joost Van De Weijer, Taihang Hu, Fahad Shah- baz Khan, Qibin Hou, Yaxing Wang, Jian Yang, and Ming- Ming Cheng. Stylediffusion: Prompt-embedding inversion for text-based editing.arXiv preprint arXiv:2303.15649,
-
[19]
Reflect-dit: Inference-time scaling for text-to-image diffu- sion transformers via in-context reflection
Shufan Li, Konstantinos Kallidromitis, Akash Gokul, Arsh Koneru, Yusuke Kato, Kazuki Kozuka, and Aditya Grover. Reflect-dit: Inference-time scaling for text-to-image diffu- sion transformers via in-context reflection. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 15657–15668, 2025. 1, 4
2025
-
[20]
Tiancheng Li, Jinxiu Liu, Huajun Chen, and Qi Liu. Instruc- trl4pix: Training diffusion for image editing by reinforce- ment learning.arXiv preprint arXiv:2406.09973, 2024. 4
arXiv 2024
-
[21]
Brushedit: All-in-one image inpainting and editing.arXiv preprint arXiv:2412.10316, 2024
Yaowei Li, Yuxuan Bian, Xuan Ju, Zhaoyang Zhang, Junhao Zhuang, Ying Shan, Yuexian Zou, and Qiang Xu. Brushedit: All-in-one image inpainting and editing.arXiv preprint arXiv:2412.10316, 2024. 4
arXiv 2024
-
[22]
Zongjian Li, Zheyuan Liu, Qihui Zhang, Bin Lin, Feize Wu, Shenghai Yuan, Zhiyuan Yan, Yang Ye, Wangbo Yu, Yuwei Niu, et al. Uniworld-v2: Reinforce image editing with diffu- sion negative-aware finetuning and mllm implicit feedback. arXiv preprint arXiv:2510.16888, 2025. 4
Pith/arXiv arXiv 2025
-
[23]
An eval- uation framework for product images background inpainting based on human feedback and product consistency
Yuqi Liang, Jun Luo, Xiaoxi Guo, and Jianqi Bi. An eval- uation framework for product images background inpainting based on human feedback and product consistency. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 478–486, 2025. 2, 4
2025
-
[24]
Flow-grpo: Training flow matching models via on- line rl.arXiv preprint arXiv:2505.05470, 2025
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via on- line rl.arXiv preprint arXiv:2505.05470, 2025. 2, 4, 6 9
Pith/arXiv arXiv 2025
-
[25]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuro- pean conference on computer vision, pages 38–55. Springer,
-
[26]
Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chun- rui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025. 1, 4
Pith/arXiv arXiv 2025
-
[27]
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu- Chiang Frank Wang, Kwang-Ting Cheng, et al. Gdpo: Group reward-decoupled normalization policy optimiza- tion for multi-reward rl optimization.arXiv preprint arXiv:2601.05242, 2026. 6
Pith/arXiv arXiv 2026
-
[28]
Xin Luo, Jiahao Wang, Chenyuan Wu, Shitao Xiao, Xiyan Jiang, Defu Lian, Jiajun Zhang, Dong Liu, et al. Editscore: Unlocking online rl for image editing via high-fidelity re- ward modeling.arXiv preprint arXiv:2509.23909, 2025. 4
arXiv 2025
-
[29]
Hpsv3: Towards wide-spectrum human preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum human preference score. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15086–15095, 2025. 4
2025
-
[30]
Ishaan Malhi, Praneet Dutta, Ellie Talius, Sally Ma, Bren- dan Driscoll, Krista Holden, Garima Pruthi, and Arunacha- lam Narayanaswamy. Preserving product fidelity in large scale image recontextualization with diffusion models.arXiv preprint arXiv:2503.08729, 2025. 6
arXiv 2025
-
[31]
Null-text inversion for editing real im- ages using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real im- ages using guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6038–6047, 2023. 1
2023
-
[32]
T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InProceedings of the AAAI conference on artificial intelligence, pages 4296–4304, 2024. 1, 4
2024
-
[33]
Gpt-5.1: A smarter, more conversational chatgpt,
OpenAI. Gpt-5.1: A smarter, more conversational chatgpt,
-
[34]
OpenAI Product Release. 7
-
[35]
Introducing gpt image 1 (gpt-4o image generation),
OpenAI. Introducing gpt image 1 (gpt-4o image generation),
-
[36]
Initial GPT Image 1 release (March 25, 2025). 5
2025
-
[37]
Bowen Ping, Chengyou Jia, Minnan Luo, Changliang Xia, Xin Shen, Zhuohang Dang, and Hangwei Qian. Paco- rl: Advancing reinforcement learning for consistent image generation with pairwise reward modeling.arXiv preprint arXiv:2512.04784, 2025. 6
arXiv 2025
-
[38]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 4
Pith/arXiv arXiv 2023
-
[39]
Can Qin, Shu Zhang, Ning Yu, Yihao Feng, Xinyi Yang, Yingbo Zhou, Huan Wang, Juan Carlos Niebles, Caiming Xiong, Silvio Savarese, et al. Unicontrol: A unified diffusion model for controllable visual generation in the wild.arXiv preprint arXiv:2305.11147, 2023. 1, 4
arXiv 2023
-
[40]
Tianyuan Qu, Lei Ke, Xiaohang Zhan, Longxiang Tang, Yuqi Liu, Bohao Peng, Bei Yu, Dong Yu, and Jiaya Jia. Replan: Reasoning-guided region planning for com- plex instruction-based image editing.arXiv preprint arXiv:2512.16864, 2025. 1, 4
arXiv 2025
-
[41]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 6
2021
-
[42]
Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 6
Pith/arXiv arXiv 2024
-
[43]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1, 4
2022
-
[44]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500– 22510, 2023. 6
2023
-
[45]
Introduction: Ai aes- thetics
Jan-No ¨el Thon and Lukas RA Wilde. Introduction: Ai aes- thetics. InAI Aesthetics, pages 1–21. Routledge, 2025. 4
2025
-
[46]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 8
Pith/arXiv arXiv 2025
-
[47]
Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 1, 4
Pith/arXiv arXiv 2025
-
[48]
Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025. 4
Pith/arXiv arXiv 2025
-
[49]
Keming Wu, Sicong Jiang, Max Ku, Ping Nie, Minghao Liu, and Wenhu Chen. Editreward: A human-aligned reward model for instruction-guided image editing.arXiv preprint arXiv:2509.26346, 2025. 4
arXiv 2025
-
[50]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341,
-
[51]
Omnigen: Unified image genera- tion
Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xin- grun Xing, Ruiran Yan, Chaofan Li, Shuting Wang, Tiejun Huang, and Zheng Liu. Omnigen: Unified image genera- tion. InProceedings of the IEEE/CVF Conference on Com- 10 puter Vision and Pattern Recognition, pages 13294–13304,
-
[52]
Imagere- ward: Learning and evaluating human preferences for text- to-image generation.Advances in Neural Information Pro- cessing Systems, 36:15903–15935, 2023
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagere- ward: Learning and evaluating human preferences for text- to-image generation.Advances in Neural Information Pro- cessing Systems, 36:15903–15935, 2023. 4
2023
-
[53]
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arXiv:2308.06721,
-
[54]
Reasonedit: Towards reasoning-enhanced image editing models.arXiv preprint arXiv:2511.22625,
Fukun Yin, Shiyu Liu, Yucheng Han, Zhibo Wang, Peng Xing, Rui Wang, Wei Cheng, Yingming Wang, Aojie Li, Zixin Yin, et al. Reasonedit: Towards reasoning-enhanced image editing models.arXiv preprint arXiv:2511.22625,
-
[55]
R-genie: Reasoning-guided generative image editing
Dong Zhang, Lingfeng He, Rui Yan, Fei Shen, and Jinhui Tang. R-genie: Reasoning-guided generative image editing. arXiv preprint arXiv:2505.17768, 2025. 1, 4
arXiv 2025
-
[56]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 1, 4
2023
-
[57]
Easycontrol: Adding efficient and flexible control for diffusion transformer
Yuxuan Zhang, Yirui Yuan, Yiren Song, Haofan Wang, and Jiaming Liu. Easycontrol: Adding efficient and flexible control for diffusion transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19513–19524, 2025. 1, 4
2025
-
[58]
Multibooth: Towards generating all your concepts in an im- age from text
Chenyang Zhu, Kai Li, Yue Ma, Chunming He, and Xiu Li. Multibooth: Towards generating all your concepts in an im- age from text. InProceedings of the AAAI Conference on Artificial Intelligence, pages 10923–10931, 2025. 6
2025
-
[59]
Zhentao Zou, Zhengrong Yue, Kunpeng Du, Binlei Bao, Hanting Li, Haizhen Xie, Guozheng Xu, Yue Zhou, Yali Wang, Jie Hu, et al. Beyond textual cot: Interleaved text- image chains with deep confidence reasoning for image edit- ing.arXiv preprint arXiv:2510.08157, 2025. 1, 4 11 ProductConsistency: Improving Product Identity Preservation in Instruction-Based I...
arXiv 2025
-
[60]
Qualitative Evaluation We present qualitative results from our experiments in Fig- ure 7 for the Qwen-Image-Edit-2511 model and in Figure 8 for the Flux.1-Kontext-dev model. As shown in both figures, the baseline models exhibit several common fail- ure modes, including incorrect or distorted text, inconsis- tent product geometry and color, and hallucinate...
-
[61]
First, the pipeline pri- marily focuses on products with straight and clearly visible text layouts
Limitations and Future Work Although the ProductConsistency dataset and training framework significantly improve product fidelity and text preservation in instruction-based image editing, several op- portunities remain for future work. First, the pipeline pri- marily focuses on products with straight and clearly visible text layouts. Extending the framewo...
-
[62]
Place the bottle on a modern bathroom countertop with a large mirror reflecting soft morning light; include a neatly folded white towel and a small potted succulent as accents; warm ambient lighting to create a clean, inviting atmosphere; subtle reflections on the countertop to enhance the bottle’s frosted finish; avoid clutter or personal items. 2) Posit...
-
[63]
• Primary = product body; Secondary/Accent = minimal trims/edge lines/engraving fills
Color Scheme (Primary / Secondary / Accent) • Choose a tasteful triad appropriate to{{PRODUCT CATEGORY}}and the brand’s character. • Primary = product body; Secondary/Accent = minimal trims/edge lines/engraving fills. • Always ensure strong text-to-body contrast for readability (e.g., light text on dark product)
-
[64]
Finish • Select a realistic finish (e.g., matte, glossy, satin, brushed, frosted, soft touch, ceramic)
-
[65]
This is CRITICAL
Contrast Level • Implicitly aim for high readability of the text on the product. This is CRITICAL. • Explicitly state text color vs product body color to ensure clear read. Text color MUST NOT match product color
-
[66]
• Placement: precise (e.g., centered upper third, lid center, front and center under shoulder)
Logo Style, Placement, Typography Feel • Logo style: Choose a logo style that best fits the brand, and describe in detail how the logo should look in the prompt. • Placement: precise (e.g., centered upper third, lid center, front and center under shoulder). • Typography feel: specify (serif, sans-serif, geometric, humanist, condensed, script)
-
[67]
• Reflect it in materials, color usage, typography and finish
Brand Archetype (to guide tone and visuals) • Infer one of: minimalist, luxury, rugged, playful, eco-conscious. • Reflect it in materials, color usage, typography and finish
-
[68]
prompt", 2:
Text Keywords (brand benefits + product type) • Build the printed line to naturally reference brand benefits and product type. • Keep it on brand with the chosen archetype and category. STRICT RULES (MANDATORY) 1)Start of each prompt: Create your own random brand name in the given product category and describe brand detailing (logo, text, tagline position...
-
[69]
Carefully analyze theinput imageand understand the product, structure, text, layout, and composition
-
[70]
Readinput image descriptionto confirm product identity and expected details
-
[71]
Compareinput imageandedited imagecarefully
-
[72]
Evaluate each metric thoughtfully, paying attention to anything that might impact the score
-
[73]
Do NOT inflate scores
Be strict. Do NOT inflate scores. ONLY output final JSON. METRICS (Score each 0–10 integer)
-
[74]
Shape, proportions, structural features, geometry, and defining characteristics must remain unchanged
Product Consistency The product in the edited image must be the SAME product as in the input image. Shape, proportions, structural features, geometry, and defining characteristics must remain unchanged. Failures include: • Shape distortion (even subtle warping or stretching) • Missing components • Identity change of product • Brand identity changes (logo,...
-
[75]
no visible product text in input image
Text Rendering / Text Fidelity Any text originally visible on the product (brand name, label, instructions, numbers, logo text) must remain legible and sharp, correctly spelled with no character substitutions, and unchanged in content, font style, and positioning. Failures include: • Misspellings or altered characters; altered or missing words • Missing t...
-
[76]
good” — baseline for a decent edit. If giving 9 or 10, you MUST justify by confirming no meaningful mistakes were found. OUTPUT FORMAT (STRICT JSON ONLY) { “product consistency
Aesthetics / Composition Overall visual appeal, composition quality, and alignment with the edit instruction’s intent. The edited image must appear photorealistic and visually coherent. Check for: • Proper centering or intentional framing; balanced negative space • Product prominence and clear visual focus • Color temperature consistency; pleasant, consis...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.