What's the Point? Spatial Grammar & Index Resolution for Sign Language Processing
Pith reviewed 2026-06-27 19:38 UTC · model grok-4.3
The pith
Sign language recognition models fail to recover spatial indexing despite it comprising 10-15% of signing content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
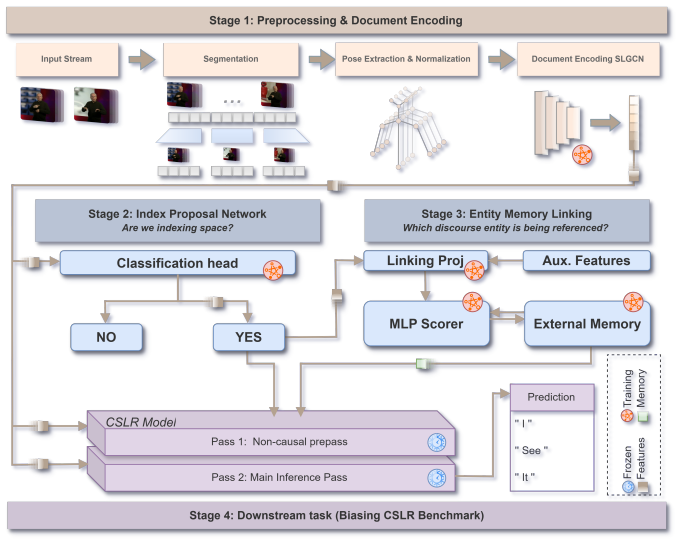
The central claim is that indexing is poorly recovered by standard sign language recognition despite making up 10-15% of content, and that decomposing spatial reference resolution into index detection and discourse entity linking creates mention representations that enable automatic annotation, non-lexical structure modeling, and augmentation of frozen SLR models as an auxiliary indexing expert at inference time.
What carries the argument
The two-stage decomposition of spatial reference resolution into index detection and discourse entity linking that yields mention representations.
If this is right
- Mention representations from the decomposition enable automatic annotation of indexing in sign language data.
- Non-lexical structures can be modeled explicitly using the resulting index and linking information.
- A frozen sign language recognition model can be augmented at inference time with the indexing expert.
- The framework provides a baseline for training and evaluating index-aware sign language models.
Where Pith is reading between the lines
- The same detection-plus-linking split might apply to other productive, non-lexical elements in sign languages beyond indexing.
- Better recovered spatial references could improve performance on downstream tasks such as co-reference tracking in sign language translation.
- Testing the expert on a wider range of base models would show how much indexing recovery contributes to overall sign language understanding.
Load-bearing premise
That the chosen datasets, metrics, and existing SLR models are representative of real signing and that splitting the task into detection plus linking captures the essential productive aspects of spatial grammar.
What would settle it
Adding the indexing expert to a frozen SLR model and measuring no increase in the percentage of correctly recovered indexing gestures on held-out signing data.
Figures



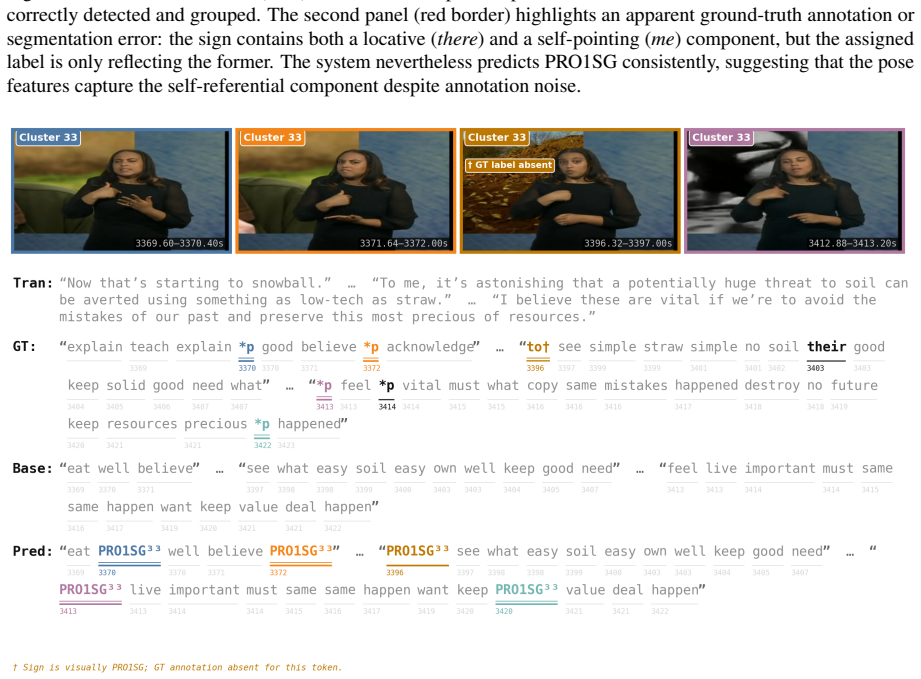
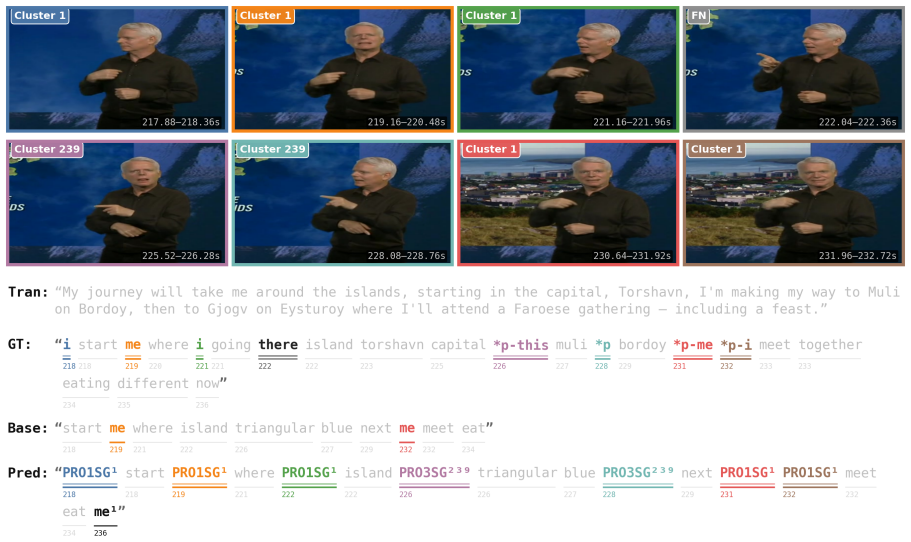
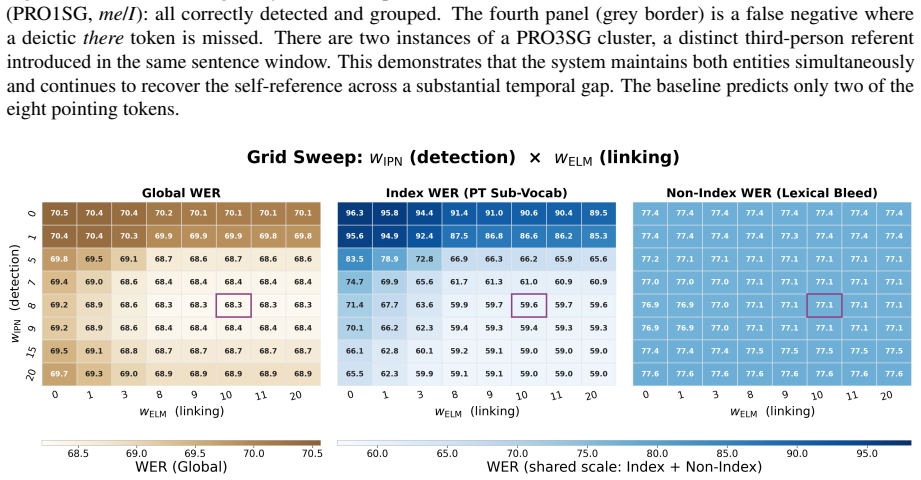

read the original abstract
Sign language models are predominantly trained with gloss-sequence or text supervision, thereby under-modeling non-lexical and productive constructions. One comparatively tractable instance is spatial indexing: pointing gestures that assign discourse entities to spatial loci for subsequent co-reference, which lexicon-centric objectives largely fail to capture. We present a targeted evaluation of indexing in Sign Language Recognition, showing that despite comprising 10-15% of signing content, indexing is poorly recovered. We introduce a framework for training and evaluating indexing experts, establishing a baseline for index-aware sign language modeling. Our approach decomposes spatial reference resolution into index detection and discourse entity linking. The resulting mention representations enable automatic annotation and non-lexical structure modeling, and serve as an auxiliary indexing expert that augments a frozen SLR model at inference time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current sign language recognition models under-model non-lexical spatial indexing (pointing gestures assigning discourse entities to loci for co-reference), which comprises 10-15% of signing content yet is poorly recovered. It introduces a framework that decomposes spatial reference resolution into index detection and discourse entity linking; the resulting mention representations support automatic annotation, non-lexical structure modeling, and serve as an auxiliary indexing expert that augments a frozen SLR model at inference time.
Significance. If the evaluation demonstrates poor recovery with appropriate baselines and the decomposition proves effective for augmentation, the work would establish a useful baseline for index-aware sign language modeling and help address the field's predominant reliance on gloss or text supervision for productive constructions.
major comments (3)
- [Abstract and §3] Abstract and §3 (Framework): the central claim that the two-stage detection-plus-linking decomposition enables effective non-lexical modeling and auxiliary augmentation rests on the unexamined premise that index detection and discourse entity linking are separable; the manuscript provides no analysis or ablation showing that this split preserves simultaneous spatial modifications or discourse-level spatial consistency that characterize productive signing.
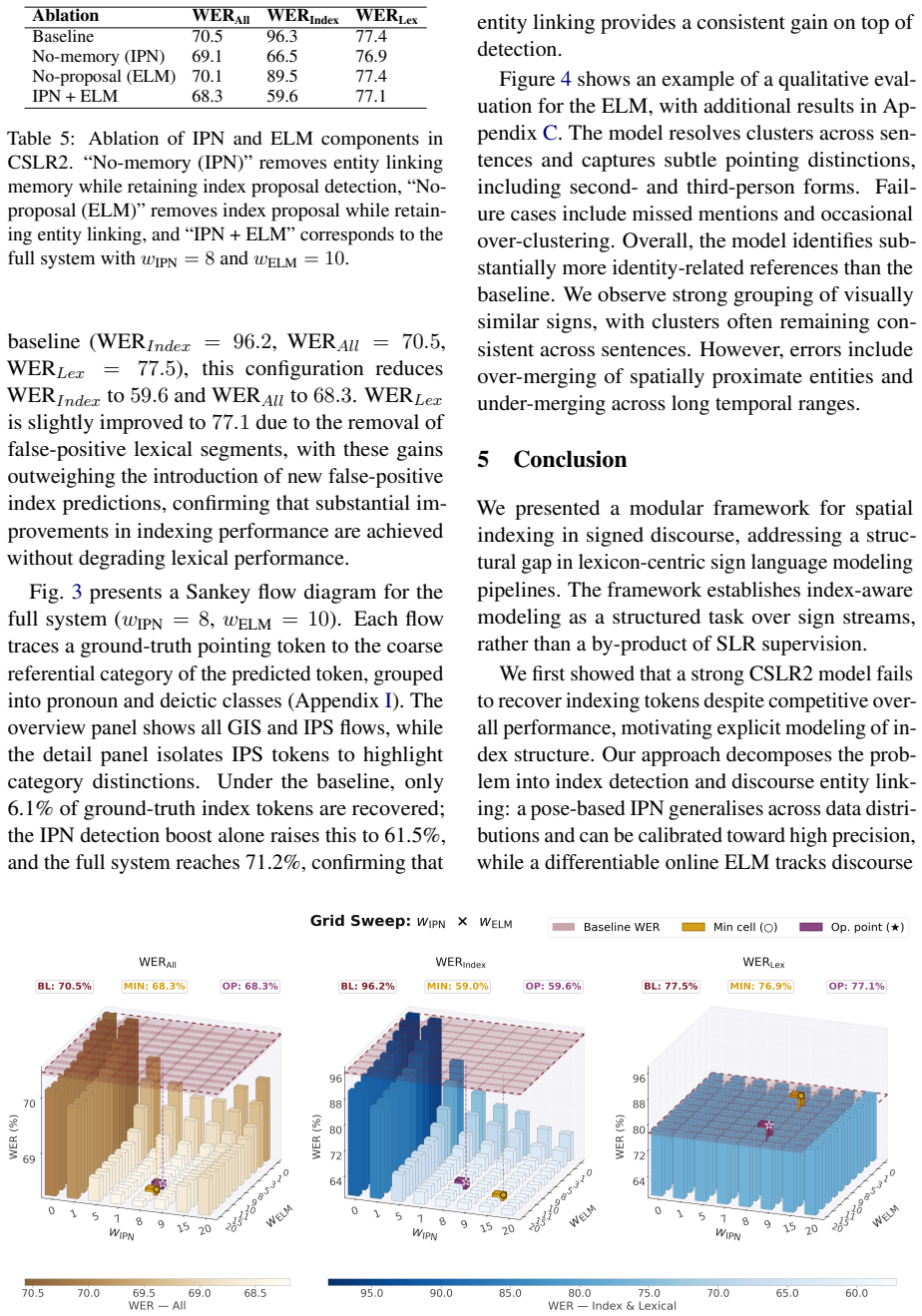
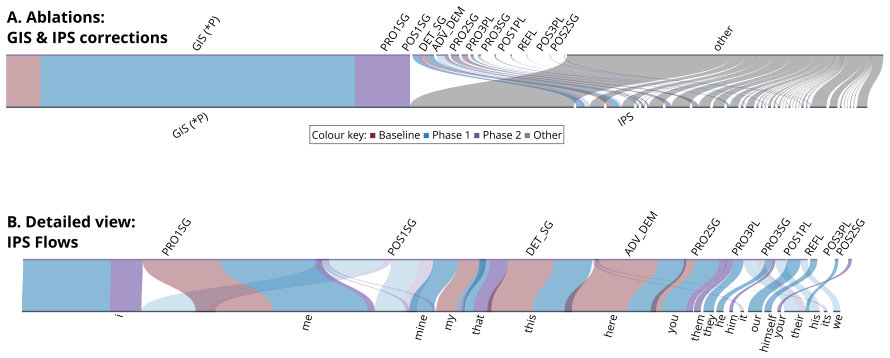
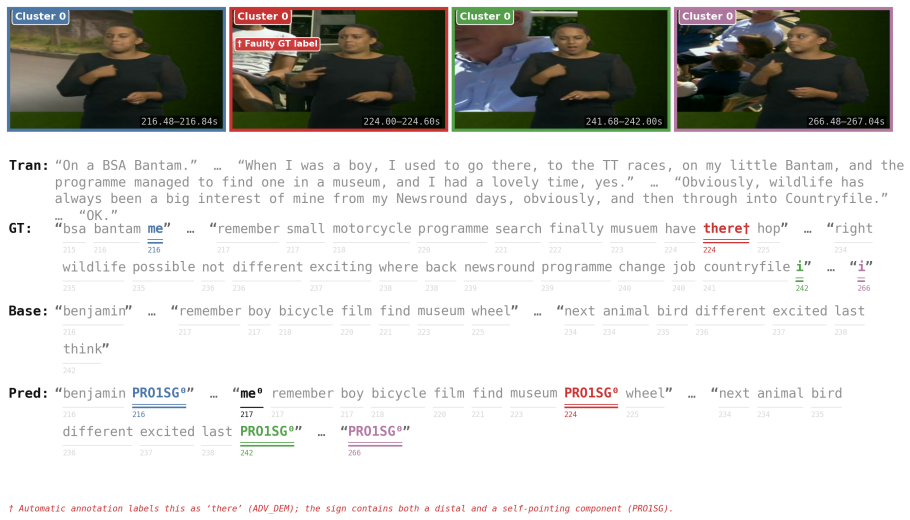
- [§4] §4 (Evaluation): the assertion that indexing is poorly recovered supplies no quantitative metrics, baselines, error analysis, or dataset statistics, so it is impossible to determine whether the data support the stated claims or whether the chosen SLR models and metrics are representative.
- [§5] §5 (Augmentation experiments): the claim that the indexing expert augments a frozen SLR model lacks reported performance deltas, statistical significance tests, or controls for the contribution of the mention representations versus other factors.
minor comments (2)
- [§3] Notation for loci and mention representations is introduced without a consolidated table or figure clarifying the mapping from raw video to the decomposed components.
- [Abstract] The 10-15% figure for indexing prevalence is stated without a citation or derivation from the evaluation corpus.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major point below, indicating planned revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Framework): the central claim that the two-stage detection-plus-linking decomposition enables effective non-lexical modeling and auxiliary augmentation rests on the unexamined premise that index detection and discourse entity linking are separable; the manuscript provides no analysis or ablation showing that this split preserves simultaneous spatial modifications or discourse-level spatial consistency that characterize productive signing.
Authors: The decomposition is motivated by linguistic descriptions of sign language spatial reference, in which pointing gestures (detection) are distinct from subsequent anaphoric reference (linking). The current manuscript does not contain an explicit ablation on separability or preservation of simultaneous modifications. We will add such an analysis and ablation study in the revised version, evaluating discourse consistency across linked mentions. revision: yes
-
Referee: [§4] §4 (Evaluation): the assertion that indexing is poorly recovered supplies no quantitative metrics, baselines, error analysis, or dataset statistics, so it is impossible to determine whether the data support the stated claims or whether the chosen SLR models and metrics are representative.
Authors: Section 4 presents a targeted evaluation that includes quantitative recovery metrics for indexing gestures, comparisons against standard SLR models as baselines, and dataset statistics on the 10-15% proportion of indexing content. We agree that the error analysis section can be expanded for greater clarity and will add more granular breakdowns and additional model comparisons in the revision. revision: partial
-
Referee: [§5] §5 (Augmentation experiments): the claim that the indexing expert augments a frozen SLR model lacks reported performance deltas, statistical significance tests, or controls for the contribution of the mention representations versus other factors.
Authors: Section 5 reports results from augmenting a frozen SLR model with the indexing expert. We will add explicit performance deltas, statistical significance testing, and controls isolating the contribution of the mention representations in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical evaluation and framework introduction
full rationale
The paper presents an empirical evaluation of indexing in sign language recognition and introduces a two-stage detection-plus-linking framework. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described content. The work is self-contained as a data-driven analysis and auxiliary model augmentation approach without reducing claims to definitional inputs or prior self-referential results.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
BackTranslation2.0 -- A Linguistically Motivated Metric to Assess Sign Language Production
BackTranslation2.0 is a linguistically motivated evaluation metric for sign language production that uses an agentic tool pipeline and LLM cross-referencing to score four dimensions and shows strong human correlation ...
Reference graph
Works this paper leans on
-
[1]
In Proceedings of the LREC 2026 12th Workshop on the Representation and Processing of Sign Languages: Language in Motion
Signgpt and the visual language toolkit. In Proceedings of the LREC 2026 12th Workshop on the Representation and Processing of Sign Languages: Language in Motion. Necati Cihan Camgoz, Simon Hadfield, Oscar Koller, and Richard Bowden. 2017. Subunets: End-to-end hand shape and continuous sign language recognition. InProceedings of the IEEE international con...
2026
-
[2]
Kearsy Cormier, Adam Schembri, and Bencie Woll
Diversity across sign languages and spoken languages: Implications for language universals.Lin- gua. Kearsy Cormier, Adam Schembri, and Bencie Woll
-
[3]
Runpeng Cui, Hu Liu, and Changshui Zhang
Pronouns and pointing in sign languages.Lin- gua. Runpeng Cui, Hu Liu, and Changshui Zhang. 2019. A deep neural framework for continuous sign language recognition by iterative training.IEEE Transactions on Multimedia. Mathieu De Coster, Dimitar Shterionov, Mieke Van Her- reweghe, and Joni Dambre. 2024. Machine transla- tion from signed to spoken languages...
2019
-
[4]
Georgios Pavlakos, Vasileios Choutas, Nima Ghor- bani, Timo Bolkart, Ahmed A
Locative expressions in signed languages: A view from turkish sign language (tid).Linguistics. Georgios Pavlakos, Vasileios Choutas, Nima Ghor- bani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. 2019. Expressive body capture: 3d hands, face, and body from a sin- gle image. InProceedings IEEE Conf. on Computer Vision and Patter...
2019
-
[5]
InProceedings of the 2020 Con- ference on Empirical Methods in Natural Language Processing (EMNLP)
Incremental neural coreference resolution in constant memory. InProceedings of the 2020 Con- ference on Empirical Methods in Natural Language Processing (EMNLP). Aoxiong Yin, Zhou Zhao, Jinglin Liu, Weike Jin, Meng Zhang, Xingshan Zeng, and Xiaofei He. 2021a. Simulslt: End-to-end simultaneous sign language translation. InProc. of the 29th ACM Internationa...
2020
-
[6]
London”, “British Sign Language
Proper-noun sequences:one or more consec- utive PROPN tokens (e.g. “London”, “British Sign Language”)
-
[7]
the deaf com- munity
Nominal phrases:optional DET/PRON/NUM, followed by zero or more ADJ and one or more NOUN/PROPN tokens (e.g. “the deaf com- munity”)
-
[8]
I, you, she, it)
Pronominal mentions:single-token PRON (e.g. I, you, she, it)
-
[9]
So I started school in London
Standalone demonstratives: DET tokens from {this, that, these, those} not followed by a noun. Nested spans are pruned to maximal spans. The output is one line per dialogue turn with its ex- tracted mentions: [turn=3 speaker=BF25F29WHN] "So I started school in London", ["I", "school", "London"] E.0.2 Stage 2: LLM Coreference Cluster Assignment Model setup....
-
[10]
Process the dialogue strictly in order, from the first turn to the last
-
[11]
When a mention refers to an entity already seen, reuse the SAME cluster ID
-
[12]
When a mention is new, assign the NEXT unused integer (starting at 0)
-
[13]
Never renumber, reuse, or reshuffle existing cluster IDs
-
[14]
Well I was born deaf
If a mention is not an entity mention or you are unsure, output "-". REFERENCE RULES - Same entity => same integer. - I / me / my => current speaker. - you / your => most likely addressee. OUTPUT FORMAT - Return ONLY one bracketed list per input line. - Item count MUST equal mention count. Examples: [0] [1, 2, 3] [4, 3, -] User Message Format doc_id: BF25...
-
[15]
Explicit mapping.Fixed-referent glosses are resolved deterministically (PT:PRO1SG→first- person cluster; PT:PRO2SG→second-person cluster; etc.)
-
[16]
PT: and PT:DET tokens are then grouped into runs; temporally proximate occurrences (within 25 entries) are merged into the same cluster
Generic pointers.All bare PT: tokens are first collapsed into a single shared cluster. PT: and PT:DET tokens are then grouped into runs; temporally proximate occurrences (within 25 entries) are merged into the same cluster
-
[17]
Soft third-person lookup.Before co- occurrence scoring, PT:PRO3SG, PT:POSS3SG, PT:PRO3PL, and PT:POSS3PL labels search entities_raw for clusters containing a third- person pronoun mention (he, she, her, his, it, they, them, their), providing a lightweight resolution path that avoids spurious co- occurrence matches
-
[18]
Cross-sentence co-occurrence.Remaining PT labels are linked to the LLM cluster with which they most frequently co-occur (pro- cessed by decreasing cluster size)
-
[19]
BUOY grouping.Nearby buoy tokens (PT:BUOY, PT:LBUOY, PT:FBUOY) within a 15- entry window share a cluster
-
[20]
E.0.4 Stage 4: Rule-Based Post-Processing Refinements Raw LLM clusters often contain systematic errors that degrade training label quality
Fallback.Remaining instances attach to the nearest assigned cluster of the same label type, 17 or open a new cluster. E.0.4 Stage 4: Rule-Based Post-Processing Refinements Raw LLM clusters often contain systematic errors that degrade training label quality. Three targeted refinements are applied after Stage 3: Inanimate co-referent suppression.A regex pat...
-
[21]
Scale alignment.Body skeleton auto-scaled so that the mean body–hand limb length matches a fixed target of0.075 in WiLoR met- ric units, preventing the larger SMPL-X range from dominating hand features
-
[22]
Wrist stitching.Body wrist nodes (0, 5) are translated to coincide with their WiLoR coun- terparts, enforcing a consistent hand origin
-
[23]
Root centring.Skeleton translated so that the mean wrist position over the window lies at the origin
-
[24]
Scale normalisation.All coordinates divided by the inter-shoulder distance (nodes 2–3), giving viewpoint invariance
-
[25]
F.1 ELM Auxiliary Geometric Features As described in Sec
Canonical orientation.Rotation aligns the shoulder–shoulder axis with the y-axis, re- moving in-plane torso rotation while preserv- ing relative hand pose. F.1 ELM Auxiliary Geometric Features As described in Sec. 4.3 of the main paper, the ELM scoring incorporates auxiliary feature streams that recover spatial and kinematic information com- pressed away ...
-
[26]
Elevation.Vertical angle of the mean point- ing direction arcsin(dy), where d is the nor- malised sum of the finger vector (tip−wrist) and arm vector (wrist−elbow)
-
[27]
Distinguishes upward (addressee, abstract loci) from body-level (self, nearby referents) pointing
Target-y.Mean fingertip height relative to the shoulder midpoint, normalised by shoul- der width. Distinguishes upward (addressee, abstract loci) from body-level (self, nearby referents) pointing
-
[28]
Distinguishes forward-directed (third- person, distal) from body-proximal pointing
Target-z.Mean fingertip depth relative to the shoulder midpoint, normalised by shoulder width. Distinguishes forward-directed (third- person, distal) from body-proximal pointing
-
[29]
Arm reach.Normalised elbow-to-fingertip distance, capturing how fully extended the arm is
-
[30]
High values indicate a prototypical pointing handshape
Index selectivity.Difference between the normalised index fingertip extension and the mean extension of the middle, ring, and pinky fingertips, measured relative to palm scale. High values indicate a prototypical pointing handshape
-
[31]
Distinguishes static holds from sweeping or arc-shaped pointing gestures
Trajectory length.Cumulative fingertip dis- placement over the clip, normalised by shoul- der width. Distinguishes static holds from sweeping or arc-shaped pointing gestures. For scoring compatibility with entitye k, the six values for the current mention are concatenated with the stored per-cluster running mean and their element-wise difference (18 value...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.