Evaluating Chunking Strategies for Retrieval-Augmented Generation on Academic Texts
Pith reviewed 2026-07-03 06:55 UTC · model grok-4.3
The pith
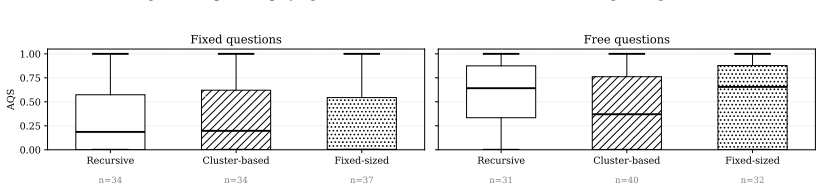
Cluster-based chunking did not outperform simpler fixed-size or recursive chunking for RAG on academic theses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
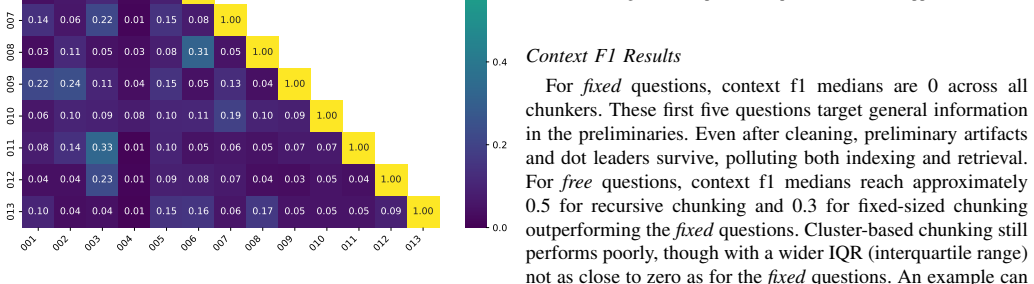
Under the tested configuration, cluster-based chunking did not outperform simpler strategies. RAGAs-based faithfulness shows limited reliability in this setup. Performance on fixed versus document-specific questions varied substantially, likely related to the formatting of documents and preprocessing.
What carries the argument
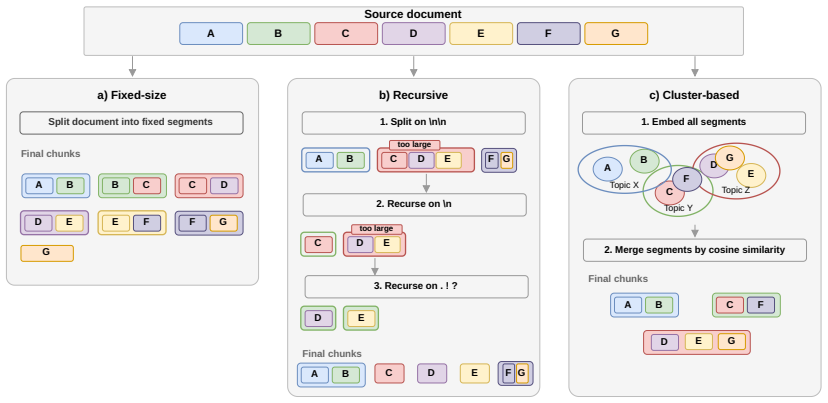
Direct comparison of three chunking methods (cluster-based semantic, fixed-size, recursive) inside a RAG pipeline, scored by RAGAs metrics on academic theses.
If this is right
- Simpler chunking methods can be used without loss of quality for RAG on structured academic documents.
- RAGAs faithfulness scores may not track human-perceived answer quality reliably on thesis-length texts.
- Question design and document preprocessing choices affect measured RAG performance more than chunking method.
- Fixed-size chunking remains a practical baseline for academic RAG applications.
Where Pith is reading between the lines
- Teams building RAG systems for academic content may save compute by defaulting to basic chunking unless domain-specific tests prove otherwise.
- RAG evaluation frameworks require additional validation steps when applied to long-form technical documents.
- The observed gap between fixed and document-specific questions points to a need for standardized test sets that control for document structure.
Load-bearing premise
The RAGAs framework supplies reliable measurements of faithfulness and answer quality for academic theses and the chosen question types.
What would settle it
Human raters scoring the same RAG answers for faithfulness and relevance, finding cluster-based chunking produces clearly superior results on the tested theses.
Figures



read the original abstract
Retrieval-Augmented Generation (RAG) systems use the question-answering capabilities of Large Language Models (LLMs) to access information outside their parameters. We evaluate if cluster-based semantic chunking improves retrieval and answer quality compared to fixed-size and recursive chunking evaluating on long, structured academic theses using the Retrieval Augmented Generation Assessment (RAGAs) framework. RAGAs based faithfulness shows limited reliability in this setup. Performance on fixed versus document specific questions varied substantially, likely related to the formatting of documents and preprocessing. Under the tested configuration, cluster-based chunking did not outperform simpler strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates cluster-based semantic chunking against fixed-size and recursive chunking for RAG on long academic theses, using the RAGAs framework to measure retrieval and answer quality. It reports that cluster-based chunking did not outperform the simpler strategies under the tested configuration, while noting that RAGAs faithfulness exhibits limited reliability and that performance varies substantially with document formatting and preprocessing.
Significance. If the comparative result can be placed on firmer evidential ground, the finding would indicate that semantic clustering adds little value over simpler chunking for structured academic documents, which could simplify RAG pipelines in scholarly settings. The work supplies a domain-specific empirical comparison on real theses, a useful data point given the length and hierarchical structure of such texts.
major comments (1)
- [Abstract] Abstract: The central claim that cluster-based chunking did not outperform simpler strategies is grounded in RAGAs faithfulness and answer-quality scores, yet the abstract itself states that 'RAGAs based faithfulness shows limited reliability in this setup'. Without independent validation (human evaluation, alternative metrics, or controls for the noted formatting effects), this self-identified limitation renders the 'did not outperform' conclusion insecure.
minor comments (2)
- [Abstract] Abstract: The statement that 'performance on fixed versus document specific questions varied substantially' is left without quantitative detail or statistical test; adding effect sizes or significance levels would strengthen the observation.
- The manuscript does not describe the exact question-generation procedure, the number of theses, or the LLM used for generation and evaluation; these omissions hinder reproducibility even if the RAGAs limitation is addressed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the concern about the security of our central claim below and propose revisions to better qualify our findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that cluster-based chunking did not outperform simpler strategies is grounded in RAGAs faithfulness and answer-quality scores, yet the abstract itself states that 'RAGAs based faithfulness shows limited reliability in this setup'. Without independent validation (human evaluation, alternative metrics, or controls for the noted formatting effects), this self-identified limitation renders the 'did not outperform' conclusion insecure.
Authors: We agree that the abstract's phrasing could more clearly signal the tentative nature of the finding given the metric limitation we ourselves identify. The manuscript already states both the empirical observation ('Under the tested configuration, cluster-based chunking did not outperform simpler strategies') and the caveat ('RAGAs based faithfulness shows limited reliability in this setup') in the same paragraph, and the results section further discusses substantial performance variation linked to document formatting and preprocessing. Nevertheless, to strengthen the presentation, we will revise the abstract to frame the result more explicitly as an observation within the RAGAs framework rather than a definitive comparative outcome, and we will add a brief clause noting that independent validation would be valuable for future work. This change preserves the paper's honest reporting of both the result and its limitations without overstating generalizability. revision: yes
Circularity Check
No circularity: pure empirical evaluation with no derivations or self-referential reductions
full rationale
The paper conducts an empirical comparison of chunking strategies (cluster-based, fixed-size, recursive) on academic theses, measuring outcomes via the external RAGAs framework. No equations, fitted parameters, uniqueness theorems, or derivations are present that could reduce to inputs by construction. The central claim rests on experimental results rather than any self-definitional or self-citation chain. Limitations in RAGAs reliability are explicitly noted but do not create circularity in the reported comparisons.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mirsky, Grace M. and Raman, Marc M. , month = nov, year =. Data. 2025 3rd. doi:10.1109/FLLM67465.2025.11390957 , abstract =
-
[2]
Campello, Ricardo J. G. B. and Moulavi, Davoud and Zimek, Arthur and Sander, Jörg , month = jul, year =. Hierarchical. doi:10.1145/2733381 , file =
-
[3]
Campello, Ricardo J. G. B. and Moulavi, Davoud and Sander, Joerg , editor =. Density-. Advances in. 2013 , keywords =. doi:10.1007/978-3-642-37456-2_14 , abstract =
-
[4]
ACM Trans. Database Syst. , author =. 2017 , pages =. doi:10.1145/3068335 , abstract =
-
[5]
Wang, Yining and Wang, Liwei and Li, Yuanzhi and He, Di and Liu, Tie-Yan and Chen, Wei , month = apr, year =. A. doi:10.48550/arXiv.1304.6480 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1304.6480
-
[6]
Edge, Darren and Trinh, Ha and Cheng, Newman and Bradley, Joshua and Chao, Alex and Mody, Apurva and Truitt, Steven and Metropolitansky, Dasha and Ness, Robert Osazuwa and Larson, Jonathan , month = feb, year =. From. doi:10.48550/arXiv.2404.16130 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.16130
-
[7]
IEEE Transactions on Big Data , author =
Billion-. IEEE Transactions on Big Data , author =. 2021 , keywords =. doi:10.1109/TBDATA.2019.2921572 , abstract =
-
[8]
Ioffe, Sergey , month = dec, year =. Improved. 2010. doi:10.1109/ICDM.2010.80 , abstract =
-
[9]
WIREs Data Mining and Knowledge Discovery , author =
Algorithms for hierarchical clustering: an overview , volume =. WIREs Data Mining and Knowledge Discovery , author =. 2012 , pages =. doi:10.1002/widm.53 , abstract =
-
[10]
and Matsuura, Kenji , year =
Willmott, Cort J. and Matsuura, Kenji , year =. Advantages of the mean absolute error (. Climate Research , publisher =
-
[11]
The American Journal of Psychology 15, 72–101
The. The American Journal of Psychology , author =. 1904 , pages =. doi:10.2307/1412159 , language =
-
[12]
scikit-learn , file =
-
[13]
Proceedings of
Riedl, Martin and Biemann, Chris , editor =. Proceedings of. 2012 , pages =
2012
-
[14]
Yepes, Antonio Jimeno and You, Yao and Milczek, Jan and Laverde, Sebastian and Li, Renyu , month = mar, year =. Financial. doi:10.48550/arXiv.2402.05131 , abstract =
-
[15]
Kreileder, Valentin and Fischer, Andreas and Reisinger, Johannes , month = jan, year =. Thesis-
-
[16]
2026 , note =
vibrantlabsai/ragas , copyright =. 2026 , note =
2026
-
[17]
and Raghavan, Prabhakar and Schütze, Hinrich , month = jul, year =
Manning, Christopher D. and Raghavan, Prabhakar and Schütze, Hinrich , month = jul, year =. Introduction to. Cambridge Aspire website , publisher =. doi:10.1017/CBO9780511809071 , note =
-
[18]
Wang, Zhitong and Gao, Cheng and Xiao, Chaojun and Huang, Yufei and Si, Shuzheng and Luo, Kangyang and Bai, Yuzhuo and Li, Wenhao and Duan, Tangjian and Lv, Chuancheng and Lu, Guoshan and Chen, Gang and Qi, Fanchao and Sun, Maosong , editor =. Document. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-acl.422 , abstract =
-
[19]
A. ACM Comput. Surv. , author =. 2023 , pages =. doi:10.1145/3606367 , abstract =
-
[20]
The Computer Journal , author =. 1973 , pages =. doi:10.1093/comjnl/16.1.30 , abstract =
-
[21]
Qu, Renyi and Tu, Ruixuan and Bao, Forrest Sheng , editor =. Is. Findings of the. 2025 , pages =. doi:10.18653/v1/2025.findings-naacl.114 , abstract =
-
[22]
Yu, Hao and Gan, Aoran and Zhang, Kai and Tong, Shiwei and Liu, Qi and Liu, Zhaofeng , year =. Evaluation of. doi:10.1007/978-981-96-1024-2_8 , abstract =
-
[23]
Es, Shahul and James, Jithin and Espinosa Anke, Luis and Schockaert, Steven , editor =. Proceedings of the 18th. 2024 , pages =. doi:10.18653/v1/2024.eacl-demo.16 , abstract =
-
[24]
Information Storage and Retrieval , author =
A definition of relevance for information retrieval , volume =. Information Storage and Retrieval , author =. 1971 , pages =. doi:10.1016/0020-0271(71)90024-6 , abstract =
-
[25]
How to split text based on semantic similarity
-
[26]
Chase, Harrison , month = oct, year =
-
[27]
Günther, Michael and Mohr, Isabelle and Williams, Daniel James and Wang, Bo and Xiao, Han , month = jul, year =. Late. doi:10.48550/arXiv.2409.04701 , abstract =
-
[28]
Bhat, Sinchana Ramakanth and Rudat, Max and Spiekermann, Jannis and Flores-Herr, Nicolas , month = may, year =. Rethinking. doi:10.48550/arXiv.2505.21700 , abstract =
-
[29]
IEEE Transactions on Pattern Analysis and Machine Intelligence , author =
n-. IEEE Transactions on Pattern Analysis and Machine Intelligence , author =. 1979 , keywords =. doi:10.1109/TPAMI.1979.4766902 , abstract =
-
[30]
Étude comparative de la distribution florale dans une portion des
Jaccard, Paul , year =. Étude comparative de la distribution florale dans une portion des. Bulletin de la Société Vaudoise des Sciences Naturelles , publisher =. doi:10.5169/seals-266450 , number =
-
[31]
Procedia Computer Science , author =
Matching. Procedia Computer Science , author =. 2024 , keywords =. doi:10.1016/j.procs.2024.03.039 , abstract =
-
[32]
Nussbaum, Zach and Duderstadt, Brandon , month = mar, year =. Training. doi:10.48550/arXiv.2502.07972 , abstract =
-
[33]
Thakur, Nandan and Reimers, Nils and Rücklé, Andreas and Srivastava, Abhishek and Gurevych, Iryna , month = aug, year =
-
[34]
Caspari, Laura and Dastidar, Kanishka Ghosh and Zerhoudi, Saber and Mitrovic, Jelena and Granitzer, Michael , month = jul, year =. Beyond. doi:10.48550/arXiv.2407.08275 , abstract =
-
[35]
Wang, Jiapeng and Dong, Yihong , month = sep, year =. Measurement of. Information , publisher =. doi:10.3390/info11090421 , abstract =
-
[36]
Chroma , file =
Chroma , url =. Chroma , file =
-
[37]
Engineering at Meta , month = mar, year =
Faiss:. Engineering at Meta , month = mar, year =
-
[38]
The vector database to build knowledgeable
-
[39]
Cohen, Ruslan Salakhut- dinov, and Christopher D
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. , editor =. Proceedings of the 2018. 2018 , pages =. doi:10.18653/v1/D18-1259 , abstract =
-
[40]
2025 , note =
allenai/scidocs , url =. 2025 , note =
2025
-
[41]
Zhang, Yue and Li, Yafu and Cui, Leyang and Cai, Deng and Liu, Lemao and Fu, Tingchen and Huang, Xinting and Zhao, Enbo and Zhang, Yu and Xu, Chen and Chen, Yulong and Wang, Longyue and Luu, Anh Tuan and Bi, Wei and Shi, Freda and Shi, Shuming , month = sep, year =. Siren's. doi:10.48550/arXiv.2309.01219 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.01219
-
[42]
Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Zhang, Xin and Lin, Huan and Yang, Baosong and Xie, Pengjun and Yang, An and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren , month = jun, year =. Qwen3. doi:10.48550/arXiv.2506.05176 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.05176
-
[43]
2024 , file =
nomic-ai/nomic-embed-text-v1 ·. 2024 , file =
2024
-
[44]
Arize AI , file =
Understanding and. Arize AI , file =
-
[45]
Analytics Vidhya , author =
8. Analytics Vidhya , author =. 2025 , file =
2025
-
[46]
Zhong, Zijie and Liu, Hanwen and Cui, Xiaoya and Zhang, Xiaofan and Qin, Zengchang , month = jun, year =. Mix-of-. doi:10.48550/arXiv.2406.00456 , abstract =
-
[47]
IEEE Transactions on Knowledge and Data Engineering , author =
Neural. IEEE Transactions on Knowledge and Data Engineering , author =. 2022 , keywords =. doi:10.1109/TKDE.2020.2983360 , abstract =
-
[48]
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy , month = nov, year =. Lost in the. doi:10.48550/arXiv.2307.03172 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.03172
-
[49]
https://openaccess.nhh.no/nhh-xmlui/bitstream/handle/11250/3178510/no.nhh\
-
[50]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
Grootendorst, Maarten , month = mar, year =. doi:10.48550/arXiv.2203.05794 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.05794
-
[51]
https://simg.baai.ac.cn/paperfile/25a43194-c74c-4cd3-b60f-0a1f27f8b8af.pdf , url =
-
[52]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and Küttler, Heinrich and Lewis, Mike and Yih, Wen-tau and Rocktäschel, Tim and Riedel, Sebastian and Kiela, Douwe , month = apr, year =. Retrieval-. doi:10.48550/arXiv.2005.11401 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2005.11401 2005
-
[53]
https://arxiv.org/pdf/2005.11401 , url =
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[54]
Retrieval-Augmented Generation for Large Language Models: A Survey
Gao, Yunfan and Xiong, Yun and Gao, Xinyu and Jia, Kangxiang and Pan, Jinliu and Bi, Yuxi and Dai, Yi and Sun, Jiawei and Wang, Meng and Wang, Haofen , month = mar, year =. Retrieval-. doi:10.48550/arXiv.2312.10997 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.10997
-
[55]
Bavarian Journal of Applied Sciences , author =
Topical. Bavarian Journal of Applied Sciences , author =. 2023 , note =. doi:10.25929/1rjp-d197 , abstract =
-
[56]
MTEB: Massive Text Embedding Benchmark
Muennighoff, Niklas and Tazi, Nouamane and Magne, Loïc and Reimers, Nils , month = mar, year =. doi:10.48550/arXiv.2210.07316 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.07316
-
[57]
Asai, Akari and Min, Sewon and Zhong, Zexuan and Chen, Danqi , editor =. Retrieval-based. Proceedings of the 61st. 2023 , pages =. doi:10.18653/v1/2023.acl-tutorials.6 , abstract =
-
[58]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , editor =. Proceedings of the 2019. 2019 , pages =. doi:10.18653/v1/N19-1423 , abstract =
-
[59]
Bari, Harsh , month = jan, year =. Contextual. 2025. doi:10.1109/SCEECS64059.2025.10940513 , abstract =
-
[60]
Putra, Syopiansyah Jaya and Gunawan, Muhamad Nur and Hidayat, Arief Akbar , month = sep, year =. Feature. 2022 10th. doi:10.1109/CITSM56380.2022.9935873 , abstract =
-
[61]
Rahman, Rifat , month = dec, year =. Robust and. 2020 23rd. doi:10.1109/ICCIT51783.2020.9392738 , abstract =
-
[62]
Wang, Liang and Yang, Nan and Huang, Xiaolong and Jiao, Binxing and Yang, Linjun and Jiang, Daxin and Majumder, Rangan and Wei, Furu , month = feb, year =. Text. doi:10.48550/arXiv.2212.03533 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.03533
-
[63]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna , month = aug, year =. Sentence-. doi:10.48550/arXiv.1908.10084 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1908.10084 1908
-
[64]
Reisinger, Johannes and Fischer, Andreas and Igl, Andreas , month = aug, year =. Semantic. 2025 2nd. doi:10.1109/GACLM67198.2025.11231968 , abstract =
-
[65]
Advances in Neural Information Processing Systems , author =
Judging. Advances in Neural Information Processing Systems , author =. 2023 , pages =
2023
-
[66]
2024 , keywords =
sentence-transformers/all-. 2024 , keywords =
2024
-
[67]
Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, M. Wang, and H. Wang, `` en Retrieval- Augmented Generation for Large Language Models : A Survey ,'' Mar. 2024, arXiv:2312.10997 [cs]. [Online]. Available: http://arxiv.org/abs/2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
R. Qu, R. Tu, and F. S. Bao, ``Is Semantic Chunking Worth the Computational Cost ?'' in Findings of the Association for Computational Linguistics : NAACL 2025 , L. Chiruzzo, A. Ritter, and L. Wang, Eds. 1em plus 0.5em minus 0.4em Albuquerque, New Mexico: Association for Computational Linguistics, Apr. 2025, pp. 2155--2177. [Online]. Available: https://acl...
2025
-
[69]
M. Günther, I. Mohr, D. J. Williams, B. Wang, and H. Xiao, ``Late Chunking : Contextual Chunk Embeddings Using Long - Context Embedding Models ,'' Jul. 2025, arXiv:2409.04701 [cs]. [Online]. Available: http://arxiv.org/abs/2409.04701
-
[70]
J. Reisinger, A. Fischer, and A. Igl, ``Semantic Document Graphs for Knowledge Retrieval ,'' in 2025 2nd International Generative AI and Computational Language Modelling Conference ( GACLM ) , Aug. 2025, pp. 294--298. [Online]. Available: https://ieeexplore.ieee.org/document/11231968
-
[71]
``sentence-transformers/all- MiniLM - L6 -v2 · Hugging Face ,'' Jan. 2024. [Online]. Available: https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
2024
-
[72]
S. Es, J. James, L. Espinosa Anke, and S. Schockaert, `` RAGAs : Automated Evaluation of Retrieval Augmented Generation ,'' in Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics : System Demonstrations , N. Aletras and O. De Clercq, Eds. 1em plus 0.5em minus 0.4em St. Julians, Malta: Association for...
2024
-
[73]
C. D. Manning, P. Raghavan, and H. Schütze, `` en Introduction to Information Retrieval ,'' Jul. 2008, iSBN: 9780511809071. [Online]. Available: https://www.cambridge.org/highereducation/books/introduction-to-information-retrieval/669D108D20F556C5C30957D63B5AB65C
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.