Your Mouse and Eyes Secretly Leak Your Preference: LLM Alignment using Implicit Feedback from Users
Pith reviewed 2026-06-26 17:24 UTC · model grok-4.3
The pith
Implicit feedback from mouse trajectories and eye gaze improves LLM reward models from 55 percent to 64 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A reward model trained on implicit user feedback collected as mouse trajectories and eye-gaze points during response reading outperforms a text-only reward model, raising preference-prediction accuracy from 55 percent to 64 percent and nearly tripling the relative response-quality gains obtained after Direct Preference Optimization on eight LLMs.
What carries the argument
IFLLM dataset and multimodal reward model that fuses mouse-trajectory and eye-gaze features with response text to predict user preference.
If this is right
- Preference data for alignment can be gathered at scale without prompting users for explicit ratings.
- Direct Preference Optimization yields substantially larger gains when the reward model incorporates implicit signals.
- Diverse gazing and mouse behaviors across users can be aggregated into a single improved reward function.
- The same implicit signals could be collected continuously during normal LLM use rather than in dedicated annotation sessions.
Where Pith is reading between the lines
- Continuous collection of mouse and eye data during live interactions could support ongoing model updates without separate feedback campaigns.
- Privacy and consent mechanisms would need to be addressed before deploying such tracking at internet scale.
- Similar implicit signals might be captured from other interfaces such as touch or scroll patterns on mobile devices.
Load-bearing premise
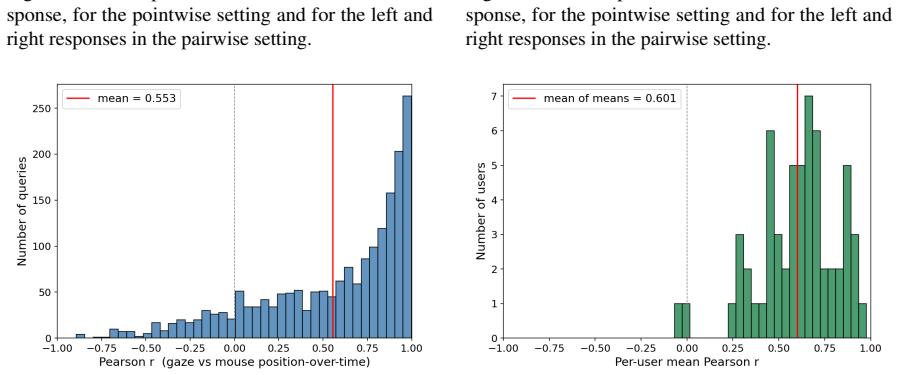
The mouse and eye signals gathered from 59 paid Mechanical Turk workers reliably reflect genuine preferences and will appear the same way for ordinary users in real deployments.
What would settle it
Run the same data-collection protocol with a larger and more diverse unpaid user pool and measure whether the implicit-feedback reward model still outperforms the text-only baseline by the reported margin.
Figures





read the original abstract
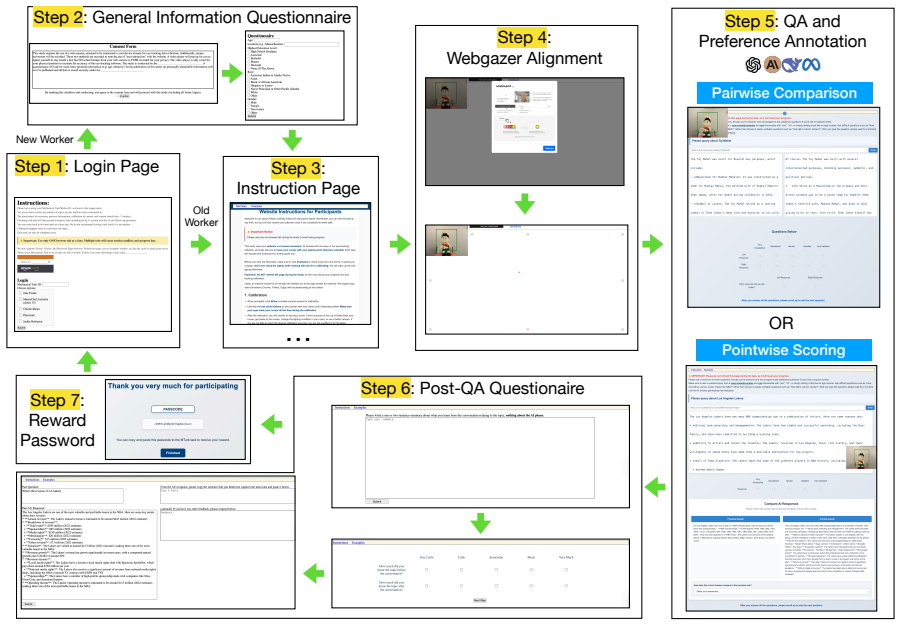
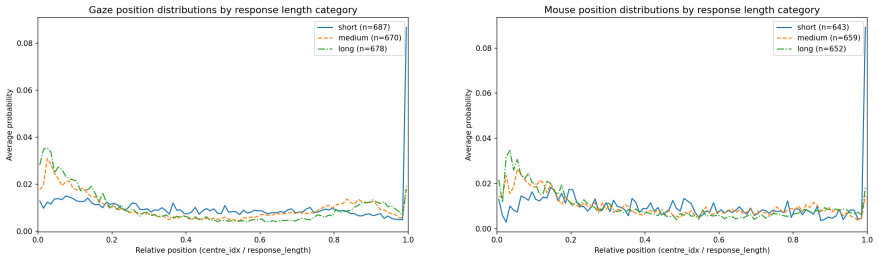
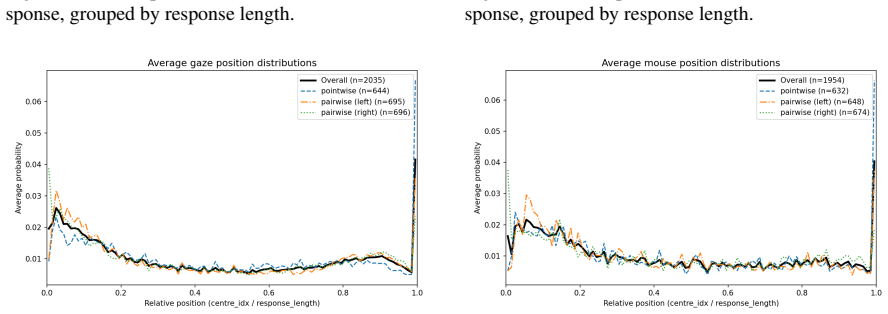
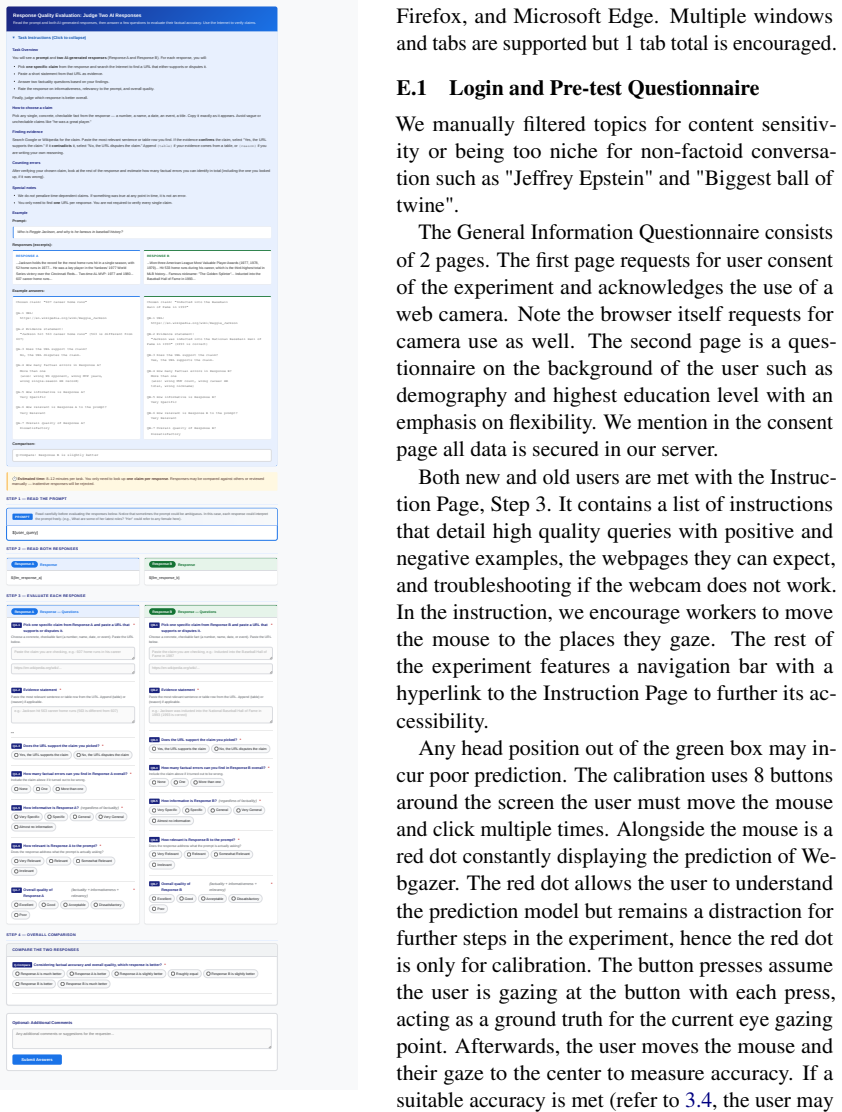
To align a Large Language Model (LLM), most existing methods collect explicit human feedback and train a reward model to predict the human preference based on the response text. These existing methods have two key limitations. First, the users rarely provide explicit feedback for LLM responses, which makes the high-quality preference annotation expensive to collect. Second, the methods do not leverage implicit human feedback, which has proven vital to the economic moats of Internet giants. To quantify the value of implicit feedback, we build a new dataset called IFLLM, which collects 1336 multi-turn questions from the 59 Mechanical Turk workers, their mouse trajectories, and eye gazing points to the LLMs' responses from their webcams. IFLLM shows that the users have very diverse types of gazing behavior and mouse trajectories. Our reward model based on the implicit user feedback boosts the accuracy of the text-based reward model from 55% to 64% and nearly triples the relative response quality improvements after applying the DPO to eight LLMs, demonstrating the value of implicit feedback in the wild. Our data collection website, dataset, and codes can be found at https://github.com/themehulpatwari/llm-implicit-feedback/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the IFLLM dataset, collected from 59 Mechanical Turk workers across 1336 multi-turn interactions, capturing mouse trajectories and webcam-based eye gaze points alongside LLM responses. It claims that a reward model trained on this implicit feedback improves text-only reward model accuracy from 55% to 64% and nearly triples relative response quality gains when used to train DPO on eight LLMs, arguing for the value of implicit signals 'in the wild.' The authors release the dataset, collection website, and code.
Significance. If the implicit signals are shown to reliably proxy genuine preferences and generalize beyond the small paid sample, the work would meaningfully reduce reliance on expensive explicit annotations for LLM alignment while demonstrating a practical way to leverage natural user behavior, akin to implicit signals in web systems. The public release of IFLLM, the website, and code is a clear strength that enables direct reproducibility and follow-on studies.
major comments (3)
- [Data collection / §4] Data collection and evaluation sections: The headline accuracy lift (55% o 64%) and DPO gains rest on signals from only 59 MTurk workers with no reported cross-user hold-out, cohort-level validation, or direct comparison against explicit preference labels collected on the same turns; this leaves open whether the 9-point improvement reflects robust implicit preference or sample-specific artifacts.
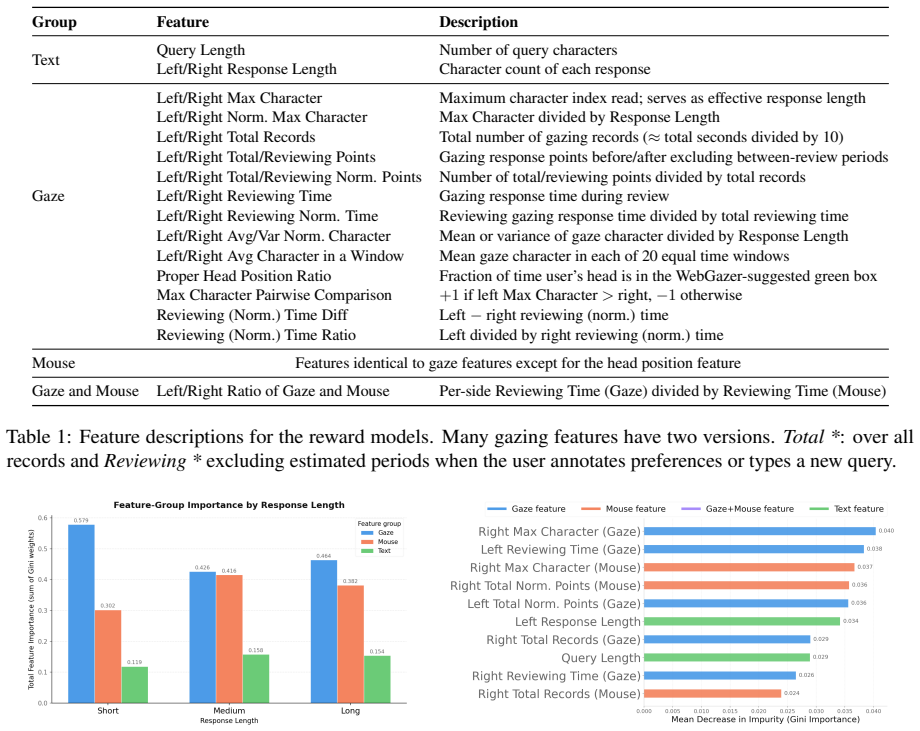
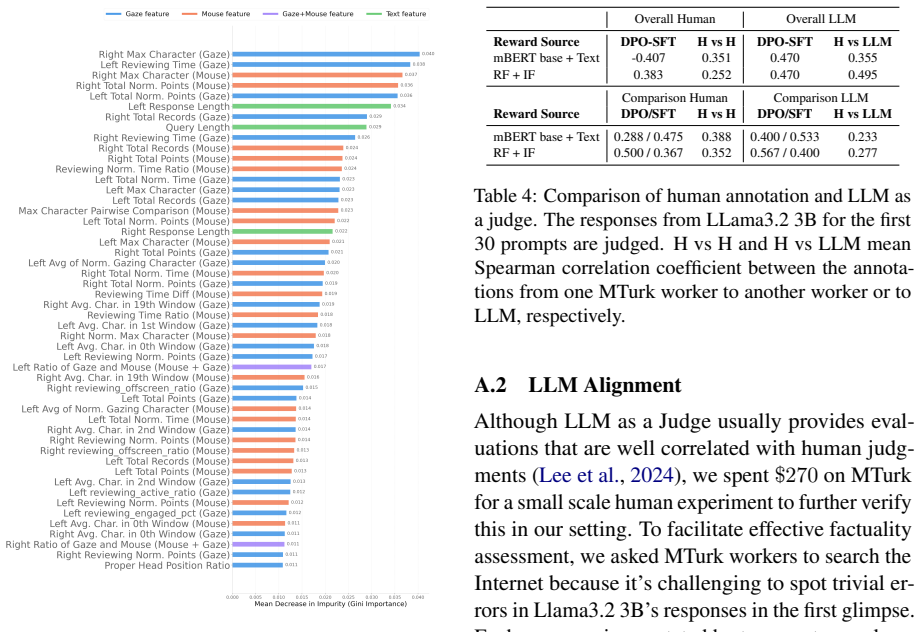
- [Reward model / §5] Reward model section: The manuscript states the accuracy improvement but supplies no description of the reward-model architecture, the precise feature extraction pipeline from mouse trajectories and gaze points, or any statistical significance testing or controls for confounds such as reading time or interface effects.
- [DPO experiments / §6] DPO experiments: The claim that implicit feedback 'nearly triples' quality improvements across eight LLMs lacks details on the exact evaluation protocol, baseline definitions, or human evaluation rubric, making it impossible to assess whether the tripling is robust or driven by the particular reward model.
minor comments (2)
- [Abstract] Abstract: The phrase 'nearly triples the relative response quality improvements' is imprecise; reporting the exact relative gain and the underlying metric would improve clarity.
- [Dataset description] The paper would benefit from a table summarizing the 1336 interactions (e.g., turns per worker, average trajectory length) to allow readers to gauge data scale and diversity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to supply the requested details where feasible.
read point-by-point responses
-
Referee: [Data collection / §4] Data collection and evaluation sections: The headline accuracy lift (55% to 64%) and DPO gains rest on signals from only 59 MTurk workers with no reported cross-user hold-out, cohort-level validation, or direct comparison against explicit preference labels collected on the same turns; this leaves open whether the 9-point improvement reflects robust implicit preference or sample-specific artifacts.
Authors: The study collected data from 59 workers across 1336 interactions, which we present as an initial demonstration of implicit signals in the wild. The revised version will add user-level cross-validation results to test for cohort-specific effects. Explicit preference labels were not collected on the same turns, preventing a direct paired comparison. revision: partial
-
Referee: [Reward model / §5] Reward model section: The manuscript states the accuracy improvement but supplies no description of the reward-model architecture, the precise feature extraction pipeline from mouse trajectories and gaze points, or any statistical significance testing or controls for confounds such as reading time or interface effects.
Authors: We agree these technical details are absent from the current text. The revision will expand the reward-model section with the architecture, feature extraction pipeline, significance testing, and confound controls. revision: yes
-
Referee: [DPO experiments / §6] DPO experiments: The claim that implicit feedback 'nearly triples' quality improvements across eight LLMs lacks details on the exact evaluation protocol, baseline definitions, or human evaluation rubric, making it impossible to assess whether the tripling is robust or driven by the particular reward model.
Authors: The revision will provide the full evaluation protocol, baseline definitions, and human evaluation rubric used for the DPO quality measurements across the eight models. revision: yes
- Direct comparison against explicit preference labels collected on the same turns, as this paired data was not gathered in the original study.
Circularity Check
No significant circularity; results are empirical measurements on newly collected data.
full rationale
The paper collects a fresh dataset (IFLLM) of 1336 interactions from 59 MTurk workers including mouse trajectories and webcam gaze, trains a reward model on these implicit signals, and reports accuracy gains (55% to 64%) plus DPO quality improvements on eight LLMs. These are direct empirical outcomes on the collected data rather than any derivation that reduces by construction to fitted parameters, self-citations, or renamed inputs. No equations, uniqueness theorems, or ansatzes are invoked that loop back to the paper's own definitions or prior author work. The central claims rest on external validation against text-only baselines and DPO runs, making the work self-contained against its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Reward model parameters
axioms (1)
- domain assumption Mouse trajectories and eye gaze points collected during response viewing correlate with user preferences for LLM outputs
Reference graph
Works this paper leans on
-
[1]
InInternational conference on machine learning, pages 2397–2430
Pythia: A suite for analyzing large language models across training and scaling. InInternational conference on machine learning, pages 2397–2430. PMLR. Anna Bondar, David Robert Reich, and Lena Ann Jäger. 2025a. Aleyegnment: Leveraging eye-tracking- while-reading to align language models with human preferences. InProceedings of the First International Wor...
Pith/arXiv arXiv 2025
-
[2]
Douglas W Oard and Jinliang Kim
International Joint Conferences on Artificial Intelligence Organization. Douglas W Oard and Jinliang Kim. 1998. Implicit feed- back for recommender systems. InAAAI Workshop on Recommender Systems, pages 81–85. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and ...
arXiv 1998
-
[3]
Ningzhi Tang, Junwen An, Meng Chen, Aakash Bansal, Yu Huang, Collin McMillan, and Toby Jia-Jun Li
A comparison of document clustering tech- niques. Ningzhi Tang, Junwen An, Meng Chen, Aakash Bansal, Yu Huang, Collin McMillan, and Toby Jia-Jun Li. 2024a. Codegrits: A research toolkit for developer behavior and eye tracking in ide. InProceedings of the 2024 ieee/acm 46th international conference on software engineering: Companion proceedings, pages 119–...
arXiv 2024
-
[4]
All claims are equal, but some claims are more equal than others: Importance-sensitive factu- ality evaluation of llm generations.arXiv preprint arXiv:2510.07083. Kun Yan, Zeyu Wang, Lei Ji, Yuntao Wang, Nan Duan, and Shuai Ma. 2024. V oila-a: Aligning vision- language models with user’s gaze attention.Ad- vances in neural information processing systems, ...
arXiv 2024
-
[5]
Instruction Following : Did the model follow all explicit and implicit instructions ?
-
[6]
Informativeness : Is the response comprehensive without being verbose ?
-
[7]
Factuality : Are the claims accurate ? For creative prompts , judge internal consistency
-
[8]
Clarity and Coherence : Is the response well - structured and easy to read ?
-
[9]
he was a great player
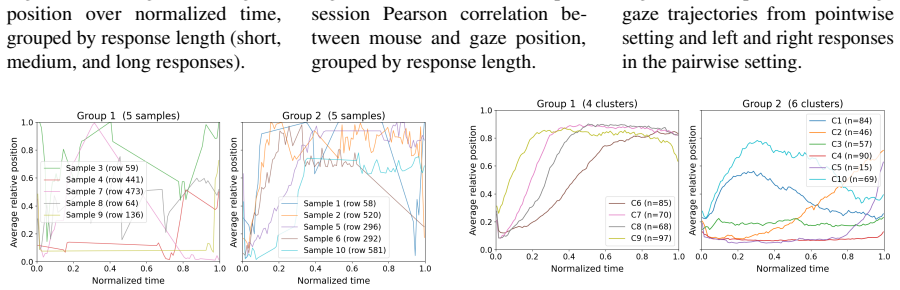
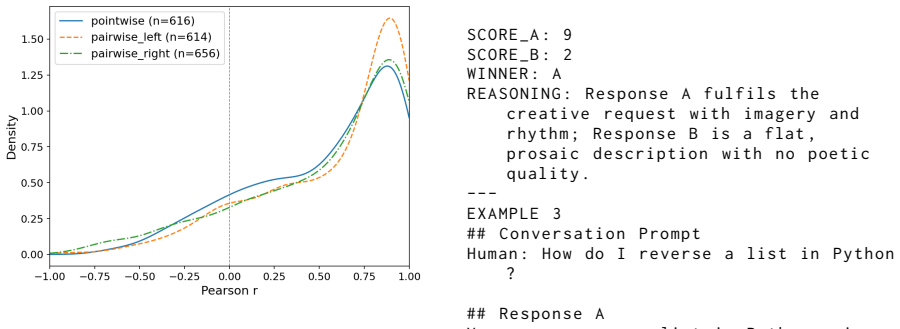
Overall Helpfulness : Which response Figure 25: Distribution of the per-session Pearson cor- relation between mouse and gaze position, for the point- wise setting and for the left and right responses in the pairwise setting. is more ready to use for the human ? You MUST always respond in EXACTLY this format ( no extra text , no markdown , no blank respons...
1977
-
[10]
Left-click the red circle buttons on your screen with your cursor until it becomes yellow
Calibration When prompted, click Allow to enable camera access for calibration. Left-click the red circle buttons on your screen with your cursor until it becomes yellow. Make sure your eyes track your cursor all the time during the calibration. After the calibration, you will receive an accuracy score. If your accuracy is low, try to better track your cu...
-
[11]
Interaction with AI You will be redirected to one of two tasks: General Guidelines for AI Interaction Each time you ask a question in the search box, the AI will respond in the box below. Please keep in mind that refreshing the page, switch to instruction page, or asking another question will delete the previous question and response on the screen, but th...
-
[12]
The summary should focus on what you learned on the topic and include nothing about the AI
Conversation Summary Summarize the conversation using one or two sentence(s) in the text box provided. The summary should focus on what you learned on the topic and include nothing about the AI. Click Submit to proceed to the next page
-
[13]
Copy the sentence you felt was most important and paste it into the provided box
Past Question and Response You will be shown a randomly chosen past question and the AI’s response. Copy the sentence you felt was most important and paste it into the provided box. (Optional) Add feedback in the Feedback Box if needed. Click Submit when you are done
-
[14]
Store this passcode somewhere safe and submit the passcode to MTurk to receive your payment
Payment Code A unique passcode will be displayed. Store this passcode somewhere safe and submit the passcode to MTurk to receive your payment. You will not be able to retrieve it later. Important: Please do NOT submit one passcode multiple times. We might be forced to reject your submission if you do that. If you really have issues with passcode, please c...
-
[15]
Chrome On your computer, open Chrome
Troubleshooting: Clearing Cookies If you experience issues with the study website, such as buttons not working or pages not loading correctly, try clearing cookies for using the instructions below for your browser. Chrome On your computer, open Chrome. At the top right, select More (three dots) → Settings. Go to Privacy and security → Third-party cookies....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.