First-Token Broadcasters: Mechanistic Origins of Language Identity and Distributed Robustness in Transformers
Pith reviewed 2026-06-26 10:50 UTC · model grok-4.3
The pith
Instruction tuning moves language identity circuits to the first layer by concentrating first-token broadcaster heads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
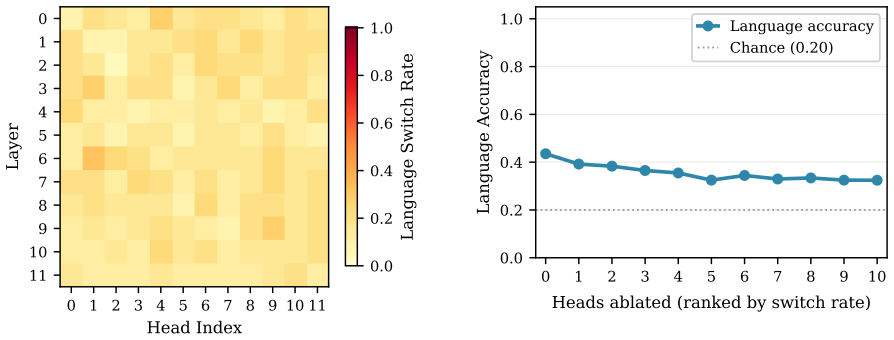
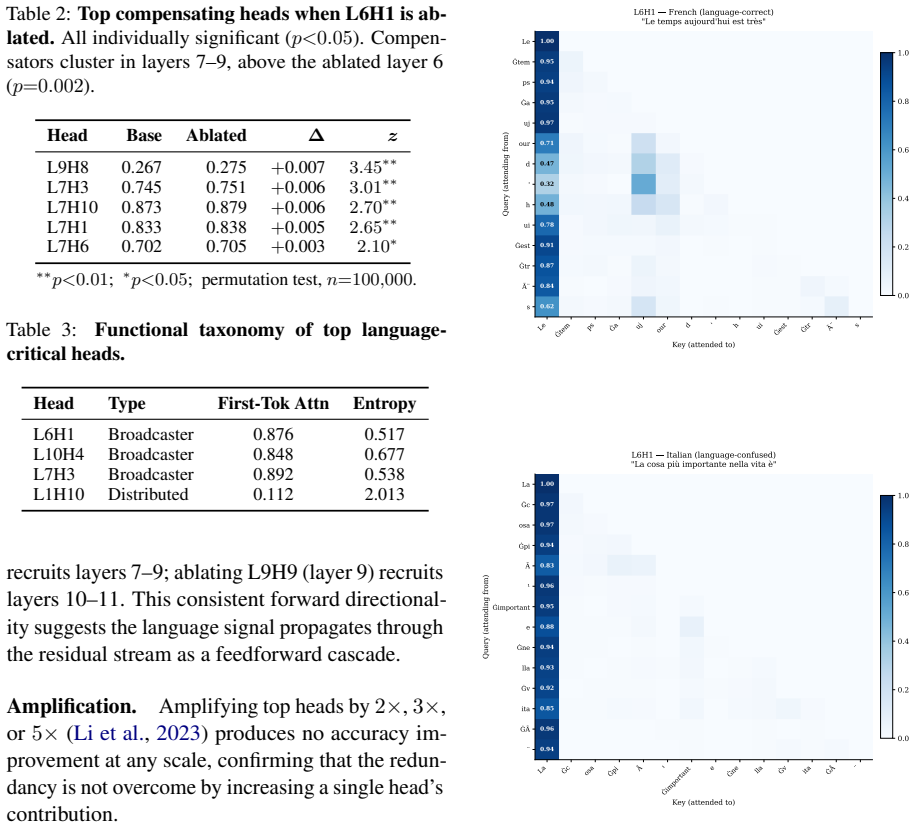
Language Identity Head Ablation applied to matched base and instruct models reveals that instruction tuning reorganizes language identity circuits toward early-layer localization, with the instruct model showing a sharp peak at layer 0 while the base model remains nearly flat; first-token broadcaster heads such as L6H1 in GPT-2 and L0H5 in the instruct model carry the primary causal influence and trigger hierarchical compensation in higher layers when removed.
What carries the argument
Language Identity Head Ablation (LIHA), which zeros one attention head at a time and records the resulting language switch rate across 2,700 parallel prompt-language pairs.
If this is right
- Ablating first-token broadcaster heads raises language switch rate, with L6H1 reaching 0.32 and L0H5 reaching 0.224.
- Compensation after ablation recruits heads only in layers above the removed head and follows a statistically significant directional pattern.
- Base models distribute language identity influence across many heads while instruct models confine it to layer zero.
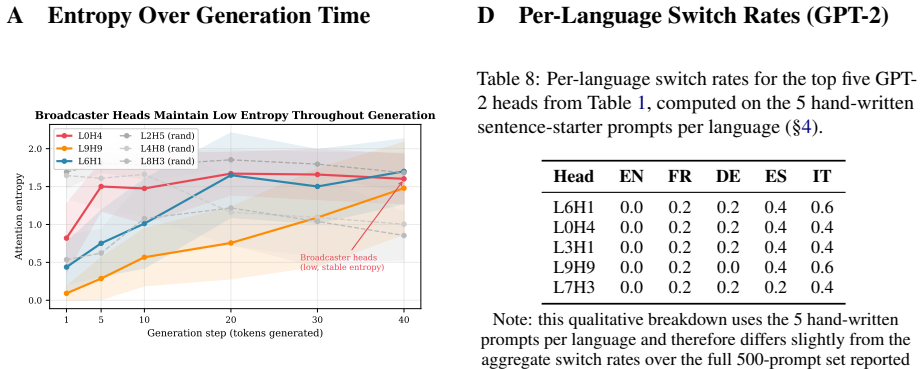
- Non-Latin scripts in GPT-2 are handled at layer 0, matching the locus found in the instruction-tuned model.
Where Pith is reading between the lines
- The observed early-layer concentration may make language output more controllable through targeted interventions at layer 0.
- The hierarchical compensation pattern suggests language identity is maintained by a layered cascade rather than diffuse redundancy.
- Similar reorganization could be tested in other fine-tuning settings to determine whether early localization is specific to instruction tuning.
Load-bearing premise
Zeroing individual attention heads on the parallel dataset isolates their specific causal role in language identity without confounding effects from prompt wording or unmeasured interactions among heads.
What would settle it
Ablating the reported heads such as L6H1 or L0H5 produces no statistically significant rise in language switch rate on the 2,700-pair dataset.
Figures
read the original abstract
Why do multilingual language models sometimes generate in the wrong language, and why is this so hard to fix? We introduce Language Identity Head Ablation (LIHA), a causal intervention that zeros each attention head individually and measures the resulting language switch rate across a parallel dataset of 2,700 prompt-language pairs spanning seven languages. Applied to GPT-2, LIHA identifies a small set of first-token broadcaster heads - led by L6H1 (switch rate 0.32, 3.23 $\sigma$ above the population mean) - that attend persistently to the first prompt token, propagating its language signal throughout generation. Compensatory redistribution when heads are ablated is statistically significant (p < $10^{-5}$) and follows a directional, hierarchical pattern: compensation always recruits heads in layers above the ablated head, suggesting a feedforward cascade rather than global diffusion. To probe how training regime shapes these circuits, we apply LIHA to a controlled pair - Qwen2.5-1.5B-Base and Qwen2.5-1.5B-Instruct - identical in architecture and size, differing only in training. The base model is nearly flat (max SR=0.016, 200/336 heads at SR=0.0); the instruct model concentrates causal influence sharply at layer 0, led by L0H5 (SR=0.224, 8.93 $\sigma$ above mean), with all other layers near zero. This controlled comparison provides direct causal evidence that instruction tuning reorganizes language identity circuits toward early-layer localization. Extended experiments with Chinese and Russian confirm that first-token broadcasting is script-specific in GPT-2, with non-Latin languages handled at layer 0 - the same locus as the instruction-tuned model. Code and data will be released upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Language Identity Head Ablation (LIHA), which zeros individual attention heads and measures resulting language switch rates on a 2,700-pair parallel dataset spanning seven languages. It identifies first-token broadcaster heads in GPT-2 (e.g., L6H1 with switch rate 0.32, 3.23σ above mean) that attend to the first prompt token, along with statistically significant upward compensatory redistribution (p < 10^{-5}). A controlled comparison of architecture-matched Qwen2.5-1.5B base and instruct models shows the base model is nearly flat (max SR=0.016, 200/336 heads at SR=0.0) while the instruct model concentrates influence at layer 0 (L0H5, SR=0.224, 8.93σ above mean), supporting the claim that instruction tuning reorganizes language identity circuits toward early-layer localization. Extended experiments indicate script-specific first-token broadcasting.
Significance. If the results hold, the work supplies causal evidence on how training regime shapes language identity mechanisms, with implications for controlling multilingual generation errors. Strengths include the architecture-matched base-instruct pair enabling direct comparison and the commitment to release code and data, which supports reproducibility and follow-up verification.
major comments (2)
- [LIHA description (abstract)] LIHA description (abstract): the central claim that single-head ablation on the 2,700-pair dataset isolates the causal contribution of heads to language identity (and thereby demonstrates reorganization) is not supported without explicit controls or tests for confounds from prompt construction (how language is cued or left implicit) and dataset biases across the seven languages; the reported compensation pattern alone does not rule out these alternatives.
- [Qwen2.5 base-vs-instruct comparison (abstract)] Qwen2.5 base-vs-instruct comparison (abstract): the conclusion of early-layer localization in the instruct model rests on the assumption that ablation effects are not driven by unmeasured interactions with non-ablated components or prompt-specific sensitivities; without additional verification (e.g., multi-head ablations or prompt-variation controls), the layer-0 concentration (L0H5) could arise independently of circuit reorganization.
minor comments (2)
- [Abstract] The precise definition of switch rate, the population mean used for σ calculations, and the exact statistical test yielding p < 10^{-5} should be stated explicitly in the main text rather than deferred.
- [Results] The handling of zero switch-rate heads in the population statistics (200/336 heads at SR=0.0) and any sensitivity of results to the choice of parallel dataset construction details merit a brief methods appendix.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below with clarifications on our design and indicate planned revisions.
read point-by-point responses
-
Referee: [LIHA description (abstract)] LIHA description (abstract): the central claim that single-head ablation on the 2,700-pair dataset isolates the causal contribution of heads to language identity (and thereby demonstrates reorganization) is not supported without explicit controls or tests for confounds from prompt construction (how language is cued or left implicit) and dataset biases across the seven languages; the reported compensation pattern alone does not rule out these alternatives.
Authors: The 2,700-pair parallel dataset matches semantic content across languages, isolating the language cue while controlling for content-related biases. Prompts cue language explicitly via the first token, which is the target of our attention analysis for broadcaster heads. The seven languages are represented in balanced pairs. The compensation pattern (p < 10^{-5}, upward and layer-directional) is one line of evidence; it is supplemented by the identification of heads with extreme switch rates and their consistent first-token attention. We will add an explicit discussion of these controls and remaining limitations in a revised limitations section. revision: partial
-
Referee: [Qwen2.5 base-vs-instruct comparison (abstract)] Qwen2.5 base-vs-instruct comparison (abstract): the conclusion of early-layer localization in the instruct model rests on the assumption that ablation effects are not driven by unmeasured interactions with non-ablated components or prompt-specific sensitivities; without additional verification (e.g., multi-head ablations or prompt-variation controls), the layer-0 concentration (L0H5) could arise independently of circuit reorganization.
Authors: The base and instruct models are identical in architecture and parameter count and differ solely in training regime, enabling attribution of the flat (max SR=0.016) versus concentrated (L0H5 at 8.93σ) distributions to instruction tuning. Single-head ablation is the intended method for isolating per-head contributions. While multi-head ablations and systematic prompt variations would add robustness, the magnitude and layer-specificity of the observed effects make independent artifactual explanations unlikely. We will incorporate additional prompt-variation results or a discussion of their value in the revision. revision: partial
Circularity Check
No circularity: empirical ablation study with no derivations or self-referential reductions
full rationale
The paper presents an empirical method (LIHA) involving head ablations on existing models (GPT-2, Qwen2.5 base/instruct pairs) and reports measured switch rates on a parallel dataset. Central claims rest on controlled comparisons of ablation outcomes across training regimes, with no equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations that reduce the result to its inputs by construction. The work is self-contained against external benchmarks via direct intervention measurements.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Individual head ablation isolates causal contributions to language identity without major unaccounted side effects on the rest of the network.
- domain assumption The parallel prompt dataset provides an unbiased measure of language switching across the seven languages tested.
Reference graph
Works this paper leans on
-
[1]
Transformer Circuits Thread , year =
A Mathematical Framework for Transformer Circuits , author =. Transformer Circuits Thread , year =
-
[2]
Interpretability in the Wild: A Circuit for Indirect Object Identification in
Wang, Kevin and Alexandre, Luc and Conmy, Arthur and Variengien, Arthur and Steinhardt, Jacob , booktitle =. Interpretability in the Wild: A Circuit for Indirect Object Identification in. 2023 , url =
2023
-
[3]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle =. Locating and Editing Factual Associations in. 2022 , url =
2022
-
[4]
Proceedings of ACL , year =
Unsupervised Cross-lingual Representation Learning at Scale , author =. Proceedings of ACL , year =
-
[5]
How Language-Neutral is Multilingual
Libovick. How Language-Neutral is Multilingual. Proceedings of ACL , year =
-
[6]
Wendler, Chris and Veselovsky, Veniamin and Monea, Giovanni and West, Robert , booktitle =. Do. 2024 , url =
2024
-
[7]
Language Contamination Helps Explains the Cross-lingual Capabilities of E nglish Pretrained Models
Blevins, Terra and Zettlemoyer, Luke , booktitle =. Language Contamination Helps Explains the Cross-lingual Capabilities of. 2022 , address =. doi:10.18653/v1/2022.emnlp-main.233 , pages =
-
[8]
Understanding and Mitigating Language Confusion in LLM s
Marchisio, Kelly and Ko, Wei-Yin and B. Understanding and Mitigating Language Confusion in. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2024.emnlp-main.380 , pages =
-
[9]
Findings of ACL , year =
Plug-and-Play Document Modules for Pre-trained Models , author =. Findings of ACL , year =
-
[10]
Proceedings of ACL , year =
Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models , author =. Proceedings of ACL , year =
-
[11]
Proceedings of EMNLP , year =
Multilingual Mechanistic Interpretability: Cross-Lingual Circuits in Large Language Models , author =. Proceedings of EMNLP , year =
-
[12]
ICLR Workshop , year =
Understanding Intermediate Layers Using Linear Classifier Probes , author =. ICLR Workshop , year =
-
[13]
2019 , url =
Tenney, Ian and Das, Dipanjan and Pavlick, Ellie , booktitle =. 2019 , url =
2019
-
[14]
and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J. and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J. ...
2023
-
[15]
Advances in Neural Information Processing Systems , volume =
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[16]
OpenAI Blog , volume =
Language Models are Unsupervised Multitask Learners , author =. OpenAI Blog , volume =. 2019 , url =
2019
-
[17]
Language Detection Library for
Nakatani, Shuyo , year =. Language Detection Library for
-
[18]
Costa-juss. The. Transactions of the Association for Computational Linguistics , volume =. 2022 , url =
2022
-
[19]
Macdougall and Hannah McLean and Neel Nanda , title =
Arthur Conmy and Augustine N. Macdougall and Hannah McLean and Neel Nanda , title =. Advances in Neural Information Processing Systems , volume =
-
[20]
arXiv preprint arXiv:2412.15115 , year =
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =
-
[21]
arXiv preprint arXiv:2211.05100 , year=
Bloom: A 176b-parameter open-access multilingual language model , author=. arXiv preprint arXiv:2211.05100 , year=
-
[22]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
SilVar: Speech-Driven Multimodal Model for Reasoning Visual Question Answering and Object Localization , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.