Control-Plane Placement Shapes Forgetting: An Architectural Study of Agent Memory Across Thirteen System Configurations
Pith reviewed 2026-06-27 03:58 UTC · model grok-4.3
The pith
Placing LLM assistance at the mutation-time control plane recovers intent-aware deletion and achieves 91.7-93.2% overall forgetting accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
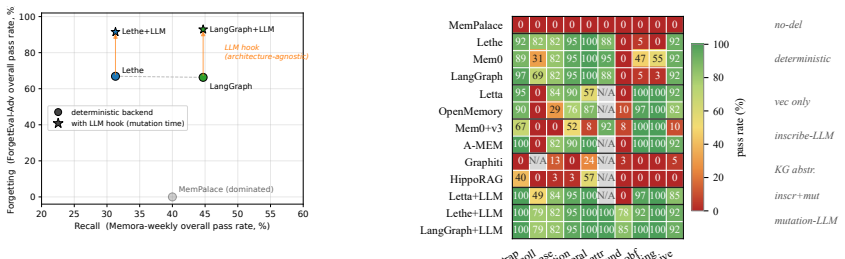
Control-plane placement shapes forgetting recovery in agent memory systems. Comparing thirteen configurations on a 385-case adversarial surface reveals three regimes with complementary coverage: deterministic primitives suffice for lexical/temporal categories but fail canonicalization; inscribe-time LLM recovers canonicalization but not intent-aware deletion; mutation-time hooks recover intent-aware deletion at 78-85% and achieve 91.7-93.2% overall, at modest cost, without changing the recall path. The evaluation uses ForgetEval, a 1000-case templated suite plus adversarial layer scored by deterministic substring match.
What carries the argument
Control-plane placement of LLM assistance for memory mutations (supersede, release, purge) in agent systems.
If this is right
- Deterministic primitives achieve high accuracy on lexical and temporal forgetting categories but only 5% on identifier-obfuscation and 0% on cross-lingual.
- Inscribe-time LLM use achieves 100% on canonicalization but 0% on prefix-collision and compound-fact for intent-aware deletion.
- Mutation-time hook achieves 78-85% on intent-aware deletion and 91.7-93.2% overall.
- The approach costs $0.17 per 385-case run with 2.3s per case latency compared to 64-191ms for deterministic.
- The recall path remains unchanged.
Where Pith is reading between the lines
- Agent designers could combine multiple placements for broader coverage without increasing recall latency.
- The ForgetEval suite could be extended to test other memory operations beyond forgetting.
- Production systems might benefit from monitoring which forgetting modes occur most frequently to choose placement.
- The asymmetry in canonicalization recovery suggests that inscription and mutation phases have distinct roles in memory integrity.
Load-bearing premise
The 385-case adversarial surface and 1000-case ForgetEval suite, scored by deterministic substring match, capture the forgetting failure modes that arise in actual production agent deployments.
What would settle it
A production deployment log or new test set where the mutation-time hook fails to recover intent-aware deletion at 78-85% rates.
Figures
read the original abstract
Where an LLM sits in an agent memory pipeline -- between the recall plane that retrieves stored facts (extensively benchmarked) and the control plane that mutates them via supersede, release, purge (largely untested) -- shapes which forgetting failure modes the system recovers. Comparing thirteen system configurations on a 385-case adversarial surface, we observe three placement regimes with partly complementary coverage: deterministic primitives suffice for lexical/temporal categories but fail canonicalization (5% on identifier-obfuscation, 0% on cross-lingual); inscribe-time LLM recovers canonicalization (100%) but cannot help intent-aware deletion (0% on prefix-collision and compound-fact); a mutation-time hook recovers intent-aware deletion (78-85%) and brightens nearly all categories simultaneously (91.7-93.2% overall, $0.17 per 385-case run, 2.3s/case mutation latency vs. 64-191ms/case deterministic, recall path unchanged). We expose the trade-off via ForgetEval, a 1000-case templated suite plus a 385-case adversarial layer (132 hand-crafted + 253 LLM-drafted oracle-validated) scored by deterministic substring match, paired with a six-method Adapter Protocol with honest N/A scoring that lets heterogeneous memory stores enter in 130 lines. Admission is corroborated by 10-annotator IAA (Fleiss' kappa = 0.958) and a 77-case external-authored subset (four blind contributors) that replicates the canonicalization asymmetry and amplifies the joint-placement lift (+27.8 pt). Production failures are predominantly forgetting failures rather than recall failures, yet existing benchmarks measure only recall. ForgetEval and all adapters are released under MIT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the architectural placement of the control plane (handling supersede, release, purge mutations) relative to the recall plane in LLM agent memory systems determines recoverable forgetting failure modes. Comparing 13 configurations on ForgetEval—a 1000-case templated suite plus 385-case adversarial layer (132 hand-crafted + 253 LLM-drafted, oracle-validated), scored by deterministic substring match—the authors identify three regimes: deterministic primitives suffice for lexical/temporal categories but fail canonicalization (5% on identifier-obfuscation, 0% on cross-lingual); inscribe-time LLM recovers canonicalization (100%) but not intent-aware deletion (0% on prefix-collision/compound-fact); a mutation-time hook recovers intent-aware deletion (78-85%) while achieving 91.7-93.2% overall, at $0.17 per 385-case run and 2.3s/case latency (vs. 64-191ms deterministic), with recall path unchanged. Additional contributions include a 6-method Adapter Protocol, 10-annotator IAA (Fleiss' kappa 0.958), 77-case external replication (+27.8 pt joint-placement lift), and public release of ForgetEval/adapters under MIT.
Significance. If the results hold under robust evaluation, the work usefully demonstrates that forgetting is architecturally distinct from recall and that placement choices yield complementary coverage of failure modes, with concrete cost/latency trade-offs. The release of the benchmark, adapters, and external replication data strengthens reproducibility and could inform agent system design. The honest N/A scoring and high IAA are positive features.
major comments (3)
- [Evaluation / ForgetEval scoring] Evaluation section (scoring protocol for ForgetEval): The central quantitative claims (78-85% recovery on intent-aware deletion; 91.7-93.2% overall) rest on deterministic substring match. This metric is least secure for prefix-collision and compound-fact categories, where semantic leakage or paraphrased retention could occur without a substring hit yet still be counted as recovered; the paper provides no semantic validation or human judgment baseline to confirm that substring absence reliably indicates successful intent-aware deletion.
- [Results / Placement regimes] Results on placement regimes (Table or Figure reporting per-category rates): The distinction among the three regimes depends on the 385-case adversarial surface plus 1000-case templated suite being representative; however, no mapping or justification is given showing that these cases cover the forgetting failure modes observed in production agent deployments, weakening the claim that the mutation-time hook 'brightens nearly all categories simultaneously.'
- [External validation] External replication (77-case subset): While the external-authored cases replicate the canonicalization asymmetry, the manuscript does not detail selection criteria, exclusion rules, or raw per-case scores for this subset, making it difficult to assess whether it independently corroborates the main findings or introduces post-hoc selection effects.
minor comments (2)
- [Abstract / Cost analysis] The abstract reports specific numbers ($0.17 per run, 2.3s/case) without a corresponding breakdown or table in the main text showing how these were computed across the 13 configurations.
- [Methods / Adapter Protocol] Notation for the six-method Adapter Protocol is introduced without a dedicated diagram or pseudocode listing the 130 lines, which would aid readers implementing heterogeneous stores.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on evaluation rigor, representativeness, and reproducibility. We address each major comment below with proposed revisions to strengthen the manuscript where the points identify genuine gaps.
read point-by-point responses
-
Referee: [Evaluation / ForgetEval scoring] Evaluation section (scoring protocol for ForgetEval): The central quantitative claims (78-85% recovery on intent-aware deletion; 91.7-93.2% overall) rest on deterministic substring match. This metric is least secure for prefix-collision and compound-fact categories, where semantic leakage or paraphrased retention could occur without a substring hit yet still be counted as recovered; the paper provides no semantic validation or human judgment baseline to confirm that substring absence reliably indicates successful intent-aware deletion.
Authors: We agree that deterministic substring match can overstate recovery on intent-aware categories if models paraphrase while retaining semantics. The metric is conservative for detecting retention (any exact substring triggers failure) but does not rule out paraphrased leakage. We will revise the evaluation section to acknowledge this limitation explicitly and add a human judgment baseline: two annotators will score a random sample of 50 cases from prefix-collision and compound-fact categories for semantic retention, reporting agreement with the substring metric. revision: yes
-
Referee: [Results / Placement regimes] Results on placement regimes (Table or Figure reporting per-category rates): The distinction among the three regimes depends on the 385-case adversarial surface plus 1000-case templated suite being representative; however, no mapping or justification is given showing that these cases cover the forgetting failure modes observed in production agent deployments, weakening the claim that the mutation-time hook 'brightens nearly all categories simultaneously.'
Authors: ForgetEval cases were derived from failure modes documented in prior agent memory literature (canonicalization, temporal, lexical, and intent-aware deletion). The adversarial layer was built to target these via hand-crafted and LLM-drafted examples with oracle validation. We will add a dedicated paragraph in the benchmark section mapping each category to cited production-style failure reports from the literature. However, a direct empirical mapping to specific proprietary production logs is outside the paper's scope and would require access to non-public data; we will note this as a limitation on generalizability to all deployments. revision: partial
-
Referee: [External validation] External replication (77-case subset): While the external-authored cases replicate the canonicalization asymmetry, the manuscript does not detail selection criteria, exclusion rules, or raw per-case scores for this subset, making it difficult to assess whether it independently corroborates the main findings or introduces post-hoc selection effects.
Authors: We will expand the external validation subsection to specify: selection was stratified random sampling from the 385 adversarial cases (ensuring coverage of all 8 categories); exclusion applied only to the 12 cases where the four blind contributors failed to reach consensus on oracle labels (leaving 77); and raw per-case scores plus contributor annotations will be released in the public repository. This removes any ambiguity about post-hoc selection. revision: yes
Circularity Check
Empirical architectural comparison with no derivation chain or self-referential fitting
full rationale
The paper is an empirical study comparing thirteen memory-system configurations on the released ForgetEval benchmark (1000 templated + 385 adversarial cases scored by deterministic substring match). No equations, derivations, fitted parameters, or predictions appear in the provided text; results are direct observations of performance differences across placement regimes. The Adapter Protocol and scoring method are explicitly defined and released rather than derived from prior self-citations. No load-bearing self-citation, ansatz smuggling, or renaming of known results is present. The work is self-contained against external benchmarks and does not reduce any claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 385 adversarial cases and 1000-case templated suite capture the relevant forgetting failure modes in real agent systems
Reference graph
Works this paper leans on
-
[1]
Evaluating Memory in
Hu, Yuanzhe and Wang, Yu and McAuley, Julian , booktitle =. Evaluating Memory in. 2026 , note =
2026
-
[2]
Findings of the Association for Computational Linguistics (ACL Findings) , year =
From Recall to Forgetting: Benchmarking Long-Term Memory for Personalized Agents , author =. Findings of the Association for Computational Linguistics (ACL Findings) , year =
-
[3]
Findings of the Association for Computational Linguistics (EMNLP Findings) , year =
To Forget or Not? Towards Practical Knowledge Unlearning for Large Language Models , author =. Findings of the Association for Computational Linguistics (EMNLP Findings) , year =
-
[4]
2024 , url =
Jin, Zhuoran and Cao, Pengfei and Wang, Chenhao and He, Zhitao and Yuan, Hongbang and Li, Jiachun and Chen, Yubo and Liu, Kang and Zhao, Jun , booktitle =. 2024 , url =
2024
-
[5]
and Kolter, J
Maini, Pratyush and Feng, Zhili and Schwarzschild, Avi and Lipton, Zachary C. and Kolter, J. Zico , journal =. 2024 , url =
2024
-
[6]
2025 , note =
Forgetful but Faithful: A Cognitive Memory Architecture and Benchmark for Privacy-Aware Generative Agents , author =. 2025 , note =
2025
-
[7]
Zhao, Yujie and Yuan, Boqin and Huang, Junbo and Yuan, Haocheng and Yu, Zhongming and Xu, Haozhou and Hu, Lanxiang and Shankarampeta, Abhilash and Huang, Zimeng and Ni, Wentao and Tian, Yuandong and Zhao, Jishen , year =
-
[9]
Gu, Yingjie and Xiong, Wenjian and Wang, Liqiang and Ren, Pengcheng and Li, Chao and Zhang, Xiaojing and Guo, Yijuan and Sun, Qi and Ma, Jingyao and Shi, Shidang , year =
-
[10]
He, Zexue and Wang, Yu and Zhi, Churan and Hu, Yuanzhe and Chen, Tzu-Ping and Yin, Lang and Chen, Ze and Wu, Tong Arthur and Ouyang, Siru and Wang, Zihan and Pei, Jiaxin and McAuley, Julian and Choi, Yejin and Pentland, Alex , year =
-
[11]
Wang, Yuyao and Zhang, Zhongjian and Chi, Mo and Yu, Kaichi and Li, Yuhan and Peng, Miao and Tong, Bing and Zhang, Chen and Zhou, Yan and Li, Jia , year =
-
[12]
Agentic Unlearning: When
Wang, Bin and Wang, Fan and Wang, Pingping and Cong, Jinyu and Yu, Yang and Yin, Yilong and Han, Zhongyi and Wei, Benzheng , year =. Agentic Unlearning: When
-
[13]
Don't Ask the
Reddy, Vikas and Challaram, Sumanth , year =. Don't Ask the
-
[14]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle =. Locating and Editing Factual Associations in. 2022 , note =
2022
-
[15]
ICLR , year =
Mass-Editing Memory in a Transformer , author =. ICLR , year =
-
[16]
and Potts, Christopher and Chen, Danqi , booktitle =
Zhong, Zexuan and Wu, Zhengxuan and Manning, Christopher D. and Potts, Christopher and Chen, Danqi , booktitle =. 2023 , note =
2023
-
[17]
Findings of the Association for Computational Linguistics (ACL Findings) , year =
Model Editing at Scale leads to Gradual and Catastrophic Forgetting , author =. Findings of the Association for Computational Linguistics (ACL Findings) , year =
-
[18]
2025 , note =
Tan, Haoran and Zhang, Zeyu and Ma, Chen and Chen, Xu and Dai, Quanyu and Dong, Zhenhua , booktitle =. 2025 , note =
2025
-
[21]
2024 , howpublished =
MemPalace: An open-source AI memory system , author =. 2024 , howpublished =
2024
-
[23]
2024 , howpublished =
Letta: Stateful agents framework (successor to MemGPT) , author =. 2024 , howpublished =
2024
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) , year =
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[27]
2024 , howpublished =
Cognee: Memory layer for AI agents , author =. 2024 , howpublished =
2024
-
[28]
ICLR , year =
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , author =. ICLR , year =
-
[29]
EACL , year =
MTEB: Massive Text Embedding Benchmark , author =. EACL , year =
-
[30]
NeurIPS Datasets and Benchmarks , year =
BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models , author =. NeurIPS Datasets and Benchmarks , year =
-
[31]
Ebbinghaus, Hermann , year =
-
[32]
Coding processes in human memory , pages =
Theoretical implications of directed forgetting , author =. Coding processes in human memory , pages =
-
[33]
Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =
Remembering can cause forgetting: Retrieval dynamics in long-term memory , author =. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =
-
[34]
IEEE Symposium on Security and Privacy , year =
Towards Making Systems Forget with Machine Unlearning , author =. IEEE Symposium on Security and Privacy , year =
-
[35]
IEEE Symposium on Security and Privacy , year =
Machine Unlearning , author =. IEEE Symposium on Security and Privacy , year =
-
[36]
2016 , howpublished =
Regulation (EU) 2016/679 of the European Parliament and of the Council (General Data Protection Regulation) , author =. 2016 , howpublished =
2016
-
[37]
1998 , publisher =
Pathmarks , author =. 1998 , publisher =
1998
-
[38]
2024 , howpublished =
sqlite-vec: A vector search SQLite extension , author =. 2024 , howpublished =
2024
-
[39]
2024 , howpublished =
fastembed: Fast, accurate, lightweight embeddings via ONNX runtime , author =. 2024 , howpublished =
2024
-
[40]
SIGIR , pages =
Reciprocal Rank Fusion outperforms Condorcet and individual rank learning methods , author =. SIGIR , pages =
-
[41]
2011 , howpublished =
Ed25519: high-speed high-security signatures , author =. 2011 , howpublished =
2011
-
[42]
2025 , note =
Graphiti: Temporal Knowledge Graphs for Memory , author =. 2025 , note =
2025
-
[43]
2025 , howpublished =
2025
-
[44]
Saad Alqithami. 2025. https://arxiv.org/abs/2512.12856 Forgetful but faithful: A cognitive memory architecture and benchmark for privacy-aware generative agents . Introduces FiFA benchmark and Memory-Aware Retention Schema (MaRS); six forgetting policies for privacy-preserving generative agents. arXiv:2512.12856
arXiv 2025
-
[45]
Anderson and Barbara A
Michael C. Anderson and Barbara A. Spellman. 1995. Remembering can cause forgetting: Retrieval dynamics in long-term memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21(5):1063--1087
1995
-
[46]
Robert A. Bjork. 1972. Theoretical implications of directed forgetting. Coding processes in human memory, pages 217--235
1972
-
[47]
Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot
Lucas Bourtoule, Varun Chandrasekaran, Christopher A. Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. 2021. Machine unlearning. In IEEE Symposium on Security and Privacy. ArXiv:1912.03817. SISA: Sharded, Isolated, Sliced, Aggregated; retrain affected shard only
arXiv 2021
-
[48]
machine unlearning
Yinzhi Cao and Junfeng Yang. 2015. Towards making systems forget with machine unlearning. In IEEE Symposium on Security and Privacy. Coined the term "machine unlearning". Summation-form training for asymptotically-faster point removal
2015
-
[49]
CaviraOSS Contributors . 2025. OpenMemory : Self-hosted long-term AI memory engine. https://github.com/CaviraOSS/OpenMemory. Open-source persistent memory store for LLM applications, MIT-licensed
2025
-
[50]
Prateek Chhikara and 1 others. 2025. https://arxiv.org/abs/2504.19413 Mem0: Building production-ready ai agents with scalable long-term memory . arXiv preprint arXiv:2504.19413. Also appearing at ECAI 2025
Pith/arXiv arXiv 2025
-
[51]
Cognee contributors . 2024. Cognee: Memory layer for ai agents. https://github.com/topoteretes/cognee. No peer-reviewed evaluation published; graph updates documented as destructive chunk-replace
2024
-
[52]
Cormack, Charles L
Gordon V. Cormack, Charles L. A. Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In SIGIR, pages 758--759
2009
-
[53]
U ber das Ged \
Hermann Ebbinghaus. 1885. \"U ber das Ged \"a chtnis: Untersuchungen zur experimentellen Psychologie . Duncker & Humblot. The original forgetting-curve experiment, on himself, using non-sense syllables
-
[54]
Right to erasure
European Parliament and Council . 2016. Regulation (eu) 2016/679 of the european parliament and of the council (general data protection regulation). Official Journal of the European Union, L 119, 1--88. See in particular Article 17, "Right to erasure"
2016
-
[55]
Alex Garcia. 2024. sqlite-vec: A vector search sqlite extension. https://github.com/asg017/sqlite-vec
2024
-
[56]
Yingjie Gu, Wenjian Xiong, Liqiang Wang, Pengcheng Ren, Chao Li, Xiaojing Zhang, Yijuan Guo, Qi Sun, Jingyao Ma, and Shidang Shi. 2026. https://arxiv.org/abs/2604.20300 FSFM : A biologically-inspired framework for selective forgetting of agent memory . Framework + taxonomy of forgetting mechanisms (passive decay / active deletion / safety-triggered / adap...
Pith/arXiv arXiv 2026
-
[57]
Akshat Gupta, Anurag Rao, and Gopala Anumanchipalli. 2024. Model editing at scale leads to gradual and catastrophic forgetting. In Findings of the Association for Computational Linguistics (ACL Findings). Shows knowledge editing causes catastrophic forgetting of unrelated facts
2024
-
[58]
Bernal Jim \'e nez Guti \'e rrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. 2024. https://arxiv.org/abs/2405.14831 Hipporag: Neurobiologically inspired long-term memory for large language models . Advances in Neural Information Processing Systems (NeurIPS)
arXiv 2024
-
[59]
Zexue He, Yu Wang, Churan Zhi, Yuanzhe Hu, Tzu-Ping Chen, Lang Yin, Ze Chen, Tong Arthur Wu, Siru Ouyang, Zihan Wang, Jiaxin Pei, Julian McAuley, Yejin Choi, and Alex Pentland. 2026. https://arxiv.org/abs/2602.16313 MemoryArena : Benchmarking agent memory in interdependent multi-session agentic tasks . Memory-Agent-Environment loops; couples memorization ...
arXiv 2026
-
[60]
Yuanzhe Hu, Yu Wang, and Julian McAuley. 2026. https://arxiv.org/abs/2507.05257 Evaluating memory in LLM agents via incremental multi-turn interactions . In International Conference on Learning Representations (ICLR). Introduces MemoryAgentBench evaluating four memory competencies: Accurate Retrieval, Test-Time Learning, Long-Range Understanding, Selectiv...
Pith/arXiv arXiv 2026
-
[61]
Zhuoran Jin, Pengfei Cao, Chenhao Wang, Zhitao He, Hongbang Yuan, Jiachun Li, Yubo Chen, Kang Liu, and Jun Zhao. 2024. https://arxiv.org/abs/2406.10890 RWKU : Benchmarking real-world knowledge unlearning for large language models . In NeurIPS
arXiv 2024
-
[62]
Letta contributors . 2024. Letta: Stateful agents framework (successor to memgpt). https://github.com/letta-ai/letta
2024
-
[63]
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C. Lipton, and J. Zico Kolter. 2024. https://arxiv.org/abs/2401.06121 TOFU : A task of fictitious unlearning for LLMs . arXiv preprint arXiv:2401.06121
Pith/arXiv arXiv 2024
-
[64]
MemPalace contributors . 2024. Mempalace: An open-source ai memory system. https://github.com/mempalace/mempalace. Verbatim-retention memory system; baseline on LongMemEval-S. No deletion / supersession primitives exposed in the public API
2024
-
[65]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in GPT . In NeurIPS. ROME: knowledge-editing method, foundational supersession-of-facts work
2022
-
[66]
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. 2023. Mass-editing memory in a transformer. In ICLR. MEMIT: batch knowledge editing in LLM weights
2023
-
[67]
Niklas Muennighoff, Nouamane Tazi, Lo \" c Magne, and Nils Reimers. 2023. Mteb: Massive text embedding benchmark. In EACL. ArXiv:2210.07316. 56 datasets across 8 task families, 112+ languages
Pith/arXiv arXiv 2023
-
[68]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2023. https://arxiv.org/abs/2310.08560 Memgpt: Towards llms as operating systems . arXiv preprint arXiv:2310.08560
Pith/arXiv arXiv 2023
-
[69]
Qdrant team . 2024. fastembed: Fast, accurate, lightweight embeddings via onnx runtime. https://github.com/qdrant/fastembed
2024
-
[70]
Preston Rasmussen and 1 others. 2025. https://arxiv.org/abs/2501.13956 Zep: A temporal knowledge graph architecture for agent memory . arXiv preprint arXiv:2501.13956
Pith/arXiv arXiv 2025
-
[71]
Vikas Reddy and Sumanth Challaram. 2026. https://arxiv.org/abs/2606.01435 Don't ask the LLM to track freshness: A deterministic recipe for memory conflict resolution . On MemoryAgentBench FactConsolidation, deterministic version-aware aggregation (max-serial / max-timestamp) beats LLM-mediated conflict resolution; the bottleneck is post-retrieval assembly...
Pith/arXiv arXiv 2026
-
[72]
Haoran Tan, Zeyu Zhang, Chen Ma, Xu Chen, Quanyu Dai, and Zhenhua Dong. 2025. https://aclanthology.org/2025.findings-acl.989/ MemBench : Towards more comprehensive evaluation on the memory of LLM -based agents . In Findings of the Association for Computational Linguistics (ACL Findings). Factual vs.\ reflective memory evaluation; comprehensive benchmark c...
2025
-
[73]
Nandan Thakur, Nils Reimers, Andreas R \"u ckl \'e , Abhishek Srivastava, and Iryna Gurevych. 2021. Beir: A heterogeneous benchmark for zero-shot evaluation of information retrieval models. In NeurIPS Datasets and Benchmarks. ArXiv:2104.08663. 18 zero-shot IR datasets
Pith/arXiv arXiv 2021
-
[74]
Bozhong Tian, Xiaozhuan Liang, Siyuan Cheng, Qingbin Liu, Mengru Wang, Dianbo Sui, Xi Chen, Huajun Chen, and Ningyu Zhang. 2024. https://arxiv.org/abs/2407.01920 To forget or not? towards practical knowledge unlearning for large language models . In Findings of the Association for Computational Linguistics (EMNLP Findings). Introduces KnowUnDo benchmark w...
arXiv 2024
-
[75]
Md Nayem Uddin, Kumar Shubham, Eduardo Blanco, Chitta Baral, and Gengyu Wang. 2026. https://arxiv.org/abs/2604.20006 From recall to forgetting: Benchmarking long-term memory for personalized agents . In Findings of the Association for Computational Linguistics (ACL Findings). Introduces FAMA (Forgetting-Aware Memory Accuracy), a single aggregate metric th...
Pith/arXiv arXiv 2026
-
[76]
Bin Wang, Fan Wang, Pingping Wang, Jinyu Cong, Yang Yu, Yilong Yin, Zhongyi Han, and Benzheng Wei. 2026 a . https://arxiv.org/abs/2602.17692 Agentic unlearning: When LLM agent meets machine unlearning . Synchronized Backflow Unlearning (SBU): joint unlearning across model parameters and persistent memory pathways. arXiv:2602.17692
arXiv 2026
-
[77]
Yuyao Wang, Zhongjian Zhang, Mo Chi, Kaichi Yu, Yuhan Li, Miao Peng, Bing Tong, Chen Zhang, Yan Zhou, and Jia Li. 2026 b . https://arxiv.org/abs/2605.18421 EvoMemBench : Benchmarking agent memory from a self-evolving perspective . Memory benchmark on scope (in-/cross-episode) x content (knowledge / execution) axes; 15 memory methods. arXiv:2605.18421
Pith/arXiv arXiv 2026
-
[78]
Di Wu and 1 others. 2025. https://arxiv.org/abs/2410.10813 Longmemeval: Benchmarking chat assistants on long-term interactive memory . ICLR. ArXiv:2410.10813. 500 questions across seven categories at two scales (S=115k tokens, M=1.5M tokens)
Pith/arXiv arXiv 2025
-
[79]
Menglin Xia, Xuchao Zhang, Shantanu Dixit, Paramaguru Harimurugan, Rujia Wang, Victor Ruhle, Robert Sim, Chetan Bansal, and Saravan Rajmohan. 2026. https://arxiv.org/abs/2602.03315 Memora: A harmonic memory representation balancing abstraction and specificity . arXiv preprint arXiv:2602.03315. Retrieval-method paper from Microsoft Research using the name ...
arXiv 2026
-
[80]
Wujiang Xu and 1 others. 2025. https://arxiv.org/abs/2502.12110 A-mem: Agentic memory for llm agents . arXiv preprint arXiv:2502.12110
Pith/arXiv arXiv 2025
-
[81]
Zep AI . 2025. Graphiti: Temporal knowledge graphs for memory. https://github.com/getzep/graphiti. Open-source successor to the deprecated Zep CE
2025
-
[82]
Dawen Zhang, Pamela Finckenberg-Broman, Thong Hoang, Shidong Pan, Zhenchang Xing, Mark Staples, and Xiwei Xu. 2023. https://arxiv.org/abs/2307.03941 Right to be forgotten in the era of large language models: Implications, challenges, and solutions . arXiv preprint arXiv:2307.03941. GDPR right-to-be-forgotten compliance challenges for LLMs; surveys differe...
arXiv 2023
-
[83]
Yujie Zhao, Boqin Yuan, Junbo Huang, Haocheng Yuan, Zhongming Yu, Haozhou Xu, Lanxiang Hu, Abhilash Shankarampeta, Zimeng Huang, Wentao Ni, Yuandong Tian, and Jishen Zhao. 2026. https://arxiv.org/abs/2602.22769 AMA-Bench : Evaluating long-horizon memory for agentic applications . Long-horizon agentic memory benchmark covering states, actions, observations...
Pith/arXiv arXiv 2026
-
[84]
Manning, Christopher Potts, and Danqi Chen
Zexuan Zhong, Zhengxuan Wu, Christopher D. Manning, Christopher Potts, and Danqi Chen. 2023. MQUAKE : Assessing knowledge editing in language models via multi-hop questions. In EMNLP. Multi-hop counterfactual evaluation; basis for FactConsolidation in memoryagentbench
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.