GeoIMO: Geometry-Driven Independent Motion Classification for Event Cameras
Pith reviewed 2026-06-26 00:54 UTC · model grok-4.3
The pith
A geometry-driven method classifies objects in event camera streams as static or independently moving without training or motion labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
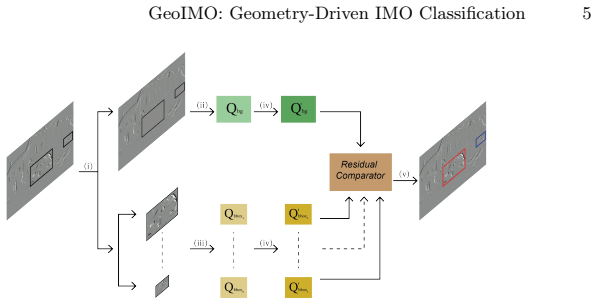
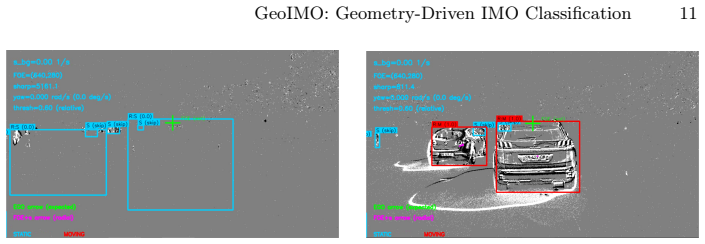
Global background motion is estimated from the event stream using a Focus of Expansion model with yaw compensation; objects are then labeled as independently moving when their local motion deviates from this global prediction, with the deviation quantified by a scale-invariant residual and stabilized temporally across event windows.
What carries the argument
Focus of Expansion model with yaw compensation that estimates global background motion, paired with a scale-invariant residual to quantify local deviations from that prediction.
If this is right
- Consistent performance across diverse driving scenarios on MVSEC and the Prophesee 1 Megapixel Automotive Detection dataset.
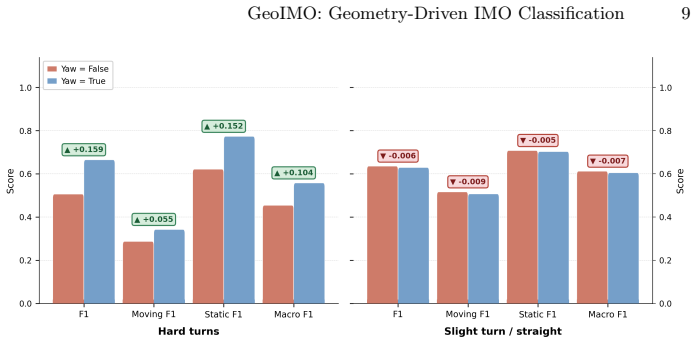
- Yaw compensation improves classification accuracy during turns.
- A simple translational local model provides a favorable accuracy-efficiency trade-off.
- Enables motion-aware event perception datasets without manual motion labels or learning.
Where Pith is reading between the lines
- The same geometric residual could be used to refine bounding box inputs iteratively within the same pipeline.
- Integration with other event-based tasks such as depth estimation might yield joint motion and structure recovery.
- The annotation-free labels could serve as weak supervision for training learned event models on larger unlabeled streams.
Load-bearing premise
Deviations from the predicted global background motion reliably indicate independent object motion rather than sensor noise, model inaccuracies during complex maneuvers, or errors in the input bounding boxes.
What would settle it
A test set of driving sequences with known static objects during sharp turns or acceleration changes where the method produces many false positive moving labels.
Figures

read the original abstract
Existing automotive event datasets rely on appearance-based annotations from frame pipelines, making them poorly suited for motion-aware event perception. We present a geometry-driven, annotation-free framework that classifies detected objects as static or independently moving by exploiting ego-motion structure directly from the event stream. A Focus of Expansion model with yaw compensation estimates global background motion, while objects are labeled as moving when local motion deviates from this prediction, as quantified by a scale-invariant residual. Temporal stabilization improves robustness across consecutive event windows. The method requires no learning, no manual motion labels, and works with any input bounding boxes. Experiments on MVSEC and the Prophesee 1 Megapixel Automotive Detection dataset demonstrate consistent performance across diverse driving scenarios, with yaw compensation improving results during turns and a simple translational local model offering a favorable accuracy-efficiency trade-off.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GeoIMO, a geometry-driven, annotation-free framework for classifying objects in event-camera streams as static or independently moving. It estimates global background motion via a Focus of Expansion model with yaw compensation, then labels an object as moving when its local motion deviates from the predicted background motion as measured by a scale-invariant residual; temporal stabilization is added for robustness. The approach requires no learning or manual labels and is compatible with arbitrary input bounding boxes. Experiments on MVSEC and the Prophesee 1-Megapixel Automotive Detection dataset report consistent performance, with yaw compensation helping during turns and a simple translational local model providing a favorable accuracy-efficiency trade-off.
Significance. If the central geometric claim holds, the work supplies a practical, parameter-free route to motion-aware labels for event-based automotive perception, addressing the mismatch between existing appearance-based dataset annotations and the motion-centric nature of event data. The explicit incorporation of yaw compensation and the absence of learned parameters are concrete strengths that could aid reproducible dataset construction and downstream motion-aware algorithms.
major comments (2)
- [Method (FoE + residual definition) and Experiments] The scale-invariant residual (described in the method and used for the classification decision) is load-bearing for the central claim. The manuscript does not provide a quantitative isolation of this residual from confounds such as event noise, FoE model mismatch during complex maneuvers, or bounding-box localization error; without such isolation the reported classification accuracies on MVSEC and Prophesee could partly reflect model mismatch rather than independent motion.
- [Experiments and Discussion] The assumption that the background is dominant and that a local translational model suffices is stated but not stress-tested against unmodeled rotational components or sensor artifacts. A controlled ablation (e.g., synthetic event streams with known independent motion plus added noise or rotation) would be needed to confirm that deviations are attributable to independent motion.
minor comments (2)
- Clarify the exact definition and normalization of the scale-invariant residual; a short equation or pseudocode block would remove ambiguity for readers attempting to reproduce the metric.
- The claim of “consistent performance across diverse driving scenarios” would be strengthened by reporting per-scenario breakdowns (e.g., straight vs. turning segments) rather than aggregate numbers only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the design choices and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Method (FoE + residual definition) and Experiments] The scale-invariant residual (described in the method and used for the classification decision) is load-bearing for the central claim. The manuscript does not provide a quantitative isolation of this residual from confounds such as event noise, FoE model mismatch during complex maneuvers, or bounding-box localization error; without such isolation the reported classification accuracies on MVSEC and Prophesee could partly reflect model mismatch rather than independent motion.
Authors: We appreciate the emphasis on isolating the residual's contribution. The scale-invariant residual is explicitly formulated to normalize deviations relative to distance from the estimated FoE, reducing sensitivity to scale. Experiments demonstrate that adding yaw compensation—which directly mitigates FoE mismatch during turns—improves classification accuracy on both MVSEC and Prophesee datasets, indicating that performance gains track reductions in ego-motion modeling error rather than residual artifacts. Temporal stabilization further attenuates transient bounding-box localization errors. We agree that explicit discussion of these confounds would strengthen the paper and will add a dedicated paragraph in the revised manuscript analyzing their potential impact and the method's mitigation strategies. revision: partial
-
Referee: [Experiments and Discussion] The assumption that the background is dominant and that a local translational model suffices is stated but not stress-tested against unmodeled rotational components or sensor artifacts. A controlled ablation (e.g., synthetic event streams with known independent motion plus added noise or rotation) would be needed to confirm that deviations are attributable to independent motion.
Authors: The background-dominance assumption is standard for automotive ego-motion estimation and is operationalized here by the global FoE model with explicit yaw compensation for rotational ego-motion. The local translational model is justified by the accuracy-efficiency trade-off reported in the experiments. While sensor artifacts and residual rotational effects are possible, the consistent cross-dataset results under varied driving conditions (including turns) provide empirical support. A full synthetic ablation with controlled noise and rotation would require generating new labeled event streams, which is not feasible in the current revision cycle; we will instead expand the discussion section to more explicitly address these modeling assumptions and their limitations. revision: no
Circularity Check
No circularity; geometric model is independently motivated from event data
full rationale
The paper defines a direct geometric procedure: FoE model with yaw compensation estimates global background motion from the event stream, then objects are labeled independently moving via deviation quantified by a scale-invariant residual. This is a first-principles application of ego-motion geometry rather than any fitted parameter renamed as prediction, self-definitional loop, or self-citation chain. No equations reduce the classification output to the input data by construction, and the method is explicitly annotation-free with no learning. The derivation chain is self-contained against external geometric benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A Focus of Expansion model with yaw compensation can accurately estimate global background motion from the event stream alone.
- domain assumption Scale-invariant residual deviation from the global model reliably separates independent motion from background or noise.
Reference graph
Works this paper leans on
-
[1]
IEEE Signal Processing Magazine37(4), 34–49 (Jul 2020)
Chen, G., Cao, H., Conradt, J., Tang, H., Rohrbein, F., Knoll, A.: Event-Based Neuromorphic Vision for Autonomous Driving: A Paradigm Shift for Bio-Inspired Visual Sensing and Perception. IEEE Signal Processing Magazine37(4), 34–49 (Jul 2020). https://doi.org/10.1109/MSP.2020.2985815
-
[2]
Event-Based Vision: A Survey ,
Gallego, G., Delbrück, T., Orchard, G., Bartolozzi, C., Taba, B., Censi, A., Leutenegger, S., Davison, A.J., Conradt, J., Daniilidis, K., Scaramuzza, D.: Event- BasedVision:ASurvey.IEEETransactionsonPatternAnalysisandMachineIntel- ligence44(1), 154–180 (Jan 2022). https://doi.org/10.1109/TPAMI.2020.3008413
-
[3]
International Journal of Computer Vision7(2), 95–117 (Jan 1992)
Heeger, D.J., Jepson, A.D.: Subspace methods for recovering rigid motion I: Algo- rithm and implementation. International Journal of Computer Vision7(2), 95–117 (Jan 1992). https://doi.org/10.1007/BF00128130
-
[4]
Artificial Intelligence 17(1), 185–203 (Aug 1981)
Horn, B.K.P., Schunck, B.G.: Determining optical flow. Artificial Intelligence 17(1), 185–203 (Aug 1981). https://doi.org/10.1016/0004-3702(81)90024-2
-
[5]
A 128× 128 120 dB 15 µs Latency Asynchronous Temporal Contrast Vision Sensor
Lichtsteiner, P., Posch, C., Delbruck, T.: A 128\times 128 120 dB 15µs Latency Asynchronous Temporal Contrast Vision Sensor. IEEE Journal of Solid-State Cir- cuits43(2), 566–576 (Feb 2008). https://doi.org/10.1109/JSSC.2007.914337
-
[6]
Proceedings of the Royal Society of London
Longuet-Higgins, H.C., Prazdny, K.: The interpretation of a moving retinal image. Proceedings of the Royal Society of London. B. Biological Sciences208(1173), 385–397 (Jul 1980). https://doi.org/10.1098/rspb.1980.0057
-
[7]
ImmFusion: Robust mmWave-RGB Fusion for 3D Human Body Reconstruction in All Weather Conditions,
Nagaraj, M., Liyanagedera, C.M., Roy, K.: DOTIE - Detecting Objects through Temporal Isolation of Events using a Spiking Architecture. In: 2023 IEEE Inter- national Conference on Robotics and Automation (ICRA). pp. 4858–4864 (May 2023). https://doi.org/10.1109/ICRA48891.2023.10161164
-
[8]
In: International Workshop on Advanced Image Technology (IWAIT) 2019
Nagata, J., Sekikawa, Y., Hara, K., Aoki, Y.: FOE-based regularization for optical flow estimation from an in-vehicle event camera. In: International Workshop on Advanced Image Technology (IWAIT) 2019. vol. 11049, pp. 562–565. SPIE (Mar 2019). https://doi.org/10.1117/12.2521520
-
[9]
In: Advances in Neural Information Processing Systems
Perot, E., de Tournemire, P., Nitti, D., Masci, J., Sironi, A.: Learning to Detect Objects with a 1 Megapixel Event Camera. In: Advances in Neural Information Processing Systems. vol. 33, pp. 16639–16652. Curran Associates, Inc. (2020)
2020
-
[10]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
Stoffregen, T., Gallego, G., Drummond, T., Kleeman, L., Scaramuzza, D.: Event- based motion segmentation by motion compensation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
2019
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
Stoffregen, T., Kleeman, L.: Event cameras, contrast maximization and reward functions: An analysis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
2019
-
[12]
IEEE Access8, 58443– 58469 (2020)
Yurtsever, E., Lambert, J., Carballo, A., Takeda, K.: A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access8, 58443– 58469 (2020). https://doi.org/10.1109/ACCESS.2020.2983149
-
[13]
IEEE Robotics and Automation Letters3(3), 2032–2039 (Jul 2018)
Zhu, A.Z., Thakur, D., Özaslan, T., Pfrommer, B., Kumar, V., Daniilidis, K.: The Multivehicle Stereo Event Camera Dataset: An Event Camera Dataset for 3D Perception. IEEE Robotics and Automation Letters3(3), 2032–2039 (Jul 2018)
2032
-
[14]
https://doi.org/10.15607/RSS.2018.XIV.062
Zhu, A.Z., Yuan, L., Chaney, K., Daniilidis, K.: EV-FlowNet: Self- Supervised Optical Flow Estimation for Event-based Cameras (Feb 2018). https://doi.org/10.15607/RSS.2018.XIV.062
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.