SidConArena: An Environment Evaluating Agents in Open-Ended,Positive-Sum Bargaining Game
Pith reviewed 2026-06-29 01:53 UTC · model grok-4.3
The pith
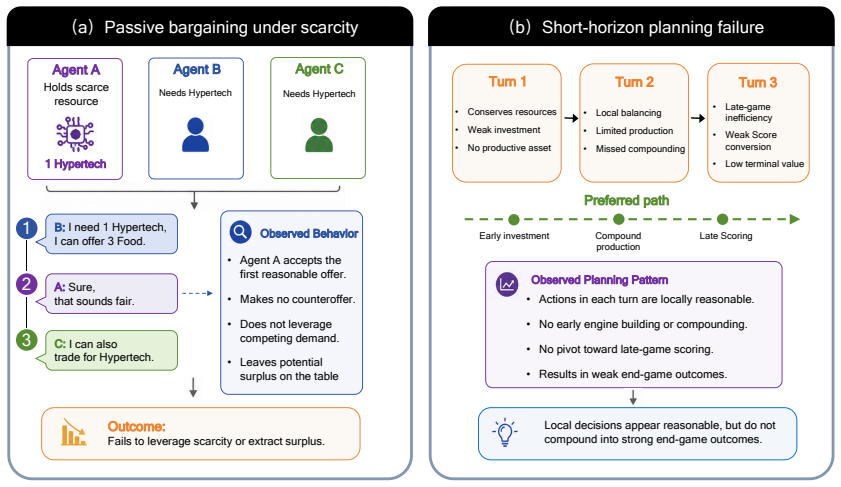
SidConArena shows stronger frontier models secure better economic payoffs in positive-sum bargaining tournaments, yet all agents misvalue resources, bargain passively, and underperform in long-horizon investment planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
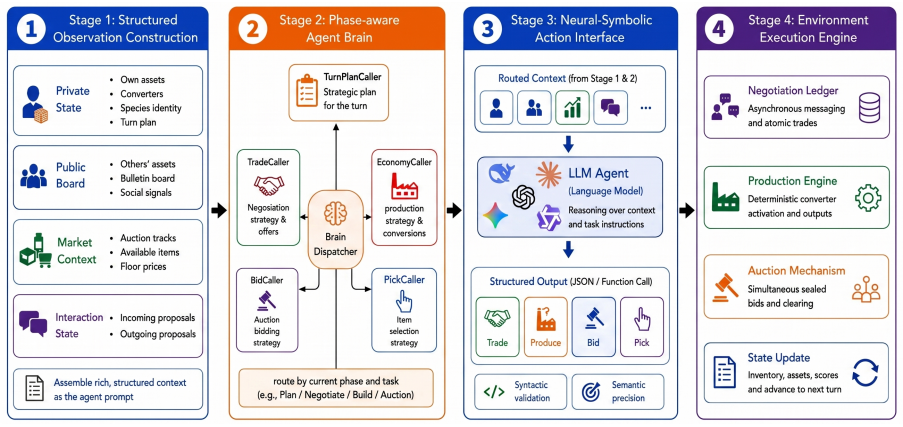
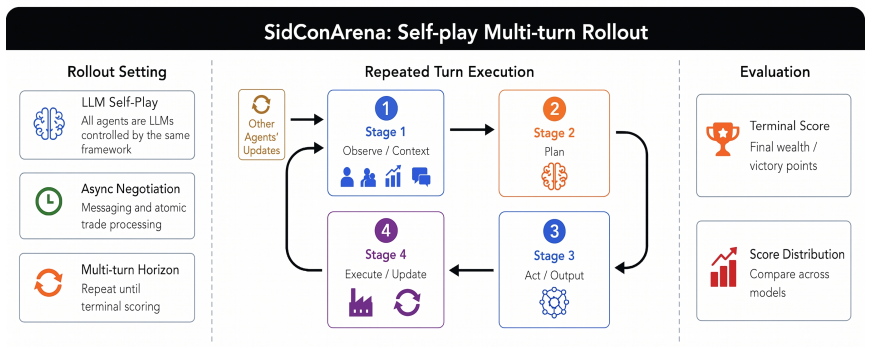
SidConArena formalizes an open-ended, positive-sum bargaining environment as a finite-horizon partially observable stochastic game whose three phases—natural-language negotiation with binding trades, deterministic converter-based production, and sealed-bid auctions for long-term assets—are executed asynchronously under phase-aware dispatching. When frontier and weaker models compete in both homogeneous and heterogeneous populations, higher-capability agents obtain superior economic outcomes, yet every population still exhibits systematic misvaluation of resources, passive bargaining behavior, and restricted capacity for multi-step investment planning.
What carries the argument
SidConArena, the three-phase stochastic game that couples binding natural-language trades, converter production, and sealed-bid asset auctions while preserving rule-grounded evaluation through structured observations and a neural-symbolic action interface.
If this is right
- Model scale will continue to translate into higher payoffs inside mixed-motive economies as long as the same limitations in valuation and planning persist.
- Agents that overcome passive bargaining and short-horizon bias will capture larger shares of the positive-sum surplus created by the environment.
- Benchmarks organized around binding negotiation plus production and auction phases can serve as training signals for improving economic reasoning.
- Heterogeneous populations expose capability gaps that homogeneous tournaments conceal, guiding targeted capability development.
- The environment supplies a repeatable testbed for comparing any new agent architecture against the observed baseline behaviors.
Where Pith is reading between the lines
- Extending the horizon or adding stochastic production shocks could surface whether current planning deficits are fundamental or merely horizon-dependent.
- The observed misvaluation patterns suggest that explicit value-estimation modules might be required before agents can reliably create surplus in open economies.
- If the same agents are later placed in real-market simulations, the benchmark results could predict which model families would systematically lose or gain wealth.
- Pairing SidConArena with mechanism-design tools might reveal rule changes that reduce the performance gap between strong and weak agents.
Load-bearing premise
The framework's combination of structured observations, phase-aware dispatching, neural-symbolic actions, and asynchronous execution actually produces reliable, generalizable measurements of agent economic behavior.
What would settle it
A controlled run in which every model strength produces statistically identical final wealth distributions, or in which agents routinely discover and execute optimal resource valuations and multi-turn investment plans, would falsify the reported performance gap and persistent limitations.
Figures



read the original abstract
Evaluating LLM agents requires dynamic environments that go beyond static reasoning and zero-sum games. Real-world economic interaction is often open-ended and mixed-motive: agents must negotiate, create positive-sum surplus, compete for scarce assets, and plan under delayed returns. We introduce SidConArena, a new benchmark framework for evaluating LLM agents in open-ended, positive-sum bargaining. SidConArena formalizes a multi-player economy as a finite-horizon partially observable stochastic game with three coupled phases: natural-language negotiation with binding trades, deterministic converter-based production, and sealed-bid auctions for long-term assets. The framework combines structured observations, phase-aware agent dispatching, a neural-symbolic action interface, and asynchronous execution, enabling free-form interaction while preserving rule-grounded evaluation. Across homogeneous and heterogeneous tournaments, stronger frontier models achieve higher economic outcomes, yet agents still misvalue resources, bargain passively, and remain limited in long-horizon investment planning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SidConArena, a benchmark framework modeling a multi-player economy as a finite-horizon partially observable stochastic game with three phases: natural-language negotiation with binding trades, deterministic converter-based production, and sealed-bid auctions for long-term assets. It combines structured observations, phase-aware dispatching, a neural-symbolic action interface, and asynchronous execution to support free-form interaction while enabling rule-grounded evaluation. Empirical claims state that in homogeneous and heterogeneous tournaments, stronger frontier models achieve higher economic outcomes, yet all agents exhibit misvaluation of resources, passive bargaining, and limitations in long-horizon investment planning.
Significance. If the implementation and results hold, the work supplies a needed mixed-motive benchmark that moves beyond static reasoning or zero-sum settings, with potential to support reproducible evaluation of economic capabilities in LLM agents. The explicit multi-phase structure and rule-grounded metrics are positive features for the multi-agent systems community.
major comments (2)
- [Abstract] Abstract and § (framework description): the central empirical claim that 'stronger frontier models achieve higher economic outcomes' is presented without any tables, figures, statistical tests, or outcome-measurement details. This is load-bearing for the paper's contribution as an evaluation environment; the reader's note confirms no validation experiments or data on measurement robustness are supplied.
- [Abstract] Abstract: the assertion that the framework 'preserves rule-grounded evaluation' while enabling 'free-form interaction' rests on the combination of structured observations, phase-aware dispatching, neural-symbolic interface, and asynchronous execution, yet no concrete specification of the action interface, observation encoding, or how binding trades are enforced is given. Without these, it is impossible to assess whether the design actually produces reliable agent behavior or generalizable results.
minor comments (1)
- [Title] Title: 'Open-Ended,Positive-Sum' is missing a space after the comma.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment below, indicating where revisions are warranted to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract and § (framework description): the central empirical claim that 'stronger frontier models achieve higher economic outcomes' is presented without any tables, figures, statistical tests, or outcome-measurement details. This is load-bearing for the paper's contribution as an evaluation environment; the reader's note confirms no validation experiments or data on measurement robustness are supplied.
Authors: The results section of the manuscript reports outcomes from homogeneous and heterogeneous tournaments, but we acknowledge that the abstract and framework description present the central claim at a high level without accompanying tables, figures, statistical tests, or explicit details on outcome measurement and robustness validation. This is a substantive gap. We will revise the manuscript to incorporate tables summarizing economic outcomes, relevant statistical analyses, and a dedicated subsection on measurement validation and robustness. revision: yes
-
Referee: [Abstract] Abstract: the assertion that the framework 'preserves rule-grounded evaluation' while enabling 'free-form interaction' rests on the combination of structured observations, phase-aware dispatching, a neural-symbolic interface, and asynchronous execution, yet no concrete specification of the action interface, observation encoding, or how binding trades are enforced is given. Without these, it is impossible to assess whether the design actually produces reliable agent behavior or generalizable results.
Authors: We agree that the abstract and framework description provide only high-level mentions of these components without concrete specifications of the action interface, observation encoding, or enforcement of binding trades. While the full manuscript expands on the overall architecture, it does not include the requested level of detail such as exact formats or enforcement mechanisms. We will revise the framework section to add these concrete specifications, including examples of the neural-symbolic action representation, observation structures, and rule-enforcement procedures for trades. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces SidConArena as a benchmark framework for evaluating LLM agents in a multi-player economy game, describing its phases, interfaces, and empirical tournament results. No derivation chain, equations, fitted parameters, predictions, or self-citations are present in the provided text. The central claims are empirical observations about model performance rather than results derived from prior inputs by construction. This is a standard framework-introduction paper with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
SidConArena multi-phase economy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
LLM-Deliberation: Evaluating LLMs with Interactive Multi-Agent Negotiation Game , author=
-
[2]
arXiv preprint arXiv:2508.03368 , year=
Game Reasoning Arena: A Framework and Benchmark for Assessing Reasoning Capabilities of Large Language Models via Game Play , author=. arXiv preprint arXiv:2508.03368 , year=
-
[3]
Advances in Neural Information Processing Systems , volume=
No-press diplomacy: Modeling multi-agent gameplay , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Language agents with reinforcement learning for strategic play in the werewolf game , author=. arXiv preprint arXiv:2310.18940 , year=
-
[5]
Llm reasoners: New evaluation, library, and analysis of step-by-step reasoning with large language models , author=. arXiv preprint arXiv:2404.05221 , year=
-
[6]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[7]
arXiv preprint arXiv:2407.13696 , year=
Do these llm benchmarks agree? fixing benchmark evaluation with benchbench , author=. arXiv preprint arXiv:2407.13696 , year=
-
[8]
Proceedings of the 2021 conference of the North American chapter of the Association for Computational Linguistics: human language technologies , pages=
Dynabench: Rethinking benchmarking in NLP , author=. Proceedings of the 2021 conference of the North American chapter of the Association for Computational Linguistics: human language technologies , pages=
2021
-
[9]
Humanities and Social Sciences Communications , volume=
Large language models empowered agent-based modeling and simulation: A survey and perspectives , author=. Humanities and Social Sciences Communications , volume=. 2024 , publisher=
2024
-
[10]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[11]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
A Visualized Framework for Event Cooperation with Generative Agents , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[12]
Gensim: A general social simulation platform with large language model based agents , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (System Demonstrations) , pages=
2025
-
[13]
Agentsociety: Large-scale simulation of llm-driven generative agents advances understanding of human behaviors and society , author=
-
[14]
Advances in Neural Information Processing Systems , volume=
Adasociety: An adaptive environment with social structures for multi-agent decision-making , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
arXiv preprint arXiv:2311.06957 , year=
Simulating public administration crisis: A novel generative agent-based simulation system to lower technology barriers in social science research , author=. arXiv preprint arXiv:2311.06957 , year=
-
[16]
arXiv preprint arXiv:2503.09639 , year=
Can a society of generative agents simulate human behavior and inform public health policy? A case study on vaccine hesitancy , author=. arXiv preprint arXiv:2503.09639 , year=
-
[17]
arXiv preprint arXiv:2410.13915 , year=
A simulation system towards solving societal-scale manipulation , author=. arXiv preprint arXiv:2410.13915 , year=
-
[18]
arXiv preprint arXiv:2406.19966 , year=
Simulating financial market via large language model based agents , author=. arXiv preprint arXiv:2406.19966 , year=
-
[19]
International Conference on Learning Representations , volume=
Gamearena: Evaluating llm reasoning through live computer games , author=. International Conference on Learning Representations , volume=
-
[20]
arXiv preprint arXiv:2506.09655 , year=
DipLLM: Fine-tuning LLM for strategic decision-making in diplomacy , author=. arXiv preprint arXiv:2506.09655 , year=
-
[21]
International Conference on Learning Representations , volume=
Smartplay: A benchmark for llms as intelligent agents , author=. International Conference on Learning Representations , volume=
-
[22]
International Conference on Learning Representations , volume=
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors , author=. International Conference on Learning Representations , volume=
-
[23]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Multiagentbench: Evaluating the collaboration and competition of llm agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[24]
Advances in Neural Information Processing Systems , volume=
Large language models play starcraft ii: Benchmarks and a chain of summarization approach , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
arXiv preprint arXiv:2406.06613 , year=
Gamebench: Evaluating strategic reasoning abilities of llm agents , author=. arXiv preprint arXiv:2406.06613 , year=
-
[26]
Andrei Lupu, Timon Willi, and Jakob Foerster
Avalonbench: Evaluating llms playing the game of avalon , author=. arXiv preprint arXiv:2310.05036 , year=
-
[27]
Science , volume=
Human-level play in the game of diplomacy by combining language models with strategic reasoning , author=. Science , volume=. 2022 , publisher=
2022
-
[28]
arXiv preprint arXiv:2402.05863 , year=
How well can llms negotiate? negotiationarena platform and analysis , author=. arXiv preprint arXiv:2402.05863 , year=
-
[29]
International Conference on Learning Representations , volume=
Agentbench: Evaluating llms as agents , author=. International Conference on Learning Representations , volume=
-
[30]
Advances in neural information processing systems , volume=
Agentboard: An analytical evaluation board of multi-turn llm agents , author=. Advances in neural information processing systems , volume=
-
[31]
International Conference on Learning Representations , volume=
Sotopia: Interactive evaluation for social intelligence in language agents , author=. International Conference on Learning Representations , volume=
-
[32]
Generative agent-based modeling with actions grounded in physical, social, or digital space using Concordia , author=. arXiv preprint arXiv:2312.03664 , year=
-
[33]
2026 , eprint=
OpenAI GPT-5 System Card , author=. 2026 , eprint=
2026
-
[34]
2024 , eprint=
GPT-4o System Card , author=. 2024 , eprint=
2024
-
[35]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.