Style-CCL: Content-Preserving Style Transfer via Curriculum Continual Learning
Pith reviewed 2026-07-04 00:10 UTC · model grok-4.3
The pith
Curriculum learning from semantic to texture styles lets diffusion transformers preserve content during style transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
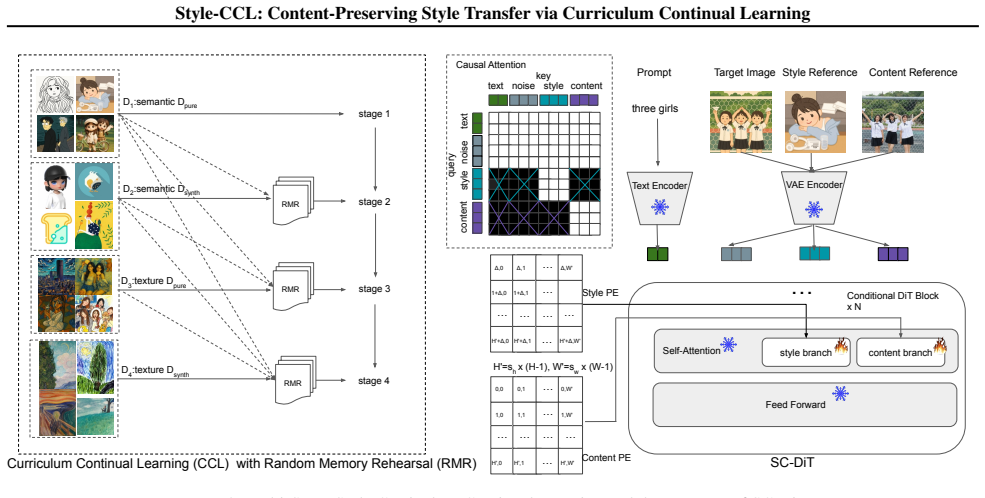
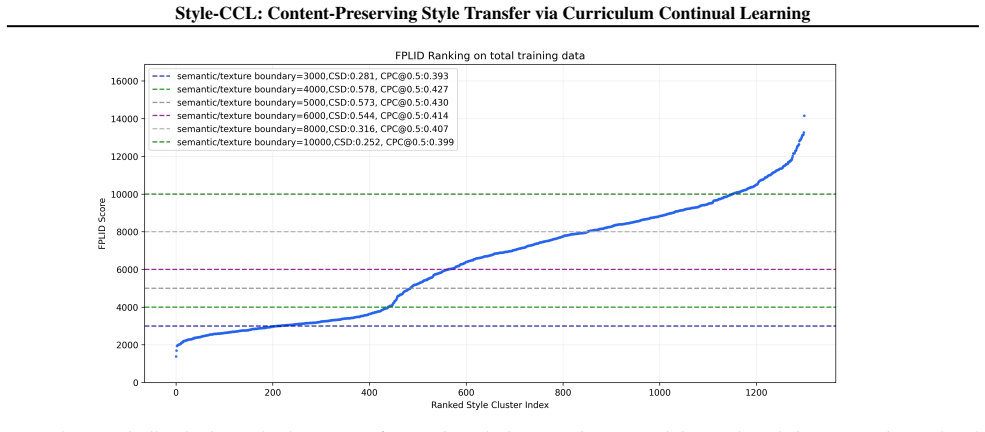
Style-CCL is a multi-stage curriculum continual learning framework that trains the SC-DiT model progressively from semantic (easy) to texture (hard) styles and from clean to synthetic data with random memory rehearsal across stages, overcoming the semantic dominance observed in one-stage training on mixed categories and delivering state-of-the-art results on style similarity, content consistency, and aesthetic quality.
What carries the argument
The Multi-Stage Curriculum Continual Learning framework applied to the SC-DiT dual-branch diffusion transformer, which decouples style and content via separate ROPE embeddings and causal masking while sequencing training from semantic to texture styles plus random memory rehearsal.
If this is right
- Progressing training from semantic to texture styles prevents semantic features from overwhelming texture learning.
- Random memory rehearsal across curriculum stages prevents catastrophic forgetting of earlier style categories.
- The staged approach combined with the dual-branch decoupling yields state-of-the-art scores on style similarity, content consistency, and aesthetic quality.
- Reverse triplet synthesis supplies the million-scale paired data needed to support the curriculum stages.
Where Pith is reading between the lines
- The same staged decoupling might apply to other generative tasks where content and style features compete, such as text-to-image editing.
- If the curriculum order proves robust, it could reduce the need for heavy hyperparameter search when adapting the model to new style domains.
- Testing whether the method still works when users supply arbitrary real-world style images rather than the paper's synthetic triplets would reveal practical limits.
- The memory rehearsal mechanism might extend to continual learning settings beyond style transfer, such as incremental addition of new artistic domains.
Load-bearing premise
That semantic style dominance in mixed one-stage training is the main reason for poor content preservation and that moving from semantic to texture styles in stages will resolve it without creating new problems.
What would settle it
A controlled comparison in which a single-stage SC-DiT trained on a balanced mix of semantic and texture styles matches or exceeds the multi-stage version on content consistency metrics would falsify the claim that curriculum ordering is required.
Figures





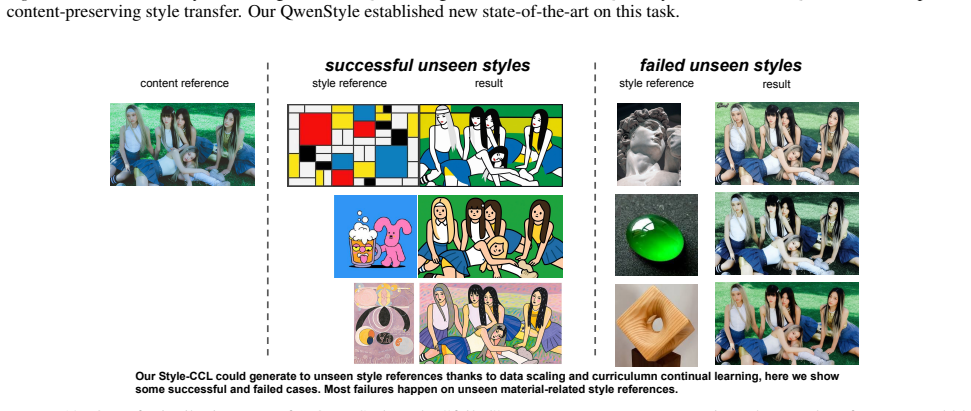


read the original abstract
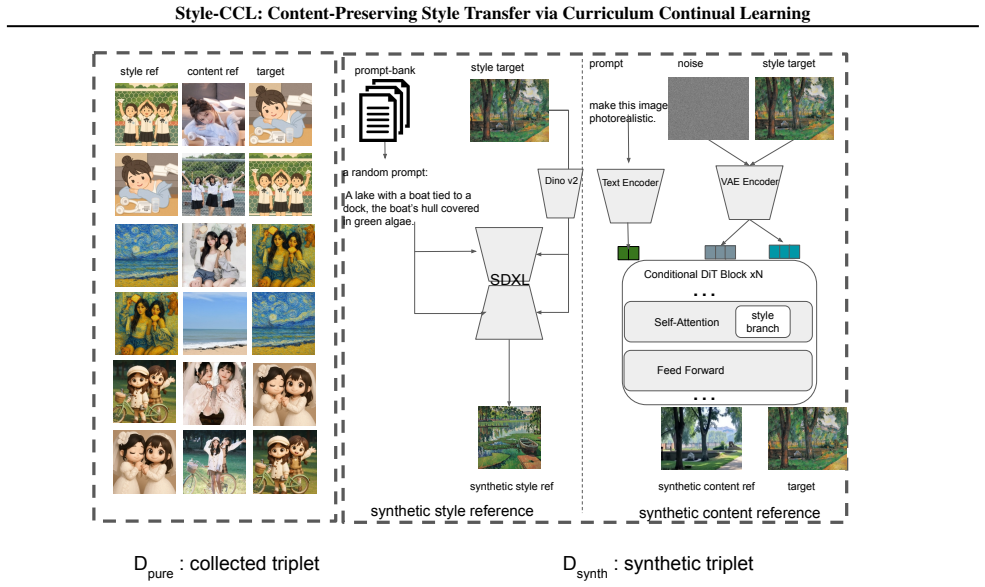
Content-Preserving Style transfer, given content and style references, remains challenging for Diffusion Transformers (DiTs) due to entangled content and style features. With a reverse triplet synthesis pipeline to build a million-scale training set and a dual-branch Style-Content DiT (SC-DiT) that decouples style and content via separate ROPE embeddings and causal masking, we observe that such a one-stage training paradigm on mixed style categories causes semantic styles to dominate, hindering texture style learning, and harming content preservation. To address these issues, we propose Style-CCL, a Multi-Stage Curriculum Continual Learning framework that trains SC-DiT from semantic (easy) to texture (hard) styles, and from clean to synthetic data, with Random Memory Rehearsal across stages to avoid catastrophic forgetting. Extensive experiments demonstrate that our Style-CCL achieves state-of-the-art performance in three core metrics: style similarity, content consistency, and aesthetic quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Style-CCL, a multi-stage curriculum continual learning framework for content-preserving style transfer with Diffusion Transformers. It describes a reverse triplet synthesis pipeline to construct a million-scale training set, a dual-branch Style-Content DiT (SC-DiT) that decouples style and content features using separate RoPE embeddings and causal masking, and a curriculum that progresses from semantic (easy) to texture (hard) styles and from clean to synthetic data, augmented by random memory rehearsal to mitigate catastrophic forgetting. The central claim is that this curriculum resolves semantic-style dominance observed in one-stage training and yields state-of-the-art results on style similarity, content consistency, and aesthetic quality.
Significance. If the experimental claims hold after verification, the work would be significant for DiT-based style transfer by demonstrating that a structured curriculum can address feature dominance and entanglement without requiring changes to the core architecture. The large-scale dataset construction and explicit decoupling mechanism via RoPE and masking are concrete engineering contributions that could be adopted more broadly if shown to be robust.
major comments (2)
- [Abstract / motivation for curriculum] The load-bearing assumption (stated in the abstract) that one-stage training on mixed styles causes semantic styles to dominate texture styles and thereby harms content preservation is not accompanied by quantitative evidence or ablation results showing the magnitude of this dominance or its direct causal link to content metrics. Without such data (e.g., per-style learning curves or content-consistency scores before versus after the curriculum), it remains possible that gains arise primarily from the SC-DiT decoupling or dataset scale rather than the proposed multi-stage progression.
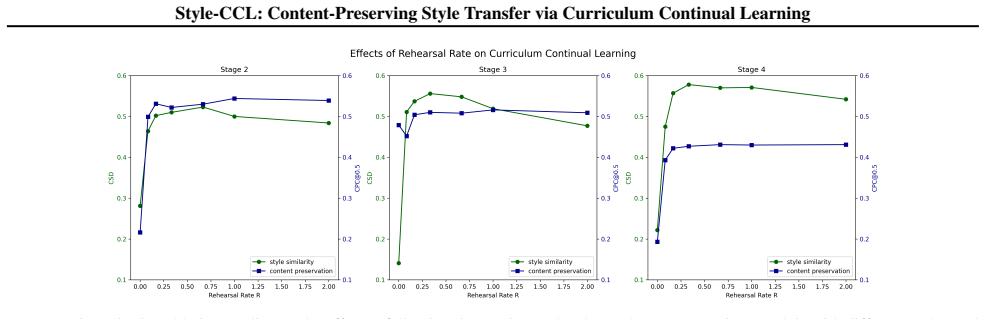
- [Curriculum Continual Learning framework description] The claim that random memory rehearsal across stages prevents catastrophic forgetting and enables stable progression from semantic to texture styles lacks reported controls for rehearsal ratio, memory size, or stability metrics; if rehearsal introduces its own hyperparameter sensitivity or instability, the curriculum's advantage over simpler one-stage or two-stage baselines would be undermined.
minor comments (2)
- [Abstract] The abstract asserts SOTA performance on three metrics but supplies no numerical deltas, baseline names, or error bars; adding a compact results table or key numbers would strengthen the summary.
- [SC-DiT architecture] Notation for the dual-branch SC-DiT (separate RoPE and causal masking) is introduced without an accompanying diagram or equation block clarifying how the branches interact during forward and reverse diffusion passes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the motivation for the curriculum and the rehearsal controls. We address the points below and will revise the manuscript to incorporate additional evidence and ablations.
read point-by-point responses
-
Referee: [Abstract / motivation for curriculum] The load-bearing assumption (stated in the abstract) that one-stage training on mixed styles causes semantic styles to dominate texture styles and thereby harms content preservation is not accompanied by quantitative evidence or ablation results showing the magnitude of this dominance or its direct causal link to content metrics. Without such data (e.g., per-style learning curves or content-consistency scores before versus after the curriculum), it remains possible that gains arise primarily from the SC-DiT decoupling or dataset scale rather than the proposed multi-stage progression.
Authors: We agree that the manuscript would benefit from explicit quantitative evidence supporting the semantic-style dominance observation. The current text notes the observation from our one-stage experiments, but does not include the requested per-style curves or direct before/after content-consistency comparisons. In the revision we will add these ablations (learning curves across style categories and content-consistency deltas) to quantify the dominance effect and isolate its contribution from SC-DiT and dataset scale. revision: yes
-
Referee: [Curriculum Continual Learning framework description] The claim that random memory rehearsal across stages prevents catastrophic forgetting and enables stable progression from semantic to texture styles lacks reported controls for rehearsal ratio, memory size, or stability metrics; if rehearsal introduces its own hyperparameter sensitivity or instability, the curriculum's advantage over simpler one-stage or two-stage baselines would be undermined.
Authors: We acknowledge the absence of hyperparameter controls and stability metrics for the rehearsal component. The manuscript describes the use of random memory rehearsal but does not report ablations on ratio, memory size, or quantitative stability measures. We will add these experiments and metrics in the revision to demonstrate robustness and confirm the curriculum's advantage over one-stage and two-stage baselines. revision: yes
Circularity Check
No circularity; empirical claims rest on experiments, not self-referential derivations
full rationale
The paper presents an empirical method (SC-DiT decoupling plus multi-stage curriculum with rehearsal) whose central claims are validated solely through experimental metrics on style similarity, content consistency, and aesthetic quality. No equations, derivations, or mathematical reductions appear in the provided text. The observation that semantic styles dominate in one-stage training is framed as an experimental finding used to motivate the curriculum, not as a fitted parameter or self-defined quantity that is then relabeled as a prediction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The derivation chain is therefore self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
Preserving Color in Neural Artistic Style Transfer
13 Style-CCL: Content-Preserving Style Transfer via Curriculum Continual Learning Leon A Gatys, Matthias Bethge, Aaron Hertzmann, and Eli Shechtman. Preserving color in neural artistic style transfer.arXiv preprint arXiv:1606.05897,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language mod- els.arXiv preprint arXiv:2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
US Patent 10,713,493. Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer
Robin Rombach, A. Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image syn- thesis with latent diffusion models.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
work page 2022
-
[12]
arXiv preprint arXiv:2404.01292 (2024)
Gowthami Somepalli, Anubhav Gupta, Kamal Gupta, Shra- may Palta, Micah Goldblum, Jonas Geiping, Abhinav Shrivastava, and Tom Goldstein. Measuring style similar- ity in diffusion models.arXiv preprint arXiv:2404.01292,
-
[13]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score- based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[14]
Yiren Song, Cheng Liu, and Mike Zheng Shou. Omnicon- sistency: Learning style-agnostic consistency from paired stylization data.arXiv preprint arXiv:2505.18445,
-
[15]
14 Style-CCL: Content-Preserving Style Transfer via Curriculum Continual Learning Jan Stanczuk, Georgios Batzolis, Teo Deveney, and Carola- Bibiane Sch¨onlieb. Your diffusion model secretly knows the dimension of the data manifold.arXiv preprint arXiv:2212.12611,
-
[16]
arXiv preprint arXiv:2411.15098 (2024)
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and uni- versal control for diffusion transformer.arXiv preprint arXiv:2411.15098, 3,
-
[17]
Styleadapter: A unified stylized image generation model.arXiv preprint arXiv:2309.01770, 2023a
Zhouxia Wang, Xintao Wang, Liangbin Xie, Zhongang Qi, Ying Shan, Wenping Wang, and Ping Luo. Styleadapter: A unified stylized image generation model.arXiv preprint arXiv:2309.01770, 2023a. Zhizhong Wang, Lei Zhao, and Wei Xing. Stylediffusion: Controllable disentangled style transfer via diffusion mod- els. InProceedings of the IEEE/CVF international con-...
-
[18]
Shiwen Zhang. Tfcnet: Temporal fully connected networks for static unbiased temporal reasoning.arXiv preprint arXiv:2203.05928,
-
[19]
Shiwen Zhang. Fast Imagic: Solving Overfitting in Text- guided Image Editing via Disentangled UNet with For- getting Mechanism and Unified Vision-Language Opti- mization. InPMLR, 2024a. Shiwen Zhang. Hyper-parameter tuning for text guided image editing.arXiv preprint arXiv:2407.21703, 2024b. Shiwen Zhang, Sheng Guo, Weilin Huang, Matthew R Scott, and Limi...
-
[20]
Shiwen Zhang, Zhuowei Chen, Lang Chen, and Yanze Wu. Cdst: Color disentangled style transfer for uni- versal style reference customization.arXiv preprint arXiv:2506.13770, 2025a. Shiwen Zhang, Haibin Huang, Chi Zhang, and Xuelong Li. Qwenstyle: Content-preserving style transfer with qwen- image-edit.arXiv preprint arXiv:2601.06202, 2026a. Shiwen Zhang, Yi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.