ASSCG: Just-Right Gating over Chattering for Fast-Slow LLM Planning in Autonomous Driving
Pith reviewed 2026-06-25 21:18 UTC · model grok-4.3
The pith
A trainable gate learns per-frame Query, Cache or Drop actions to control when slow LLM guidance is used in driving planners.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that an Adaptive Slow-System Control Gate using an RWKV backbone, trained first by supervised fine-tuning and then by GRPO-style compute-aware reinforcement learning, produces Query/Cache/Drop policies that outperform hand-designed triggering rules, yielding higher scores at reduced end-to-end latency when the gate is integrated into existing fast-slow LLM planners for autonomous driving.
What carries the argument
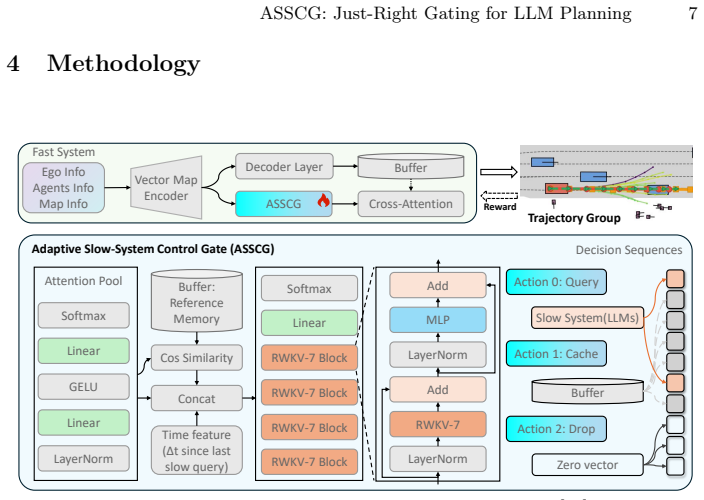
The Adaptive Slow-System Control Gate (ASSCG), an RWKV-based module that outputs frame-level Query, Cache, or Drop decisions to manage slow-system invocations.
If this is right
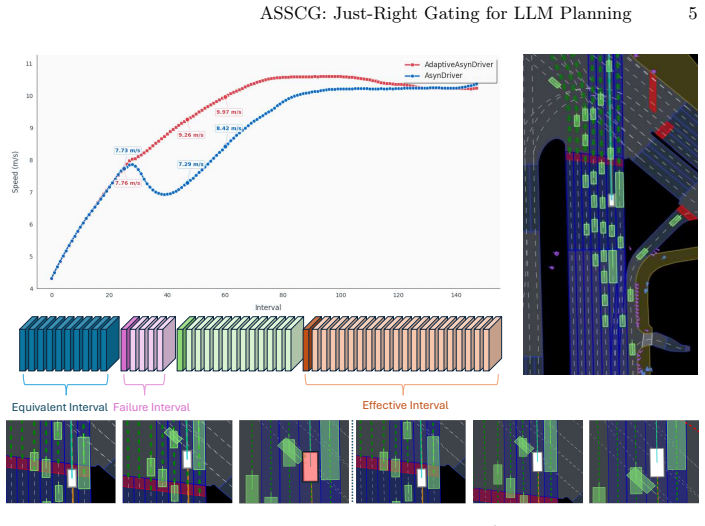
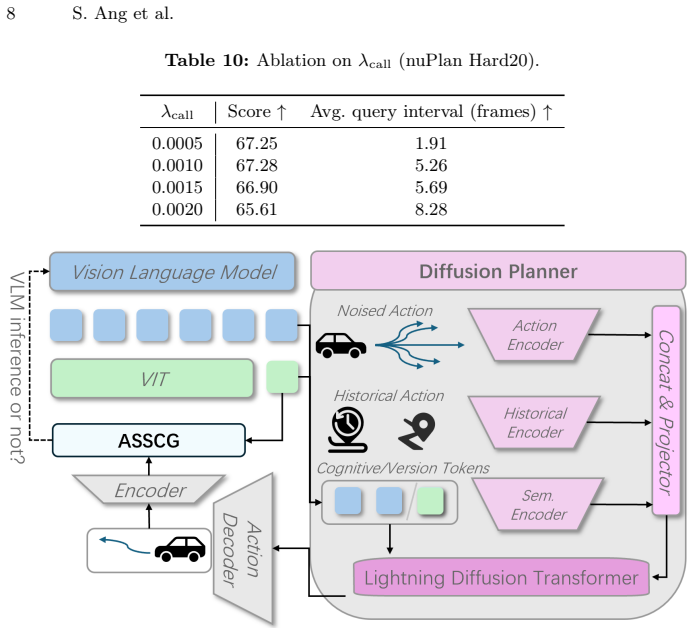
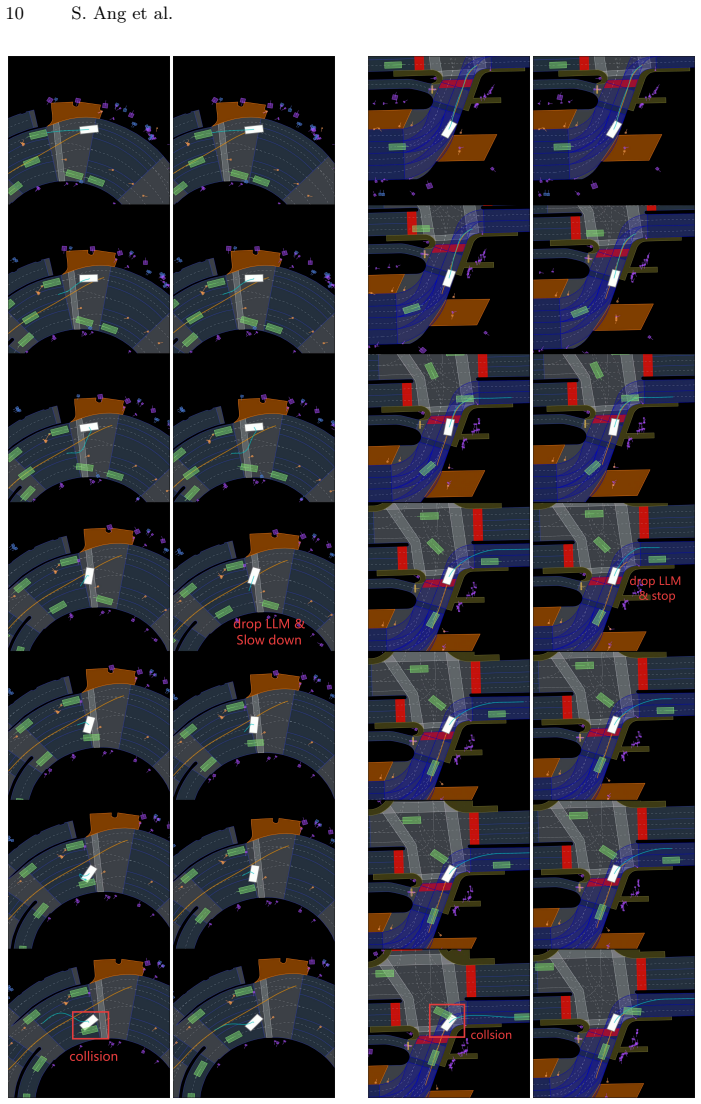
- On AsyncDriver with nuPlan Hard20 the gate raises the planning score while cutting average inference latency by 60 percent.
- On the modified RecogDrive system with NAVSIM the gate raises PDMS score and increases average vehicle speed by 25 percent.
- The same gate architecture transfers across two distinct fast-slow planner designs without architecture-specific redesign.
- Training via supervised fine-tuning followed by compute-aware reinforcement learning produces stable long-horizon gating policies.
Where Pith is reading between the lines
- Similar learned gates could be applied to other domains where an expensive slow model must be invoked sparingly inside a fast loop.
- The Query/Cache/Drop formulation might generalize to any sequential control task that trades off expensive inference against action quality.
- If the learned policies prove robust outside the training distribution, hand-crafted triggering logic could be replaced in additional LLM-augmented systems.
- The compute-aware reinforcement stage offers a template for training efficiency-sensitive policies in other real-time AI applications.
Load-bearing premise
The RWKV-based gate trained by supervised fine-tuning followed by compute-aware reinforcement learning can discover Query/Cache/Drop policies that beat hand-designed rules on the target driving benchmarks without instability or loss of generalization.
What would settle it
Evaluating the ASSCG-augmented planners on nuPlan Hard20 and NAVSIM and finding no gain in planning score or no reduction in latency relative to the original hand-designed baselines.
Figures

read the original abstract
Large language models (LLMs) can improve autonomous driving planning but are costly to query online, and existing fast-slow planners often rely on hand-designed triggering rules that either over-call the slow system or call it at the wrong times. We formulate slow-system invocation as a resource-aware sequential decision problem and propose the Adaptive Slow-System Control Gate (ASSCG), which makes frame-level Query/Cache/Drop decisions to refresh, reuse, or suppress slow guidance. ASSCG uses an RWKV backbone for efficient long-horizon gating and is trained with supervised fine-tuning followed by GRPO-style compute-aware reinforcement fine-tuning. We apply ASSCG to two different fast-slow architectures: (i) AsyncDriver on nuPlan Hard20 closed-loop evaluation, where ASSCG improves score to 67.28 (+2.28) while reducing average end-to-end inference latency by 60%; and (ii) a RecogDrive-based dual system that we build by replacing its original VLM-2B module with a lightweight ViT-based fast planner and adding an LLM slow planner, evaluated on NAVSIM, where ASSCG achieves 91.4 PDMS (+0.6) and increases average speed by 25%. The project page, including video visualizations and additional results, is available at https://williamxuanyu.github.io/asscg/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ASSCG, an RWKV-based Adaptive Slow-System Control Gate that makes per-frame Query/Cache/Drop decisions for invoking or suppressing slow LLM guidance in fast-slow autonomous driving planners. Trained first via supervised fine-tuning then GRPO-style compute-aware reinforcement learning, ASSCG is applied to AsyncDriver on nuPlan Hard20 (score 67.28, +2.28; 60% lower latency) and a modified RecogDrive system on NAVSIM (91.4 PDMS, +0.6; 25% higher speed), claiming to avoid the over- or under-triggering of hand-designed rules.
Significance. If the attribution of gains to the learned long-horizon policy holds after proper controls, the work would offer a practical, resource-aware alternative to heuristic triggering in LLM-augmented planners, with potential for lower latency at comparable or better closed-loop performance on established benchmarks.
major comments (2)
- [Experiments] Experiments section (and abstract): the headline deltas (67.28 on nuPlan Hard20, 91.4 PDMS on NAVSIM) are reported without an ablation that holds the fast planner, slow planner, and evaluation protocol fixed while swapping only the gating mechanism (ASSCG vs. the original hand-designed rules). Without this comparison the performance improvement cannot be attributed to the learned RWKV policy rather than other implementation changes.
- [Training] Training and results sections: no comparison is provided between the full SFT+GRPO pipeline and an SFT-only baseline (or a compute-aware RL variant). This leaves open whether the reinforcement stage is responsible for any of the reported latency or score gains.
minor comments (2)
- Abstract and experimental reporting: no error bars, number of runs, statistical tests, or list of baselines appear in the provided summary of results; these details should be added for reproducibility.
- The project page is referenced but no link to code or exact hyper-parameters for the RWKV gate and GRPO reward is given in the manuscript excerpt; including these would strengthen the contribution.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which highlight important aspects for strengthening the attribution of our results. We provide point-by-point responses below and will make the necessary revisions to the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and abstract): the headline deltas (67.28 on nuPlan Hard20, 91.4 PDMS on NAVSIM) are reported without an ablation that holds the fast planner, slow planner, and evaluation protocol fixed while swapping only the gating mechanism (ASSCG vs. the original hand-designed rules). Without this comparison the performance improvement cannot be attributed to the learned RWKV policy rather than other implementation changes.
Authors: We agree with the referee that a controlled experiment isolating the effect of the gating mechanism is necessary to firmly attribute the performance gains to ASSCG rather than other factors. The current manuscript reports results on systems where ASSCG replaces the original triggering rules, but does not present a direct side-by-side comparison under identical fast/slow planners and protocols. We will add this ablation study to the Experiments section in the revised manuscript, reporting the metrics for the hand-designed rules baseline alongside ASSCG. revision: yes
-
Referee: [Training] Training and results sections: no comparison is provided between the full SFT+GRPO pipeline and an SFT-only baseline (or a compute-aware RL variant). This leaves open whether the reinforcement stage is responsible for any of the reported latency or score gains.
Authors: The referee correctly notes the absence of an SFT-only baseline. While the manuscript describes the full training pipeline and its results, it does not include a comparison to supervised fine-tuning alone. To address this, we will incorporate results from an SFT-only model in the revised Training and Results sections to demonstrate the additional benefits provided by the GRPO-style reinforcement learning stage. revision: yes
Circularity Check
No derivation chain present; results are empirical benchmark outcomes
full rationale
The manuscript formulates ASSCG as an RWKV-based gating policy trained via SFT followed by compute-aware RL and evaluates it on nuPlan Hard20 and NAVSIM, reporting concrete metric deltas (67.28 score, 60% latency reduction, 91.4 PDMS). No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The performance claims rest on external closed-loop benchmarks rather than any reduction of outputs to inputs by construction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2310.02071 (2023)
Chen,L.,Zhang,Y.,Ren,S.,Zhao,H.,Cai,Z.,Wang,Y.,Wang,P.,Liu,T.,Chang, B.: Towards end-to-end embodied decision making via multi-modal large language model: Explorations with gpt4-vision and beyond. arXiv preprint arXiv:2310.02071 (2023)
arXiv 2023
-
[2]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Chen, L., Sinavski, O., Hünermann, J., Karnsund, A., Willmott, A.J., Birch, D., Maund, D., Shotton, J.: Driving with llms: Fusing object-level vector modality for explainable autonomous driving. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 14093–14100. IEEE (2024)
2024
-
[3]
In: European Confer- ence on Computer Vision
Chen, Y., Ding, Z.h., Wang, Z., Wang, Y., Zhang, L., Liu, S.: Asynchronous large language model enhanced planner for autonomous driving. In: European Confer- ence on Computer Vision. pp. 22–38. Springer (2024)
2024
-
[4]
arXiv preprint arXiv:2412.18607 (2024)
Chen, Y., Wang, Y., Zhang, Z.: Drivinggpt: Unifying driving world model- ing and planning with multi-modal autoregressive transformers. arXiv preprint arXiv:2412.18607 (2024)
arXiv 2024
-
[5]
arXiv preprint arXiv:2404.14327 (2024)
Cheng, J., Chen, Y., Chen, Q.: Pluto: Pushing the limit of imitation learning-based planning for autonomous driving. arXiv preprint arXiv:2404.14327 (2024)
arXiv 2024
-
[6]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Cheng, J., Chen, Y., Mei, X., Yang, B., Li, B., Liu, M.: Rethinking imitation- based planners for autonomous driving. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 14123–14130. IEEE (2024)
2024
-
[7]
IEEE Trans- actions on Pattern Analysis and Machine Intelligence45(11), 12878–12895 (2022)
Chitta, K., Prakash, A., Jaeger, B., Yu, Z., Renz, K., Geiger, A.: Transfuser: Imi- tation with transformer-based sensor fusion for autonomous driving. IEEE Trans- actions on Pattern Analysis and Machine Intelligence45(11), 12878–12895 (2022)
2022
-
[8]
IEEE Intelligent Transportation Systems Magazine16(4), 81–94 (2024)
Cui, C., Ma, Y., Cao, X., Ye, W., Wang, Z.: Receive, reason, and react: Drive as you say, with large language models in autonomous vehicles. IEEE Intelligent Transportation Systems Magazine16(4), 81–94 (2024)
2024
-
[9]
In: Conference on Robot Learning
Dauner, D., Hallgarten, M., Geiger, A., Chitta, K.: Parting with misconceptions about learning-based vehicle motion planning. In: Conference on Robot Learning. pp. 1268–1281. PMLR (2023)
2023
-
[10]
In: 2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW)
Fu, D., Li, X., Wen, L., Dou, M., Cai, P., Shi, B., Qiao, Y.: Drive like a human: Rethinking autonomous driving with large language models. In: 2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW). pp. 910–919. IEEE (2024)
2024
-
[11]
Caesar, J
H. Caesar, J. Kabzan, K.T.e.a.: Nuplan: A closed-loop ml-based planning bench- mark for autonomous vehicles. In: CVPR ADP3 workshop (2021)
2021
-
[12]
In: 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC)
Hallgarten, M., Stoll, M., Zell, A.: From prediction to planning with goal con- ditioned lane graph traversals. In: 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC). pp. 951–958. IEEE (2023)
2023
-
[13]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Han, W., Guo, D., Xu, C.Z., Shen, J.: Dme-driver: Integrating human decision logic and 3d scene perception in autonomous driving. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 3347–3355 (2025)
2025
-
[14]
In: European Conference on Computer Vision
Hu, Y., Chai, S., Yang, Z., Qian, J., Li, K., Shao, W., Zhang, H., Xu, W., Liu, Q.: Solving motion planning tasks with a scalable generative model. In: European Conference on Computer Vision. pp. 386–404. Springer (2024)
2024
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., et al.: Planning-oriented autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17853– 17862 (2023) ASSCG: Just-Right Gating for LLM Planning 17
2023
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Huang, Z., Liu, H., Lv, C.: Gameformer: Game-theoretic modeling and learning of transformer-based interactive prediction and planning for autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3903–3913 (2023)
2023
-
[17]
arXiv preprint arXiv:2508.11428 (2025)
Li, J., Zhang, B., Jin, X., Deng, J., Zhu, X., Zhang, L.: Imagidrive: A uni- fied imagination-and-planning framework for autonomous driving. arXiv preprint arXiv:2508.11428 (2025)
arXiv 2025
-
[18]
arXiv preprint arXiv:2510.12796 (2025)
Li, Y., Shang, S., Liu, W., Zhan, B., Wang, H., Wang, Y., Chen, Y., Wang, X., An, Y., Tang, C., et al.: Drivevla-w0: World models amplify data scaling law in autonomous driving. arXiv preprint arXiv:2510.12796 (2025)
Pith/arXiv arXiv 2025
-
[19]
arXiv preprint arXiv:2504.01941 (2025)
Li, Y., Wang, Y., Liu, Y., He, J., Fan, L., Zhang, Z.: End-to-end driving with online trajectory evaluation via bev world model. arXiv preprint arXiv:2504.01941 (2025)
arXiv 2025
-
[20]
arXiv preprint arXiv:2506.08052 (2025)
Li, Y., Xiong, K., Guo, X., Li, F., Yan, S., Xu, G., Zhou, L., Chen, L., Sun, H., Wang, B., et al.: Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving. arXiv preprint arXiv:2506.08052 (2025)
Pith/arXiv arXiv 2025
-
[21]
arXiv preprint arXiv:2406.06978 (2024)
Li, Z., Li, K., Wang, S., Lan, S., Yu, Z., Ji, Y., Li, Z., Zhu, Z., Kautz, J., Wu, Z., et al.: Hydra-mdp: End-to-end multimodal planning with multi-target hydra- distillation. arXiv preprint arXiv:2406.06978 (2024)
Pith/arXiv arXiv 2024
-
[22]
arXiv preprint arXiv:2411.15139 (2024)
Liao, B., Chen, S., Yin, H., Jiang, B., Wang, C., Yan, S., Zhang, X., Li, X., Zhang, Y., Zhang, Q., et al.: Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. arXiv preprint arXiv:2411.15139 (2024)
arXiv 2024
-
[23]
arXiv preprint arXiv:2305.13048 (2023)
Peng, B., Alcaide, E., Anthony, Q., Albalak, A., Arcadinho, S., Biderman, S., Cao, H., Cheng, X., Chung, M., Grella, M., et al.: Rwkv: Reinventing rnns for the transformer era. arXiv preprint arXiv:2305.13048 (2023)
Pith/arXiv arXiv 2023
-
[24]
arXiv preprint arXiv:2411.18013 (2024)
Qian,K.,Ma,Z.,He,Y.,Luo,Z.,Shi,T.,Zhu,T.,Li,J.,Wang,J.,Chen,Z.,He,X., et al.: Fasionad: Fast and slow fusion thinking systems for human-like autonomous driving with adaptive feedback. arXiv preprint arXiv:2411.18013 (2024)
arXiv 2024
-
[25]
In: Con- ference on Robot Learning
Scheel, O., Bergamini, L., Wolczyk, M., Osiński, B., Ondruska, P.: Urban driver: Learning to drive from real-world demonstrations using policy gradients. In: Con- ference on Robot Learning. pp. 718–728. PMLR (2022)
2022
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shao, H., Hu, Y., Wang, L., Song, G., Waslander, S.L., Liu, Y., Li, H.: Lmdrive: Closed-loop end-to-end driving with large language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15120– 15130 (2024)
2024
-
[27]
arXiv preprint arXiv:2402.03300 (2024)
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
Pith/arXiv arXiv 2024
-
[28]
arXiv preprint arXiv:2401.00125 (2023)
Sharan, S., Pittaluga, F., Chandraker, M., et al.: Llm-assist: Enhancing closed-loop planning with language-based reasoning. arXiv preprint arXiv:2401.00125 (2023)
arXiv 2023
-
[29]
arXiv preprint arXiv:2507.20342 (2025)
Tang, Z., Zhang, S., Deng, J., Wang, C., You, G., Huang, Y., Lin, X., Zhang, Y.: Vlmplanner: Integrating visual language models with motion planning. arXiv preprint arXiv:2507.20342 (2025)
arXiv 2025
-
[30]
arXiv preprint arXiv:2402.12289 (2024)
Tian, X., Gu, J., Li, B., Liu, Y., Wang, Y., Zhao, Z., Zhan, K., Jia, P., Lang, X., Zhao, H.: Drivevlm: The convergence of autonomous driving and large vision- language models. arXiv preprint arXiv:2402.12289 (2024)
Pith/arXiv arXiv 2024
-
[31]
Physical review E62(2), 1805 (2000)
Treiber, M., Hennecke, A., Helbing, D.: Congested traffic states in empirical ob- servations and microscopic simulations. Physical review E62(2), 1805 (2000)
2000
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Weng, X., Ivanovic, B., Wang, Y., Wang, Y., Pavone, M.: Para-drive: Parallelized architecture for real-time autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15449–15458 (2024) 18 S. Ang et al
2024
-
[33]
In: Proceedings of the AAAI Conference on Arti- ficial Intelligence
Wu, D., Han, W., Liu, Y., Wang, T., Xu, C.z., Zhang, X., Shen, J.: Language prompt for autonomous driving. In: Proceedings of the AAAI Conference on Arti- ficial Intelligence. vol. 39, pp. 8359–8367 (2025)
2025
-
[34]
arXiv preprint arXiv:2512.11872 (2025)
Xu, M., Cui, J., Cai, F., Shang, H., Zhu, Z., Luan, S., Xu, Y., Zhang, N., Li, Y., Cai, J., et al.: Wam-diff: A masked diffusion vla framework with moe and online reinforcement learning for autonomous driving. arXiv preprint arXiv:2512.11872 (2025)
arXiv 2025
-
[35]
IEEE Robotics and Automation Letters (2024)
Xu, Z., Zhang, Y., Xie, E., Zhao, Z., Guo, Y., Wong, K.Y.K., Li, Z., Zhao, H.: Drivegpt4: Interpretable end-to-end autonomous driving via large language model. IEEE Robotics and Automation Letters (2024)
2024
-
[36]
Yao, R., Wang, Y., Liu, H., Yang, R., Peng, Z., Zhu, L., Ma, J.: Calmm-drive: Confidence-awareautonomousdrivingwithlargemultimodalmodel.arXivpreprint arXiv:2412.04209 (2024)
arXiv 2024
-
[37]
arXiv preprint arXiv:2408.03601 (2024)
Yuan, C., Zhang, Z., Sun, J., Sun, S., Huang, Z., Lee, C.D.W., Li, D., Han, Y., Wong, A., Tee, K.P., et al.: Drama: An efficient end-to-end motion planner for autonomous driving with mamba. arXiv preprint arXiv:2408.03601 (2024)
arXiv 2024
-
[38]
arXiv preprint arXiv:2402.10828 (2024)
Yuan, J., Sun, S., Omeiza, D., Zhao, B., Newman, P., Kunze, L., Gadd, M.: Rag-driver:Generalisabledrivingexplanationswithretrieval-augmentedin-context learning in multi-modal large language model. arXiv preprint arXiv:2402.10828 (2024)
arXiv 2024
-
[39]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision
Zhang, R., Xie, J., Zhang, W., Chen, W., Tan, X., Wan, X., Li, G.: Adadrive: Self- adaptive slow-fast system for language-grounded autonomous driving. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision. pp. 5112– 5121 (2025)
2025
-
[40]
Zhang, Y., Zhang, S., Zhang, Y., Ji, J., Duan, Y., Huang, Y., Peng, J., Zahng, Y.: Multi-modality fusion perception and computing in autonomous driving. J. Comput. Res. Dev57, 1781–1799 (2020)
2020
-
[41]
arXiv preprint arXiv:2503.07485 (2025)
Zhang, Z., Li, X., Zou, S., Chi, G., Li, S., Qiu, X., Wang, G., Zheng, G., Wang, L., Zhao, H., et al.: Chameleon: Fast-slow neuro-symbolic lane topology extraction. arXiv preprint arXiv:2503.07485 (2025)
arXiv 2025
-
[42]
arXiv preprint arXiv:2406.01587 (2024)
Zheng, Y., Xing, Z., Zhang, Q., Jin, B., Li, P., Zheng, Y., Xia, Z., Zhan, K., Lang, X., Chen, Y., et al.: Planagent: A multi-modal large language agent for closed-loop vehicle motion planning. arXiv preprint arXiv:2406.01587 (2024)
arXiv 2024
-
[43]
arXiv preprint arXiv:2506.13757 (2025)
Zhou, Z., Cai, T., Zhao, S.Z., Zhang, Y., Huang, Z., Zhou, B., Ma, J.: Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning. arXiv preprint arXiv:2506.13757 (2025)
Pith/arXiv arXiv 2025
-
[44]
Zou, J., Chen, S., Liao, B., Zheng, Z., Song, Y., Zhang, L., Zhang, Q., Liu, W., Wang, X.: Diffusiondrivev2: Reinforcement learning-constrained truncated diffu- sion modeling in end-to-end autonomous driving. arXiv preprint arXiv:2512.07745 (2025) ASSCG: Just-Right Gating for LLM Planning 1 A Per-type fixed-schedule grid search on nuPlan Hard20 We provide...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.