When Top-1 Fails: Calibrating LoRA Monitors for Masked Diffusion LMs
Pith reviewed 2026-06-26 00:47 UTC · model grok-4.3
The pith
Top-1 argmax concentration fires falsely in every tested LoRA configuration for discrete diffusion language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
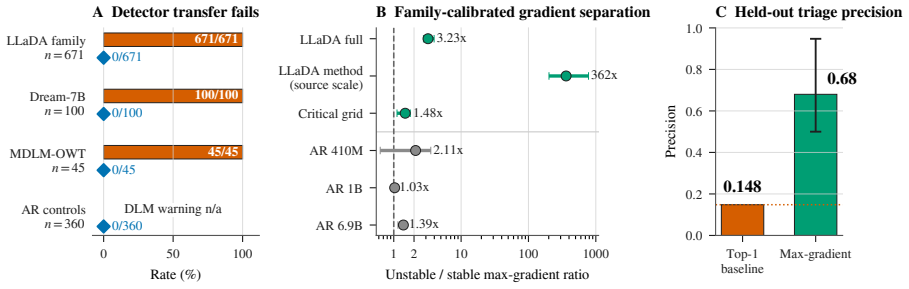
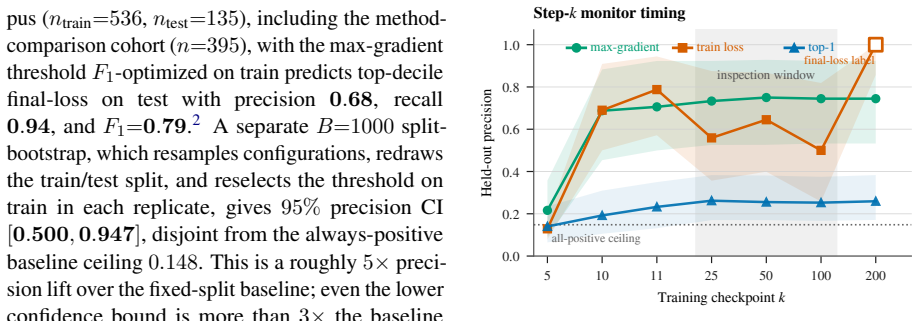
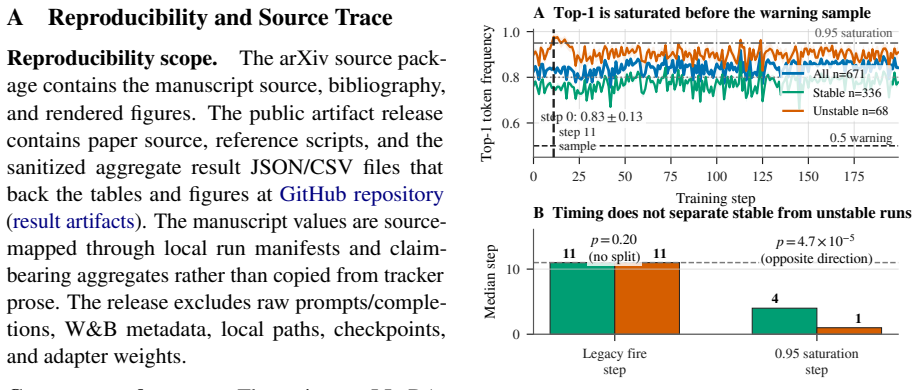
The top-1 argmax concentration warning fires for every one of the 816 LoRA/PEFT configurations tested across three DLM families, yet logs show zero actual collapses at the 200-step horizon, yielding zero precision. This occurs because of pre-equilibrium saturation where the top-1 concentration reaches high values before optimization begins and becomes insensitive to later training outcomes. In contrast, a threshold on the maximum LoRA gradient norm, optimized on training data, identifies the top-decile final-loss configurations with precision 0.68 and F1=0.79 on a held-out LLaDA-family split, outperforming the top-1 baseline. Autoregressive controls and cross-family threshold failures indica
What carries the argument
Maximum LoRA gradient norm as a parameter-side signal that samples gradient routing during early training rather than token concentration.
If this is right
- Drop top-1 concentration as a PEFT alarm for these models.
- Log maximum gradient norm early in training to track behavior.
- Calibrate thresholds separately for each DLM family before routing runs for inspection.
- Limit use of the gradient norm approach to short-horizon DLM-LoRA rather than treating it as universal.
Where Pith is reading between the lines
- Other early-training parameter signals could substitute for gradient norm in different PEFT setups.
- Extending the horizon beyond 200 steps might change how well the gradient norm threshold separates stable from unstable runs.
- The same monitoring shift could be tested on non-diffusion language model families to see if token concentration fails there too.
Load-bearing premise
The logged record of zero collapses across all 816 runs correctly identifies training stability and the train-optimized threshold on max gradient norm will generalize to new runs outside the specific held-out LLaDA split.
What would settle it
Additional LoRA configurations run on a fourth DLM family outside the three tested, with the same gradient norm threshold checked for whether it still separates top-decile final loss runs above baseline precision.
Figures
read the original abstract
Discrete diffusion language model (DLM) fine-tuning inherits inexpensive diagnostics from denoising-time confidence monitors, but their PEFT-training meaning is untested. We test top-1 argmax concentration as a collapse warning. Across 816 LoRA/PEFT configurations from three DLM families, the warning fires for every configuration while logs record 0/816 actual collapses at the 200 step horizon, giving zero precision. The cause is pre-equilibrium saturation: top-1 concentration is already high before optimization and quickly becomes insensitive to final training stability. We then evaluate max LoRA gradient norm, a parameter-side signal that samples gradient routing rather than token concentration. On a pooled held-out LLaDA-family split, a train-optimized threshold identifies top-decile final-loss configurations with precision 0.68 and F1=0.79, above the all-positive top-1 baseline even at the lower split-bootstrap confidence bound. Autoregressive controls and cross-family threshold failures bound the result to short-horizon DLM-LoRA inspection rather than a universal collapse detector. Workflow: drop top-1 as a PEFT alarm, log max-gradient early in training, and calibrate thresholds per DLM family before routing runs for inspection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that top-1 argmax concentration is ineffective as a collapse warning during LoRA/PEFT fine-tuning of discrete diffusion LMs: across 816 configurations from three DLM families the signal fires for every run while training logs record 0/816 collapses at the 200-step horizon (zero precision). It attributes this to pre-equilibrium saturation and instead evaluates max LoRA gradient norm as a parameter-side monitor; on a pooled held-out LLaDA-family split a threshold optimized on the training portion yields precision 0.68 and F1 0.79 for identifying top-decile final-loss runs, outperforming the all-positive top-1 baseline, though results are bounded to short-horizon DLM-LoRA settings with noted cross-family failures.
Significance. If the empirical findings hold after addressing verification gaps, the work supplies a large-scale (816-run) demonstration that token-concentration monitors inherited from denoising are unreliable for PEFT stability in DLMs and that a simple gradient-norm signal can provide usable early warning for high final-loss configurations within a single family. The scale of the experiment and the explicit bounding to short-horizon, family-specific use are strengths; the result would usefully caution practitioners against default reliance on top-1 while motivating per-family calibration of parameter-side monitors.
major comments (4)
- [Abstract and §4 (experiment description)] Abstract and the section reporting the 816-run experiment: the central zero-precision claim for top-1 rests on the logged record of 0/816 collapses, yet no definition of 'collapse,' no operationalization in the logs, and no verification procedure for those logs are supplied. This is load-bearing for both the failure of top-1 and the contrast with the gradient-norm monitor.
- [Results on max LoRA gradient norm] Section presenting the gradient-norm results: the reported precision 0.68 and F1 0.79 are obtained after explicitly optimizing the threshold on the training split of the LLaDA pooled data and evaluating only on its held-out portion; the performance metric is therefore defined in terms of the fitted parameter, undermining the claim of an independent test.
- [Results on max LoRA gradient norm] Same results section: positive numbers are shown only for the LLaDA held-out split while the manuscript itself records cross-family threshold failures; without corresponding numbers or failure analysis for the other two DLM families under the identical 200-step protocol, the generalization statement cannot be assessed.
- [Results on max LoRA gradient norm] Results section: although the text references a 'lower split-bootstrap confidence bound,' no error bars, bootstrap distributions, or statistical significance tests accompany the 0.68/0.79 figures, making it impossible to judge whether the improvement over the all-positive baseline is reliable.
minor comments (2)
- [Abstract] Abstract: the sentence 'above the all-positive top-1 baseline even at the lower split-bootstrap confidence bound' would benefit from stating the exact baseline precision value for direct comparison.
- [Method] Notation: 'max LoRA gradient norm' is used without an explicit equation or pseudocode definition of how the norm is aggregated across layers or steps; a short formal definition would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will revise the manuscript to improve clarity, completeness, and rigor where the comments identify gaps.
read point-by-point responses
-
Referee: [Abstract and §4 (experiment description)] Abstract and the section reporting the 816-run experiment: the central zero-precision claim for top-1 rests on the logged record of 0/816 collapses, yet no definition of 'collapse,' no operationalization in the logs, and no verification procedure for those logs are supplied. This is load-bearing for both the failure of top-1 and the contrast with the gradient-norm monitor.
Authors: We agree that the manuscript insufficiently specifies the definition of 'collapse,' its operationalization, and the verification procedure. This is a substantive omission. In the revision we will add an explicit definition and a dedicated paragraph in §4 describing how collapse was identified from the training logs (distinct from the top-decile final-loss proxy used later for the gradient-norm monitor) together with the verification steps applied to confirm the 0/816 count. revision: yes
-
Referee: [Results on max LoRA gradient norm] Section presenting the gradient-norm results: the reported precision 0.68 and F1 0.79 are obtained after explicitly optimizing the threshold on the training split of the LLaDA pooled data and evaluating only on its held-out portion; the performance metric is therefore defined in terms of the fitted parameter, undermining the claim of an independent test.
Authors: The referee correctly notes that the threshold was optimized on the training split. We view this as standard calibration for a family-specific monitor rather than a claim of a universal pre-specified threshold; the held-out split still provides an estimate of within-family generalization. In revision we will explicitly state that the threshold is training-optimized, report the numerical threshold value, and qualify the independence claim accordingly while retaining the held-out metrics. revision: partial
-
Referee: [Results on max LoRA gradient norm] Same results section: positive numbers are shown only for the LLaDA held-out split while the manuscript itself records cross-family threshold failures; without corresponding numbers or failure analysis for the other two DLM families under the identical 200-step protocol, the generalization statement cannot be assessed.
Authors: We agree that quantitative illustration of the cross-family failures would allow readers to assess the bounding statement. In the revision we will add a short paragraph or supplementary table reporting the performance (or lack of improvement over baseline) obtained when the LLaDA-derived threshold is applied to the other two families under the same 200-step protocol. revision: yes
-
Referee: [Results on max LoRA gradient norm] Results section: although the text references a 'lower split-bootstrap confidence bound,' no error bars, bootstrap distributions, or statistical significance tests accompany the 0.68/0.79 figures, making it impossible to judge whether the improvement over the all-positive baseline is reliable.
Authors: The manuscript already performed split-bootstrap resampling to obtain the lower confidence bound. In revision we will add error bars derived from the bootstrap distribution, a brief description of the resampling procedure, and a direct comparison (with the associated interval) against the all-positive baseline to permit evaluation of reliability. revision: yes
Circularity Check
No circularity: empirical counts and held-out evaluation are independent of inputs
full rationale
The paper performs an empirical sweep over 816 LoRA configurations, directly counts top-1 warnings versus logged collapses (0/816), and reports a threshold optimized on a training split then evaluated on a held-out LLaDA split. These steps are standard data reporting and cross-validation; the held-out metrics are not forced by the fit itself, no equations reduce to self-definition, and no load-bearing self-citations or uniqueness theorems appear. The derivation chain consists of experimental observation rather than any closed loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- train-optimized threshold on max LoRA gradient norm
axioms (2)
- domain assumption Logged record of zero collapses across 816 runs accurately reflects absence of training instability
- domain assumption Held-out LLaDA-family split is representative for evaluating monitor performance
Reference graph
Works this paper leans on
-
[1]
2024 , howpublished =
Electricity Map: Live. 2024 , howpublished =
2024
-
[3]
2025 , url =
Bie, Tiwei and Cao, Maosong and Chen, Kun and Du, Lun and Gong, Mingliang and Gong, Zhuochen and Gu, Yanmei and Hu, Jiaqi and Huang, Zenan and Lan, Zhenzhong and Li, Chengxi and Li, Chongxuan and Li, Jianguo and Li, Zehuan and Liu, Huabin and Liu, Lin and Lu, Guoshan and Lu, Xiaocheng and Ma, Yuxin and Tan, Jianfeng and Wei, Lanning and Wen, Ji-Rong and X...
2025
-
[4]
A Rank Stabilization Scaling Factor for Fine-Tuning with
Kalajdzievski, Damjan , journal =. A Rank Stabilization Scaling Factor for Fine-Tuning with. 2023 , url =
2023
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Simple and Effective Masked Diffusion Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[7]
2022 , url =
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =. 2022 , url =
2022
-
[10]
Proceedings of the 41st International Conference on Machine Learning , pages =
Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , url =
2024
-
[11]
2026 , url =
Wang, Shuaidi and Zhuang, Zhan and HUANG, Ruping and Zhang, Yu , journal =. 2026 , url =
2026
-
[13]
Sensitivity-
Zhang, Hao and Huang, Bo and Li, Zhenjia and Xiao, Xi and Leong, Hui Yi and Zhang, Zumeng and Long, Xinwei and Wang, Tianyang and Xu, Hao , booktitle =. Sensitivity-. 2025 , pages =
2025
-
[14]
2025 , pages =
Chang, Yupeng and Guo, Chenlu and Chang, Yi and Wu, Yuan , booktitle =. 2025 , pages =
2025
-
[15]
Riemannian Optimization for
Park, JuneYoung and Kang, Minjae and Lee, Seongbae and Lee, Haegang and Kim, Seongwan and Lee, Jaeho , booktitle =. Riemannian Optimization for. 2025 , pages =
2025
-
[16]
2025 , url =
Kuiper, Ruurd Jan Anthonius and de Groot, Lars and van Es, Bram and van Smeden, Maarten and Bagheri, Ayoub , booktitle =. 2025 , url =
2025
-
[18]
2025 , url =
Xu, Guowei and Xu, Wenxin and Zhao, Jiawang and Ma, Kaisheng , journal =. 2025 , url =
2025
-
[19]
Mangrulkar, Sourab and Gugger, Sylvain and Debut, Lysandre and Belkada, Younes and Paul, Sayak and Bossan, Benjamin , year =
-
[20]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages =
Transformers: State-of-the-Art Natural Language Processing , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages =. 2020 , publisher =
2020
-
[21]
2024 , url =
Zhao, Jiawei and Zhang, Zhenyu and Chen, Beidi and Wang, Zhangyang and Anandkumar, Anima and Tian, Yuandong , journal =. 2024 , url =
2024
-
[22]
Tuning the Implicit Regularizer of Masked Diffusion Language Models: Enhancing Generalization via Insights from k -
Huang, Jianhao and Mirzasoleiman, Baharan , journal =. Tuning the Implicit Regularizer of Masked Diffusion Language Models: Enhancing Generalization via Insights from k -. 2026 , url =
2026
-
[24]
2025 , url =
Zhu, Fengqi and You, Zebin and Xing, Yipeng and Huang, Zenan and Liu, Lin and Zhuang, Yihong and Lu, Guoshan and Wang, Kangyu and Wang, Xudong and Wei, Lanning and Guo, Hongrui and Hu, Jiaqi and Ye, Wentao and Chen, Tieyuan and Li, Chenchen and Tang, Chengfu and Feng, Haibo and Hu, Jun and Zhou, Jun and Zhang, Xiaolu and Lan, Zhenzhong and Zhao, Junbo and...
2025
-
[25]
Tianao Zhang and Zhiteng Li and Xianglong Yan and Haotong Qin and Yong Guo and Yulun Zhang , booktitle =. Quant-d. 2026 , url =
2026
-
[26]
Chengyue Wu and Hao Zhang and Shuchen Xue and Zhijian Liu and Shizhe Diao and Ligeng Zhu and Ping Luo and Song Han and Enze Xie , booktitle =. Fast-d. 2026 , url =
2026
-
[27]
ICML , year =
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling , author =. ICML , year =
-
[28]
2026 , howpublished =
2026
-
[31]
International Conference on Learning Representations (ICLR) , year =
Measuring Massive Multitask Language Understanding , author =. International Conference on Learning Representations (ICLR) , year =
-
[32]
When Scaling Meets
Zhang, Biao and Liu, Zhongtao and Cherry, Colin and Firat, Orhan , booktitle =. When Scaling Meets. 2024 , url =
2024
-
[33]
NeurIPS , year =
Are Emergent Abilities of Large Language Models a Mirage? , author =. NeurIPS , year =
-
[34]
2024 , url =
Meng, Fanxu and Wang, Zhaohui and Zhang, Muhan , booktitle =. 2024 , url =
2024
-
[35]
2025 , url =
Jung, Yeonjoon and Ahn, Daehyun and Kim, Hyungjun and Kim, Taesu and Park, Eunhyeok , booktitle =. 2025 , url =
2025
-
[36]
2025 , url =
Li, Zhizhong and Sajadmanesh, Sina and Li, Jingtao and Lyu, Lingjuan , booktitle =. 2025 , url =
2025
-
[39]
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O'Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. 2023. https://arxiv.org/abs/2304.01373 Pythia: A suite for analyzing large language models across training and scaling . In ICML
Pith/arXiv arXiv 2023
-
[40]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, Chengxi Li, Chongxuan Li, Jianguo Li, Zehuan Li, Huabin Liu, Lin Liu, Guoshan Lu, Xiaocheng Lu, Yuxin Ma, and 12 others. 2025. https://arxiv.org/abs/2512.15745 LLaDA2.0 : Scaling up diffusion language models to 100b . arXiv preprint ar...
Pith/arXiv arXiv 2025
-
[41]
Yupeng Chang, Chenlu Guo, Yi Chang, and Yuan Wu. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.34 LoRA-MGPO : Mitigating double descent in low-rank adaptation via momentum-guided perturbation optimization . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 648--659. Association for Computational Linguistics
-
[42]
Mark Chen and 1 others. 2021. https://arxiv.org/abs/2107.03374 Evaluating large language models trained on code . arXiv preprint arXiv:2107.03374
Pith/arXiv arXiv 2021
-
[43]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. https://arxiv.org/abs/2110.14168 Training verifiers to solve math word problems . arXiv preprint arXiv:2110.14168
Pith/arXiv arXiv 2021
-
[44]
Alexander Conzelmann, Albert Catalan-Tatjer, and Shiwei Liu. 2026. https://arxiv.org/abs/2605.06366 Layer collapse in diffusion language models . arXiv preprint arXiv:2605.06366
Pith/arXiv arXiv 2026
-
[45]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. https://arxiv.org/abs/2305.14314 Qlora: Efficient finetuning of quantized llms . arXiv preprint arXiv:2305.14314
Pith/arXiv arXiv 2023
-
[46]
Electricity Maps . 2024. Electricity map: Live CO _2 emissions of electricity consumption. https://app.electricitymaps.com
2024
-
[47]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. https://arxiv.org/abs/2009.03300 Measuring massive multitask language understanding . In International Conference on Learning Representations (ICLR)
Pith/arXiv arXiv 2021
-
[48]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://arxiv.org/abs/2106.09685 LoRA : Low-rank adaptation of large language models . In International Conference on Learning Representations (ICLR)
Pith/arXiv arXiv 2022
-
[49]
Jianhao Huang and Baharan Mirzasoleiman. 2026. https://arxiv.org/abs/2601.22450 Tuning the implicit regularizer of masked diffusion language models: Enhancing generalization via insights from k - P arity . arXiv preprint arXiv:2601.22450
Pith/arXiv arXiv 2026
-
[50]
Yeonjoon Jung, Daehyun Ahn, Hyungjun Kim, Taesu Kim, and Eunhyeok Park. 2025. https://openreview.net/forum?id=8wvOMQ2Olw GraLoRA : Granular low-rank adaptation for parameter-efficient fine-tuning . In Advances in Neural Information Processing Systems
2025
-
[51]
Damjan Kalajdzievski. 2023. https://arxiv.org/abs/2312.03732 A rank stabilization scaling factor for fine-tuning with LoRA . arXiv preprint arXiv:2312.03732
Pith/arXiv arXiv 2023
-
[52]
Ruurd Jan Anthonius Kuiper, Lars de Groot, Bram van Es, Maarten van Smeden, and Ayoub Bagheri. 2025. https://doi.org/10.18653/v1/2025.emnlp-demos.8 LAD : LoRA -adapted diffusion . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations
-
[53]
Tianyi Li, Mingda Chen, Bowei Guo, and Zhiqiang Shen. 2025 a . https://arxiv.org/abs/2508.10875 A survey on diffusion language models . arXiv preprint arXiv:2508.10875
Pith/arXiv arXiv 2025
-
[54]
Zhizhong Li, Sina Sajadmanesh, Jingtao Li, and Lingjuan Lyu. 2025 b . https://openreview.net/forum?id=55Lv1unlUL StelLA : Subspace learning in low-rank adaptation using stiefel manifold . In Advances in Neural Information Processing Systems
2025
-
[55]
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. 2024. https://arxiv.org/abs/2402.09353 Dora: Weight-decomposed low-rank adaptation . arXiv preprint arXiv:2402.09353
Pith/arXiv arXiv 2024
-
[56]
Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, and Benjamin Bossan. 2022. PEFT : State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft. Software library
2022
-
[57]
Fanxu Meng, Zhaohui Wang, and Muhan Zhang. 2024. https://arxiv.org/abs/2404.02948 PiSSA : Principal singular values and singular vectors adaptation of large language models . In Advances in Neural Information Processing Systems
arXiv 2024
-
[58]
David Mullett. 2026. https://arxiv.org/abs/2606.00329 Benchmarking recursive-collapse warning claims under matched false-positive control . arXiv preprint arXiv:2606.00329
Pith/arXiv arXiv 2026
-
[59]
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. 2025. https://arxiv.org/abs/2502.09992 Large language diffusion models . arXiv preprint arXiv:2502.09992
Pith/arXiv arXiv 2025
-
[60]
JuneYoung Park, Minjae Kang, Seongbae Lee, Haegang Lee, Seongwan Kim, and Jaeho Lee. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.1143 Riemannian optimization for LoRA on the stiefel manifold . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 20971--20985. Association for Computational Linguistics
-
[61]
Julianna Piskorz, Cristina Pinneri, Alvaro Correia, Motasem Alfarra, Risheek Garrepalli, and Christos Louizos. 2025. https://arxiv.org/abs/2511.21338 Masks can be distracting: On context comprehension in diffusion language models . arXiv preprint arXiv:2511.21338
Pith/arXiv arXiv 2025
-
[62]
Qwen Team, Alibaba . 2026. https://huggingface.co/Qwen/Qwen3.5-9B Qwen3.5-9B model card . Hugging Face model card
2026
-
[63]
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and Volodymyr Kuleshov. 2024. https://arxiv.org/abs/2406.07524 Simple and effective masked diffusion language models . In Advances in Neural Information Processing Systems (NeurIPS)
arXiv 2024
-
[64]
Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. 2023. https://arxiv.org/abs/2304.15004 Are emergent abilities of large language models a mirage? In NeurIPS
arXiv 2023
-
[65]
Shuaidi Wang, Zhan Zhuang, Ruping HUANG, and Yu Zhang. 2026. https://arxiv.org/abs/2605.29716 NaRA : Noise-aware LoRA for parameter-efficient fine-tuning of diffusion LLM s . arXiv preprint arXiv:2605.29716
Pith/arXiv arXiv 2026
-
[66]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, R \'e mi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao , Sylvain Gugger, and 3 others. 2020. https://aclanthology.org/2020.emnlp-demos.6 Transformers: S...
2020
-
[67]
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. 2026. https://openreview.net/forum?id=3Z3Is6hnOT Fast-d LLM : Training-free acceleration of diffusion LLM by enabling KV cache and parallel decoding . In International Conference on Learning Representations (ICLR)
2026
-
[68]
Guowei Xu, Wenxin Xu, Jiawang Zhao, and Kaisheng Ma. 2025. https://arxiv.org/abs/2509.20863 GIFT : Guided importance-aware fine-tuning for diffusion language models . arXiv preprint arXiv:2509.20863
Pith/arXiv arXiv 2025
-
[69]
Jingyi Yang, Yuxian Jiang, Xuhao Hu, Shuang Cheng, Biqing Qi, and Jing Shao. 2026. https://arxiv.org/abs/2604.04215 Dare: Diffusion large language models alignment and reinforcement executor . arXiv preprint arXiv:2604.04215
Pith/arXiv arXiv 2026
-
[70]
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. 2025. https://arxiv.org/abs/2508.15487 Dream 7b: Diffusion large language models . arXiv preprint arXiv:2508.15487
Pith/arXiv arXiv 2025
-
[71]
Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. 2024. https://proceedings.mlr.press/v235/yu24p.html Language models are super mario: Absorbing abilities from homologous models as a free lunch . In Proceedings of the 41st International Conference on Machine Learning, pages 57755--57775
2024
-
[72]
Biao Zhang, Zhongtao Liu, Colin Cherry, and Orhan Firat. 2024. https://arxiv.org/abs/2402.17193 When scaling meets LLM finetuning: The effect of data, model and finetuning method . In ICLR
arXiv 2024
-
[73]
Hao Zhang, Bo Huang, Zhenjia Li, Xi Xiao, Hui Yi Leong, Zumeng Zhang, Xinwei Long, Tianyang Wang, and Hao Xu. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.709 Sensitivity- LoRA : Low-load sensitivity-based fine-tuning for large language models . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 13185--13199. Associat...
-
[74]
Tianao Zhang, Zhiteng Li, Xianglong Yan, Haotong Qin, Yong Guo, and Yulun Zhang. 2026. https://openreview.net/forum?id=HD7tuVakmR Quant-d LLM : Post-training extreme low-bit quantization for diffusion large language models . In International Conference on Learning Representations (ICLR)
2026
-
[75]
Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, and Yuandong Tian. 2024. https://arxiv.org/abs/2403.03507 GaLore : Memory-efficient LLM training by gradient low-rank projection . arXiv preprint arXiv:2403.03507
Pith/arXiv arXiv 2024
-
[76]
Fengqi Zhu, Zebin You, Yipeng Xing, Zenan Huang, Lin Liu, Yihong Zhuang, Guoshan Lu, Kangyu Wang, Xudong Wang, Lanning Wei, Hongrui Guo, Jiaqi Hu, Wentao Ye, Tieyuan Chen, Chenchen Li, Chengfu Tang, Haibo Feng, Jun Hu, Jun Zhou, and 7 others. 2025. https://arxiv.org/abs/2509.24389 LLaDA - MoE : A sparse MoE diffusion language model . arXiv preprint arXiv:...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.