Beyond Textual Repository Exploration: Dual-Modal Structural Reasoning for Agentic Issue Resolution
Pith reviewed 2026-07-03 09:02 UTC · model grok-4.3
The pith
DUALVIEW improves agent issue resolution by giving persistent visual and textual graph views of code repositories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
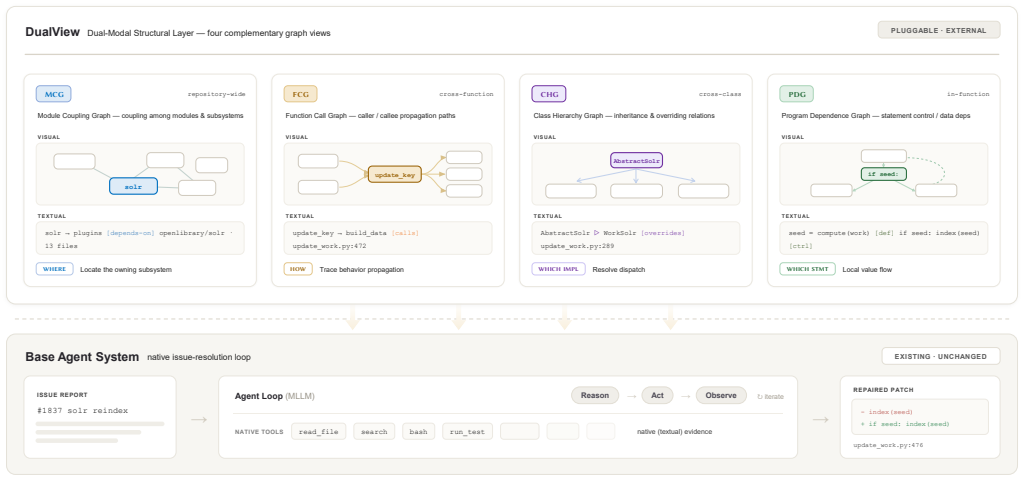
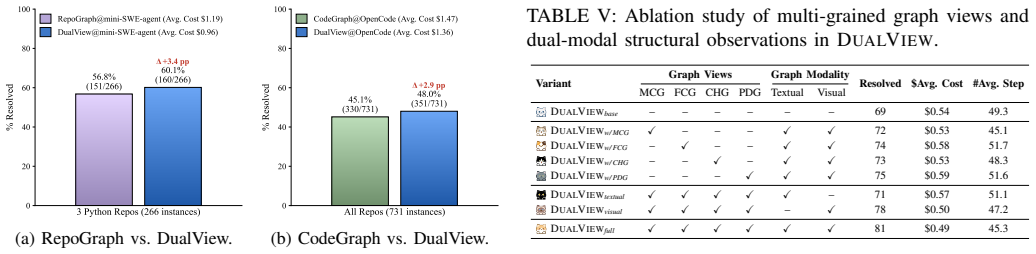
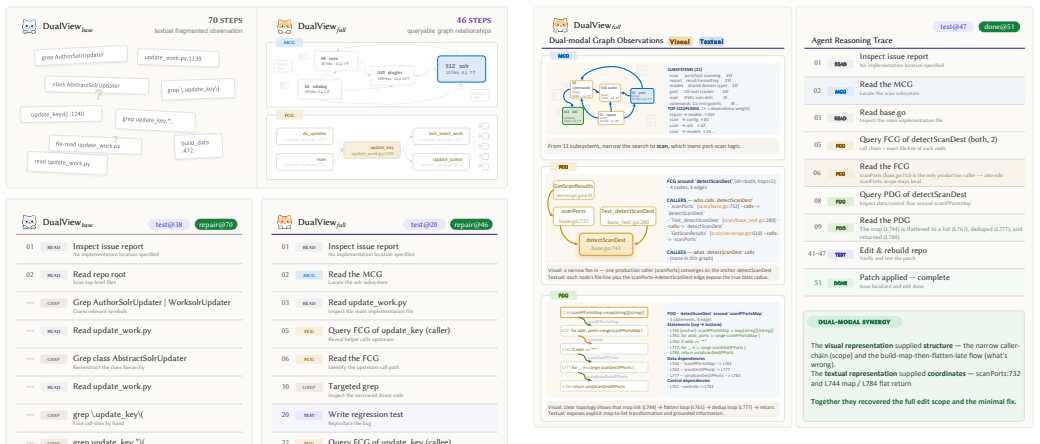
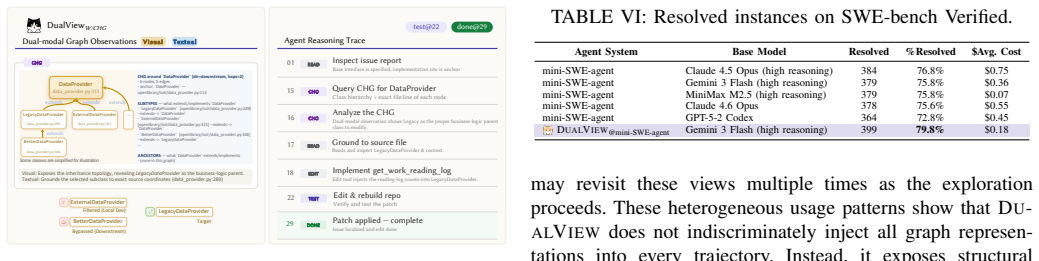
DUALVIEW represents repository structure through four complementary graph views: Module Coupling Graph (MCG), Function Call Graph (FCG), Class Hierarchy Graph (CHG), and Program Dependence Graph (PDG), and exposes them through a queryable interface with visual and textual responses. Rather than reconstructing repository structure from a sequence of textual observations, agents can directly reason over persistent visual representations of code dependencies, enabling more effective exploration and understanding of long-horizon codebases. Evaluation on SWE-bench Pro and Verified shows consistent improvements across agent architectures and model families, with ablation studies attributing gains
What carries the argument
DUALVIEW dual-modal scaffolding framework that maintains four repository graphs and returns both visual and textual answers to agent queries.
If this is right
- Higher issue-resolution rates on SWE-bench Pro and Verified.
- Consistent gains across different agent architectures and model families.
- Performance lift arises from both textual structural data and visual externalization.
- Visual graph views reduce exploration drift in long-horizon tasks.
Where Pith is reading between the lines
- The same persistent visual graphs could be tested in other agent tasks such as test generation or multi-file refactoring.
- One could measure whether particular graphs (for example PDG versus MCG) matter more for certain classes of bugs.
- Persistent visuals might allow agents to operate effectively with shorter context windows by storing structure outside the prompt.
- Training pipelines for code agents could incorporate the four graph views as additional observation channels.
Load-bearing premise
Visual externalization of repository dependencies better supports long-horizon exploration than textual observations alone.
What would settle it
An experiment in which agents receive only the textual forms of the four graphs and match the full DUALVIEW success rates on SWE-bench Pro and Verified.
Figures




read the original abstract
Recent advances in agentic program repair have significantly improved issue resolution by enabling iterative repository exploration. However, existing approaches predominantly rely on sequential, text-based code navigation, which fundamentally limits their ability to reason over large-scale long-horizon repositories with complex and long-range dependencies. As issue-resolution agents traverse repositories through fragmented textual observations, structural information such as module organization, call relationships, and dependency chains must be repeatedly reconstructed across interaction steps, often leading to exploration drift and incomplete localization. We present DUALVIEW, a dual-modal structural scaffolding framework that brings visual reasoning into repository exploration for issue-resolution agents. DUALVIEW represents repository structure through four complementary graph views: Module Coupling Graph (MCG), Function Call Graph (FCG), Class Hierarchy Graph (CHG), and Program Dependence Graph (PDG), and exposes them through a queryable interface with visual and textual responses. Rather than reconstructing repository structure from a sequence of textual observations, agents can directly reason over persistent visual representations of code dependencies, enabling more effective exploration and understanding of long-horizon codebases. We evaluate DUALVIEW on SWE-bench Pro and Verified. Results show that DUALVIEW consistently improves issue-resolution performance across different agent architectures and model families. Further ablation studies demonstrate that the gains arise not only from textual structural information but also from visual externalization of repository dependencies, which better supports long-horizon repository exploration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DUALVIEW, a dual-modal structural scaffolding framework for agentic issue resolution. It represents repositories via four graph views (Module Coupling Graph (MCG), Function Call Graph (FCG), Class Hierarchy Graph (CHG), and Program Dependence Graph (PDG)) exposed through a queryable interface providing both visual and textual responses. The central claim is that this enables more effective long-horizon exploration than text-only approaches, yielding consistent improvements on SWE-bench Pro and Verified across agent architectures and model families, with ablation studies attributing the gains specifically to visual externalization of dependencies.
Significance. If the performance gains and their attribution to visual modality hold under controlled conditions, the work could advance agentic program repair by addressing exploration drift in large repositories through persistent visual representations. The evaluation on established SWE-bench benchmarks provides a clear point of comparison, which is a positive aspect of the experimental design.
major comments (1)
- [Abstract] Abstract (and experimental evaluation section): The claim that 'gains arise not only from textual structural information but also from visual externalization of repository dependencies' rests on ablation studies, but no details are supplied on whether these studies hold the underlying graph content (MCG/FCG/CHG/PDG) and query interface fixed when comparing text-only structural interfaces against the dual-modal version. Without such controls, measured improvements could arise from richer textual serialization, multi-turn context, or redundant formatting rather than visual reasoning per se. This directly undermines the attribution of benefits to the visual modality, which is load-bearing for the central claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the ablation studies and their role in supporting the central claim. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and experimental evaluation section): The claim that 'gains arise not only from textual structural information but also from visual externalization of repository dependencies' rests on ablation studies, but no details are supplied on whether these studies hold the underlying graph content (MCG/FCG/CHG/PDG) and query interface fixed when comparing text-only structural interfaces against the dual-modal version. Without such controls, measured improvements could arise from richer textual serialization, multi-turn context, or redundant formatting rather than visual reasoning per se. This directly undermines the attribution of benefits to the visual modality, which is load-bearing for the central claim.
Authors: We agree that the current manuscript does not provide sufficient detail on the ablation controls, which weakens the attribution to the visual modality. In the revised manuscript we will expand the experimental evaluation section (and update the abstract accordingly) to explicitly state that the text-only structural baseline uses identical graph content (MCG, FCG, CHG, PDG) and the same queryable interface, differing solely in the absence of visual responses. We will also report additional controls (e.g., token-matched textual serializations and fixed multi-turn context lengths) to rule out alternative explanations. These clarifications will be added as a dedicated subsection with pseudocode and example outputs. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks
full rationale
The paper introduces DUALVIEW as a new dual-modal framework with four graph views and evaluates it empirically on SWE-bench Pro and Verified. Performance gains and ablation results are measured against these established external benchmarks rather than derived from internal definitions or self-citations. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described chain; the central claim about visual externalization is supported by comparative experiments whose inputs (agent architectures, model families) are independent of the reported outcomes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,”Advances in Neural Information Processing Systems, vol. 37, pp. 50 528–50 652, 2024
2024
-
[2]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singhet al., “Openhands: An open platform for ai software developers as generalist agents,”arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” 2023. [Online]. Available: https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Autocoderover: Autonomous program improvement,
Y . Zhang, H. Ruan, Z. Fan, and A. Roychoudhury, “Autocoderover: Autonomous program improvement,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, 2024, pp. 1592–1604
2024
-
[5]
Repairagent: An autonomous, llm-based agent for program repair,
I. Bouzenia, P. Devanbu, and M. Pradel, “Repairagent: An autonomous, llm-based agent for program repair,” inIEEE/ACM 47th International Conference on Software Engineering (ICSE), 2025, pp. 2188–2200
2025
-
[6]
J. Zhang, K. Huang, J. Zhang, Y . Liu, and C. Chen, “Repair ingredients are all you need: Improving large language model-based program repair via repair ingredients search,”arXiv preprint arXiv:2506.23100, 2025
-
[7]
Live-SWE-agent: Can software engineering agents self-evolve on the fly?
C. S. Xia, Z. Wang, Y . Yang, Y . Wei, and L. Zhang, “Live-swe-agent: Can software engineering agents self-evolve on the fly?”arXiv preprint arXiv:2511.13646, 2025
-
[8]
Trae agent: An llm-based agent for software engineering with test-time scaling,
T. R. Team, P. Gao, Z. Tian, X. Meng, X. Wang, R. Hu, Y . Xiao, Y . Liu, Z. Zhang, J. Chen, C. Gao, Y . Lin, Y . Xiong, C. Peng, and X. Liu, “Trae agent: An llm-based agent for software engineering with test-time scaling,” 2025. [Online]. Available: https://arxiv.org/abs/2507.23370
-
[9]
Demystifying llm-based software engineering agents,
C. S. Xia, Y . Deng, S. Dunn, and L. Zhang, “Demystifying llm-based software engineering agents,”Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 801–824, 2025
2025
-
[10]
Swe-bench: Can language models resolve real-world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “Swe-bench: Can language models resolve real-world github issues?” in12th International Conference on Learning Represen- tations, ICLR 2024, 2024
2024
-
[11]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
X. Deng, J. Da, E. Pan, Y . Y . He, C. Ide, K. Garg, N. Lauffer, A. Park, N. Pasari, C. Raneet al., “Swe-bench pro: Can ai agents solve long- horizon software engineering tasks?”arXiv preprint arXiv:2509.16941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Swe-bench multimodal: Do ai systems generalize to visual software domains?
J. Yang, C. E. Jimenez, A. L. Zhang, K. Lieret, J. Yang, X. Wu, O. Press, N. Muennighoff, G. Synnaeve, K. R. Narasimhanet al., “Swe-bench multimodal: Do ai systems generalize to visual software domains?” in The Thirteenth International Conference on Learning Representations
-
[13]
Swe-bench verified,
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “Swe-bench verified,” https://www.swebench.com/verified. html, 2025
2025
-
[14]
SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents
Y . Wang, Y . Shi, M. Yang, R. Zhang, S. He, H. Lian, Y . Chen, S. Ye, K. Cai, and X. Gu, “Swe-pruner: Self-adaptive context pruning for coding agents,”arXiv preprint arXiv:2601.16746, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
mini-swe-agent: The minimal ai software engineering agent,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. R. Narasimhan, and O. Press, “mini-swe-agent: The minimal ai software engineering agent,” https://github.com/SWE-agent/mini-swe-agent, 2026
2026
-
[16]
Repograph: Enhancing ai software engineer- ing with repository-level code graph,
S. Ouyang, W. Yu, K. Ma, Z. Xiao, Z. Zhang, M. Jia, J. Han, H. Zhang, and D. Yu, “Repograph: Enhancing ai software engineer- ing with repository-level code graph,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 30 098–30 121
2025
-
[17]
codegraph: Pre-indexed code knowledge graph for claude code, codex, cursor, opencode, and hermes agent,
C. McHenryet al., “codegraph: Pre-indexed code knowledge graph for claude code, codex, cursor, opencode, and hermes agent,” 2026. [Online]. Available: https://github.com/colbymchenry/codegraph
2026
-
[18]
Prometheus: Towards long-horizon codebase navigation for repository-level problem solving,
Y . Pan, Z. Chen, S. Lu, Z. Chu, X. Li, H. Li, Y . Feng, C. Le Goues, F. Sarro, M. Monperruset al., “Prometheus: Towards long-horizon codebase navigation for repository-level problem solving,”arXiv e- prints, pp. arXiv–2507, 2025
2025
-
[19]
S. Seddik and F. Fard, “Arise: A repository-level graph representation and toolset for agentic fault localization and program repair,”arXiv preprint arXiv:2605.03117, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
DeepSeek-OCR: Contexts Optical Compression
H. Wei, Y . Sun, and Y . Li, “Deepseek-ocr: Contexts optical compres- sion,”arXiv preprint arXiv:2510.18234, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Kimi k2.5: Visual agentic intelligence,
MoonshotAI, “Kimi k2.5: Visual agentic intelligence,” Tech. Rep.,
-
[22]
Available: https://www.kimi.com/blog/kimi-k2-5
[Online]. Available: https://www.kimi.com/blog/kimi-k2-5
-
[23]
Introducing agentic vision in gemini 3 flash,
DeepMind, “Introducing agentic vision in gemini 3 flash,” Tech. Rep., 2026. [Online]. Available: https://blog.google/innovation-and-ai/ technology/developers-tools/agentic-vision-gemini-3-flash/
2026
-
[24]
Dualview website,
DualView, “Dualview website,” 2026. [Online]. Available: https: //sites.google.com/view/dual-view
2026
-
[25]
Dualview mcp service,
——, “Dualview mcp service,” 2026. [Online]. Available: https: //github.com/AutoVisualCoder/dualview
2026
-
[26]
A systematic literature review on large language models for auto- mated program repair,
Q. Zhang, C. Fang, Y . Xie, Y . Ma, W. Sun, Y . Yang, and Z. Chen, “A systematic literature review on large language models for auto- mated program repair,”ACM Transactions on Software Engineering and Methodology, 2024
2024
-
[27]
Agentic software issue resolution with large language models: A survey,
Z. Jiang, D. Lo, and Z. Liu, “Agentic software issue resolution with large language models: A survey,”arXiv preprint arXiv:2512.22256, 2025
-
[28]
Using automatic clustering to produce high-level system organizations of source code,
S. Mancoridis, B. S. Mitchell, C. Rorres, Y . Chen, and E. R. Gansner, “Using automatic clustering to produce high-level system organizations of source code,” inProceedings. 6th International Workshop on Program Comprehension, 1998, pp. 45–52
1998
-
[29]
On the criteria to be used in decomposing systems into modules,
D. L. Parnas, “On the criteria to be used in decomposing systems into modules,”Communications of the ACM, vol. 15, no. 12, pp. 1053–1058, 1972
1972
-
[30]
The structure and value of modularity in software design,
K. J. Sullivan, W. G. Griswold, Y . Cai, and B. Hallen, “The structure and value of modularity in software design,”ACM SIGSOFT Software Engineering Notes, vol. 26, no. 5, pp. 99–108, 2001
2001
-
[31]
How effective developers investigate source code: an exploratory study,
M. Robillard, W. Coelho, and G. Murphy, “How effective developers investigate source code: an exploratory study,”IEEE Transactions on Software Engineering, vol. 30, no. 12, pp. 889–903, 2004
2004
-
[32]
Call graph con- struction in object-oriented languages,
D. Grove, G. DeFouw, J. Dean, and C. Chambers, “Call graph con- struction in object-oriented languages,” inProceedings of the 12th ACM SIGPLAN conference on Object-oriented programming, systems, languages, and applications, 1997, pp. 108–124
1997
-
[33]
Optimization of object-oriented programs using static class hierarchy analysis,
J. Dean, D. Grove, and C. Chambers, “Optimization of object-oriented programs using static class hierarchy analysis,” inEuropean conference on object-oriented programming, 1995, pp. 77–101
1995
-
[34]
The program dependence graph and its use in optimization,
J. Ferrante, K. J. Ottenstein, and J. D. Warren, “The program dependence graph and its use in optimization,”ACM Transactions on Programming Languages and Systems (TOPLAS), vol. 9, no. 3, pp. 319–349, 1987
1987
-
[35]
Is a picture worth a thousand words? delving into spatial reasoning for vision language models,
J. Wang, Y . Ming, Z. Shi, V . Vineet, X. Wang, Y . Li, and N. Joshi, “Is a picture worth a thousand words? delving into spatial reasoning for vision language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 75 392–75 421, 2024
2024
-
[36]
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models,
Y . Hu, W. Shi, X. Fu, D. Roth, M. Ostendorf, L. Zettlemoyer, N. A. Smith, and R. Krishna, “Visual sketchpad: Sketching as a visual chain of thought for multimodal language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 139 348–139 379, 2024
2024
-
[37]
OpenCode: The open source AI coding agent,
Anomaly, “OpenCode: The open source AI coding agent,” 2026. [Online]. Available: https://opencode.ai/
2026
-
[38]
Claude sonnet 4.5,
Anthropic, “Claude sonnet 4.5,” https://www.anthropic.com/news/ claude-sonnet-4-5, 2026
2026
-
[39]
Kimi k2.5,
Moonshot, “Kimi k2.5,” https://www.kimi.com/ai-models/kimi-k2-5, 2026
2026
-
[40]
Gemini 3 flash,
Google, “Gemini 3 flash,” https://docs.cloud.google.com/ gemini-enterprise-agent-platform/models/gemini/3-flash, 2026
2026
-
[41]
Swe-bench pro leaderboard ai coding benchmark (public dataset),
S. AI, “Swe-bench pro leaderboard ai coding benchmark (public dataset),” Tech. Rep., 2026. [Online]. Available: https://labs.scale.com/ leaderboard/swe bench pro public
2026
-
[42]
Issue localization via llm-driven iterative code graph searching,
Z. Jiang, X. Ren, M. Yan, W. Jiang, Y . Li, and Z. Liu, “Issue localization via llm-driven iterative code graph searching,” in2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2025, pp. 3034–3045
2025
-
[43]
Enhancing repository-level software repair via repository-aware knowledge graphs,
B. Yang, J. Ren, S. Jin, Y . Liu, F. Liu, B. Le, and H. Tian, “Enhancing repository-level software repair via repository-aware knowledge graphs,” arXiv preprint arXiv:2503.21710, 2025
-
[44]
Sgagent: Suggestion-guided llm-based multi-agent framework for repository-level software repair,
Q. Zhang, C. Gao, Y . Han, Y . Shang, C. Fang, Z. Chen, and L. Xiao, “Sgagent: Suggestion-guided llm-based multi-agent framework for repository-level software repair,”ACM Transactions on Software Engineering and Methodology, 2026
2026
-
[45]
Seeing is fixing: Cross- modal reasoning with multimodal llms for visual software issue repair,
K. Huang, J. Zhang, X. Xie, and C. Chen, “Seeing is fixing: Cross- modal reasoning with multimodal llms for visual software issue repair,” in40th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2025, pp. 1156–1168
2025
-
[46]
Svrepair: Structured visual reasoning for automated program repair,
X. Tang, J. Wang, L. Luo, J. Xu, S. Zhou, D. Chen, W. Jiang, and Y . Li, “Svrepair: Structured visual reasoning for automated program repair,” arXiv preprint arXiv:2602.06090, 2026
-
[47]
Longcodezip: Compress long context for code language models,
Y . Shi, Y . Qian, H. Zhang, B. Shen, and X. Gu, “Longcodezip: Compress long context for code language models,” in40th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2025, pp. 141–153
2025
-
[48]
CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding
Y . Shi, C. Xie, Z. Sun, Y . Chen, C. Zhang, L. Yun, C. Wan, H. Zhang, D. Lo, and X. Gu, “Codeocr: On the effectiveness of vision language models in code understanding,”arXiv preprint arXiv:2602.01785, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
VEA and Baselines Implementation Details
J. Zhong, G. Li, C. Zhi, J. Han, Z. Qin, X. Zhao, N. Wang, S. Deng, and J. Yin, “Can vision-language models handle long-context code? an em- pirical study on visual compression,”arXiv preprint arXiv:2602.00746, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.