Do LLMsMakeNeural Distinguishers Wise?
Pith reviewed 2026-06-27 12:28 UTC · model grok-4.3
The pith
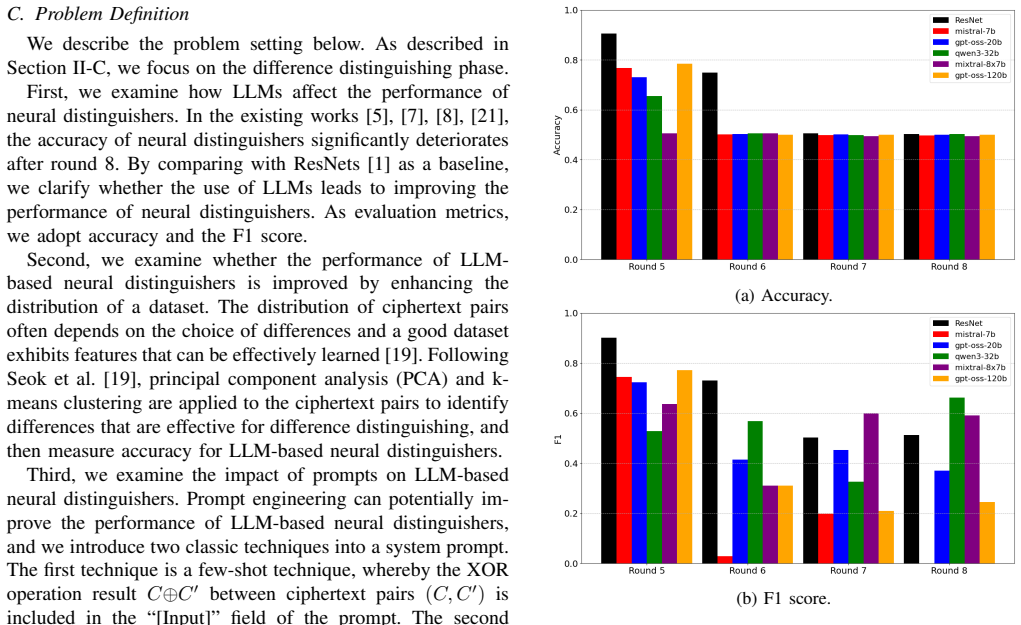
Large language models do not improve the performance of neural distinguishers compared to ResNet models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
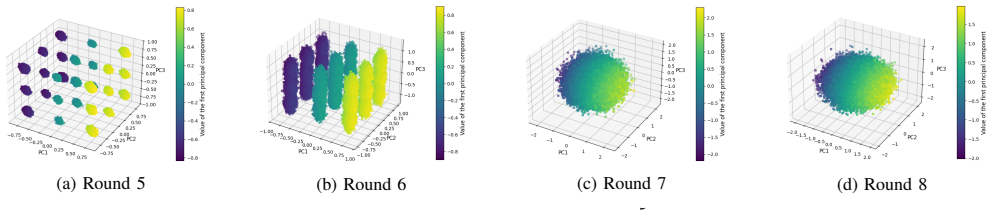
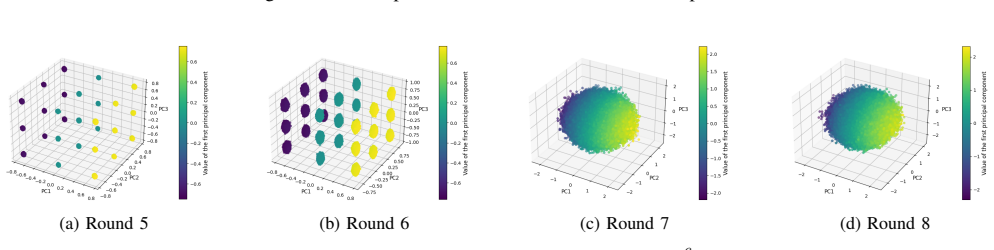
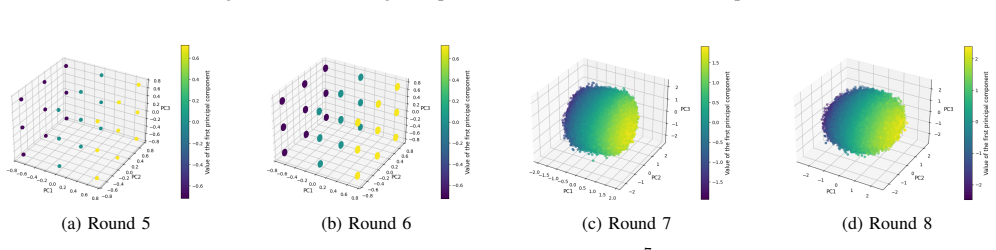
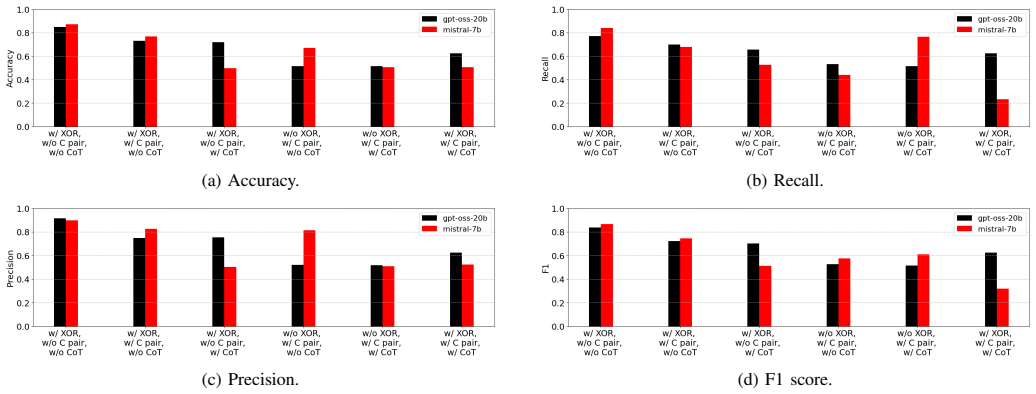
LLM-based neural distinguishers built with prompt designs show no observable improvement in performance over ResNet-based neural distinguishers when tested on SPECK-32/64. At high rounds, the choice of differences loses effectiveness for LLM-based distinguishers just as it does for ResNet. The performance of LLM-based neural distinguishers improves significantly when the prompt includes only the results of the XOR operation.
What carries the argument
Prompt design for LLM-based neural distinguishers that input differential plaintext-ciphertext pairs to classify whether they come from the cipher or not.
If this is right
- LLMs do not strengthen neural distinguishers beyond ResNet performance.
- Difference choice is ineffective at high rounds for LLM-based neural distinguishers.
- Using only XOR operation results in prompts significantly improves LLM-based neural distinguisher performance.
Where Pith is reading between the lines
- The task of distinguishing based on differential pairs may favor convolutional architectures like ResNet over language models.
- Careful selection of what information to include in prompts can enhance LLM performance in technical domains like cryptanalysis.
- The lack of improvement on this lightweight cipher raises questions about whether LLMs would help on more complex ciphers.
Load-bearing premise
The specific prompt designs and choice of SPECK-32/64 with the tested differences are representative enough to conclude that LLMs do not strengthen neural distinguishers in general.
What would settle it
Finding an LLM prompt or configuration that achieves higher accuracy than the ResNet baseline on SPECK-32/64 would falsify the claim of no improvement.
Figures
read the original abstract
Neural distinguishers are a cryptanalysis method for symmetric-key cryptography that trains machine learning models on pairs of plaintexts and ciphertexts with specific differences in order to recover a secret key. To the best of our knowledge, no existing work has explored the use of large language models (LLMs) for neural distinguishers. In this paper, we propose LLM-based neural distinguishers through a prompt design and conduct extensive experiments with them on SPECK-32/64 to investigate whether LLMs can strengthen neural distinguishers. We then found three key insights. First, by comparing the results of LLM-based neural distinguishers with ResNet in the existing work, we demonstrate that LLMs provide no observable improvement in the performance of neural distinguishers. Second, we confirm that, at high rounds, the choice of differences is no longer effective for LLM-based neural distinguishers as well as ResNet. Third, we show that the performance of LLM-based neural distinguishers can be significantly improved by incorporating only the XOR operation results as a prompt design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes prompt-based LLM neural distinguishers for cryptanalysis and reports experiments on SPECK-32/64. It claims three findings: (1) LLMs show no observable improvement over existing ResNet distinguishers, (2) at high rounds the choice of input differences loses effectiveness (as with ResNet), and (3) incorporating XOR operation results into the prompt yields significant performance gains for the LLM approach.
Significance. If the empirical comparisons hold after proper controls and replication, the work would indicate that current LLMs add little value over established CNNs for neural distinguishers on lightweight ARX ciphers, while underscoring prompt sensitivity (XOR variant). This could steer the field toward more targeted ML architectures rather than general-purpose LLMs for this task.
major comments (3)
- [Abstract] Abstract: the three findings are asserted without any reported metrics (accuracy, TPR/FPR), dataset sizes, number of rounds/differences tested, training details, or statistical tests, so it is impossible to determine whether the data support the claims. This is load-bearing for all three contributions.
- [Abstract (first finding)] The primary claim (no observable improvement over ResNet) rests on comparisons only for selected differences on SPECK-32/64; the manuscript itself notes that adding the XOR variant changes results, which directly indicates that performance is sensitive to prompt details and undermines the generality of the 'no improvement' conclusion.
- [Abstract (second and third findings)] The second finding (differences ineffective at high rounds) and third finding (XOR improvement) require explicit quantification of round counts, exact differences, and the magnitude of the reported gains versus the non-XOR baseline to be evaluable; without these the claims cannot be assessed for reproducibility or effect size.
minor comments (2)
- [Title] Title contains an apparent typographical error ('Do LLMsMakeNeural' lacks spaces).
- [Abstract] Abstract uses inconsistent tense ('we then found' after present-tense description of the proposal).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment point by point below, indicating where revisions will be made to improve clarity and evaluability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the three findings are asserted without any reported metrics (accuracy, TPR/FPR), dataset sizes, number of rounds/differences tested, training details, or statistical tests, so it is impossible to determine whether the data support the claims. This is load-bearing for all three contributions.
Authors: We agree that the abstract should contain sufficient quantitative details for the claims to be assessed. The full manuscript reports accuracy metrics, dataset sizes (typically 10^6 samples), rounds tested (1-8 for SPECK-32/64), specific differences, and training procedures, but these were omitted from the abstract for brevity. In the revision we will expand the abstract to include representative accuracy values, round ranges, and a note on the experimental scale. revision: yes
-
Referee: [Abstract (first finding)] The primary claim (no observable improvement over ResNet) rests on comparisons only for selected differences on SPECK-32/64; the manuscript itself notes that adding the XOR variant changes results, which directly indicates that performance is sensitive to prompt details and undermines the generality of the 'no improvement' conclusion.
Authors: The first finding concerns the base prompt (without XOR) versus ResNet on the tested differences; the XOR variant is introduced separately as the third finding and is not part of the base comparison. We therefore maintain that the 'no improvement' statement holds for the standard prompt design. However, we acknowledge the referee's point on prompt sensitivity and will revise the abstract to explicitly separate the base results from the XOR-enhanced results while noting that performance depends on prompt formulation. revision: partial
-
Referee: [Abstract (second and third findings)] The second finding (differences ineffective at high rounds) and third finding (XOR improvement) require explicit quantification of round counts, exact differences, and the magnitude of the reported gains versus the non-XOR baseline to be evaluable; without these the claims cannot be assessed for reproducibility or effect size.
Authors: We agree that the abstract must supply these quantities. The manuscript already contains the details (rounds 5-8 for the high-round regime, concrete differences such as 0x0040/0x0000, and accuracy deltas between XOR and non-XOR prompts). We will add explicit round counts, example differences, and quantified gains (e.g., accuracy improvement of X percentage points) to the abstract and ensure the main text tables are referenced there. revision: yes
Circularity Check
No circularity; empirical results stand independently on experiments.
full rationale
The paper's central claim rests on direct experimental comparison of LLM prompt-based distinguishers versus published ResNet accuracies for SPECK-32/64. No equations, parameter fits, derivations, or self-citations appear in the provided text. The three insights are stated as outcomes of the runs, with no reduction of any result to its own inputs by construction. The argument is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Improving attacks on round-reduced speck32/64 using deep learning,
A. Gohr, “Improving attacks on round-reduced speck32/64 using deep learning,” inAnnual International Cryptology Conference. Springer, 2019, pp. 150–179
2019
-
[2]
Machine learning in side-channel analysis: a first study,
G. Hospodar, B. Gierlichs, E. De Mulder, I. Verbauwhede, and J. Vande- walle, “Machine learning in side-channel analysis: a first study,”Journal of Cryptographic Engineering, vol. 1, no. 4, pp. 293–302, 2011
2011
-
[3]
Differential-ml distinguisher: Machine learn- ing based generic extension for differential cryptanalysis,
T. Yadav and M. Kumar, “Differential-ml distinguisher: Machine learn- ing based generic extension for differential cryptanalysis,” inProc. of LATINCRYPT, ser. LNCS, P. Longa and C. R `afols, Eds., vol. 12912. Springer, 2021, pp. 191–212
2021
-
[4]
Machine learning-assisted differential distinguishers for lightweight ciphers,
A. Baksi, “Machine learning-assisted differential distinguishers for lightweight ciphers,” inClassical and Physical Security of Symmetric Key Cryptographic Algorithms. Springer, 2022, pp. 141–162
2022
-
[5]
Enhancing neural distinguishers with partial difference bits leakage,
Y . Hu, L. Li, S. Zhu, and Z. Hu, “Enhancing neural distinguishers with partial difference bits leakage,”Internet Things, vol. 29, p. 101438, 2025
2025
-
[6]
Output prediction attacks on block ciphers using deep learning,
H. Kimura, K. Emura, T. Isobe, R. Ito, K. Ogawa, and T. Ohigashi, “Output prediction attacks on block ciphers using deep learning,” in Proc. of ACNSW 2022, ser. LNCS, vol. 13285. Springer, 2022, pp. 248–276
2022
-
[7]
Enhanced neural distinguisher model for efficient differential cryptanalysis,
Y . Lu, Y . Guo, W. Liu, W. Chen, Q. Yan, and B. Yu, “Enhanced neural distinguisher model for efficient differential cryptanalysis,”IEEE Internet of Things Journal, 2025
2025
-
[8]
A new (related-key) neural distinguisher using two differences for differential cryptanalysis,
G. Wang, G. Wang, and S. Sun, “A new (related-key) neural distinguisher using two differences for differential cryptanalysis,”IET Information Security, vol. 2024, no. 1, pp. 1–11, 2024
2024
-
[9]
A deeper look at ma- chine learning-based cryptanalysis,
A. Benamira, D. Gerault, T. Peyrin, and Q. Q. Tan, “A deeper look at ma- chine learning-based cryptanalysis,” inAnnual international conference on the theory and applications of cryptographic techniques. Springer, 2021, pp. 805–835
2021
-
[10]
Improve neural distinguishers of simon and speck,
Z. Hou, J. Ren, and S. Chen, “Improve neural distinguishers of simon and speck,”Security and Communication Networks, vol. 2021, no. 1, p. 9288229, 2021
2021
-
[11]
Neural distinguishers on tinyjambu-128 and gift-64,
T. Sun, D. Shen, S. Long, Q. Deng, and S. Wang, “Neural distinguishers on tinyjambu-128 and gift-64,” inInternational Conference on Neural Information Processing. Springer, 2022, pp. 419–431
2022
-
[12]
Enhancing differential-neural cryptanalysis,
Z. Bao, J. Guo, M. Liu, L. Ma, and Y . Tu, “Enhancing differential-neural cryptanalysis,” inInternational conference on the theory and application of cryptology and information security. Springer, 2022, pp. 318–347
2022
-
[13]
Deep neural networks aiding cryptanalysis: A case study of the speck distinguisher,
N. B ˘acuiet,i, L. Batina, and S. Picek, “Deep neural networks aiding cryptanalysis: A case study of the speck distinguisher,” inInternational Conference on Applied Cryptography and Network Security. Springer, 2022, pp. 809–829
2022
-
[14]
Enhanced neu- ral differential distinguisher for speck32/64 using attention mechanisms and multi ciphertext inputs,
X. Jiang, M. Li, M. Kaiyrbek, V . Lakhno, and S. Andrii, “Enhanced neu- ral differential distinguisher for speck32/64 using attention mechanisms and multi ciphertext inputs,”Informatica, vol. 49, no. 19, 2025
2025
-
[15]
L. Cheng, X. Li, and L. Bing, “Is gpt-4 a good data analyst?”arXiv preprint arXiv:2305.15038, 2023
arXiv 2023
-
[16]
Prompt- to-sql injections in llm-integrated web applications: Risks and defenses,
R. Pedro, M. E. Coimbra, D. Castro, P. Carreira, and N. Santos, “Prompt- to-sql injections in llm-integrated web applications: Risks and defenses,” inProc. of ICSE 2025, 2025, pp. 1768–1780
2025
-
[17]
Red-teaming llm multi-agent systems via communication attacks,
P. He, Y . Lin, S. Dong, H. Xu, Y . Xing, and H. Liu, “Red-teaming llm multi-agent systems via communication attacks,” inProc. of ACL 2025, 2025, pp. 6726–6747
2025
-
[18]
PentestGPT: Evaluating and harnessing large language models for automated penetration testing,
G. Deng, Y . Liu, V . Mayoral-Vilches, P. Liu, Y . Li, Y . Xu, T. Zhang, Y . Liu, M. Pinzger, and S. Rass, “PentestGPT: Evaluating and harnessing large language models for automated penetration testing,” inProc. of USENIX Security 2024. USENIX Association, 2024, pp. 847–864
2024
-
[19]
A novel approach to construct a good dataset for differential-neural cryptanalysis,
B. Seok and C. Lee, “A novel approach to construct a good dataset for differential-neural cryptanalysis,”IEEE Transactions on Dependable and Secure Computing, vol. 22, no. 1, pp. 246–262, 2025
2025
-
[20]
The SIMON and SPECK families of lightweight block ciphers,
R. Beaulieu, D. Shors, J. Smith, S. Treatman-Clark, B. Weeks, and L. Wingers, “The SIMON and SPECK families of lightweight block ciphers,” Cryptology ePrint Archive, Paper 2013/404, 2013. [Online]. Available: https://eprint.iacr.org/2013/404
2013
-
[21]
Investigating and enhancing the neural distinguisher for differential cryptanalysis,
G. Wang, G. Wang, and S. Sun, “Investigating and enhancing the neural distinguisher for differential cryptanalysis,”IEICE Transactions on Information and Systems, vol. E107-D, no. 8, pp. 1016–1028, 2024
2024
-
[22]
Benchmarking large language models for cryptanalysis and mismatched-generalization,
U. Maskey, C. Zhu, and U. Naseem, “Benchmarking large language models for cryptanalysis and mismatched-generalization,”arXiv preprint arXiv:2505.24621, 2025
Pith/arXiv arXiv 2025
-
[23]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[24]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[25]
A new neural distinguisher con- sidering features derived from multiple ciphertext pairs,
Y . Chen, Y . Shen, H. Yu, and S. Yuan, “A new neural distinguisher con- sidering features derived from multiple ciphertext pairs,”The Computer Journal, vol. 66, no. 6, pp. 1419–1433, 2022
2022
-
[26]
Improving deep learning-based neural distinguisher with multiple ciphertext pairs for speck and simon,
Y . Hou, J. Liu, S. Han, Z. Ma, X. Ye, and X. Nie, “Improving deep learning-based neural distinguisher with multiple ciphertext pairs for speck and simon,”Scientific Reports, vol. 15, no. 1, p. 13696, 2025
2025
-
[27]
Improved (related-key) differential-based neural distinguishers for simon and simeck block ciphers,
J. Lu, G. Liu, B. Sun, C. Li, and L. Liu, “Improved (related-key) differential-based neural distinguishers for simon and simeck block ciphers,”The Computer Journal, vol. 67, no. 2, pp. 537–547, 01 2023
2023
-
[28]
Deep learning- based differential distinguishers for nist standard authenticated encryp- tion and permutations,
D. Pal, M. Chaudhury, A. Das, and D. R. Chowdhury, “Deep learning- based differential distinguishers for nist standard authenticated encryp- tion and permutations,” inProc. of ICMC 2024, ser. LNNS, vol. 963. Springer, 2024, pp. 1–13
2024
-
[29]
On the effects of neural network- based output prediction attacks on the design of symmetric-key ciphers,
H. Watanabe, R. Ito, and T. Ohigashi, “On the effects of neural network- based output prediction attacks on the design of symmetric-key ciphers,” Journal of Information Security and Applications, vol. 90, p. 104016, 2025
2025
-
[30]
Bayesian modeling for differential cryptanalysis of block ciphers: A des instance,
V . Agate, F. Concone, A. De Paola, P. Ferraro, G. L. Re, and M. Morana, “Bayesian modeling for differential cryptanalysis of block ciphers: A des instance,”IEEE Access, vol. 11, pp. 4809–4820, 2023
2023
-
[31]
Ml based improved differential distinguisher with high accuracy: Application to gift-128 and ascon,
T. Yadav and M. Kumar, “Ml based improved differential distinguisher with high accuracy: Application to gift-128 and ascon,” inSecurity, Privacy, and Applied Cryptography Engineering, ser. Lecture Notes in Computer Science, vol. 15351. Springer, 2025, pp. 287–316
2025
-
[32]
Rethinking learning- based symmetric cryptanalysis: a theoretical perspective,
Y . Yuan, H. Xu, L. Zhang, and W. Wu, “Rethinking learning- based symmetric cryptanalysis: a theoretical perspective,”IACR Cryptology ePrint Archives, p. 1306, 2025. [Online]. Available: https://eprint.iacr.org/2025/1306
2025
-
[33]
A survey of large language models for cyber threat detection,
Y . Chen, M. Cui, D. Wang, Y . Cao, P. Yang, B. Jiang, Z. Lu, and B. Liu, “A survey of large language models for cyber threat detection,” Computers & Security, vol. 145, p. 104016, 2024
2024
-
[34]
Llm-based attack scenarios generator with it asset management and vulnerability information,
T. Naito, R. Watanabe, and T. Mitsunaga, “Llm-based attack scenarios generator with it asset management and vulnerability information,” in Proc. of ICSPIS 2023. IEEE, 2023, pp. 99–103
2023
-
[35]
Pentestagent: Incorporating llm agents to automated penetration testing,
X. Shen, L. Wang, Z. Li, Y . Chen, W. Zhao, D. Sun, J. Wang, and W. Ruan, “Pentestagent: Incorporating llm agents to automated penetration testing,” inProc. of AsiaCCS 2025. ACM, 2025, pp. 375– 391
2025
-
[36]
Qlora: Efficient finetuning of quantized llms,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,”Advances in neural information processing systems, vol. 36, pp. 10 088–10 115, 2023
2023
-
[37]
Do NOT think that much for 2+3=? On the overthinking of long reasoning models,
X. Chen, J. Xu, T. Liang, Z. He, J. Pang, D. Yu, L. Song, Q. Liu, M. Zhou, Z. Zhang, R. Wang, Z. Tu, H. Mi, and D. Yu, “Do NOT think that much for 2+3=? On the overthinking of long reasoning models,” in Proceedings of the 42nd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 267. PMLR, 2025, pp. 9487–9499
2025
-
[38]
Stop overthinking: A survey on efficient reasoning for large language models,
Y . Sui, Y .-N. Chuang, G. Wang, J. Zhang, T. Zhang, J. Yuan, H. Liu, A. Wen, S. Zhong, N. Zou, H. Chen, and X. Hu, “Stop overthinking: A survey on efficient reasoning for large language models,”Transactions on Machine Learning Research, 2025. [Online]. Available: https://openreview.net/forum?id=HvoG8SxggZ APPENDIXA PROMPTEXAMPLE We list the system prompt...
2025
-
[41]
Output only the final answer: 0 or 1. [Input] CXORC ′ : 0xf446|0x5165 [Output] Label : ’1’ System Prompt (w/ XOR, w/ C pair, w/ CoT) [Instruction] Please determine if the ciphertext pair comes from plain- texts with difference 0x0040/0000 (output 1) or random plaintexts (output 0). Output should be either 0 or 1 only. The encryption algorithm used is 5-ro...
-
[45]
Output only the final answer: 0 or 1. [Input] C:0x0051|0x35b5 C ′:0xf417|0x64d0 CXORC ′ : 0xf446|0x5165 [Output] Label : ’1’ System Prompt (w/ XOR, w/ C pair, w/o CoT) [Instruction] Please determine if the ciphertext pair comes from plain- texts with difference of 0x0040/0000 (output 1) or ran- dom plaintexts (output 0). Output should be either 0 or 1 onl...
-
[46]
Compute the XOR of the two ciphertext halves (left and right)
-
[47]
Compare the XOR result with the expected difference pattern (0x0040 for left half, 0x0000 for right half)
-
[48]
If the XOR pattern is consistent with the expected difference (or close to it), output 1, otherwise, output 0
-
[49]
[Input] C:0x0051|0x35b5 C ′:0xf417|0x64d0 [Output] Label : ’1’
Output only the final answer: 0 or 1. [Input] C:0x0051|0x35b5 C ′:0xf417|0x64d0 [Output] Label : ’1’
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.