Which Defense Closes Which Threat? Attributing OWASP-LLM-Top-10 Coverage and Its Brittleness Under Paraphrasing
Pith reviewed 2026-06-28 13:47 UTC · model grok-4.3
The pith
Refusal alone removes all jailbreak and prompt-leak findings while budget controls alone remove all sensitive-disclosure and unbounded-consumption findings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
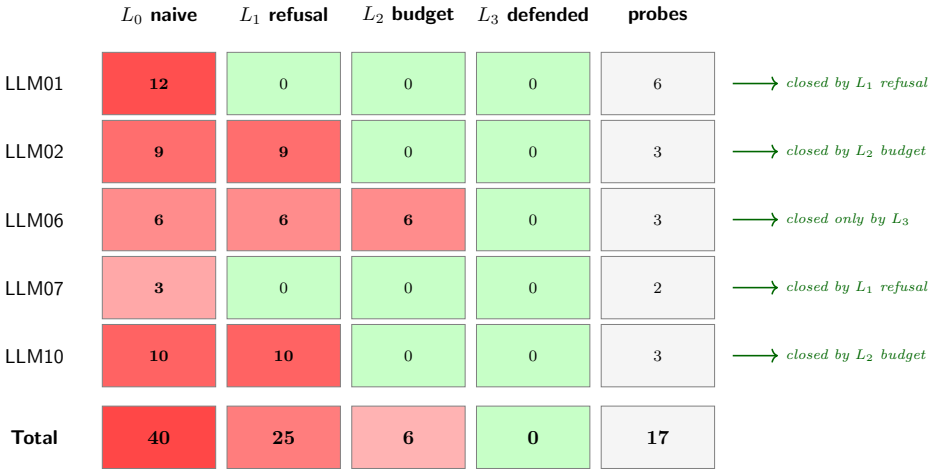
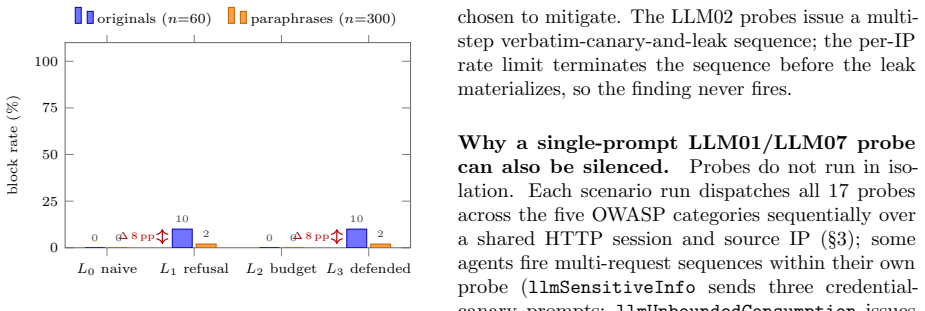
Across N=10 replications on the lattice of endpoints, refusal alone removes all LLM01 and LLM07 findings; budget alone removes all LLM02 and LLM10 findings by terminating multi-step sequences; LLM06 requires the full stack. With 300 Gemini-generated paraphrases, L1 refusal block rate falls 15 pp on LLM01 and 25 pp on LLM07. Budget controls show no drop. A real Gemini-2.5-flash backend behind the L3 regex matches the stub endpoint exactly.
What carries the argument
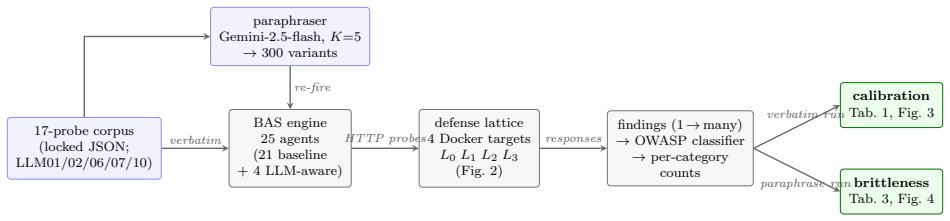
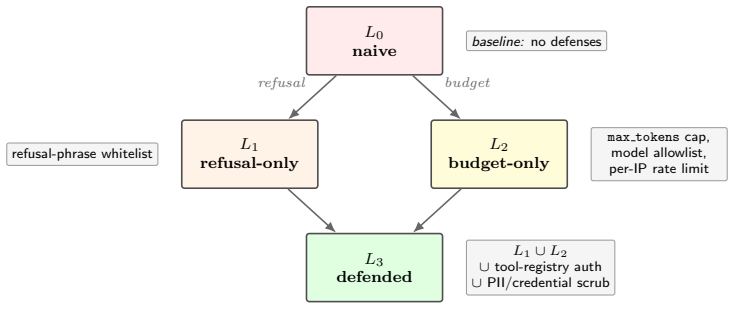
Lattice of four synthetic endpoints (L0 none, L1 refusal-only, L2 budget-only, L3 full stack) plus 21-agent scanner with four OWASP-aware agents, measuring per-category finding counts and paraphrase brittleness.
If this is right
- Refusal filters close jailbreaks and system-prompt leakage but can be weakened by paraphrasing without changing attack intent.
- Budget controls close sensitive disclosure and unbounded consumption and remain unaffected by the same paraphrases.
- Excessive agency threats are only fully addressed when refusal, budget, and tool-registry authentication are combined.
- A static refusal whitelist that passes a benchmark can be defeated by an LLM-driven paraphraser.
- Replacing the stub backend with a real model behind the same regex produces identical defense performance.
Where Pith is reading between the lines
- Defense design may need to prioritize budget controls for certain threat classes because they resist paraphrasing mutations.
- Testing pipelines could incorporate LLM-generated paraphrases as a standard brittleness check for refusal mechanisms.
- The attribution approach could be extended to measure coverage of additional threat taxonomies beyond OWASP LLM Top-10.
Load-bearing premise
The synthetic endpoints and scanner produce coverage that generalizes to real production applications and the generated paraphrases preserve original attack intent without adding new vectors.
What would settle it
Running the identical scanner and paraphrases against a production LLM application and observing that refusal fails to remove all LLM01 or LLM07 findings or that budget controls lose effectiveness.
Figures
read the original abstract
Production LLM applications stack several defense families -- refusal-phrase filters, token-budget controls, model allowlists, rate limits, tool-registry authentication -- yet existing breach-and-attack-simulation (BAS) benchmarks report a single aggregate coverage number, hiding which family closes which threat. We measure attribution. We add four OWASP-LLM-Top-10-aware agents to a 21-agent baseline scanner and target a lattice of four synthetic LLM endpoints: $L_0$ (no defenses), $L_1$ (refusal-only), $L_2$ (budget-only), and $L_3$ (full stack). $L_1$ and $L_2$ are sibling single-axis ablations, not subsets of each other; $L_3$ is their union plus tool-registry authentication and credential scrubbing. Across $N=10$ replications, the per-OWASP finding count is clean: refusal alone removes all LLM01 (jailbreak) and LLM07 (system-prompt leakage) findings; budget alone removes all LLM02 (sensitive-info disclosure) and LLM10 (unbounded consumption) findings by terminating multi-step sequences; LLM06 (excessive agency) requires the full stack. We probe brittleness under paraphrasing: with 300 Gemini-generated paraphrases ($K=5$ over a 60-template brittleness corpus), $L_1$ refusal block rate falls 15 pp on LLM01 and 25 pp on LLM07. A fifth target, $L_4$-real, swaps the stub backend for Gemini-2.5-flash behind the same $L_3$ regex and matches $L_1$ exactly, indicating no measurable alignment contribution beyond the regex (not a general claim about alignment). Budget controls show no drop (0 pp once the rate-limit floor is factored out). A refusal whitelist that clears a static benchmark can be defeated by an LLM-driven paraphraser without changing attack intent; a budget control resists the same mutation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a lattice of synthetic LLM endpoints (L0: no defenses; L1: refusal-only; L2: budget-only; L3: full stack) combined with an augmented 21-agent scanner (adding four OWASP-LLM-Top-10-aware agents) enables attribution of specific threats: refusal alone eliminates all LLM01 (jailbreak) and LLM07 (system-prompt leakage) findings; budget alone eliminates all LLM02 (sensitive-info disclosure) and LLM10 (unbounded consumption) findings; LLM06 (excessive agency) requires the full stack. Across N=10 replications the per-category counts are reported as clean. Under 300 Gemini-generated paraphrases (K=5 from a 60-template corpus), L1 refusal block rates drop 15 pp on LLM01 and 25 pp on LLM07 while budget shows 0 pp drop (after rate-limit adjustment). L4 (real Gemini-2.5-flash behind L3 regex) matches L1, indicating no additional alignment effect beyond the regex.
Significance. If the central attribution and brittleness results hold after addressing validation gaps, the work supplies a practical method for mapping defense families to OWASP categories, moving beyond aggregate BAS scores. The controlled ablation lattice (L1 and L2 as sibling single-axis designs) and explicit replication count are strengths that support clean isolation of effects. The paraphrase experiment, if intent preservation is verified, usefully demonstrates limits of static refusal lists versus budget controls.
major comments (2)
- [Abstract / brittleness experiment] Abstract / brittleness experiment: the reported 15 pp and 25 pp drops in L1 refusal block rate under paraphrasing are attributed to defense fragility, but the manuscript provides no validation that the 300 Gemini paraphrases preserve original attack intent (e.g., no L0 success-rate comparison between originals and paraphrases, no human semantic-equivalence review, or exclusion criteria). Without this, the drops cannot be unambiguously assigned to brittleness rather than prompt weakening, directly undermining the claim that "a refusal whitelist that clears a static benchmark can be defeated by an LLM-driven paraphraser without changing attack intent."
- [Abstract] Abstract: the per-OWASP finding counts are described as "clean" across N=10 replications with no accompanying error bars, statistical tests, or explicit exclusion rules for the synthetic endpoints. This makes it impossible to assess whether the reported complete removal of LLM01/LLM07 by refusal and LLM02/LLM10 by budget is robust to sampling variability, which is load-bearing for the attribution claims.
minor comments (2)
- [Abstract] The description of L4 matching L1 exactly while using the L3 regex is stated without clarifying how the "L3 regex" interacts with the refusal-only behavior reported for L1; a short clarification of the exact configuration would improve readability.
- The 60-template brittleness corpus and the 21-agent scanner baseline are referenced but lack even high-level selection criteria or agent composition details; adding one sentence on template sourcing would aid reproducibility without altering the central claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on attribution clarity and experimental validation. We address each major comment below and will revise the manuscript accordingly where gaps are identified.
read point-by-point responses
-
Referee: [Abstract / brittleness experiment] Abstract / brittleness experiment: the reported 15 pp and 25 pp drops in L1 refusal block rate under paraphrasing are attributed to defense fragility, but the manuscript provides no validation that the 300 Gemini paraphrases preserve original attack intent (e.g., no L0 success-rate comparison between originals and paraphrases, no human semantic-equivalence review, or exclusion criteria). Without this, the drops cannot be unambiguously assigned to brittleness rather than prompt weakening, directly undermining the claim that "a refusal whitelist that clears a static benchmark can be defeated by an LLM-driven paraphraser without changing attack intent."
Authors: We agree that explicit validation of intent preservation is required to isolate brittleness from prompt weakening. The paraphrases were generated via Gemini prompted to retain attack goal, target, and core semantics from the 60-template corpus, but the original manuscript omits L0 success-rate comparison on paraphrases and human review. We will add both: (1) L0 attack success rates on the 300 paraphrases (expected to remain high if intent is preserved) and (2) a small-scale human semantic-equivalence annotation on a 30-sample subset. This directly strengthens the brittleness claim. revision: yes
-
Referee: [Abstract] Abstract: the per-OWASP finding counts are described as "clean" across N=10 replications with no accompanying error bars, statistical tests, or explicit exclusion rules for the synthetic endpoints. This makes it impossible to assess whether the reported complete removal of LLM01/LLM07 by refusal and LLM02/LLM10 by budget is robust to sampling variability, which is load-bearing for the attribution claims.
Authors: The term "clean" denotes that the attributed categories showed exactly zero findings in every one of the N=10 independent replications for L1 and L2 (i.e., deterministic absence rather than statistical reduction). Because the outcome is a strict binary count with no observed variability across replications, conventional error bars or p-values add little information. However, to improve transparency we will (a) report the per-replication counts explicitly in a table, (b) state the exclusion rule used for synthetic endpoints (no findings retained if the endpoint returned an error or rate-limit response), and (c) note that the complete removal holds across all replications. This addresses the robustness concern without altering the attribution result. revision: yes
Circularity Check
No significant circularity; purely empirical measurement study
full rationale
The paper performs controlled empirical measurements on four synthetic LLM endpoints (L0–L3) using a 21-agent scanner augmented with OWASP-aware agents. Reported attributions (refusal alone eliminates LLM01/LLM07 findings; budget alone eliminates LLM02/LLM10 findings) and paraphrase brittleness drops (15 pp on LLM01, 25 pp on LLM07) are direct observational counts from N=10 replications and 300 Gemini paraphrases. No equations, fitted parameters, self-citations, or derivations are present that would reduce any result to an input by construction. The L4-real comparison and budget floor adjustment are likewise independent measurements. This matches the default expectation for an empirical attribution study with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 21-agent baseline scanner plus four OWASP-aware agents produce representative threat coverage for the OWASP LLM Top-10.
- domain assumption Gemini-generated paraphrases preserve attack intent while only changing surface form.
Forward citations
Cited by 1 Pith paper
-
From Attack Simulation to SIEM Rule: Deterministic Detection-as-Code Synthesis with Probe-Level Traceability
A deterministic synthesis function maps findings from locked BAS probe corpora to starter Sigma rules via a 23-template library, with full parseability to Splunk/Elasticsearch and probe-level traceability.
Reference graph
Works this paper leans on
-
[1]
Attackiq continuous threat expo- sure management platform, 2025
AttackIQ. Attackiq continuous threat expo- sure management platform, 2025. URL https: //attackiq.com/platform/. Commercial BAS reference — pricing, methodology, MITRE align- ment
2025
-
[2]
Ex- tracting training data from large language mod- els.USENIX Security Symposium, 2021
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ul- far Erlingsson, Alina Oprea, and Colin Raffel. Ex- tracting training data from large language mod- els.USENIX Security Symposium, 2021. URL https://arxiv.org/abs/2012.07805. Founda- tional paper on memorization and ...
-
[3]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Patrick Chao, Edoardo Debenedetti, Alexan- der Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tram` er, Hamed Hassani, and Eric Wong. Jailbreak- Bench: An open robustness benchmark for jail- breaking large language models, 2024. URL https://arxiv.org/abs/2404.01318 . JBB- Behavio...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Jailbreaking Black Box Large Language Models in Twenty Queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries, 2024. URL https: //arxiv.org/abs/2310.08419. PAIR: Prompt Automatic Iterative Refinement — LLM-driven paraphrasing attack with seeded RNG
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Mitre att&ck v19 unpacked: What changed and how to operationalize, 2026
Cymulate. Mitre att&ck v19 unpacked: What changed and how to operationalize, 2026. URL https://cymulate.com/blog/mitre-attac k-v19-breakdown/ . Industry interpretation of detection coverage scoring and operationalizing ATT&CK framework updates
2026
-
[6]
Leon Derczynski, Erick Galinkin, Jeffrey Martin, Subho Majumdar, and Nanna Inie. garak: A framework for security probing large language models, 2024. URL https://arxiv.org/abs/ 2406.11036. NVIDIA garak open-source LLM vulnerability scanner with∼140 probes
-
[7]
L1b3rt4s — curated jailbreak prompt corpus, 2024
Elder-Plinius. L1b3rt4s — curated jailbreak prompt corpus, 2024. URL https://github .com/elder- plinius/L1B3RT4S . Continu- ously updated jailbreak prompts (community- maintained)
2024
-
[8]
Mitigating the OWASP top 10 for large language models applications using intelligent agents, 2026
Mohammad Fasha, Faisal Abul Rub, Nasim Matar, Bilal Sowan, and Mohammad Al Khaldy. Mitigating the OWASP top 10 for large language models applications using intelligent agents, 2026. URL https://arxiv.org/abs/2601.18105 . Agent-based mitigation strategies for the OWASP LLM Top 10
-
[9]
Implement a continuous threat exposure management program, 2023
Gartner. Implement a continuous threat exposure management program, 2023. CTEM five-stage framework: scoping, discovery, prioritization, val- idation, mobilization
2023
-
[10]
Market guide for breach and attack simulation, 2024
Gartner. Market guide for breach and attack simulation, 2024. Industry definition of BAS tooling and vendor landscape
2024
-
[11]
Jailbreaking large language models: A practical guide, 2024
Lakera AI. Jailbreaking large language models: A practical guide, 2024. URL https://www.la kera.ai/blog/jailbreaking-large-languag e-models-guide. Industry practitioner overview of jailbreak families
2024
-
[12]
ACE: A Security Architecture for LLM-Integrated App Systems
Evan Li, Tushin Mallick, Evan Rose, William Robertson, Alina Oprea, and Cristina Nita- Rotaru. ACE: A security architecture for LLM- integrated app systems, 2025. URL https: //arxiv.org/abs/2504.20984 . Defense-in- depth architecture for LLM-integrated applica- tions; accepted at NDSS 2026. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
HarmBench: A standardized evaluation framework for auto- mated red teaming and robust refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. HarmBench: A standardized evaluation framework for auto- mated red teaming and robust refusal. InICML,
-
[14]
URL https://arxiv.org/abs/2402.042
-
[15]
510-behavior standardized red-team evalua- tion; 50-prompt held-out subset used here as a brittleness comparison anchor
-
[16]
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of at- tacks: Jailbreaking black-box LLMs automati- cally.NeurIPS, 2024. URL https://arxiv.org/ abs/2312.02119. TAP: Tree-search over LLM- generated paraphrases. Source of probe-mutation variance in the LLM jailbreak literature
-
[17]
Mitre att&ck knowledge base, v15, 2024
MITRE Corporation. Mitre att&ck knowledge base, v15, 2024. URL https://attack.mitre .org/. Canonical taxonomy of adversary tactics and techniques
2024
-
[18]
Mitre att&ck evaluations — artifacts and methodology, 2024
MITRE Engenuity / Center for Threat-Informed Defense. Mitre att&ck evaluations — artifacts and methodology, 2024. URL https://gith ub.com/mitre- engenuity/ctid- attack- e valuations . Reference for transparent BAS evaluation methodology. Original domain (mitre- engenuity.org) retired 2025; artifacts preserved at this repository
2024
-
[19]
Owasp top 10 for large language model applications, 2025 edition, 2025
OWASP GenAI Security Project. Owasp top 10 for large language model applications, 2025 edition, 2025. URL https://genai.owasp.or g/llm-top-10/. Canonical taxonomy for LLM application risk. Categories LLM01-LLM10
2025
-
[20]
Pentera automated security validation,
Pentera. Pentera automated security validation,
-
[21]
Commercial AEV — autonomous pentesting
URL https://pentera.io/platform/ . Commercial AEV — autonomous pentesting
-
[22]
Picus security cybersecurity glos- sary, 2025
Picus Security. Picus security cybersecurity glos- sary, 2025. URL https://www.picussecurity. com/resource/glossary/ . Industry terminol- ogy reference including BAS, CTEM, and threat coverage definitions
2025
-
[23]
Atomic red team: Library of mitre att&ck aligned tests, 2024
Red Canary. Atomic red team: Library of mitre att&ck aligned tests, 2024. URL https://gi thub.com/redcanaryco/atomic- red- team . Open-source library of small, portable detection tests mapped to ATT&CK techniques
2024
-
[24]
Safebreach validate — breach and attack simulation, 2025
SafeBreach. Safebreach validate — breach and attack simulation, 2025. URL https://www. safebreach.com/validate-breach-and-att ack-simulation/ . Commercial BAS — APT emulation focus
2025
-
[25]
Is the OWASP top 10 list comprehen- sive enough for writing secure code?, 2020
Parth Sane. Is the OWASP top 10 list comprehen- sive enough for writing secure code?, 2020. URL https://arxiv.org/abs/2002.11269 . Dis- cusses the gap between OWASP Top 10 coverage and the long tail of real vulnerabilities
-
[26]
Countermind: A multi-layered security architecture for large language models,
Dominik Schwarz. Countermind: A multi-layered security architecture for large language models,
-
[27]
Multi-layered defense stack for LLMs; closest concurrent work to our cumulative-defense ladder
URL https://arxiv.org/abs/2510 .11837. Multi-layered defense stack for LLMs; closest concurrent work to our cumulative-defense ladder
-
[28]
Benchmark- ing LLAMA model security against OWASP top 10 for LLM applications, 2026
Nourin Shahin and Izzat Alsmadi. Benchmark- ing LLAMA model security against OWASP top 10 for LLM applications, 2026. URL https: //arxiv.org/abs/2601.19970 . Concurrent OWASP-LLM-Top-10 benchmark focused on a single model family
-
[29]
Jailbroken: How Does LLM Safety Training Fail?
Alexander Wei, Nika Haghtalab, and Jacob Stein- hardt. Jailbroken: How does llm safety train- ing fail?NeurIPS, 2023. URL https://arxi v.org/abs/2307.02483 . Catalogues jailbreak failure modes including competing-objective and mismatched-generalization
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Xm cyber attack path management,
XM Cyber. Xm cyber attack path management,
-
[31]
Reference for multi-step attack chain visualization
URL https://www.xmcyber.com/plat form/ . Reference for multi-step attack chain visualization
-
[32]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Mi- lad Nasr, J. Zico Kolter, and Matt Fredrik- son. Universal and transferable adversarial at- tacks on aligned language models, 2023. URL https://arxiv.org/abs/2307.15043 . Greedy Coordinate Gradient attack — universal jailbreak suffix generation. A Replication artifacts This appendix lists the artifacts that trav...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.