Preference Instability in Reward Models: Detection and Mitigation via Sparse Autoencoders
Pith reviewed 2026-05-20 22:44 UTC · model grok-4.3
The pith
Reward models exhibit preference instability from brittle features that sparse autoencoders can isolate and correct at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
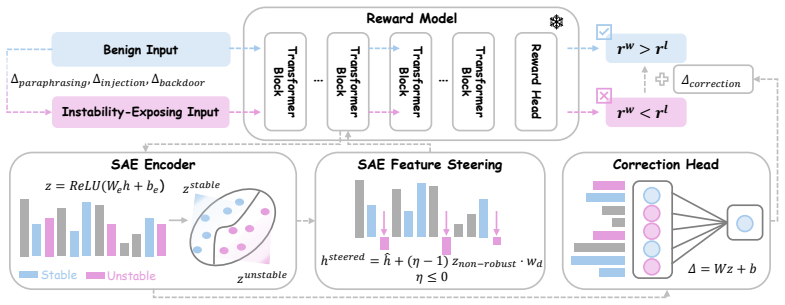
Preference instability is attributed to over-reliance on predictive yet brittle features, termed unstable features, which sparse autoencoders isolate in a sparse latent space where benign and perturbed inputs activate distinctly separable patterns. From this separability the authors derive two mitigation methods: SAE Feature Steering, which suppresses anomalously activated features at inference, and SAE Residual Correction, which learns adaptive adjustments over SAE features to restore correct preferences. These interventions reduce incorrect assignments on harmlessness and hallucination benchmarks while preserving benign performance and general utility on other tasks, without any retraining
What carries the argument
Sparse autoencoders that produce separable activation patterns for benign versus perturbed inputs inside the reward model's latent space.
If this is right
- Substantially reduces incorrect preference assignments on harmlessness and hallucination benchmarks.
- Preserves benign performance and general utility on other tasks.
- Applies across paraphrasing, pattern injection, and backdoor trigger perturbations.
- Achieves the reductions without retraining the reward model.
Where Pith is reading between the lines
- The same SAE separation technique could be tested on policy models or other alignment components that also rely on preference signals.
- Feature-level corrections of this kind might generalize to other forms of input sensitivity beyond semantic-preserving perturbations.
- Combining SAE steering with existing safety filters could produce layered defenses against both instability and overt attacks.
Load-bearing premise
The distinct activation patterns found by the SAE correspond to causally unstable features whose suppression or correction leaves performance on normal inputs unchanged.
What would settle it
If suppressing the SAE features that activate under perturbation also changes preference assignments or lowers accuracy on unperturbed benign benchmarks, the claim that these features can be corrected selectively would be falsified.
Figures







read the original abstract
Preference learning in large language models relies on reward models as proxies for human judgment. However, these models frequently exhibit preference instability, producing contradictory preference assignments in response to subtle, meaning-preserving input variations. We analyze this instability at the representation level under three semantic-preserving perturbation types: paraphrasing, pattern injection, and backdoor triggers. We attribute this instability to over-reliance on predictive yet brittle features, which we term unstable features, and isolate them via Sparse Autoencoders (SAEs) in a sparse latent space where benign and perturbed inputs activate distinctly separable patterns. Building on this separability, we propose two SAE-based instability mitigation strategies: SAE Feature Steering, which identifies and suppresses anomalously activated features at inference, and SAE Residual Correction, which learns adaptive adjustments over SAE features to restore correct preferences. Our methods substantially reduce incorrect preference assignments on harmlessness and hallucination benchmarks while preserving benign performance and general utility on other tasks, without retraining the reward model. Our code and data are available in \url{https://github.com/shunchang-liu/pisa}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that reward models for LLM preference learning exhibit instability under semantic-preserving perturbations (paraphrasing, pattern injection, backdoor triggers), which it attributes to over-reliance on brittle 'unstable features.' These features are isolated via Sparse Autoencoders (SAEs) in a latent space where benign and perturbed inputs produce distinctly separable activation patterns. Two mitigation strategies are proposed: SAE Feature Steering (suppressing anomalous activations at inference) and SAE Residual Correction (learning adaptive adjustments over SAE features). The methods are reported to substantially reduce incorrect preference assignments on harmlessness and hallucination benchmarks while preserving benign performance and general utility, without retraining the reward model. Code and data are released.
Significance. If the results hold, the work is significant for providing a post-hoc, training-free intervention that leverages SAE interpretability to address a practical robustness failure in reward models central to RLHF and preference alignment. It offers concrete, feature-level tools (steering and residual correction) that could improve deployment safety without sacrificing utility. Public code availability supports reproducibility and extension.
major comments (2)
- [§3] §3 (SAE isolation of unstable features): The manuscript shows observational separability of activation patterns between benign and perturbed inputs but does not provide causal evidence that the identified SAE features participate directly in the reward head's preference computation. Without interventions such as targeted feature ablation in the original representation space or controls comparing against random suppression, the attribution of instability to these features risks being correlational rather than mechanistic.
- [§5] §5 (mitigation experiments): The central claim of substantial reductions in incorrect preferences relies on benchmark results, yet the provided text lacks quantitative effect sizes, statistical significance, full ablation tables (e.g., vs. random feature masking or standard regularization baselines), and controls confirming that gains are not incidental. This weakens assessment of whether SAE Feature Steering and Residual Correction specifically target the instability mechanism.
minor comments (2)
- [Introduction] The term 'unstable features' is introduced descriptively; a brief formal characterization (e.g., via a stability metric over perturbations) would improve precision.
- [Figures/Tables] Figure captions and table legends should explicitly state the perturbation types, SAE sparsity level, and exact metrics used to demonstrate separability and performance preservation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for strengthening the causal interpretation and experimental validation in our work. We address each major comment below and outline the revisions we plan to implement.
read point-by-point responses
-
Referee: [§3] §3 (SAE isolation of unstable features): The manuscript shows observational separability of activation patterns between benign and perturbed inputs but does not provide causal evidence that the identified SAE features participate directly in the reward head's preference computation. Without interventions such as targeted feature ablation in the original representation space or controls comparing against random suppression, the attribution of instability to these features risks being correlational rather than mechanistic.
Authors: We acknowledge the validity of this observation. Our current results demonstrate clear separability in the SAE latent space and show that intervening on these features via steering and correction improves stability. However, to provide stronger causal evidence, we will incorporate additional experiments in the revised manuscript, including targeted ablation of the identified features directly in the reward model's representation space and comparisons against random feature suppression controls. This will help establish a more mechanistic link between the unstable features and the observed preference instability. revision: yes
-
Referee: [§5] §5 (mitigation experiments): The central claim of substantial reductions in incorrect preferences relies on benchmark results, yet the provided text lacks quantitative effect sizes, statistical significance, full ablation tables (e.g., vs. random feature masking or standard regularization baselines), and controls confirming that gains are not incidental. This weakens assessment of whether SAE Feature Steering and Residual Correction specifically target the instability mechanism.
Authors: We agree that additional quantitative details and ablations would strengthen the presentation. In the revised version, we will expand §5 to include effect sizes with confidence intervals, results from statistical significance tests across multiple seeds, comprehensive ablation tables comparing our methods to random feature masking and other regularization baselines, and further controls to rule out incidental effects. These additions will clarify the specific contribution of targeting the SAE-identified unstable features. revision: yes
Circularity Check
No significant circularity; empirical separability and benchmark validation are independent of inputs
full rationale
The paper observes distinct SAE activation patterns between benign and perturbed inputs, attributes instability to over-reliance on the differing features, and intervenes via steering or residual correction. These steps rely on measured separability and downstream benchmark outcomes (harmlessness, hallucination) rather than any equation or definition that reduces the claimed mitigation to the input patterns by construction. No self-citations, uniqueness theorems, or fitted parameters renamed as predictions appear in the load-bearing claims. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- SAE sparsity coefficient
invented entities (1)
-
unstable features
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems, 37:136037–136083, 2024
work page 2024
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
work page 1952
-
[4]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, et al. Towards monosemantic- ity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2, 2023
work page 2023
-
[5]
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, J ´er´emy Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, et al. Open problems and fundamental limitations of reinforcement learning from human feedback.arXiv preprint arXiv:2307.15217, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Xin Chen, Sam Toyer, and Florian Shkurti. Exploring and addressing reward confusion in offline preference learning.arXiv preprint arXiv:2407.16025, 2024
-
[7]
Learningsafetyconstraintsforlarge language models,
Xin Chen, Yarden As, and Andreas Krause. Learning safety constraints for large language models.arXiv preprint arXiv:2505.24445, 2025
-
[8]
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.Advances in neural information pro- cessing systems, 30, 2017
work page 2017
-
[9]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe rlhf: Safe reinforcement learning from human feedback.arXiv preprint arXiv:2310.12773, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Xuefeng Du, Chaowei Xiao, and Sharon Li. Haloscope: Harnessing unlabeled llm generations for hallucination detection.Advances in Neural Information Processing Systems, 37:102948– 102972, 2024
work page 2024
-
[12]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. InInternational Conference on Machine Learning, pages 10835–10866. PMLR, 2023
work page 2023
-
[13]
Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
Robert Geirhos, J ¨orn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
work page 2020
-
[14]
De- tecting strategic deception using linear probes.arXiv preprint arXiv:2502.03407, 2025
Nicholas Goldowsky-Dill, Bilal Chughtai, Stefan Heimersheim, and Marius Hobbhahn. De- tecting strategic deception using linear probes.arXiv preprint arXiv:2502.03407, 2025. 10
-
[15]
Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Alek- sander Madry. Adversarial examples are not bugs, they are features.Advances in neural information processing systems, 32, 2019
work page 2019
-
[16]
Rewardbench: Evaluating reward models for language modeling.arXiv preprint arXiv:2403.13787, 2024
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, et al. Rewardbench: Evaluating reward models for language modeling.arXiv preprint arXiv:2403.13787, 2024
-
[17]
Kenneth Li, Oam Patel, Fernanda Vi´egas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530, 2023
work page 2023
-
[18]
Safer: Probing safety in reward models with sparse autoencoder.arXiv preprint arXiv:2507.00665, 2025
Sihang Li, Wei Shi, Ziyuan Xie, Tao Liang, Guojun Ma, and Xiang Wang. Safer: Probing safety in reward models with sparse autoencoder.arXiv preprint arXiv:2507.00665, 2025
-
[19]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods.arXiv preprint arXiv:2109.07958, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy
Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, Jujie He, Jiacai Liu, Chaojie Wang, Rui Yan, Wei Shen, Fuxiang Zhang, Jiacheng Xu, et al. Skywork-reward-v2: Scaling preference data curation via human-ai synergy.arXiv preprint arXiv:2507.01352, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Sae-v: Interpreting multimodal models for enhanced alignment.arXiv preprint arXiv:2502.17514, 2025
Hantao Lou, Changye Li, Jiaming Ji, and Yaodong Yang. Sae-v: Interpreting multimodal models for enhanced alignment.arXiv preprint arXiv:2502.17514, 2025
-
[22]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[23]
The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models
Alexander Pan, Kush Bhatia, and Jacob Steinhardt. The effects of reward misspecification: Mapping and mitigating misaligned models.arXiv preprint arXiv:2201.03544, 2022
work page internal anchor Pith review arXiv 2022
-
[24]
Improving Dictionary Learning with Gated Sparse Autoencoders
Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, J´anos Kram´ar, Rohin Shah, and Neel Nanda. Improving dictionary learning with gated sparse autoencoders.arXiv preprint arXiv:2404.16014, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Alexandre Rame, Guillaume Couairon, Corentin Dancette, Jean-Baptiste Gaya, Mustafa Shukor, Laure Soulier, and Matthieu Cord. Rewarded soups: towards pareto-optimal align- ment by interpolating weights fine-tuned on diverse rewards.Advances in Neural Information Processing Systems, 36:71095–71134, 2023
work page 2023
-
[26]
Universal jailbreak backdoors from poisoned human feed- back.arXiv preprint arXiv:2311.14455, 2023
Javier Rando and Florian Tram `er. Universal jailbreak backdoors from poisoned human feed- back.arXiv preprint arXiv:2311.14455, 2023
-
[27]
Toward causal representation learning.Proceedings of the IEEE, 109(5):612–634, 2021
Bernhard Sch ¨olkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, and Yoshua Bengio. Toward causal representation learning.Proceedings of the IEEE, 109(5):612–634, 2021
work page 2021
-
[28]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Towards Understanding Sycophancy in Language Models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, et al. Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
The trickle-down impact of reward (in-) consistency on rlhf.arXiv preprint arXiv:2309.16155, 2023
Lingfeng Shen, Sihao Chen, Linfeng Song, Lifeng Jin, Baolin Peng, Haitao Mi, Daniel Khashabi, and Dong Yu. The trickle-down impact of reward (in-) consistency on rlhf.arXiv preprint arXiv:2309.16155, 2023
-
[31]
A long way to go: Investigating length correlations in rlhf.arXiv preprint arXiv:2310.03716,
Prasann Singhal, Tanya Goyal, Jiacheng Xu, and Greg Durrett. A long way to go: Investigating length correlations in rlhf.arXiv preprint arXiv:2310.03716, 2023. 11
-
[32]
Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and char- acterizing reward gaming.Advances in Neural Information Processing Systems, 35:9460– 9471, 2022
work page 2022
-
[33]
Adversarial visual robustness by causal intervention.arXiv preprint arXiv:2106.09534, 2021
Kaihua Tang, Mingyuan Tao, and Hanwang Zhang. Adversarial visual robustness by causal intervention.arXiv preprint arXiv:2106.09534, 2021
-
[34]
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, and Tom Henighan. Scaling monosema...
work page 2024
-
[35]
Jeremy Tien, Jerry Zhi-Yang He, Zackory Erickson, Anca D Dragan, and Daniel S Brown. Causal confusion and reward misidentification in preference-based reward learning.arXiv preprint arXiv:2204.06601, 2022
-
[36]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Chaoqi Wang, Zhuokai Zhao, Yibo Jiang, Zhaorun Chen, Chen Zhu, Yuxin Chen, Jiayi Liu, Lizhu Zhang, Xiangjun Fan, Hao Ma, et al. Beyond reward hacking: Causal rewards for large language model alignment.arXiv preprint arXiv:2501.09620, 2025
-
[38]
Jiongxiao Wang, Junlin Wu, Muhao Chen, Yevgeniy V orobeychik, and Chaowei Xiao. Rl- hfpoison: Reward poisoning attack for reinforcement learning with human feedback in large language models.arXiv preprint arXiv:2311.09641, 2023
-
[39]
Fundamental limitations of alignment in large language models,
Yotam Wolf, Noam Wies, Oshri Avnery, Yoav Levine, and Amnon Shashua. Fundamental limitations of alignment in large language models.arXiv preprint arXiv:2304.11082, 2023
-
[40]
Preference poisoning attacks on reward model learning
Junlin Wu, Jiongxiao Wang, Chaowei Xiao, Chenguang Wang, Ning Zhang, and Yevgeniy V orobeychik. Preference poisoning attacks on reward model learning. In2025 IEEE Sympo- sium on Security and Privacy (SP), pages 1622–1640. IEEE, 2025
work page 2025
-
[41]
Interpretable reward model via sparse autoencoder.arXiv preprint arXiv:2508.08746, 2025
Shuyi Zhang, Wei Shi, Sihang Li, Jiayi Liao, Hengxing Cai, and Xiang Wang. Interpretable reward model via sparse autoencoder.arXiv preprint arXiv:2508.08746, 2025
-
[42]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engi- neering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023. 12 Appendix Overview A Additional Experimental Details. . . . . . . . . . . . . . . . . . . . . . . ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
In LLMs, reward models learn shallow prox- ies instead of causal intent [29], with Casper et al
showed scaling laws for reward overoptimization. In LLMs, reward models learn shallow prox- ies instead of causal intent [29], with Casper et al. [5] cataloguing RLHF’s failure modes. Models reward keywords, sycophancy, or length regardless of quality [37, 31]. These superficial features enable manipulation via poisoning attacks that embed backdoors throu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.