Causal Evidence of Stack Representations in Modeling Counter Languages Using Transformers
Pith reviewed 2026-06-28 10:20 UTC · model grok-4.3
The pith
Ablating the principal stack-depth direction from transformer hidden states collapses accuracy on counter languages to near zero.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
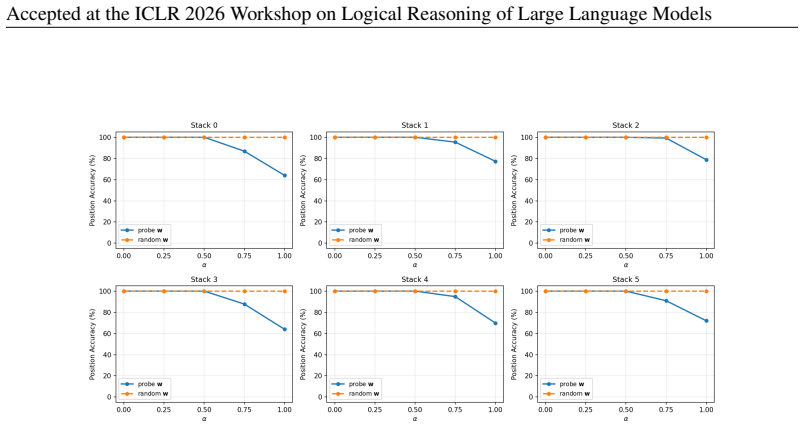
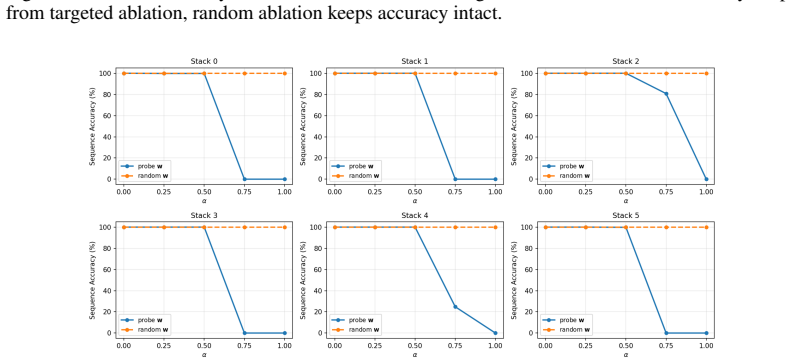
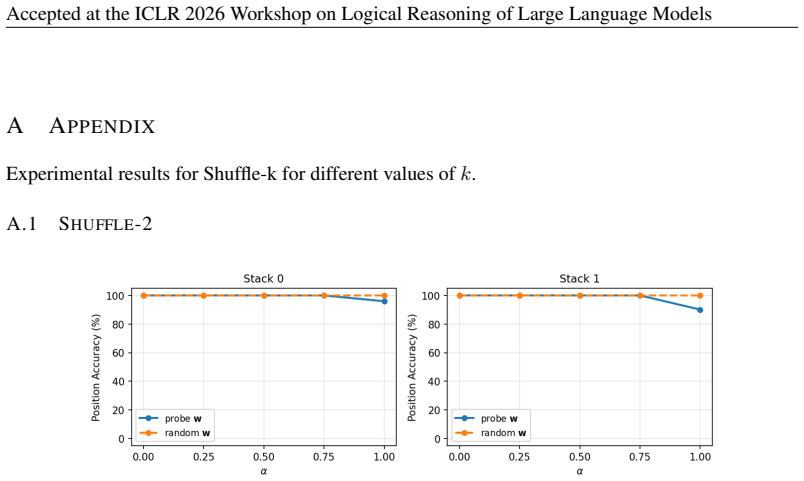
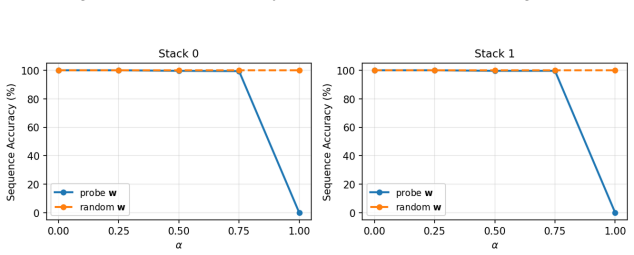
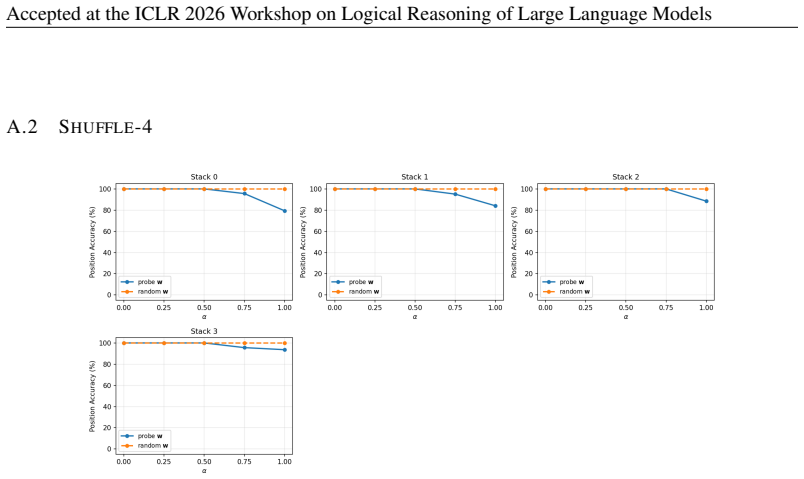
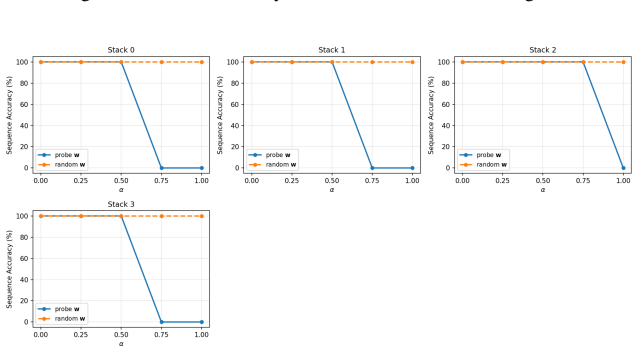
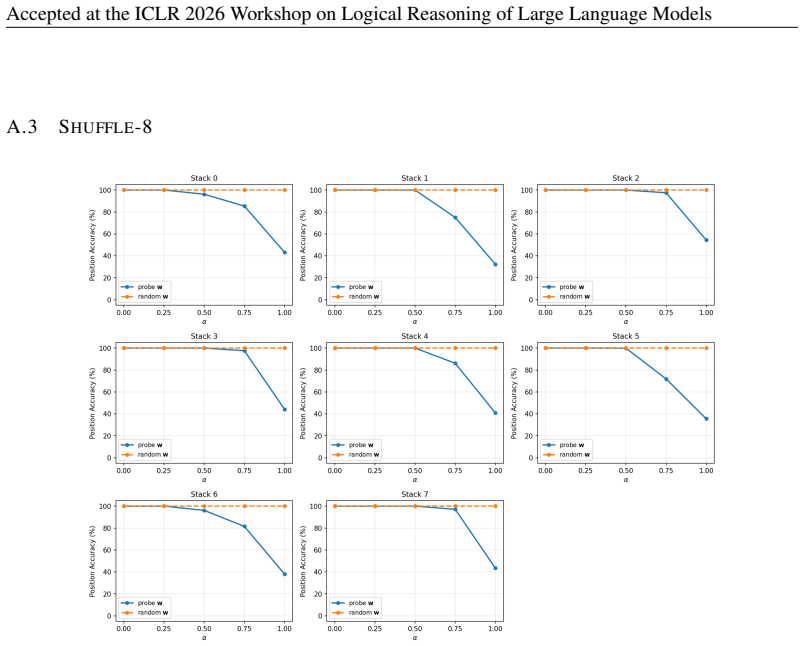
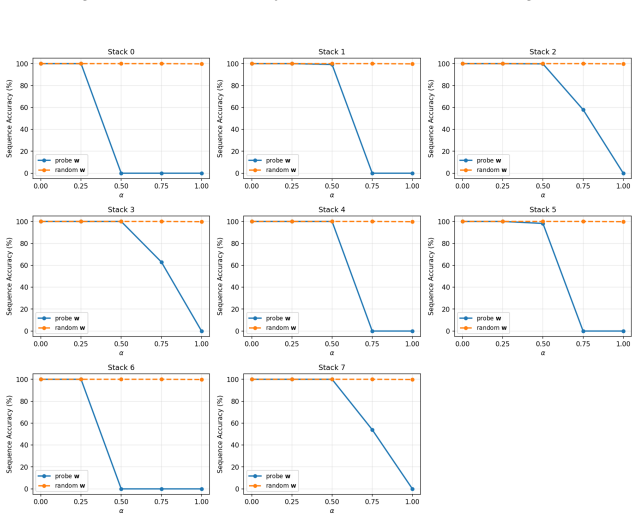
Transformers trained on next-token prediction over counter languages learn representations consistent with an underlying stack structure; the principal direction recovered by a linear probe on stack depth is causally necessary for performance because ablating it causes sequential accuracy to collapse to near 0%.
What carries the argument
Principal direction extracted from a linear probe that predicts stack depth from the model's hidden states at each token.
If this is right
- The model actively uses the recovered stack representation to carry out its sequential computations on counter languages.
- Representational similarity alone does not establish that a feature is used; causal ablation is required to demonstrate necessity.
- Targeted removal of the direction disrupts performance specifically on the stack-dependent aspects of the task.
Where Pith is reading between the lines
- The same probe-and-ablate method could be applied to other formal languages to test which internal features are required rather than merely correlated.
- If similar causal directions exist for hierarchical structure in natural language modeling, interventions on those directions might selectively impair syntactic processing.
- This result suggests that linear directions in activation space can serve as levers for testing mechanistic hypotheses in sequence models.
Load-bearing premise
The principal direction recovered from the linear probe on stack depth is the specific representational component the model relies on for its computations, and ablating it selectively removes stack information without broadly disrupting other necessary internal features.
What would settle it
Ablating the identified principal direction from the hidden states and still observing high sequential accuracy on the counter language tasks would show the direction is not causally necessary.
Figures
read the original abstract
Formal languages have proven to be effective conduits to understand the inner mechanisms of transformers. Past work has shown that transformers trained on next token prediction over counter languages learn representations consistent with an underlying stack structure. Beyond representational analysis, this paper investigates the causal role of these representations. Linear probes are trained to predict the stack depth at each token from the model's hidden states, and a principal representation direction is extracted from the probe. Ablation of this direction from the model causes sequential accuracy to collapse to near 0%, providing strong empirical evidence that the stack representation is not just learned, but is causally necessary for model performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper examines the causal role of stack representations in transformers modeling counter languages. It uses linear probes on model hidden states to predict stack depth, extracts a principal direction from the probe weights, and ablates this direction, resulting in a collapse of sequential accuracy to near zero. The authors conclude that this provides strong empirical evidence for the causal necessity of the stack representation in the model's performance.
Significance. Should the ablation be demonstrated to specifically target stack-related computations without broad disruption (e.g., via appropriate controls), the work would significantly advance the understanding of how transformers implement stack-like mechanisms for formal language tasks. It builds on prior representational studies by adding causal interventions, which is a strength of the approach.
major comments (2)
- [Ablation experiments (methods/results)] The interpretation that the ablated direction corresponds to the model's stack representation requires evidence that ablating other directions (such as random vectors or directions from probes on unrelated features like position or token identity) does not produce similar performance collapse. Without such controls, the result shows only that some depth-correlated direction is necessary, not specifically the stack representation.
- [Probe and direction extraction (methods)] It is unclear whether the principal direction recovered from the linear probe is the specific subspace used by the transformer for its stack-tracking computations, or if it is a linear combination of entangled signals. This assumption is load-bearing for the causal necessity claim but lacks supporting checks in the described procedure.
minor comments (1)
- [Abstract] The abstract could more precisely define 'sequential accuracy' and reference the exact evaluation metric or task setup used for the collapse observation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the strength of the causal claims in our work. We address each major comment below.
read point-by-point responses
-
Referee: [Ablation experiments (methods/results)] The interpretation that the ablated direction corresponds to the model's stack representation requires evidence that ablating other directions (such as random vectors or directions from probes on unrelated features like position or token identity) does not produce similar performance collapse. Without such controls, the result shows only that some depth-correlated direction is necessary, not specifically the stack representation.
Authors: We agree that control ablations are required to establish specificity. The manuscript currently shows necessity of a depth-correlated direction but does not rule out that other directions could produce similar effects. In revision we will add experiments ablating random vectors and directions from probes on position and token identity, reporting that these do not induce comparable performance collapse. revision: yes
-
Referee: [Probe and direction extraction (methods)] It is unclear whether the principal direction recovered from the linear probe is the specific subspace used by the transformer for its stack-tracking computations, or if it is a linear combination of entangled signals. This assumption is load-bearing for the causal necessity claim but lacks supporting checks in the described procedure.
Authors: The direction is recovered as the weight vector of the linear probe trained on stack depth, which by construction aligns with the feature of interest. While linear methods can entangle signals, the subsequent ablation supplies causal evidence of necessity. We will add an explicit discussion of this methodological assumption and any feasible post-hoc checks using the existing probe weights. revision: partial
Circularity Check
No circularity: purely empirical intervention study
full rationale
The paper's central claim rests on an experimental pipeline—training transformers on counter-language next-token prediction, fitting linear probes to recover a principal direction correlated with stack depth, and ablating that direction to observe accuracy collapse. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The ablation result is an independent empirical outcome, not a quantity forced by construction from the probe weights or any prior self-referential result. This matches the default expectation of a self-contained empirical paper with no load-bearing reductions to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
ICLR 2025 Workshop on World Models: Understanding, Modelling and Scaling , year=
Emergent Stack Representations in Modeling Counter Languages Using Transformers , author=. ICLR 2025 Workshop on World Models: Understanding, Modelling and Scaling , year=
2025
-
[5]
Probing Classifiers: Promises, Shortcomings, and Advances
Belinkov, Yonatan. Probing Classifiers: Promises, Shortcomings, and Advances. Computational Linguistics. 2022. doi:10.1162/coli_a_00422
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[6]
2022 , eprint=
Toy Models of Superposition , author=. 2022 , eprint=
2022
-
[7]
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D
Hewitt, John and Liang, Percy. Designing and Interpreting Probes with Control Tasks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1275
-
[8]
Transactions of the Association for Computational Linguistics , author =
Hahn, Michael. Theoretical Limitations of Self-Attention in Neural Sequence Models. Transactions of the Association for Computational Linguistics. 2020. doi:10.1162/tacl_a_00306
-
[9]
Bhattamishra, Satwik and Ahuja, Kabir and Goyal, Navin. On the A bility and L imitations of T ransformers to R ecognize F ormal L anguages. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.576
-
[10]
On the Turing Completeness of Modern Neural Network Architectures , journal =
Jorge P. On the Turing Completeness of Modern Neural Network Architectures , journal =. 2019 , url =. 1901.03429 , timestamp =
Pith/arXiv arXiv 2019
-
[11]
2023 , eprint=
Progress measures for grokking via mechanistic interpretability , author=. 2023 , eprint=
2023
-
[12]
2023 , eprint=
Locating and Editing Factual Associations in GPT , author=. 2023 , eprint=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.