SAEExplainer: Interpreting SAE Features with Activation-Guided Preference Optimization
Pith reviewed 2026-06-27 18:33 UTC · model grok-4.3
The pith
SAEExplainer trains an explainer to self-correct SAE feature descriptions using activation scores as the reward signal in a two-round preference optimization loop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
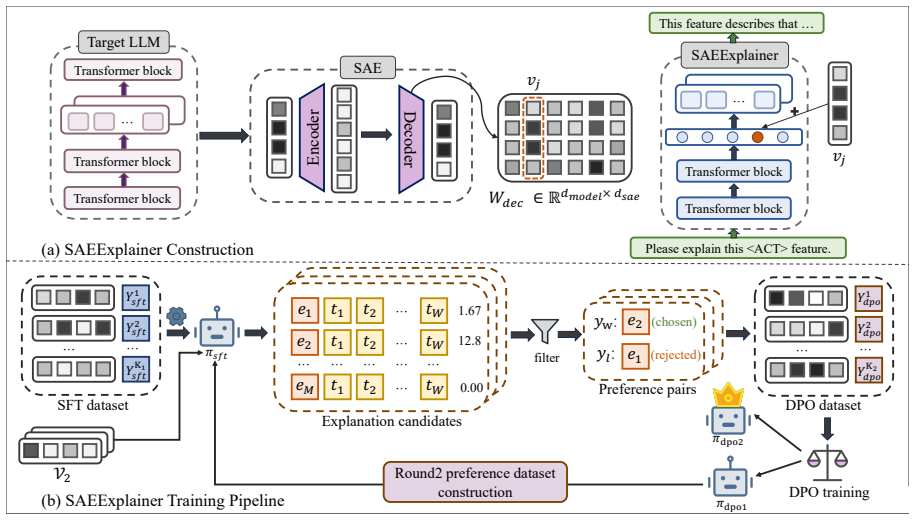
SAEExplainer is a training framework that utilizes activation scores as an objective reward signal to train the model for self-correction and iterative bootstrapping. By iteratively verifying and correcting foundational explanations through a two-round optimization process, SAEExplainer achieves continuous improvement in its explanatory capabilities. This mechanism significantly reduces explanation hallucinations and reinforces causal triggering patterns.
What carries the argument
The two-round optimization process in which activation scores serve as the reward signal for preference optimization, enabling the explainer to bootstrap better explanations from its own initial outputs.
If this is right
- Explanations improve on established baselines across most metrics, with largest gains in causal triggering and discriminative activation.
- Explanation hallucinations are reduced because each round explicitly penalizes descriptions that fail to align with measured activation.
- Causal triggering patterns are reinforced because the reward directly favors explanations that match the features' actual firing conditions.
- The process yields continuous improvement rather than a single static output because the second round feeds refined preferences back into the model.
Where Pith is reading between the lines
- The same activation-guided loop could be tested on other post-hoc interpretability methods that already produce scalar scores, such as attention or gradient attributions.
- If the reward signal remains stable across iterations, the approach might reduce the need for large-scale human annotation of explanations.
- The framework implies that any interpretability technique whose outputs can be scored against model internals could adopt a similar closed-loop refinement step.
Load-bearing premise
Activation scores constitute an objective, unbiased reward signal that can guide preference optimization without introducing new hallucinations or circular self-reference.
What would settle it
Apply SAEExplainer to a held-out set of SAE features whose true causal inputs are already known; if the refined explanations after two rounds do not produce higher activation on those inputs than the initial explanations or strong baselines, the central claim fails.
Figures

read the original abstract
Although Sparse Autoencoders (SAEs) have mitigated the opacity of large language models (LLMs) by decomposing dense representations into sparse features, explaining these features still remains a central challenge. Current explanation methods, however, typically operate within an open-loop paradigm, failing to leverage mechanistic feedback for further refinement. In this paper, we propose SAEExplainer, a training framework utilizes activation scores as an objective reward signal to train the model for self-correction and iterative bootstrapping. By iteratively verifying and correcting foundational explanations through a two-round optimization process, SAEExplainer achieves continuous improvement in its explanatory capabilities. This mechanism significantly reduces explanation hallucinations and reinforces causal triggering patterns. Extensive experiments demonstrate our approach improves upon established baselines across most metrics, especially in causal triggering and discriminative activation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAEExplainer, a framework that uses activation scores from SAEs as an objective reward signal within a two-round preference optimization process. This enables iterative self-correction and bootstrapping of explanations for SAE features, with the central claim that the approach reduces explanation hallucinations while improving causal triggering and discriminative activation over baselines.
Significance. If the activation scores can be shown to function as an external, non-circular reward without amplifying SAE biases, the method would offer a practical feedback mechanism for refining automated explanations in mechanistic interpretability. The two-round optimization structure is a concrete contribution that could be tested for robustness, but the absence of external grounding makes the significance conditional on resolving the reward-signal validity.
major comments (2)
- [Abstract] Abstract: the claim that activation scores supply an 'objective reward signal' for self-correction is load-bearing for the entire contribution, yet the abstract supplies no external validation, held-out causal test, or comparison against an independent explanation metric; without such a break in the loop the iterative process risks re-amplifying any systematic incompleteness already present in the SAE features.
- [Abstract] Abstract (results paragraph): the assertion of improvements 'across most metrics, especially in causal triggering and discriminative activation' is stated without any reported baselines, datasets, statistical tests, or effect sizes, rendering the central empirical claim unevaluable and preventing assessment of whether the two-round process actually delivers the claimed reduction in hallucinations.
minor comments (1)
- [Abstract] The abstract refers to 'extensive experiments' and 'established baselines' but provides no concrete references or descriptions, which hinders reproducibility and should be expanded even if the core method is revised.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that activation scores supply an 'objective reward signal' for self-correction is load-bearing for the entire contribution, yet the abstract supplies no external validation, held-out causal test, or comparison against an independent explanation metric; without such a break in the loop the iterative process risks re-amplifying any systematic incompleteness already present in the SAE features.
Authors: Activation scores are computed directly from SAE feature activations on input tokens and are independent of the generated explanation text, providing a mechanistic reward signal for the preference optimization. The two-round process uses this signal to prefer explanations that better align with high-activation examples, creating an iterative refinement loop. We acknowledge the referee's concern regarding potential bias amplification and will revise the abstract and add a dedicated limitations paragraph discussing the reward signal's grounding and risks of re-amplifying SAE incompletenesses. revision: yes
-
Referee: [Abstract] Abstract (results paragraph): the assertion of improvements 'across most metrics, especially in causal triggering and discriminative activation' is stated without any reported baselines, datasets, statistical tests, or effect sizes, rendering the central empirical claim unevaluable and preventing assessment of whether the two-round process actually delivers the claimed reduction in hallucinations.
Authors: The abstract is a concise summary; the full manuscript reports baselines, datasets, metrics, statistical tests, and effect sizes in the Experiments section and associated tables. To make the abstract claim more evaluable at a glance, we will revise it to briefly reference the evaluation setup and main baselines while respecting length constraints. revision: yes
Circularity Check
No significant circularity; method uses external activation signal without self-referential reduction shown
full rationale
The abstract describes a training framework that takes activation scores as an objective reward signal for iterative self-correction of explanations. No equations, self-citations, or derivation steps are provided in the given text that would reduce the claimed improvement or causal triggering to a fitted input or self-definition by construction. The approach is presented as a new optimization process with experimental validation against baselines, keeping the central claim independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
arXiv preprint arXiv:2303.18223 , volume=
A survey of large language models , author=. arXiv preprint arXiv:2303.18223 , volume=
-
[9]
2021 , journal=
A Mathematical Framework for Transformer Circuits , author=. 2021 , journal=
2021
-
[10]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Feature extraction and steering for enhanced chain-of-thought reasoning in language models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[11]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Sae-ssv: Supervised steering in sparse representation spaces for reliable control of language models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[12]
International Conference on Learning Representations , volume=
Do i know this entity? knowledge awareness and hallucinations in language models , author=. International Conference on Learning Representations , volume=
-
[13]
2023 , journal=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
2023
-
[14]
arXiv preprint arXiv:2309.08600 , year=
Sparse autoencoders find highly interpretable features in language models , author=. arXiv preprint arXiv:2309.08600 , year=
-
[15]
2022 , journal=
Toy Models of Superposition , author=. 2022 , journal=
2022
-
[16]
2023 , howpublished =
Language models can explain neurons in language models , author=. 2023 , howpublished =
2023
-
[17]
Neuronpedia: Interactive Reference and Tooling for Analyzing Neural Networks , year =
-
[18]
arXiv preprint arXiv:2412.08686 , year=
Latentqa: Teaching llms to decode activations into natural language , author=. arXiv preprint arXiv:2412.08686 , year=
-
[19]
ArXiv , year=
Activation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers , author=. ArXiv , year=
-
[20]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[21]
The Claude 3 Model Family: Opus, Sonnet, Haiku , author=
-
[22]
International Conference on Learning Representations , volume=
Scaling and evaluating sparse autoencoders , author=. International Conference on Learning Representations , volume=
-
[23]
arXiv preprint arXiv:2408.00118 , year=
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
-
[24]
ArXiv , year=
Gemma 2: Improving Open Language Models at a Practical Size , author=. ArXiv , year=
-
[25]
2024 , url=
The Llama 3 Herd of Models , author=. 2024 , url=
2024
-
[26]
Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2 , author=. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
-
[27]
ArXiv , year=
Llama Scope: Extracting Millions of Features from Llama-3.1-8B with Sparse Autoencoders , author=. ArXiv , year=
-
[28]
2024 , url=
GPT-4o System Card , author=. 2024 , url=
2024
-
[29]
2026 , eprint=
OpenAI GPT-5 System Card , author=. 2026 , eprint=
2026
-
[30]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Enhancing automated interpretability with output-centric feature descriptions , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 5: Industry Track) , pages=
Sage: An agentic explainer framework for interpreting sae features in language models , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 5: Industry Track) , pages=
-
[32]
Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
Rigorously assessing natural language explanations of neurons , author=. Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
-
[33]
2024 , month =
Choi, Dami and Huang, Vincent and Meng, Kevin and Johnson, Daniel D and Steinhardt, Jacob and Schwettmann, Sarah , title =. 2024 , month =
2024
-
[34]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Neurons in large language models: Dead, n-gram, positional , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[35]
arXiv preprint arXiv:2411.02193 , year=
Improving steering vectors by targeting sparse autoencoder features , author=. arXiv preprint arXiv:2411.02193 , year=
-
[36]
arXiv preprint arXiv:2411.04430 , year=
Towards unifying interpretability and control: Evaluation via intervention , author=. arXiv preprint arXiv:2411.04430 , year=
-
[37]
arXiv preprint arXiv:2404.16014 , year=
Improving dictionary learning with gated sparse autoencoders , author=. arXiv preprint arXiv:2404.16014 , year=
-
[38]
Distill , volume=
Zoom in: An introduction to circuits , author=. Distill , volume=
-
[39]
arXiv preprint arXiv:2410.13928 , year=
Automatically interpreting millions of features in large language models , author=. arXiv preprint arXiv:2410.13928 , year=
-
[40]
Forty-first International Conference on Machine Learning , year=
A multimodal automated interpretability agent , author=. Forty-first International Conference on Machine Learning , year=
-
[41]
2025 , month =
Anthropic , title =. 2025 , month =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.